 夜雨聆风
夜雨聆风相信大家都用过Claude Code等Agent写代码,有没有好奇过当它说"我来帮你读一下这个文件",是怎么知道什么时候要调工具?调哪个?翻了几个框架的源码和文档之后,发现这还挺有意思的。
一个请求的生命周期
假设你向一个AI Agent发送了一句:"帮我查一下北京和东京的天气,然后发邮件给edwin@example.com汇总。"
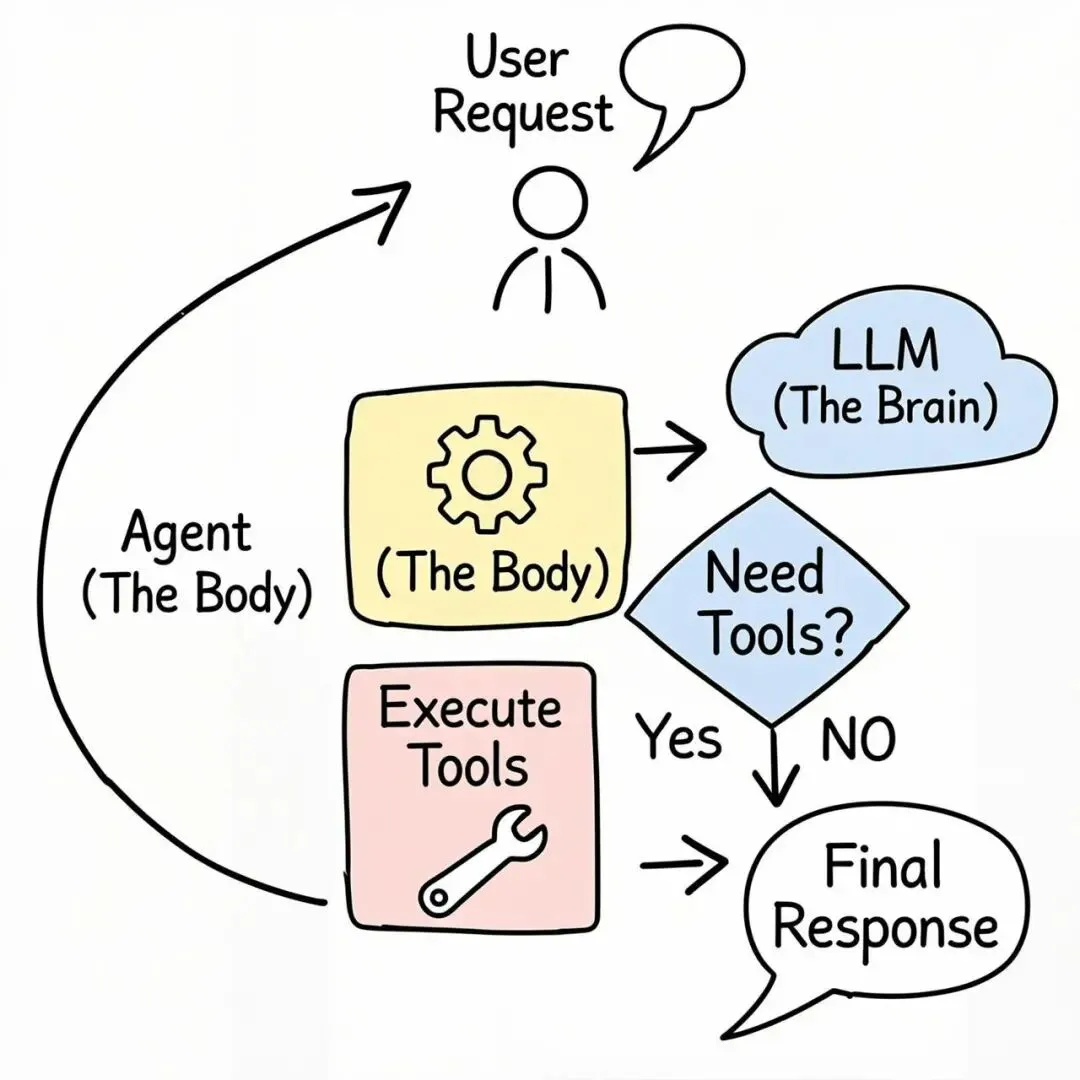
一个完整的Agent处理流程是这样的:
用户请求 │ ▼┌───────────────────────│ 1. 意图识别与工具选择 │ LLM看到请求 + 可用工具列表 │ → 决定调用哪些工具、什么参数 └──────────────┬──────── │ LLM返回工具调用指令 ▼┌──────────────────────│ 2. 参数构造与执行 │ Agent解析LLM返回的结构化数据 │ → 执行get_weather("北京") │ → 执行get_weather("东京") │ → 执行send_email(...) └──────────────┬─────── │ 执行结果 ▼┌──────────────────────│ 3. 结果回传与总结 │ 将工具执行结果发回LLM │ → LLM基于结果生成自然语言回复 └──────────────────────这里面有个关键的点:LLM本身不执行任何工具,它只负责"决定"要不要调用、调用哪个、传什么参数。实际执行和结果回传,是客户端Agent框架(说白了就是个while循环)在做。
我们来看下时序图:
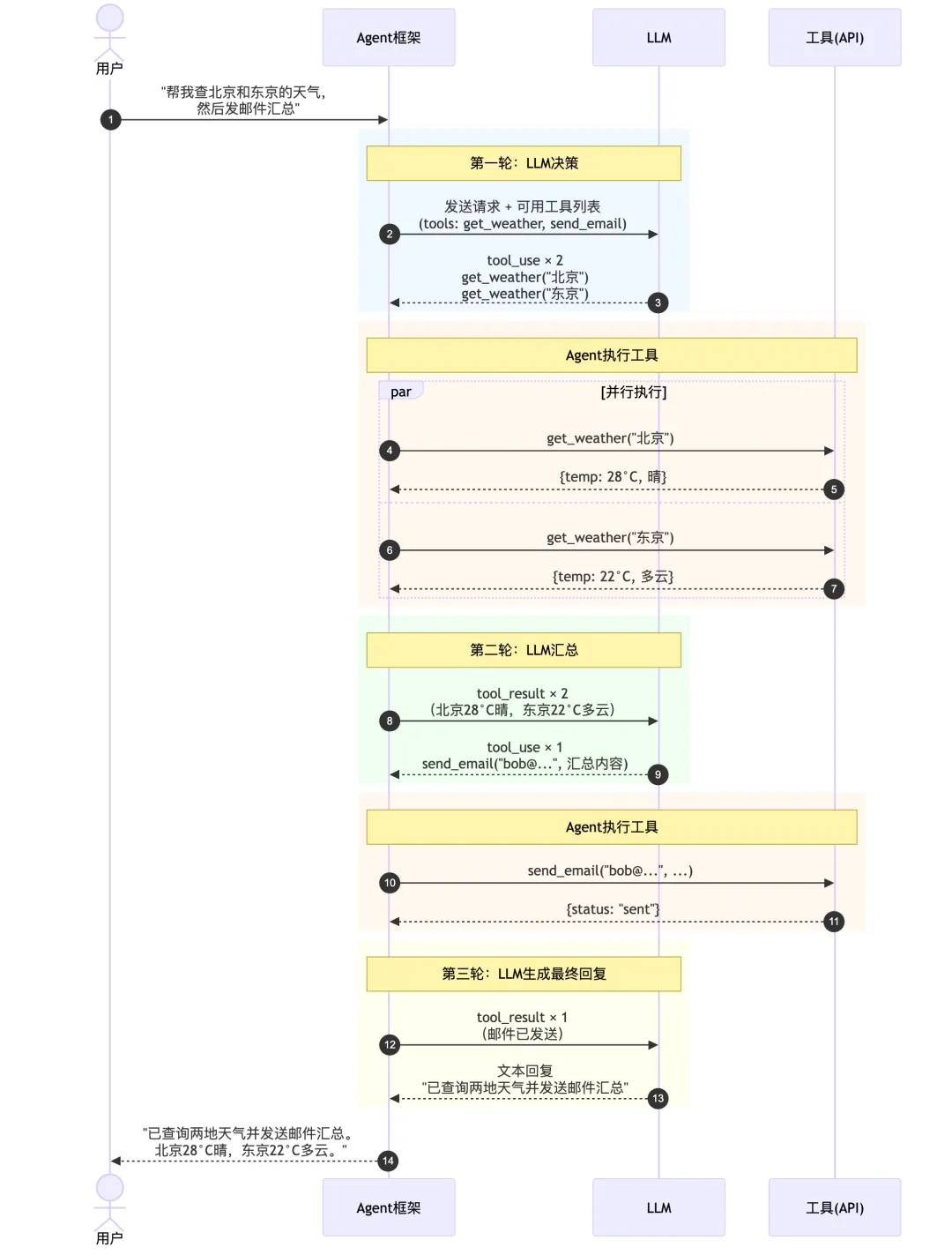
从时序图可以看到,一个看似简单的"查天气发邮件"请求,背后经历了三轮LLM调用:第一轮LLM决定调两个天气API,第二轮LLM决定发邮件,第三轮LLM生成最终回复。每一轮都是"发给LLM → 收到工具调用指令 → 执行工具 → 把结果送回去"的循环。
看似简单,但整个流程“折腾”了很久。
第一章:蛮荒时代,用提示词"哄"LLM调用工具(2022-2023)
ReAct:推理+行动的文本游戏
2022年10月,普林斯顿大学的Shunyu Yao发表了ReAct论文(Reasoning + Acting),这是最早系统化地让LLM使用工具的方法。
核心思路很简单:在提示词里定义一个固定格式,让LLM按格式输出"想调用什么工具"。
你可以使用以下工具:Search: 搜索引擎,输入查询字符串Calculator: 计算器,输入数学表达式请按以下格式回答:Question: 用户的问题Thought: 你在思考什么Action: 要使用的工具名Action Input: 工具的输入参数(JSON格式)Observation: 工具的执行结果(系统填写)... (Thought/Action/Observation 可以重复多次)Thought: 我现在知道最终答案了Final Answer: 最终答案当用户问"法国首都的人口是多少?",LLM的输出会是这样:
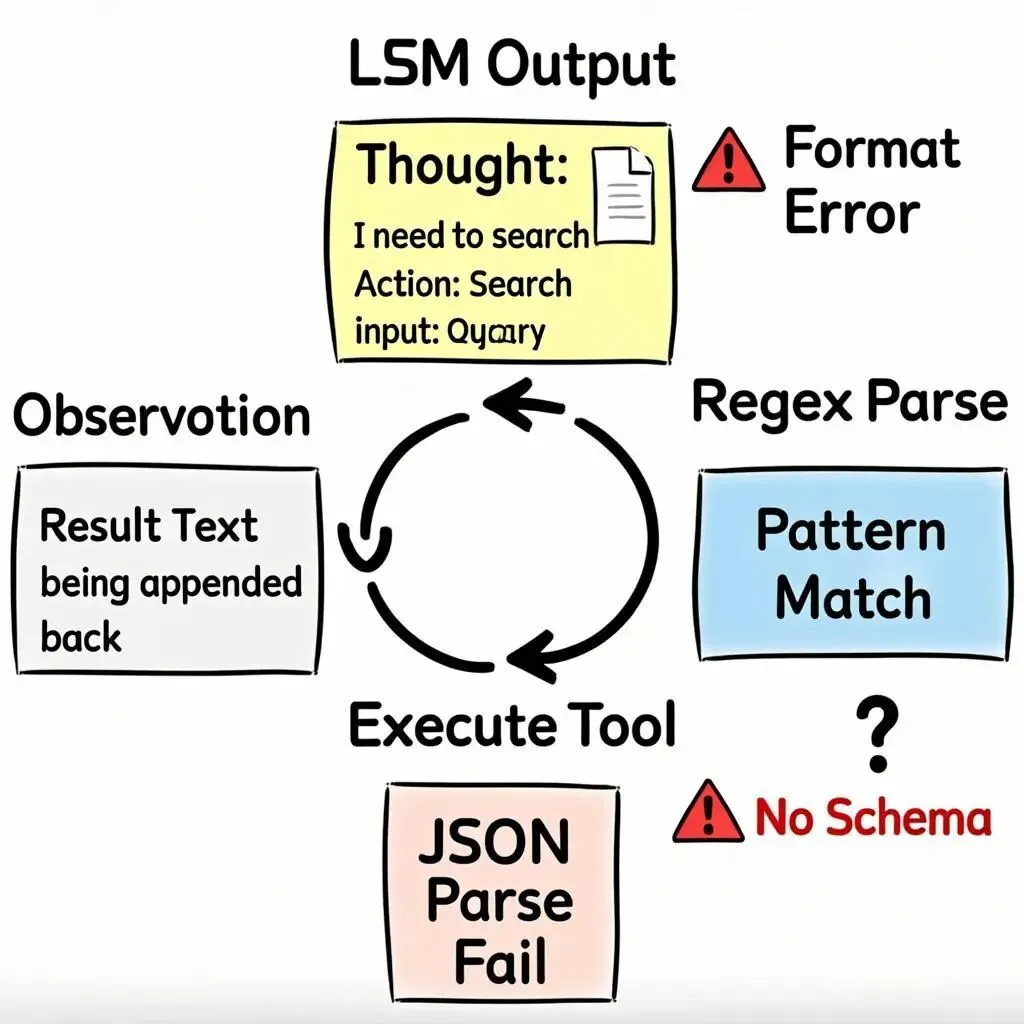
Question: 法国首都的人口是多少?Thought: 我需要先查出法国的首都是什么。Action: SearchAction Input: {"query": "法国首都"}Observation: 法国的首都是巴黎。Thought: 现在我需要查巴黎的人口。Action: SearchAction Input: {"query": "巴黎人口"}Observation: 巴黎人口约216万。Thought: 我现在知道最终答案了。Final Answer: 法国的首都是巴黎,人口约216万。Agent框架的工作就是用正则表达式解析这段文本:匹配 Action: 提取工具名,匹配 Action Input: 提取参数,调用对应的Python函数,然后把结果填到 Observation: 后面,再把整个对话历史拼回去喂给LLM。(用正则解析LLM输出,并且不断循环“折腾”直到相关参数都填满。)
问题也很明显: LLM经常不按格式输出,JSON解析经常失败,参数类型全凭LLM心情。如果你2023年初用过LangChain的Agent,或者早期的dify,你会对ReAct"印象深刻"。得不断循环哄着AI,寄希望于N轮后其会“心情“不错返回正确得结果。
在当时,这是唯一的方法。LangChain的早期版本就是基于这个模式构建的,用一个while循环不断调用LLM、解析文本、执行工具、回传结果,直到LLM输出 Final Answer。
第二章:API原生支持,LLM厂商下场做标准化(2023)
OpenAI:从functions到tools的三级跳
2023年6月,OpenAI做了一个开创性的决定:在API层面原生支持函数调用,不再依赖提示词和文本解析。
对的,这就是post‑training。
阶段一:functions参数(2023年6月,已废弃)
关键变化是:判断"是否需要调用工具"的决策权,从Agent框架的提示词解析转移到了LLM自身。以前Agent需要在提示词里写"你应该先思考再行动",然后用正则去猜LLM想不想调工具;现在LLM原生就能输出结构化的工具调用意图。
完整的交互时序如下:
- Agent注册工具
Agent在请求中通过 functions参数,把可用工具的名称、描述、参数schema告诉LLM,相当于给LLM一本"能力菜单" - LLM自主判断
LLM收到用户消息 + 工具列表后,自己决定要不要调用工具、调哪个、参数是什么。 function_call: "auto"表示让LLM自动判断(也可设为"none"强制不调,或指定函数名强制调用) - LLM返回工具调用指令
如果LLM判断需要调工具,它不再返回文本,而是返回结构化的 function_call对象(包含函数名和参数) - Agent执行工具
Agent收到LLM的工具调用指令后,在本地执行对应的函数(如调用天气API) - Agent回传结果
Agent把工具执行结果以 role: "function"消息回传给LLM - LLM生成最终回复
LLM结合工具返回的结果,生成给用户的自然语言回复
所以,"Agent知道要调工具"并不是Agent自己判断的,而是LLM判断后告诉Agent的。Agent更像一个"执行者",负责注册工具、执行LLM指定的调用、把结果送回去,而"何时调、调什么"的决策是LLM做的。
请求格式:
{ "model": "gpt-4-0613", "messages": [ {"role": "user", "content": "北京天气如何?"} ], "functions": [ { "name": "get_weather", "description": "查询指定城市的天气", "parameters": { "type": "object", "properties": { "location": {"type": "string", "description": "城市名"}, "unit": {"type": "string", "enum": ["celsius", "fahrenheit"]} }, "required": ["location"] } } ], "function_call": "auto"}LLM的响应变成了结构化的JSON:
{ "choices": [{ "message": { "role": "assistant", "content":null, "function_call": { "name": "get_weather", "arguments": "{\"location\": \"北京\"}" } }, "finish_reason": "function_call" }]}Agent框架不再需要正则匹配了,直接json 读 function_call.name 和 function_call.arguments 就行。但 function_call 是一个对象而非数组,每次只能调用一个函数。
工具执行完,结果通过新的消息角色回传:
{"role": "function", "name": "get_weather", "content": "{\"temperature\": 28, \"condition\": \"晴\"}"}阶段二:tools参数(2023年11月,当前主流格式)
OpenAI很快意识到单次调用的限制,推出了 tools 参数替代 functions:
{ "model": "gpt-4o", "messages": [{"role": "user", "content": "北京和东京的天气?"}], "tools": [ { "type": "function", "function": { "name": "get_weather", "description": "查询天气", "parameters": { "type": "object", "properties": { "location": {"type": "string"}, "unit": {"type": "string", "enum": ["celsius", "fahrenheit"]} }, "required": ["location"] } } } ], "tool_choice": "auto"}注意变化:工具定义被包在 {"type": "function", "function": {...}} 里(预留了其他类型工具的扩展空间),function_call 变成了 tool_choice。
响应中的调用也变成了数组:
{ "choices": [{ "message": { "role": "assistant", "content":null, "tool_calls": [ { "id": "call_001", "type": "function", "function": { "name": "get_weather", "arguments": "{\"location\": \"北京\"}" } }, { "id": "call_002", "type": "function", "function": { "name": "get_weather", "arguments": "{\"location\": \"东京\"}" } } ] }, "finish_reason": "tool_calls" }]}一次返回两个调用!Agent框架可以并行执行这两个查询,然后把结果分别通过 role: "tool" 消息回传:
{"role": "tool", "tool_call_id": "call_001", "content": "{\"temperature\": 28}"}{"role": "tool", "tool_call_id": "call_002", "content": "{\"temperature\": 22}"}tool_call_id 是关键,它让Agent框架能把结果精确匹配到对应的调用请求。
阶段三:Responses API(2025年,最新推荐格式)
2025年,OpenAI推出了全新的Responses API,工具调用格式进一步简化:
// 响应中的工具调用{ "output": [ { "type": "function_call", "call_id": "call_123", "name": "get_weather", "arguments": "{\"location\": \"北京\"}" } ]}// 结果回传{ "type": "function_call_output", "call_id": "call_123", "output": "{\"temperature\": 28}"}变化要点:不再用 role 区分消息类型,改用 type 字段;function_call_output 替代了 role: "tool";默认启用strict模式确保输出严格符合Schema。
说到这,大家感觉到了Agent LLM之间的协议“折腾”了吧。传言最近Claude Code升级最新版本后国内模型用不了,这也属于这种类型的“折腾”。当然,后者和今天谈的Tools之类无关,属于session架构的变化。
Anthropic Claude:content block的设计哲学
Anthropic走了一条不同的路。它没有用单独的 tool_calls 字段,而是把工具调用直接塞进content数组里,和文本内容混在一起:
{ "model": "claude-sonnet-4-20250514", "messages": [ {"role": "user", "content": "北京天气如何?"} ], "tools": [ { "name": "get_weather", "description": "查询天气", "input_schema": { "type": "object", "properties": { "location": {"type": "string"} }, "required": ["location"] } } ]}注意:Anthropic用 input_schema 而非 parameters,且工具定义没有外层的 type 包装。
LLM的响应:
{ "role": "assistant", "content": [ { "type": "text", "text": "我来帮你查一下北京的天气。" }, { "type": "tool_use", "id": "toolu_01A09q90qw90lq917835lq9", "name": "get_weather", "input": {"location": "北京"} } ], "stop_reason": "tool_use"}这个设计有个有意思的地方:文本和工具调用是同一个content数组里的元素。LLM可以先说一句"我来帮你查一下",紧接着输出工具调用,这更符合真实的对话流程。
另一个重要差异:input 是原生的JSON对象,不是字符串。OpenAI的 arguments 是JSON字符串需要 JSON.parse(),而Anthropic直接给你解析好的对象。(跨框架开发的时候,这个兼容处理经常坑人。)
结果回传更有意思,它用的是 role: "user" 而不是单独的角色:
{ "role": "user", "content": [ { "type": "tool_result", "tool_use_id": "toolu_01A09q90qw90lq917835lq9", "content": "{\"temperature\": 28, \"condition\": \"晴\"}" } ]}Google Gemini:又一派风格
Google的方案用 functionDeclarations 定义工具,响应里用 functionCall / functionResponse,参数也是原生对象(和Anthropic一样不需要parse)。格式上比较接近OpenAPI风格,有兴趣的可以去查官方文档,这里就不展开了。
第三章:Agent框架的编排艺术
理解了LLM层面的数据格式之后,来看看Agent框架是怎么把这些串起来的。
核心循环:The Agentic Loop
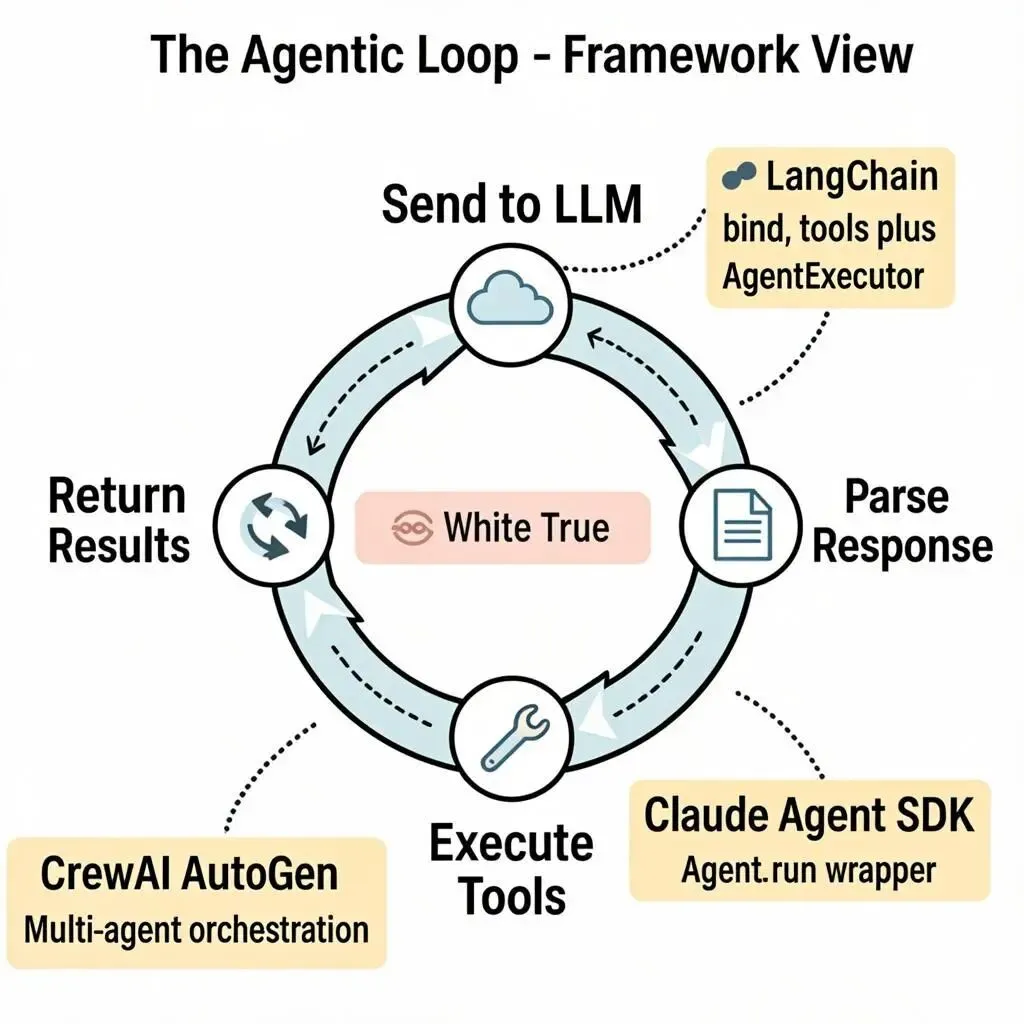
不管哪个框架,核心都是同一个模式:一个while循环。
# 伪代码:所有Agent框架的本质messages = [{"role": "user", "content": user_request}]tools = [get_weather, send_email, search_web]while True: # 1. 把当前对话历史 + 工具定义发给LLM response = llm.chat(messages=messages, tools=tool_definitions) # 2. 检查LLM是想回复文本还是调用工具 if response.has_tool_calls(): # 3. 解析并执行每个工具调用 for tool_call in response.tool_calls: result = execute_tool(tool_call.name, tool_call.arguments) # 4. 把结果回传给LLM messages.append(tool_result_message(tool_call.id, result)) # 继续循环,让LLM看到结果后决定下一步 continue else: # LLM输出了最终文本回复 print(response.content) break这段伪代码揭示了Agent的本质:LLM是大脑,Agent框架是身体。大脑决定做什么,身体去执行,然后把感知反馈给大脑,大脑再决定下一步。
下次你看到某个AI Agent"自动"完成了一串操作,拆开来看,其实就是这个循环在反复跑。
LangChain的实现:从文本解析到bind_tools
LangChain是早期最流行的Agent框架,它的演进很好地映射了整个行业的变化。
早期(2023年初):基于ReAct的文本解析
LangChain的 initialize_agent(agent="zero-shot-react-description") 本质上就是:把ReAct提示词模板和工具描述拼成一个超长的prompt,然后用正则解析LLM的文本输出。
# LangChain早期的ReAct Agent内部逻辑(简化)prompt = f"""你可以使用以下工具:{format_tools(tool_list)}请按以下格式回答:Question: {user_input}Thought: ...Action: ...Action Input: ...Observation: ..."""llm_output = llm(prompt)# 用正则提取Action和Action Inputmatch = re.search(r"Action:\s*(.+)\nAction Input:\s*(.+)", llm_output)现在(2024-2025):bind_tools + 结构化输出
from langchain_openai import ChatOpenAIfrom langchain_core.tools import tool@tooldef get_weather(location: str, unit: str = "celsius") -> str: """查询指定城市的天气""" # 实际调用天气API return f"{location}当前温度28°C,晴"# bind_tools自动把Python函数转为JSON Schemallm = ChatOpenAI(model="gpt-4o").bind_tools([get_weather])# Agent循环result = llm.invoke([HumanMessage(content="北京天气如何?")])if result.tool_calls: for tool_call in result.tool_calls: # tool_call已经是结构化的字典,无需正则 tool_output = get_weather.invoke(tool_call["args"]) # 回传结果 ...bind_tools 内部做了什么?它把Python函数的签名、docstring、类型注解自动转成LLM能理解的JSON Schema,然后通过API的 tools 参数传给模型。这比手动写提示词模板可靠得多。
Anthropic官方SDK:直接用tool_use API
Anthropic目前的做法是直接在官方Python SDK里支持tool_use,不需要额外的Agent框架包。代码比想象中简洁:
import anthropicclient = anthropic.Anthropic()# 第一步:发送请求,带上工具定义response = client.messages.create( model="claude-sonnet-4-20250514", messages=[{"role": "user", "content": "北京天气如何?"}], tools=[{ "name": "get_weather", "description": "查询天气", "input_schema": { "type": "object", "properties": {"location": {"type": "string"}}, "required": ["location"] } }])# 第二步:检查响应里有没有tool_usefor block in response.content: if block.type == "tool_use": result = get_weather(**block.input) # 直接拿到字典,不用JSON.parse # 第三步:把结果回传,继续对话...注意看,block.input 直接就是Python字典,不需要像OpenAI那样先 JSON.parse 一下。这个设计细节在实际开发中省了不少麻烦。
Claude Code CLI则走得更远。它是一个具有系统提示、多工具注册、子代理委派能力的完整Agent运行时。当你在终端运行Claude Code时,它的核心循环是这样的:
读取你的输入 + 系统提示 + 工具列表 → 调用Claude API 解析响应中的 tool_usecontent block执行对应工具(读文件、写文件、运行命令等) 将 tool_result回传 → 继续循环直到 stop_reason不是tool_use
CrewAI、AutoGen:多Agent协作
CrewAI和AutoGen则把单Agent循环扩展到了多Agent协作:
• CrewAI:定义多个角色(Researcher、Writer、Reviewer),每个角色有自己的工具集,按流程串联执行 • AutoGen:多个Agent之间通过消息传递进行对话式协作,每个Agent有自己的工具和LLM
但底层仍然是同一个模式:LLM决定调用工具,执行,回传结果,再决策。
第四章:数据格式的变迁,一张图看懂三代演进
我把三个主要厂商的工具调用格式演进总结成了一张对比表:
| 工具定义方式 | tools | tools | functionDeclarations | |
| Schema字段名 | parameters | input_schema | parameters | |
| LLM返回格式 | Action: xxx | tool_calls 数组 | contenttool_use 块 | functionCall |
| 参数格式 | ||||
| 并行调用 | ||||
| 结果回传 | Observation: | role: "tool" | role: "user"tool_result | functionResponse |
| 调用标识 | tool_call_id | tool_use_id | ||
| 可靠性 |
一个容易忽视的细节:参数是字符串还是对象?
这个细节在跨框架开发时经常坑人:
• OpenAI返回的 arguments是一个JSON字符串,你必须JSON.parse()才能拿到实际参数• Anthropic返回的 input是原生JavaScript/Python对象,直接用就行• Google Gemini返回的 args也是原生对象
这意味着如果要写一个跨LLM Provider的Agent框架,在解析参数时就得做兼容处理。
第五章:从技术到产品,为什么这个机制如此重要
LLM不执行,只决策
理解了上面的技术细节后,一个关键点浮现出来:LLM从来不直接执行任何工具。
它做的全部事情就是:
看到用户请求和可用工具列表 输出一个结构化的"我想调用这个工具,参数是这些" 看到工具执行结果后,决定下一步做什么
Agent框架负责:解析LLM的意图,调用实际函数,把结果格式化回传,维护对话历史
这个分工很关键。它意味着LLM的安全性边界是可控的——LLM只能"请求"使用你给它的工具,不能越权。你可以审查每一个工具调用请求,决定是否执行。
MCP:工具调用的标准化未来
2024年底,Anthropic推出了MCP(Model Context Protocol),试图解决一个更大的问题:不同应用、不同LLM之间的工具调用标准不统一。
MCP定义了统一的工具发现、执行和结果返回协议。2025年12月,Anthropic将MCP捐赠给了Linux基金会旗下的Agentic AI Foundation,由多家厂商共同治理,正式成为行业标准。这意味着未来Agent调用工具可能不再需要为每个LLM Provider写不同的适配代码。
本质没有变
从ReAct的文本正则解析,到OpenAI的结构化function calling,再到Anthropic的content block设计和MCP的标准化尝试,Agent与LLM的工具调用机制进步很大。
但本质没变:LLM是大脑,Agent框架是手,工具调用是大脑对手发出的指令。变的是指令的精确度。
理解了这个机制,一些现象就说得通了:为什么AI Agent有时会"幻觉"调用不存在的工具(LLM的决策失误),为什么LangChain的ReAct Agent经常失败而原生function calling的Agent更稳定(结构化 vs 文本解析)。
下次你让ChatGPT帮你查天气的时候,可以想想:是LLM决定了调工具,还是Agent框架?相信到这里,答案你已经知道了。
