 夜雨聆风
夜雨聆风2026 年,光是叫得上名字的 AI 工具就超过一万七千个。你一天能认真评估几个?一个?两个?三个?过了三个,后面全是名字。
与此同时,Harvard Business Review 记录了一种叫「AI brain fry」的现象——长期被 AI 工具信息轰炸导致的脑雾、注意力涣散。你不是不够努力,是你的大脑在设计上就没打算处理这么大量的输入。
这两件事之间有一条被大多数人跳过的因果链:AI 让获取变便宜了,但让判断变贵了。
几年前,用 AI 的门槛在获取端——你得学 Python、搭环境、找 API key。现在开源模型能跑、免费模板能抄、零代码平台拖节点就能搭。获取不再是问题。但每天几十个新工具上线,每个都说自己是「最先进的」「一键生成」「十倍效率」。谁来替你判断?你自己。
AI 让你能做的事变多了,但值得做的事不会跟着变多。筛选比获取值钱。
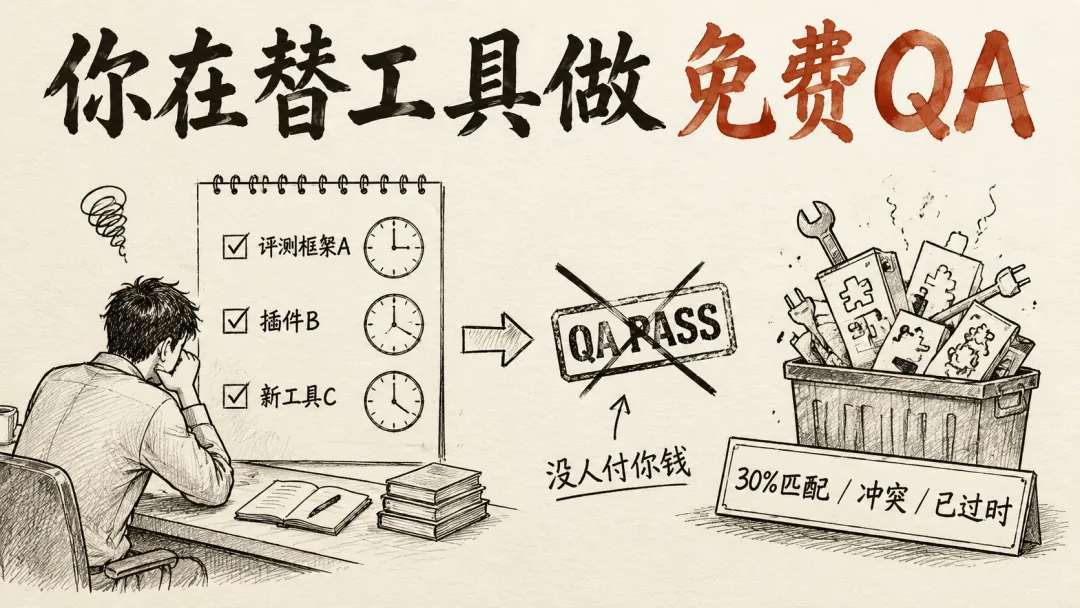
你以为在追新工具,其实在给工具做免费的 QA
37%。这是 2026 年实验室 benchmark 分数和真实部署表现之间的平均差距。传统评测基准早就饱和了。MMLU 上所有前沿模型都 88% 以上,区分不了。但你把同一个「评测第一名」的模型扔到你自己的场景里,效果能差出两个档次。
这 37% 的差距,是谁在填?是你。
每次你花三个晚上评测一个新 agent 框架、每次你把群里分享的「prompt 技巧」复制进自己的项目里试一遍、每次你在 Coze 里装新插件然后发现把稳定环境搞崩。你都在免费给这个工具做质量保证。没人付你钱。
三种人,对号入座:
A · 自配 agent 党。你已经搭了几套 agent,用着 Claude Code、Cursor、自己写的小脚本。但每天 X 和群里又出新 prompt、新 skill、新框架:LangGraph 刚搞懂,Google 又出 ADK;MCP 协议还在学,社区又推 A2A。你花了三个晚上评测一个新框架,结论是跟你的场景只有 30% 重合。浪费的不是技术能力,是判断时间。
B · 借 skill 片段党。你用 Cursor 或 Claude Code 的,别人分享 CLAUDE.md 和 rules 文件你就收藏。文件夹里存了几十个.cursorrules、上百条「prompt 技巧」、十几个「最佳实践」。但你从没系统评估过:哪些规则互相冲突?哪些在你的模型版本上已经不适用?你的 prompt 越来越长,不是因为你需要,是因为你不知道能删哪个。
C · 开源开箱即用党。你用 Dify、Coze、n8n 搭了自动化工作流,跑得挺稳。但社区每周上新插件:这周出个「知识库 RAG 插件」,下周出个「多模态理解插件」,再下周出个「代码执行沙箱」。每次看到都纠结:装怕把稳定环境搞崩,不装怕落后。结果都不敢动,但心里觉得自己在「原地踏步」。
三种人的共同点:不是缺工具,是缺一个「替我判断这个东西在我的场景下有没有用」的机制。
每个排行榜都在减少你的选择焦虑——但没人告诉你,那个让你不焦虑的工具,下周就可能被替代。
从「收藏夹」到「防火墙」——中间差一个 Harness
我写过一个 harness 系列,前三篇都在讲怎么搭:怎么拆 skill、怎么设 gate、怎么写 state。那是生产侧:让 AI 替你干活。
这一篇讲的是消费侧:让 AI 帮你判断「什么值得用」。
区别在哪?生产侧的 harness 帮你做东西:选题、写稿、核查、配图、发布。消费侧的 harness 帮你筛东西:新工具能不能进你的工作流、新 skill 跟现有规则冲突还是互补、现有工具升级后会不会把你的稳定环境搞崩。
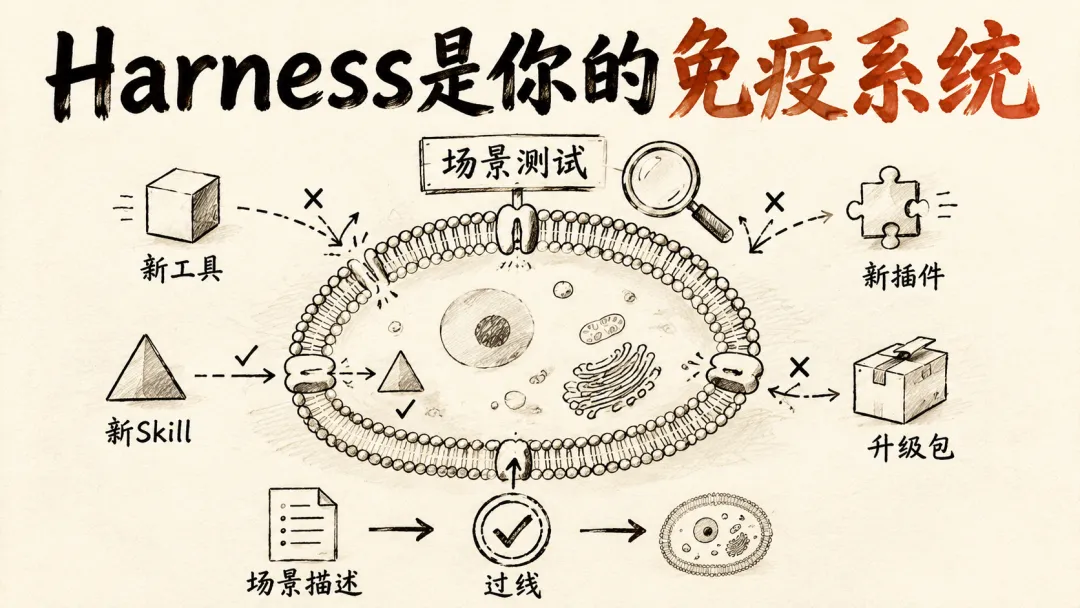
一个画面:你的 AI 工具生态是你的身体,消费侧 harness 是你的免疫系统。它不负责「让你更强壮」,它负责「识别进来的东西是有益的还是有害的」。没有免疫系统的人,随便一个病毒就能击穿整个身体。
你现在可能已经过了「我不用 AI」的阶段,但大概率还在「我用的 AI 没被筛选过」的阶段。
不是你不用 AI,是你用的 AI 没被筛选过。你没时间每天测三个新工具。但你的 harness 可以。
通用评测测的是「别人」,你的事只有你知道
为什么不直接看评测和排行榜?
评测在「理想条件下」做,但你的约束是只属于你的。你用什么模型、什么技术栈、什么预算、什么数据隐私要求、什么语言、什么行业——这六个变量排列组合,没有一个公开评测能覆盖。
社区推荐的时效问题更致命。今天推荐的前三名 agent 框架,两个月后就换了一遍。推荐是有时效的,但你的需求是持续的。你照着三个月前的推荐搭了一套,今天可能已经在用一套「过时的最优选」。
企业可以买「统一的 AI 平台」让供应商替你筛选,但个体创作者、独立开发者、副业经营者没有这个预算。你只能自己筛——而大多数人选择不筛,直接用。后果是:你的工作流里挂了三四个互相打架的 skill 文件、两个已经过时的插件、一个升级后就没跑通过的自动化节点。不是你不够勤快,是你没有工具做这件事。
反共识:真正的差距已经从「谁有 AI」变成了「谁有筛选 AI 的 AI」。AI 民主化让大家都上了车,但有人拿着导航,有人闭着眼睛踩油门。
通用评测告诉你「这个工具对你这类人有用」。你自己的 harness 告诉你「这个工具对你,在现在,在这个项目上,有用/没用/用了会崩」。
你的筛选 Harness,不需要写代码
听到「搭一个 harness」,你脑子里蹦出来的第一画面是不是终端、配置文件、脚本、调试?停下来。
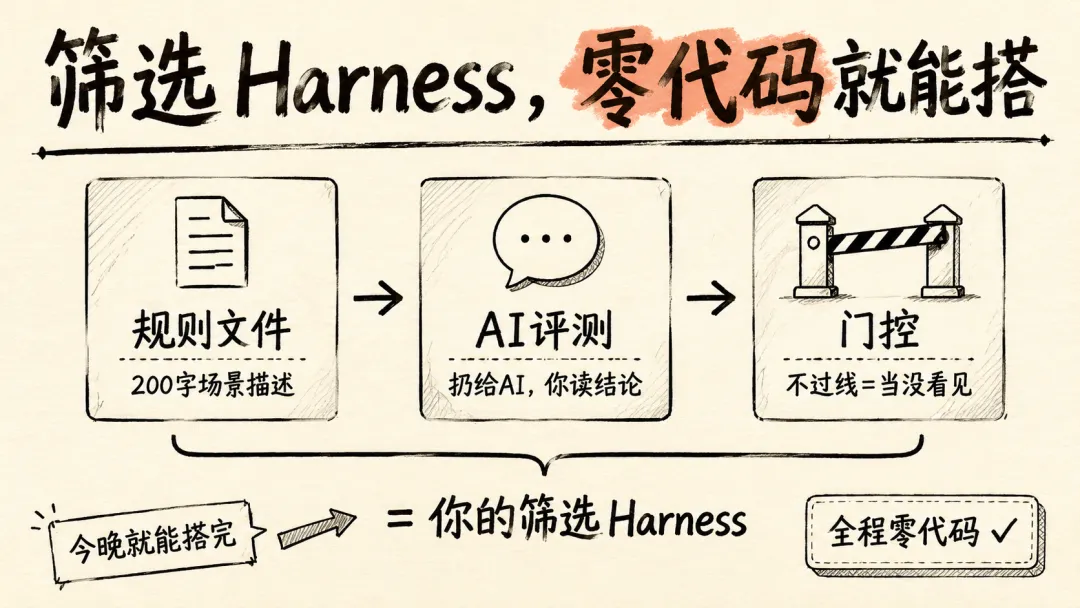
那是生产侧的 harness。筛选侧的 harness,最小版本只有三样东西。没有 YAML、没有 JSON schema、没有一行代码。全是文字。
第一样:规则文件。就是一段话,写清楚你自己的场景。用什么模型、什么工具链、什么约束、什么不能碰。两三百字,写完存着。这就是你的「场景指纹」——以后所有判断都拿它当尺子。
第二样:AI 替你跑的评测。以前新工具出来你怎么做?收藏、点星、想着周末试,然后周末过去了,什么都没试。现在不一样。下周 X 上刷到一个「革命性的 agent 框架」,不用点开研究。把它的说明页链接扔给 AI,附上你的场景描述,加上一句:「在我的场景下,这东西排第几?跟现有工具冲突还是互补?值不值得花时间?」30 秒后,AI 读完告诉你结论。看完结论,关掉页面。一个晚上都没浪费。全程你一行代码都没写——AI 读了、AI 对了、AI 回了。你是读结论的那个人。
第三样:门控。规则就一条:没通过你场景测试的,不进你的生产链路。不管多少人推荐、不管评测打几分,在你自己的场景下跑通才算数。
一个完整的画面:新工具上线 → 扔场景描述 + 工具说明给 AI → AI 告诉你它在你的场景下排第几、跟现有工具冲突还是互补 → 过线就进待测试池,不过线就当没看见。全程零代码。不是「搭系统」,是「建立你自己的判断框架」。系统会过时,判断框架不会。
三件事,今晚就做完
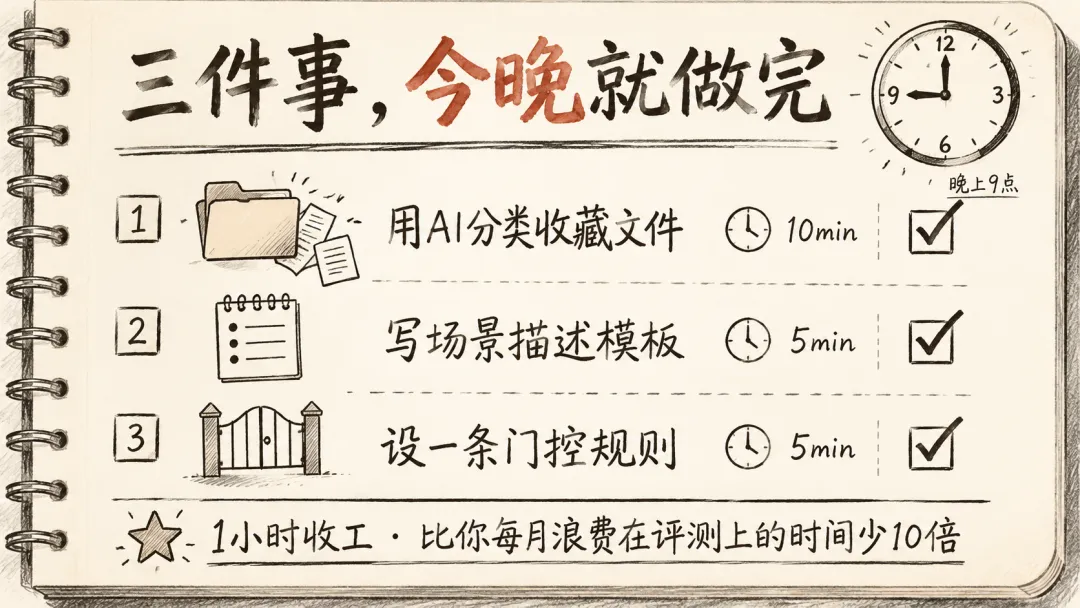
别等到周末。今晚,三件事,每件不超过 20 分钟,一个小时收工。每条都有具体指令和预期产出,照着做就行。
第一件:用 AI 分类你收藏的所有文件。把你收藏夹里的 CLAUDE.md、rules、skill 片段、prompt 技巧——一个文件夹全粘给 AI。指令复制这句:「标出哪些是我实际在用的、哪些是存着从没用过的、哪些互相冲突。」预期产出:一张三列表,清清楚楚。你不是缺规则,你是不知道哪些规则在背后互相抵消。10 分钟。
第二件:写你的场景描述模板。就三句话。第一句:你现在用什么模型,型号加调用方式。第二句:你的工具链,IDE、平台、自动化节点。第三句:你的约束,预算、数据隐私、语言、场景类型。整段不超过 200 字,写完存一个文件叫my-scene.md。预期产出:一个随时能扔给 AI 的场景描述。下次任何新工具出现,把它粘上去,加一句「在我的场景下排第几」,回车。5 分钟。
第三件:设一条不可商量的门控规则。就一句话,抄下来存进你的工作文件夹:「新工具不通过我的场景测试,不进我的生产链路。」删都别删。预期产出:一条写死的规则。下次任何新工具出来,第一反应不是「要不要试试」,是「让它先跑场景测试」。5 分钟。
这三件事做完,你花了一个小时。你每个月浪费在无效工具评测上的时间,远超这个数。但你每年都在做后者。
参考来源:
「AI brain fry」2026-03 → Harvard Business Review(morphllm.com 引用) 17,000+ AI 工具 2026 市场扫描 → 行业估算(whatif-ai.com 收录) 80% 生产力焦虑 / $1T 抑郁焦虑损失 → Forbes 2024 / WHO 37% benchmark 与真实部署差距 2026 → kili-technology.com
