 夜雨聆风
夜雨聆风阅前提示:本文的所有信息仅供用户作为研究参考,不构成任何投资建议或交易依据。所有投资决策均由用户自行作出并承担全部风险。投资有风险,入市需谨慎。
咱们在第一篇文章中拆解了应用层当前面临的变现困境,指出一些能够拥抱AI的软件股会出现困境反转式的上涨。从上下文和工作流的角度来说,像Snowflake, ServiceNow和Atlassian这样的公司开始拥抱AI后会有很好的资产重估。聊完今天这篇,可能会让大家对微软有新的看法,我们长长高估短期而低估了长期,特别是在变革如此迅速的时代。
有个玩笑是:AI变化如此之快,现在不学过3个月发现新东西已经出来了,当时其实不用学。当然换个角度,这也说明任何时候开始拥抱AI都不晚。
第二篇模型层中我们提到模型层正在被寄予厚望,能不能在B端打开局面,能不能保持惊人的营收增长决定了模型层能不能从基建层接棒,成为整个AI叙事下阶段的主要资金来源。目前看还有不确定性和非共识。
今天咱们聊基建层,是当前几乎一切AI叙事开支的源头(除了VC之外),也是接下来模型层真正崛起之后反哺的对象。
基建层(Infrastructure Layer):云计算巨头(Hyperscaler)的自建数据中心、新型云服务商(Neocloud)的算力租赁,以及数据中心托管方(Colocation)。
放眼 2026 年,这 5 家头部科技巨头的资本支出(Capex)合计将达到 7350 亿至 7700 亿美元(我们取中值7500亿美元)。这是 2026 年全球单一最大宗的资本支出所在地,它不仅是人类历史上最夸张的基建狂潮,更是资金从“模型层”流向“芯片层”与“能源层”的核心中转站。
但比“这笔钱有多庞大”更致命、也更需要穿透财务迷雾去回答的问题是:
谁能在这场烧钱大战中保住利润?
谁会被这座大山压垮?
这笔钱有没有真正转化为账面上的收入?
而资本市场和普通居民,最终又会以怎样的方式来承接这些被转嫁的风险?
双重因子决定巨头命运
我们首先需要把这7500 亿的账本彻底拆开。以下是5 家公司 2026 年全年的资本支出(Capex)完整拆分:
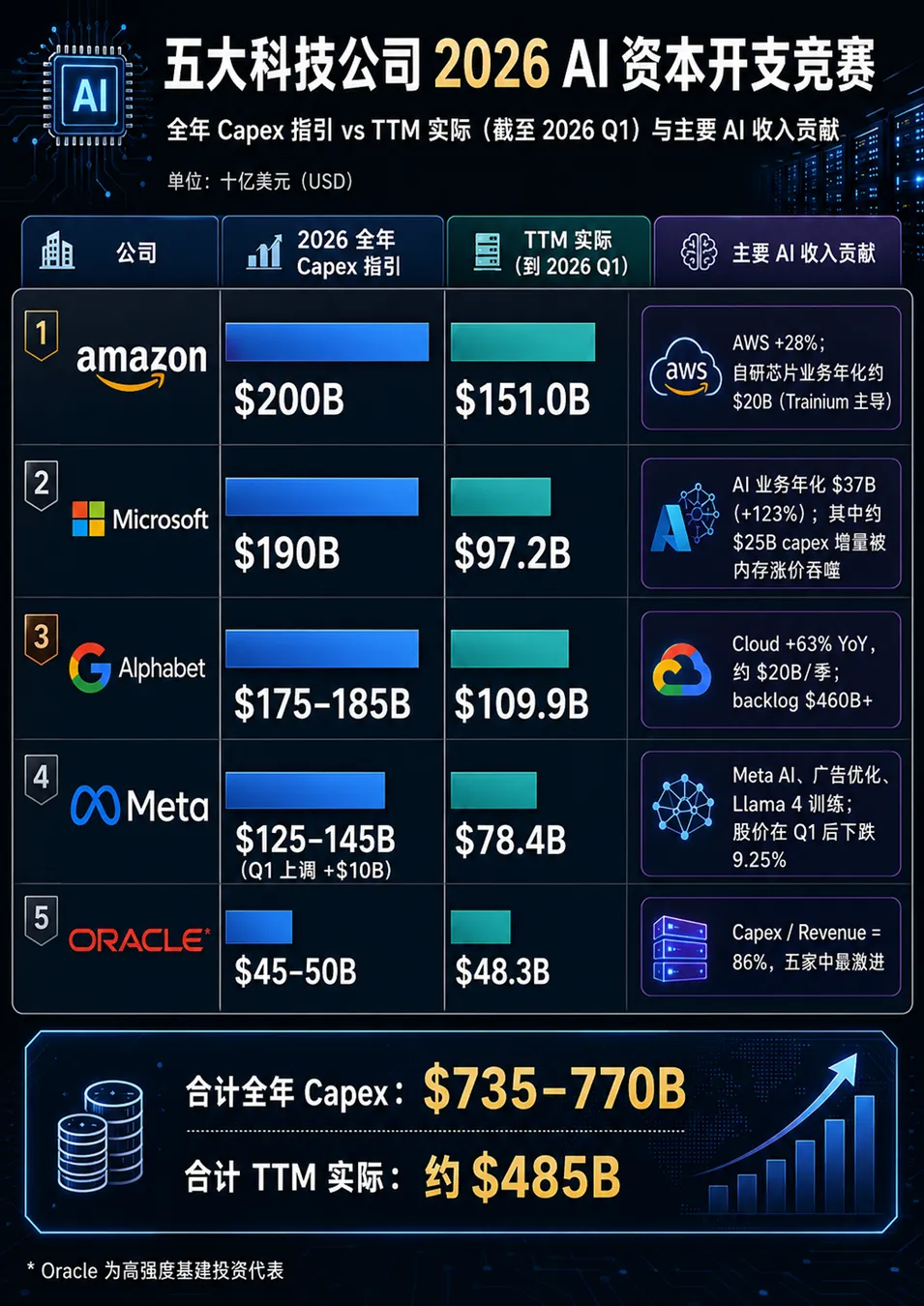
(注:甲骨文的财年到2026年5月31日结束,其 FY26 的开支已基本完成,而其他 4 家是日历年,下半年还有巨额开销。)
两个关键的商业观察:
第一,供应链倒逼带来的非AI支出。
正如上表所示,微软那庞大的增量资本支出中,有高达250 亿美元纯粹是因为内存涨价而被迫吞下的成本,这是其 CFO Hood 在 Q3 财报电话会上明确承认的。这部分钱并没有转化为更多的 AI 算力。其背后的传导链条是:云计算巨头们在今年 3-4 月被迫统一签了内存长约,锁死了未来 3 年的极高价格,导致后续几个季度的资本支出都被迫跟着向上调。
第二,没有外部云业务的特殊反噬。
巴克莱银行在 Q1 财报后给出一份悲观预测:Meta 全年的自由现金流(FCF)将同比暴跌约90%。因为极其夸张的资本支出彻底推高了成本。一季度财报后 Meta 股价大跌 9.25%,其真实原因并非其自研 ASIC 技术落后,而是因为 Meta 根本不卖云服务。
这意味着,它所有的巨额算力投入,全部只能由内部业务去消化。以前,Meta还能靠大规模裁员来抵消运营开支(OPEX)的增长,但到了 2026 年,裁员空间已经见底。没有外部云客户来分摊成本,这家公司的特殊财务压力将达到顶峰。
如果我们对比一下SaaS 的黄金时代(2015-2021),云计算巨头的资本密度(资本支出占收入的比例)通常在 10-12% 之间,纯 SaaS 公司更是低至 2-6%。而现在呢?亚马逊达到了 25%,谷歌 46%,微软 47%,Meta 54%,而甲骨文更是极其极端的 86%。这是 5 到 10 倍于历史正常水平的疯狂。
谁能保利润,谁会被碾压?
在这场史无前例的烧钱大战中,各家巨头的命运不再由单纯的口号决定,而是被基本面牢牢绑定:
因子 1(主导轴):自研ASIC 芯片的进度。这直接决定了该巨头长期脱离英伟达“剥削”的能力,决定了长期的利润率路径。 因子2(辅助轴):现金流强度。这决定了在AI 真正产生巨额利润之前,它能不能靠厚实的家底抗住短期的资本支出压力。
坦白说,这两个因子并不完全独立。长期的强ASIC 能力会带来强现金流,而弱ASIC 则注定长期被英伟达抽走利润。所以,这个生存矩阵真正描述的是一条“主对角线”以及两个例外:
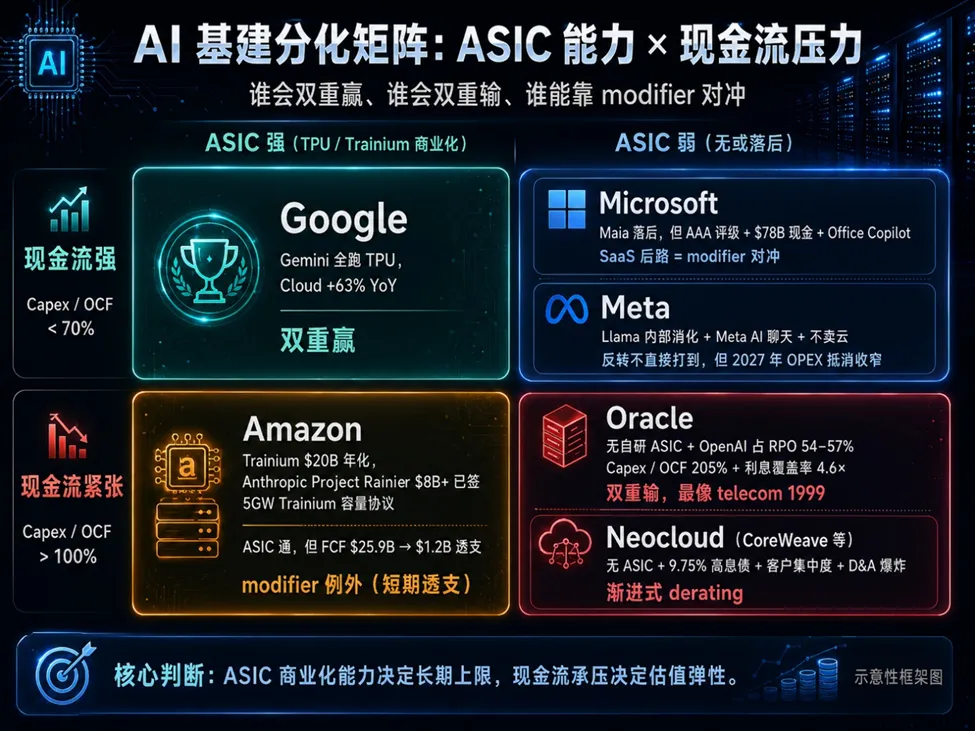
【现金流强×ASIC强】谷歌(基建层双重赢家):谷歌是最大赢家。它的Gemini已经全面跑在自研的TPU 上,实现了算力闭环。直接结果是,谷歌云业务实现了63% 的恐怖同比增速,手中握着超过4600 亿美元的在手订单Backlog),双重红利吃尽。Gemini的落后是暂时的。 【现金流强× ASIC弱】微软与 Meta(老本对冲):微软的自研芯片Maia进度落后,但它拥有极其稀缺的AAA级主权信用评级、账上趴着780亿美元现金,加上Office Copilot带来的SaaS后路,形成了完美的现金流对冲。Meta靠着聊天机器人和极强的内部广告变现,依然能稳住阵脚。但这种“硬扛”的代价已经开始显现:微软云的毛利率连续三个季度被残酷压缩(从69% 跌到66%),这是模型公司挤压公有云的最早财务信号。另外必须警惕的是,模型层一定要做AI OS系统,这是继“卖Token”,到“卖工作流”之后必然的下一步,否则无法真正拥有定价权。对于Windows来说将是一个核心冲击。 - 【现金流紧张×ASIC强】亚马逊(辅助轴例外,短期透支):亚马逊的自研芯片Trainium 已经跑通并实现了商业化(贡献200 亿年化收入),甚至签下了Anthropic Project Rainier 的80 亿大单和5GW 的容量协议。它的ASIC 是通关的,但代价惨烈:自由现金流暴跌至12 亿美元左右,短期透支极其严重。不过一旦挺过来,将和老牌的AWS一起成为对标谷歌的AI时代巨头。
- 【现金流紧张× ASIC 弱】甲骨文与新型云(危险的赌徒,双重输):甲骨文没有任何自研ASIC,极其过度依赖OpenAI(占其RPO 订单的54-57%)。它的资本支出是运营现金流的205%,利息覆盖率跌至4.6 倍。CoreWeave等新型云同样如此,没有自研芯片,背负9.75% 的高息债,客户集中度极高,折旧爆炸。它们正在经历渐进式的估值降级。
(注:在这个矩阵中没有英伟达。因为它早已横跨基建层,不仅仅是个卖芯片的。2025年底以 200 亿收购 Groq 进军推理芯片,Q4 财报网络收入同比暴涨 263%。英伟达如今面临的唯一真正威胁,是 Intel、AMD、谷歌、Meta、微软组成的 UALink 联盟对其 NVLink 标准的首次挑战。)
AI 到底有没有真的在挣钱?
这是基建层最值得问的灵魂拷问。钱花了这么多,物理现实中到底有没有对应的收入转化?答案是两极分化的。
好消息是:头部玩家的真金白银确实到账了,而且转化在加速。
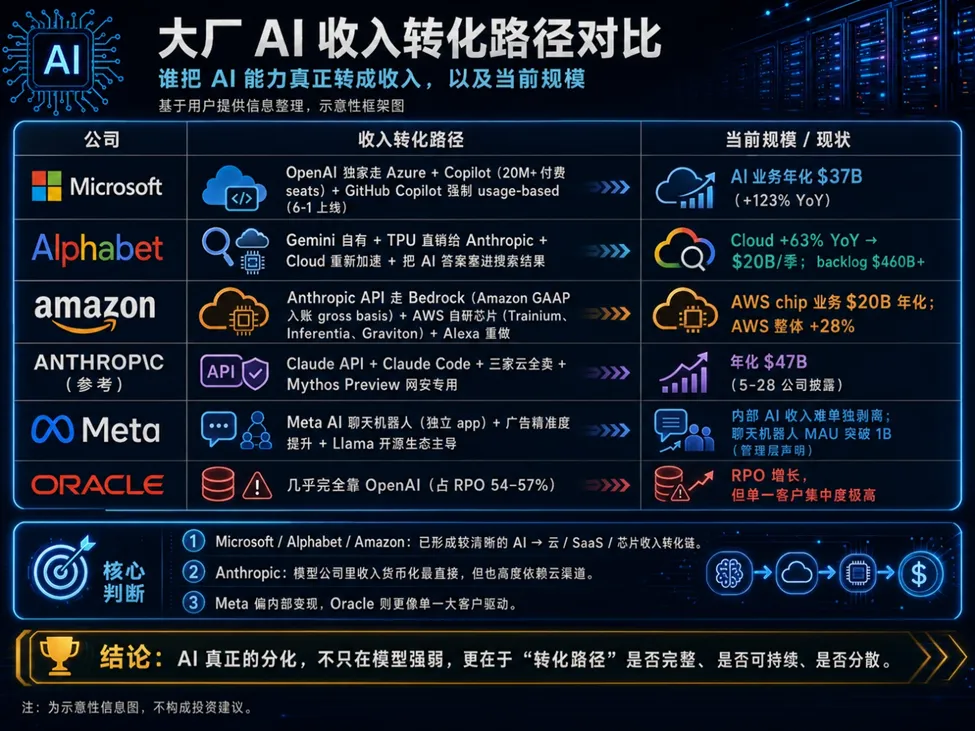
如上图所示,截至2026 年 Q1 末,这几家的 AI 相关年化收入合计已经接近 2000 亿美元;预计到今年年底,有望站稳 1600 到 2500 亿的区间。
坏消息是:对比7500 亿的投入,窟窿依然是个无底洞。
假设 7500 亿的资本支出中,有 60-70% 是纯 AI 相关的,那单年的 AI 基建支出就在 4500-5250 亿。如果我们拉长到 4 年期(2026-2029),假设支出和收入都在同步增长,总投入将达到 2-3 万亿美元,而总收入仅为 1.3-2 万亿美元。
4 年期的累计覆盖率(Cover Ratio)只有 50-70%。这意味着剩下的 30-50%,必须由目前还看不见摸不着的企业级应用大爆发、Agentic 智能体工作流来硬性填补。这也是当下整个科技圈最大的赌注。
狂飙的债务与现金流压力
由于窟窿太大,科技巨头们在2026 年开启了疯狂的“借钱模式”。我们正站在从“资本开支周期”向“资本开支信用周期”演变的悬崖边缘。
让我们看一组基于美国证券交易委员会(SEC)10-Q 文件的真实数据:
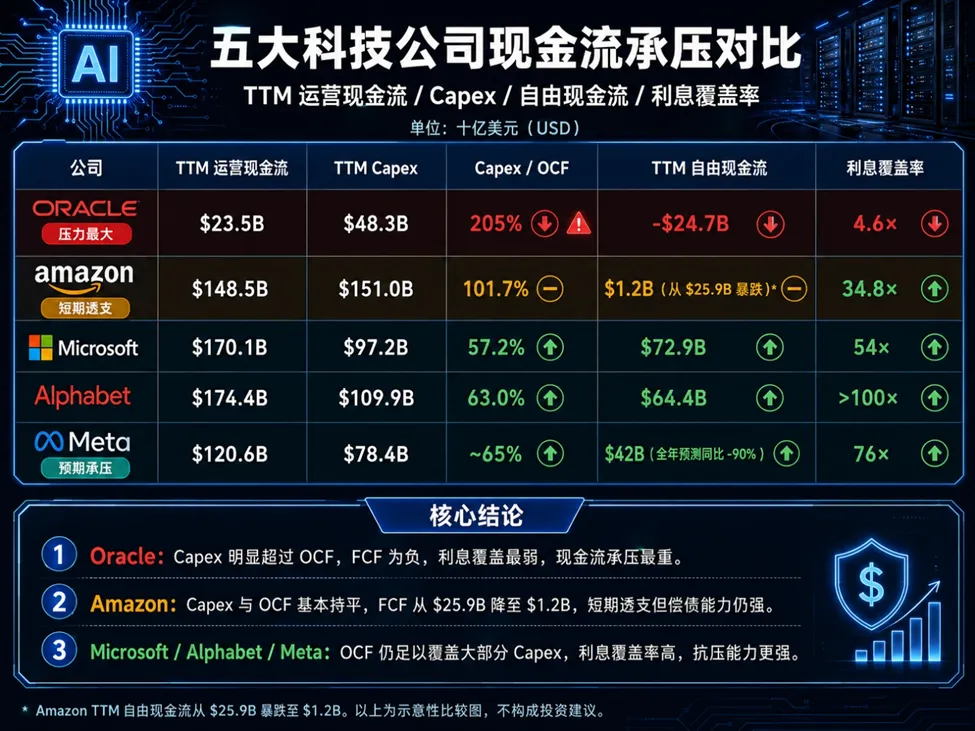
两极分化。
更为标志性的事件是,发债的大幕已经全面拉开。
2020-2024 年,这5 家巨头平均每年发债仅280 亿美元。但仅仅到了2026 年前 5 个月,发债额就已经狂飙:
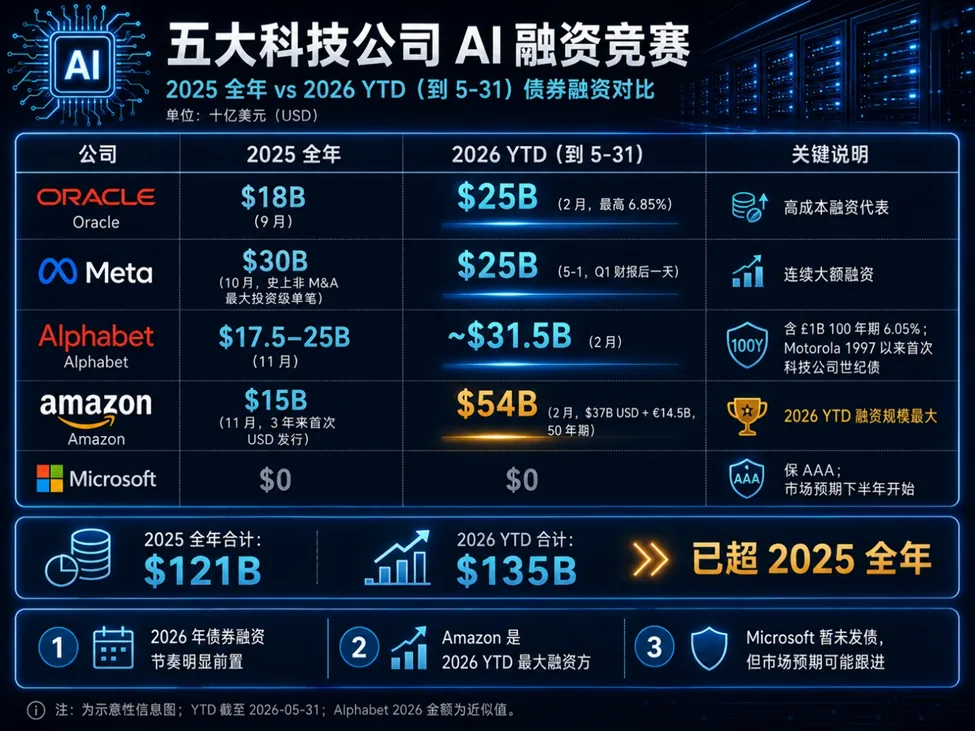
合计下来,2026 年前 5 个月(1350 亿)的发债总额,已经超越了 2025 年全年(1210 亿)的总和。
值得注意的是,5 家巨头中唯独微软在 2025-2026 年至今保持了零美元的债券发行,这是它顶级 AAA 评级和账上 780 亿现金的真实体现。但华尔街普遍预计这种克制难以持久,摩根士丹利预测 2026年 5 家总发债额可能突破 4000 亿美元,微软不发债的纪录大概率将在下半年终结。
GPU 利用率的真相:别当外行
在这个资金疯狂运转的基建层,市场上一直流传着一个极其危险的刻板印象:“企业 GPU 利用率仅有 30-40%,这 7500 亿里存在巨大的算力浪费。”
这是一个把四种不同指标和三种完全不同的工作负载混为一谈的外行的误读。要理清预期和现实的差距,必须把利用率分成3 档来看:
第一档:前沿大模型训练(占巨头支出的15-25%)
实测数据不会说谎。在超大规模集群中,梯度同步、流水线并行中的气泡都会产生不可避免的算力损耗。所以,35-55%是目前的极限。(信息来自论文哈)
第二档:公共云GPU 租赁(占巨头支出的50-60%)
分配率通常在30-60% 之间波动。这部分目前供应极度紧张。但也正是这种紧张,导致微软云的毛利率连续三个季度被残酷压缩(69% → 67% → 66%)。公有云的利润空间,正在被模型公司挤压。
第三档:企业 IT 私有自购(不在巨头的 7500 亿内),平均闲置 95%,这才是真正的浪费。
Cast AI 抽测了23000 个处于生产环境的Kubernetes 集群,发现企业自己买的GPU 平均闲置率高达95%。
老生常谈的“折旧”问题
在基建层,科技巨头们习惯把极其昂贵的GPU 按 5-6 年的寿命来折旧。
但在去年 11 月,知名大空头 Michael Burry 在 X 上抛出了一份重磅测算:他指出巨头们手里的 GPU 实际经济寿命只有 2-3 年。“未来 3 年,整个行业 1760 亿美元的折旧被低估,甲骨文高估了 26.9% 的盈利,Meta 高估了 20.8%。”
一开始,强劲的物理现实似乎狠狠打脸了Burry。
今年前 5 个月,SemiAnalysis 指数显示,H100 的一年期合约单价从去年底的 1.70 美元/小时,逆天暴涨到了 2.35 美元/小时(涨幅高达 38%)。英伟达 CFO Colette Kress 在财报电话会上更是底气十足地放出原话(CNBC 逐字记录):“H100 租金今年涨了 20%,A100 涨了近 15%,客户已经能在折旧寿命之外赚到正利润了。”
不仅如此,算力还彻底走上了金融化的道路。5月 12 日,CME(芝加哥商品交易所)与 Silicon Data 联手宣布了首个基于 H100 每日租金指数的算力期货市场。紧接着 ICE 也推出了涵盖 H100、B200 甚至 RTX 5090 的衍生品。算力,正式成为了 21 世纪的“新石油”。
但就在大家以为折旧危机解除、可以长舒一口气时,英伟达自己亲手打破了平衡。
英伟达的 Rubin架构宣布全速生产,直接将芯片的迭代节奏从以往的2 年周期(从Hopper到Blackwell),疯狂压缩到了1年周期(从2025年末的B300,到2026年下半年的R100,再到2027年的Rubin Ultra,最后是 2028 年的 Feynman)。
这就导致了一个极其致命的博弈:虽然H100 在物理现实中依然紧缺、依然能赚钱;但在心理预期层面,新一代跨代技术的飞速降临,让市场对旧卡残值的预期加速坍塌。Burry的折旧理论有可能在2027年得到验证。
新型云的利润悖论
这种折旧预期叠加极高的资金成本,对CoreWeave 等一众新型云服务商来说是很致命的问题。CoreWeave在 5 月 7 日发布的 Q1 财报,暴露了一个完全无法用常理解释的巨大悖论:
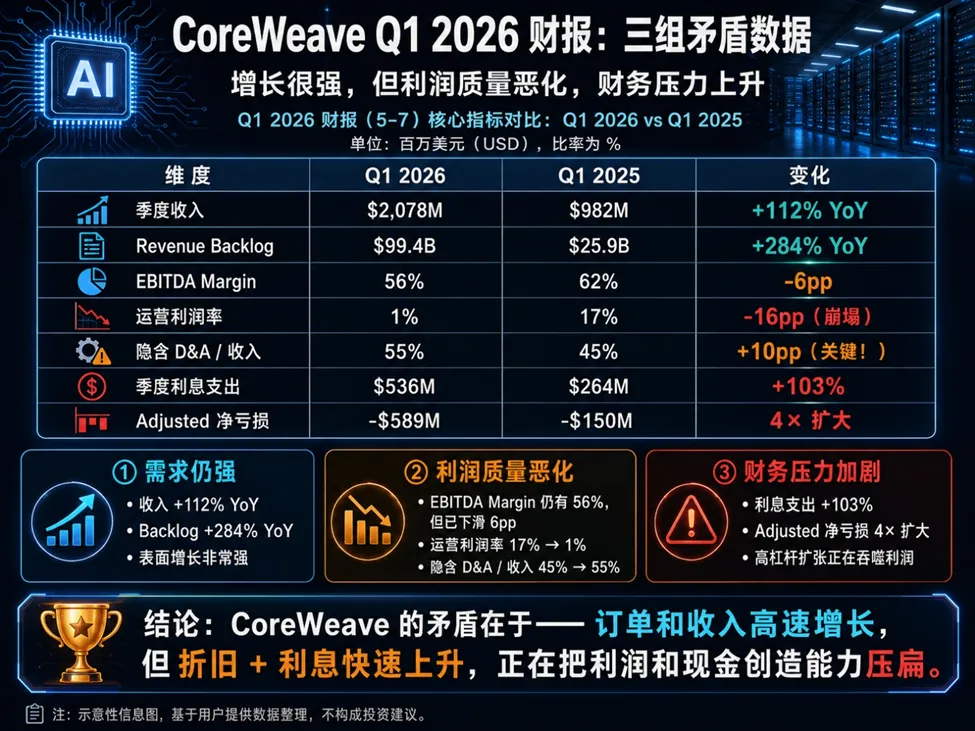
明明 GPU 租金大涨了 38%,营收翻倍,手握近千亿订单,为什么运营利润率却从 17% 直接崩塌到了仅仅 1%?
- 折旧与摊销(D&A)大爆炸:为了完成新合约的容量交付,CoreWeave 大规模上线了新GPU。这导致其Q1 的D&A 直接飙升至11.43 亿美元。D&A占收入的比重,直接从去年同期的45% 暴跳到了极其恐怖的55%。巨头们还能把D&A 藏在庞大的SaaS 收入里稀释,而100%靠租赁的新型云只能在损益表(P&L)上被狠罚。
- 长期合同的诅咒:CoreWeave 有96-98% 的收入来源于多年期的“use-or-pay”长约,而这些老合同大多锁定了2024-2025 年的低价。市场租金涨到天上去了,但根本进不了它当期的利润表。
- 高息债的系统性吞噬:为了买卡,CoreWeave 4月份以9.75%的极高利率发行了27.5亿美元的票据。直接结果是,Q1利息支出高达5.36亿美元,同比翻倍(+103%)。
这种基本面的崩塌已经在二级市场提前被定价。CoreWeave今年已经出现了两次毫无征兆的单日暴跌(2月27日跌 18.6%,5月8日跌 11%)。
风险系统性向全社会转移
这个咱们在【AI的物理世界】5篇聊完,开始聊【AI与金融市场】的时候会展开聊,1929的全球重演版。
寻找填补市场预期的物理现实,底层终究要回到能源、电网与土地的大规模部署上。目前最少被讨论,但却逐步发生趋势是:这场巨额资本支出的风险,正在被巧妙地推给外部(资产负债表外化),企业->居民。
数据中心正在抽干美国的电力。预计到2028 年,美国数据中心用电占比将狂飙至12%。在算力重镇弗吉尼亚州,因为巨头疯狂建机房,导致当地居民的电费在5 年内暴涨了267%。这引发了极其严重的社会反弹。
这一切,像极了1929 年大萧条前夕的镜像重演:当年是大资本家发动小地主去接盘铁路债;如今,是科技巨头们发动普通居民和州政府,去承担电网投资、土地租赁和长期购电协议(PPA)的巨大风险。
但 2026 与 1929 有一个绝对本质的差异:需求来源。
1929 年的需求是一个封闭在美国内部的单一循环。而今天,AI的算力需求,是全球资本。软银(SoftBank)在俄亥俄州宣布了 5000 亿美元的数据中心庞大计划;Stargate 在美国 5 个新址承诺了 4000 亿的投资;叠加中东主权基金对英伟达的无脑狂买,以及韩国 SK 海力士接收到的全球 HBM 订单。这种全球资金极其宽广的承接面,意味着这场资本周期的狂奔,可能会比1929 年跑得长得多。
这对新型云也是一把双刃剑:由于巨头越来越难搞定受阻于电网的超大型数据中心,这逼迫一部分算力走向分布式。Meta与 Nebius 签下高达 270 亿美元的合约(其中 120 亿是 Rubin 的部署),就是新型云从“次级承包商”转向“分布式推理网络运营商”的硬证据。
那么技术上,这种分布式路径真的可行吗?可行,只是需要时间。首先在美国本土多州分布式部署完全合规;其次是网络层,Equinix等提供商的Fabric 互联解决方案足以拼接多区域推理网络;真正难的依然是电力,但BTM 自带发电、地方PPA(长期购电协议)、与州政府电网合作这三条路径都已经在跑通。
这也催生了一条暗线:当公共电网成为硬约束,自带发电(BTM)甚至采用核能(Nuclear)的小型模块化反应堆(SMR),必然成为下一阶段填补预期的物理现实。
物理瓶颈的时间表与“躺赢者”
在所有人都在双因子的绞肉机里挣扎、为高息债和电网抗议焦头烂额时,产业链里只有一个群体在绝对的“躺赢”:不受双因子影响的数据中心托管方(Colocation)。当然了,弹性也最小,boring但稳定的生意。
以龙头Equinix 为例,其 Q1 收入达 24.44 亿美元,新订单创下历史纪录,其中 60% 是 AI 驱动的大单。它们不买昂贵的芯片,也不搞复杂的模型,只负责收网线、液冷设备和场地互联的租金,锁定了长达10 到 15 年的长约,拿走的是整个技术栈里毛利最稳健的产品。
随着这场狂欢不可避免地撞向物理边界,一份残酷的物理瓶颈时间表已经极其清晰:
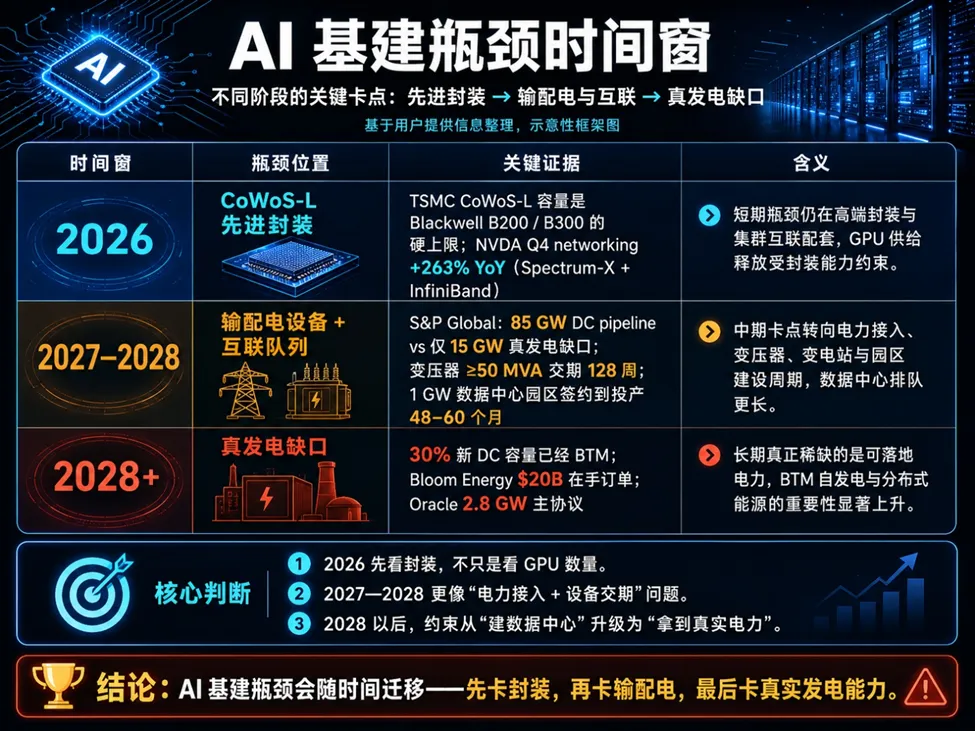
正如上表所示,2026年的扩张上限受制于先进封装产能,2027年则卡在输配电设备(大型变压器交期已长达128 周),而到了2028 年以后,真正的底层发电缺口将彻底爆发。
总结
面对这场 7500 亿美元史无前例的基建狂欢,我们要寻找的真正 Alpha,就在于盯紧以下四个预示市场预期与物理现实发生断裂的信号:
- 新型云悖论的加深:盯紧CoreWeave 后续季度的财报。如果D&A(折旧摊销)占收入的比重继续居高不下甚至突破50%,这就是新型云商业模式崩盘、基建层局部泡沫破裂的最早信号。
- 利润挤压的财务传导:紧盯微软云的毛利率。如果其跌破65%,意味着模型公司对公有云利润的挤压已经完全财务化,巨头将进入痛苦的阵痛期。
- 估值的终极锚点:关注Anthropic 是否能在10 月份顺利IPO 并完成600 亿美元的募资。这将为整个公开市场的 AI 实验室设定最硬的估值锚点。
- 【终极时间锚点】2027年下半年:输配电瓶颈的全面触发。到了这个时间节点,甲骨文1300 多亿的高昂债务、新型云的高息债与折旧爆炸,将与全美各地此起彼伏的电网抗议同时并发。叠加英伟达Rubin 加速带来的折旧悖论重新浮现,原地踏入死亡区间,2027年下半年,这才是基建层信用周期真正可能破裂的终极危险窗口。
那这7500亿到底买到了什么样的核心零部件?5层蛋糕的第4层里,HBM 内存、DDR5、网络与 CoWoS 封装,谁是下一个bottleneck?MLCC么?
如果您对拥有一个专属于自己的24/7的能自我学习成长的AI基金团队感兴趣。欢迎您入群加入公测。也可以到 www.scalealpha.ai 上加入等候名单,我们将陆续开放名额。
可以扫描下方【客服二维码】→ 备注“进群”领取入群链接

