 夜雨聆风
夜雨聆风AI 视频最大的一个隐形成本,应该被彻底解决了。
简单说一下,周末我发现 LibTV 这个 AI 视频创作工具,上线了一个叫 3D 导演台的功能。这个功能,基本上把 AI 视频创作最后那个卡点给解决了。
产品地址在这里:https://www.liblib.tv/
我强烈建议所有想做 AI 漫剧、AI 短片的同学,赶紧上手研究一下,接下来这一段时间应该会有不小的红利。
今年春节前,Seedance 2.0 发布的时候,黑神话悟空的制作人冯骥说过一句话,AIGC 的童年时代结束了。这句话我反复引用过好多次,因为很多人没理解它的分量。
我去年一整年都在玩视频模型,看到过一个很明显的过程。模型刚出来的时候,生成个人手能给你整出六根手指,眼神也是飘忽的,各种各样的小毛病。
后来每个月模型能力都在提升,提升是真提升,但一直没能真正越过那条可用的线。
Seedance 2.0 绝对是一个重要的节点。但是模型能力强,和产品足够好用,是两件事情。
最近行业里大家都在提 Harness 这个概念。为什么?因为大家慢慢发现,一个 AI 产品好不好用,光模型不够,还得看模型之上那层约束做得好不好。
模型本身的能力是发散的,什么都能生成,可什么都能生成,也就意味着什么都不确定。Harness 做的事情,就是用工程的办法,在模型外面加一层控制。
超级好用的 3D 导演台
那它到底加了什么、解决了什么问题,我稍微展开讲一下。
随着视频模型能力越来越强,创作过程中最大的挑战已经变成怎么把脑海中的画面准确表达出来。
举一个最常见的例子。一句很普通的提示词:
一个男人站在车旁,一个女人站在马路对面,两个人对峙。
大家试着读一遍,好像已经描述得挺清楚了吧?
但是对 AI 来说,这句话里缺的信息太多了。两个人谁离镜头更近,车停在哪边,镜头是俯拍还是平拍,这些它全都不知道。
于是模型只能猜测。
猜测的结果,就是把创作变成了一个概率问题。所以这个行业里大家特别爱用一个词,叫抽卡。
抽卡是什么意思我就不细说了,理解成在跟概率碰运气就行。靠碰运气做东西,效率能高才怪。
这其实是目前 AI 视频领域最大的一笔隐性成本。
大家以为自己在写提示词。实际上很多复杂的场景里,就是在抽卡,碰运气,没有什么准确性可言。
而 3D 导演台做的事情,本质上就一句话:把导演脑子里的空间关系,先可视化地摆放出来。
从 Prompt 驱动,变成构图驱动。
这是我觉得整件事情里最值得关注的地方。因为它背后对应着一个挺大的趋势。
AI 视频创作正在发生一个变化。以前主要靠文字告诉 AI 想要什么画面,现在能反过来,先把画面摆出来,再让 AI 照着生成。
其实你去看导演在现场,他很少光靠一张嘴去指挥。跟演员说站位,他不会坐在监视器后面喊一句往左点,他会直接走过去,站到那个位置上,告诉演员就在这儿。
说动作神情也一样,讲不清楚,他干脆自己示范一遍,演员一看就明白了。
3D 导演台搬进 AI 视频创作里的,就是这件事。以前写提示词,就像导演坐在后面冲着 AI 喊话,喊半天 AI 还是猜。
导演台让你能直接走过去,把演员和镜头摆到该在的位置,摆给 AI 看。
说到底,它解决的是 AI 的歧义问题,核心价值就是降低歧义。
就像刚刚说的两个人在车旁对峙的镜头。如果全靠提示词,可能要写上几百字,还不一定能说清楚谁前谁后、谁左谁右。
但是在导演台里,把两个小人摆好,谁站在车旁、谁在马路对面、面朝哪个方向、相隔多远,十几秒钟就表达完了,AI 照着图生成,不用再去瞎猜。
而且我觉得,画面这种东西,本来就不适合用文字来承载。脑子里那个画面,有位置、有角度、有运动,硬要翻成一句话,本质上是在做一次压缩,而且是有损的压缩。
所以很多复杂镜头,摆一张图的信息量,远远超过几百字的 Prompt。
所以我的判断是,接下来像导演台这样的可视化工具,会变得越来越重要。
原因其实很简单。模型能力不够的时候,大家对它只有一个要求,能生成就行。
但随着模型越来越强,大家会开始追求控制力,会想要弄明白这个角色为什么站在这里、镜头为什么要这样拍摄。
到那个时候,生成能力会慢慢沉下去,变成基础设施。而控制能力会成为新的竞争点。
实操 Case
正好最近想试试做个国漫风格的武侠短片。故事很简单,一个剑客护送受伤少女携密信穿越竹林时,遭杀手截杀的打斗短片。先看最后做出来的效果:
我们正式开始操作,首先,创建个脚本节点,先把灵感喂进去。等了一分钟,出来个十分专业的分镜脚本,我们可以进一步对脚本进行编辑优化。
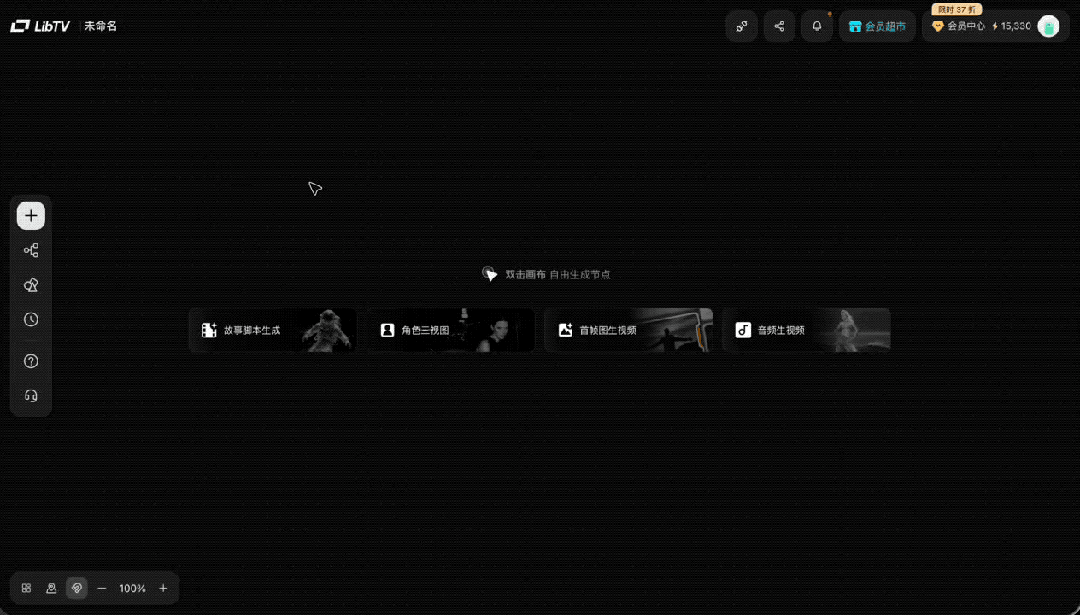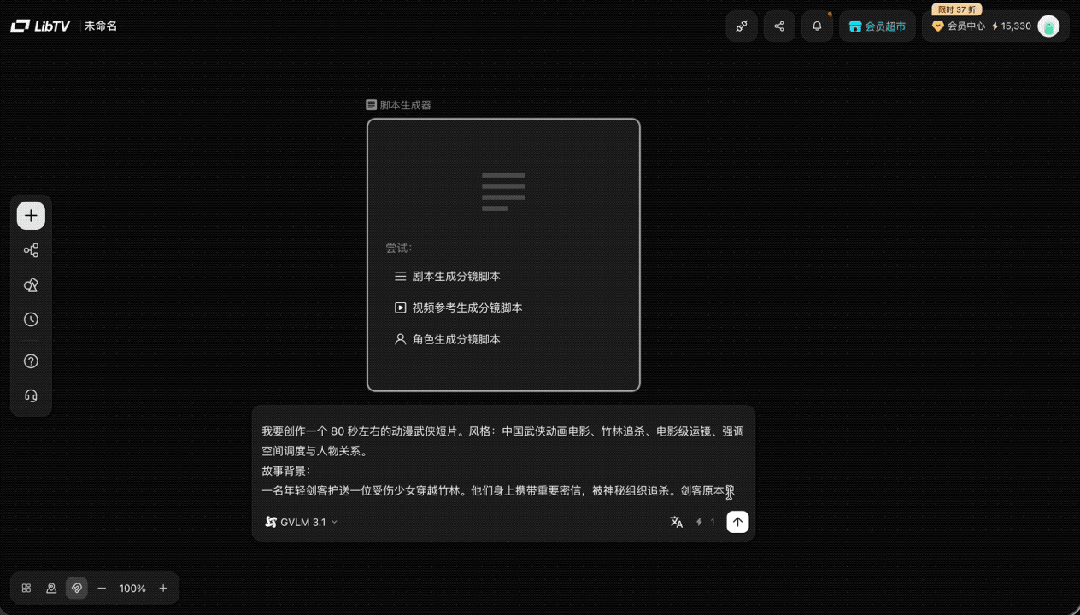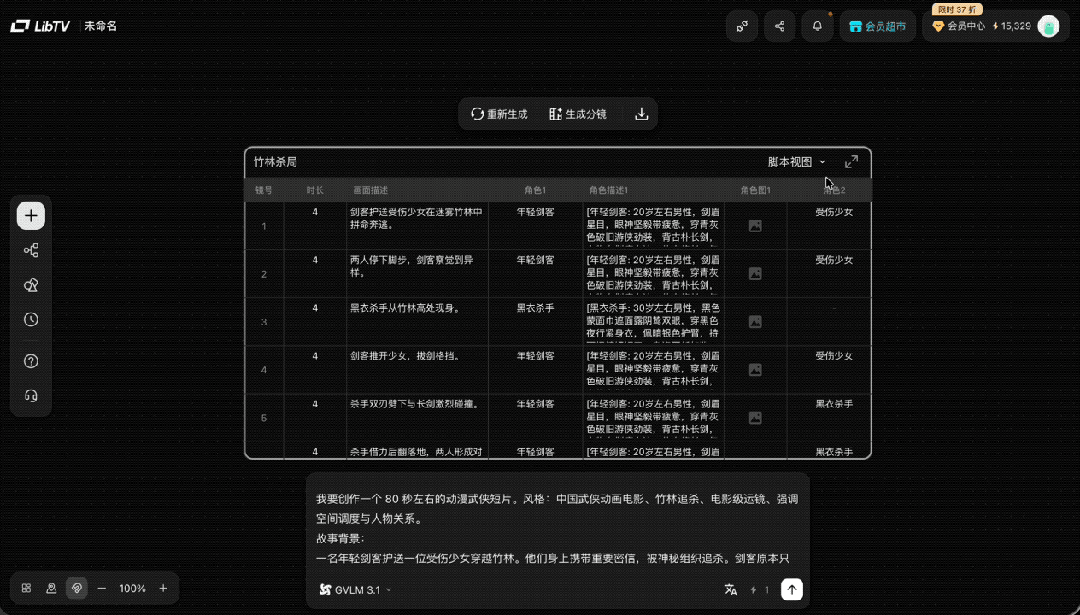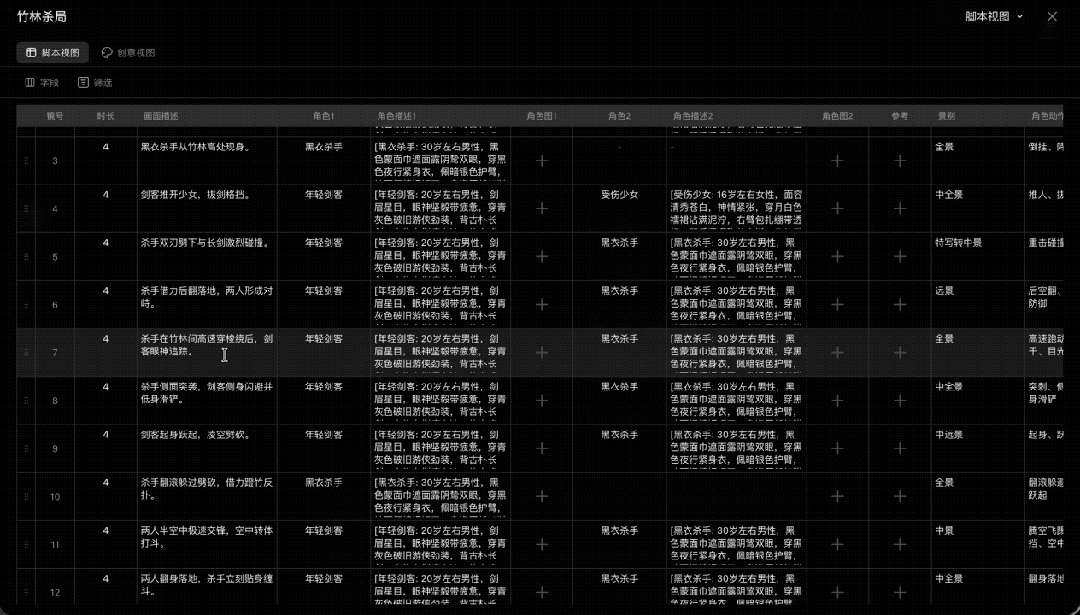
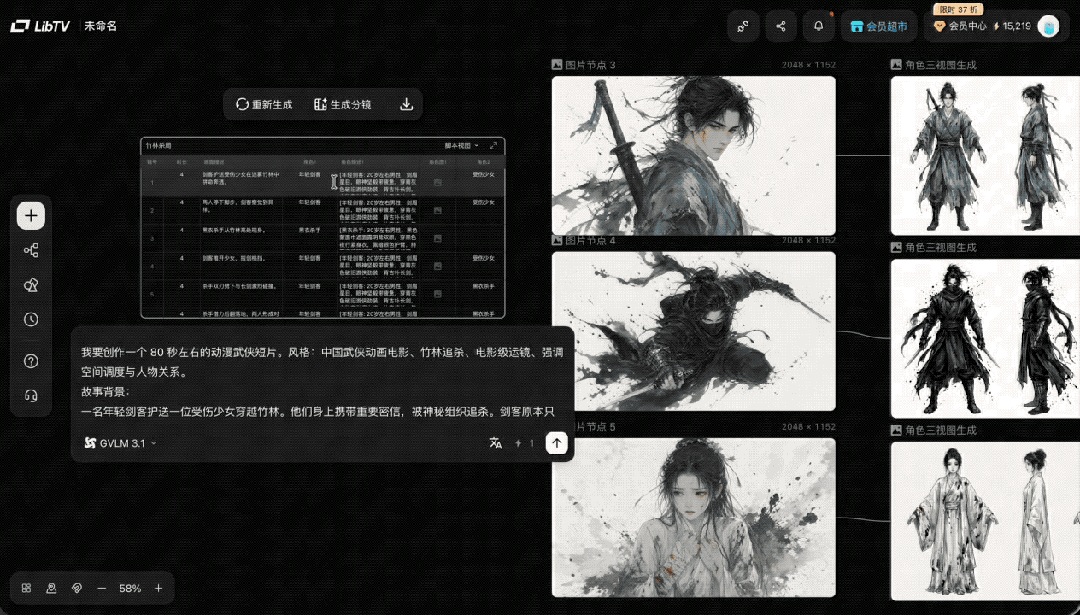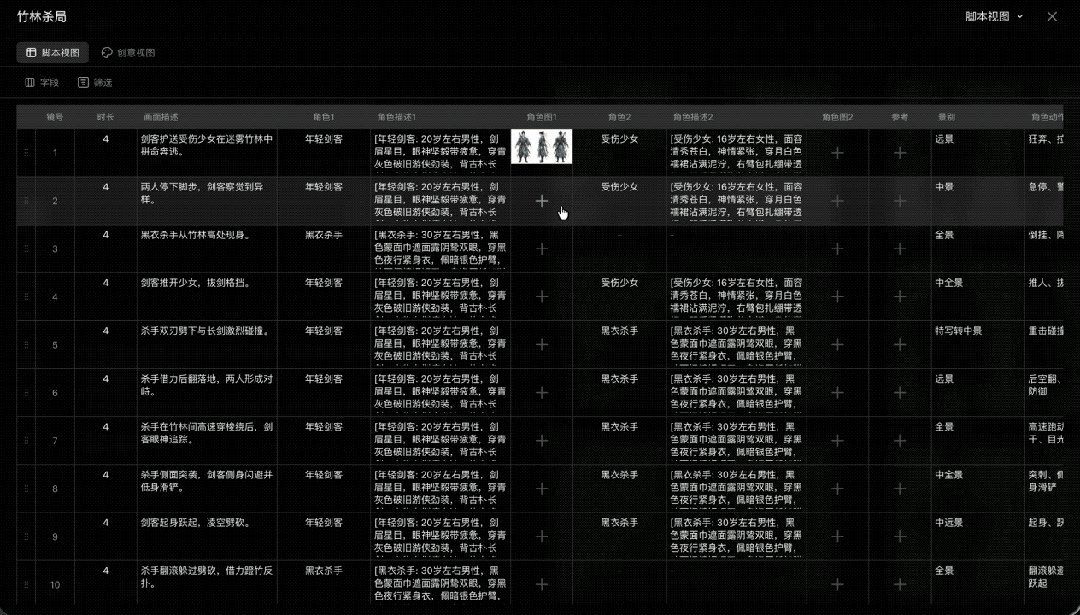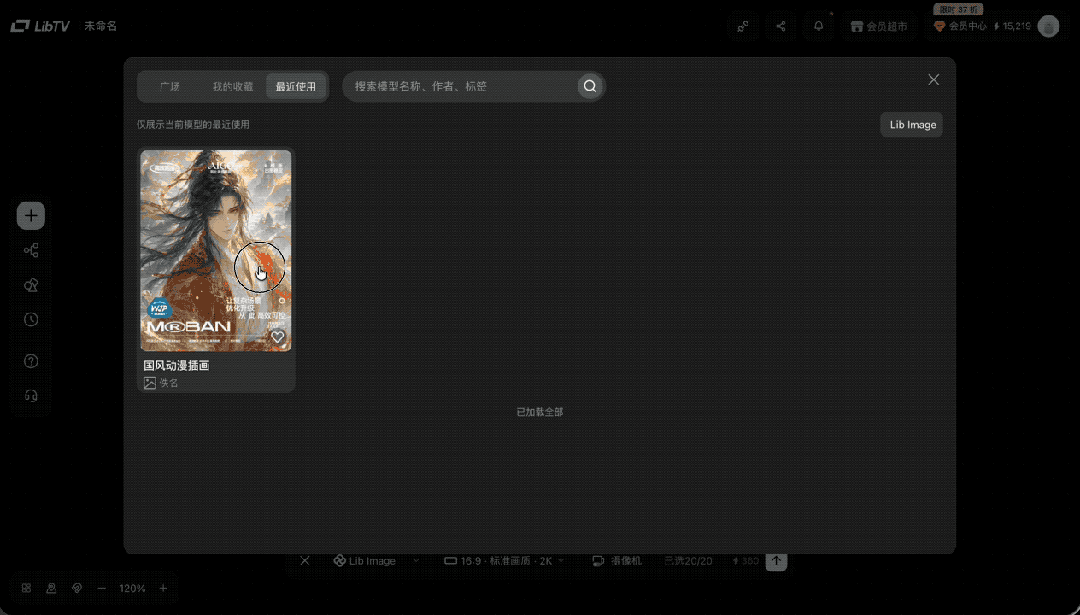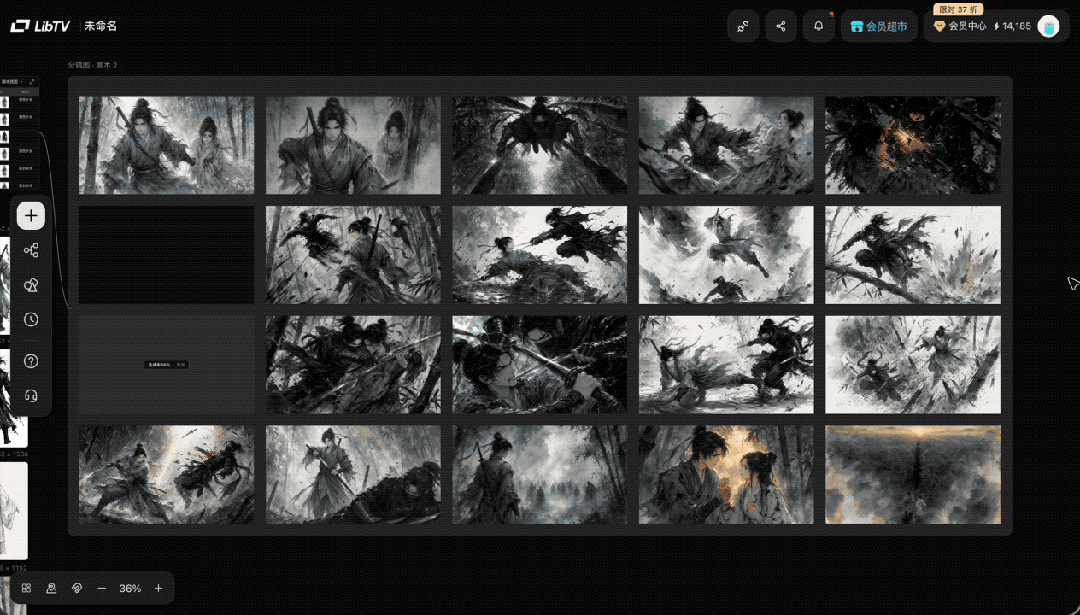
根据脚本中描述的人物形象,选择风格,用 LibTV 角色三视图生成功能,把剑客、少女和杀手三个人物的三视图生成出来。
然后添加进脚本中,加强人物一致性,选择模型和风格,点击生成分镜,没一会分镜图就生成好了。
接下来就开始优化调整分镜图了,有穿帮或者不满意的可以单独再进行修改。
像这张杀手过来,剑客把少女推开的分镜图,我感觉效果总是怪怪的,像是剑客想要把少女抓住一剑捅上去。
我想要的是剑客意识到危险之后,第一反应不是拔剑,而是先把少女往身后推开。

这个动作其实很微妙。剑客应该在前面,身体稍微压低,一只手往后伸,挡住少女。
少女应该被他带到画面后侧,身体有点失衡,但不是摔倒。这个画面靠语言就很难说清楚。
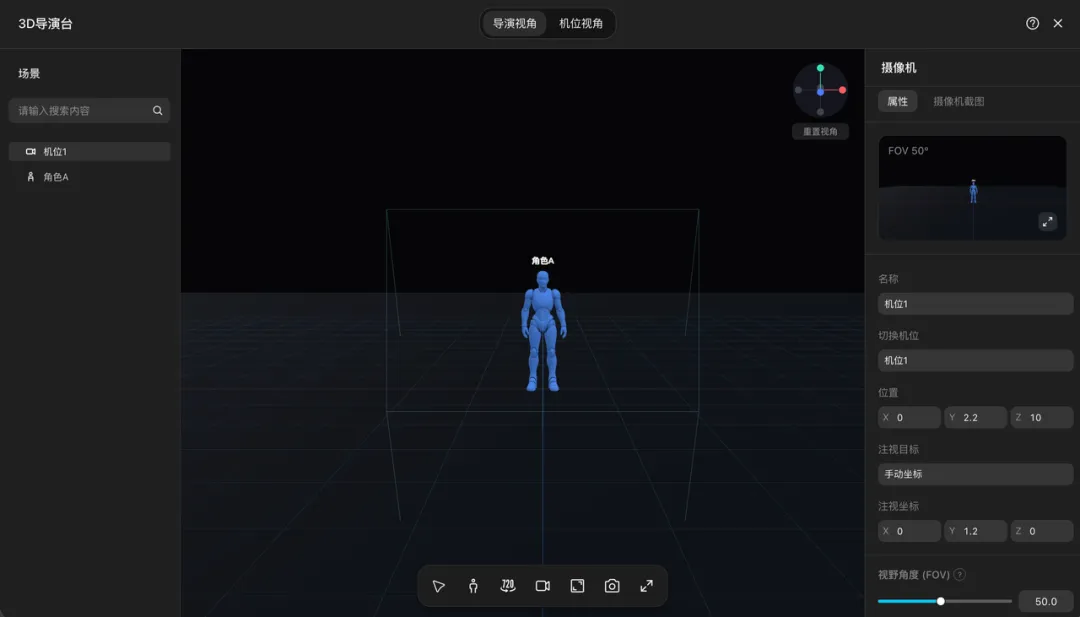
所以我直接打开导演台。进去以后,我先把人物关系摆对。角色 A 是剑客,角色 B 是少女。先把剑客放到画面前侧,少女放到剑客身后半步的位置。
然后调整两个人朝向,让剑客身体面向危险方向,但手臂往后伸,做出把少女护开的动作。
这里我不用写保护、推开、紧张这些抽象词,直接把动作摆出来就行,谁在前,谁在后,手伸向哪里,身体往哪边转。
这些原本要靠一大堆提示词描述的东西,在导演台里拖一下、转一下、调一下姿势就解决了。
它还有一个很关键的点,就是可以调整比例。AI 图最难解决的问题之一就是人物大小跟周围环境不匹配,生成出来的人物总是过大。
比如,少女应该在后面,结果生成出来和剑客一样大,还跑到视觉中心。我在导演台里就可以先把人物前后关系和画面比例卡住。
剑客占画面主要位置。少女稍微靠后、靠右一点。这样后面图片模型再生成的时候,就会很容易达到我们的标准。
接着我再调整姿势。右侧栏里有现成的姿势预设,比如站立、行走、跑步、单膝跪、伸手、推进等等。
先用预设打底,再在下方微调身体前倾、转身、侧倾、头部方向。
这个过程特别像给演员走戏。先让演员站到位置上,再告诉他身体往哪转、手抬到哪、头看向哪,最后再让摄影机站到该站的位置。导演台里面也一样。
摆完人物以后,我切到机位视角,调整一下机位的位置。如果画面太散,就调整视野角度,让人物关系在画面中更紧凑。
最后截图,发送到画布。把这张导演台截图、角色三视图、竹林场景一起丢给图像模型,再重新生成分镜。这次效果就顺很多了。
这张剑客被杀手打了个措手不及的分镜图也是一样。
我想要的画面是,剑客被打伤之后单膝跪地,用剑撑住身体,杀手站在对面,这其实是一个很典型的强弱关系镜头,谁占主动,谁被压制。
只要这里反了,整个戏就不对了。原图的问题就是剑客不够狼狈,杀手也不够有压迫感。

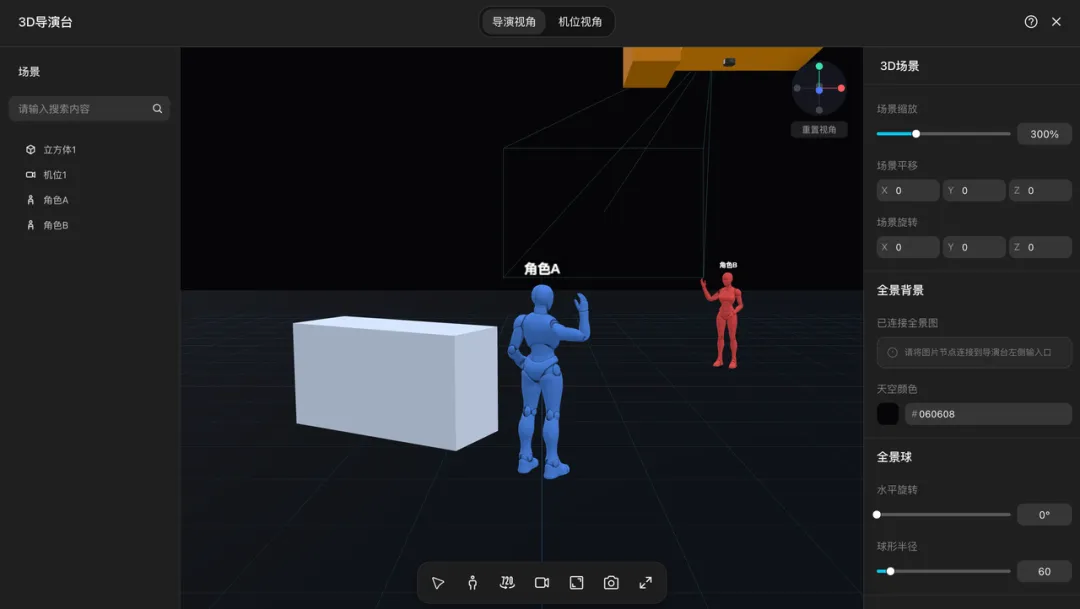
于是,我继续打开导演台,这次我先把两个角色拉开距离,剑客放在画面左侧,调成单膝跪地姿势。
杀手放在画面右侧,站立姿势,双手叉腰,身体朝向剑客,显得更有压迫感一些。
剑客虽然在前景,但姿态是低的。杀手则离得远一点,但姿态是高的。这样一高一低,强弱关系马上就出来了。
这也是我觉得导演台特别适合做分镜修正的原因。很多镜头不是 AI 画得不好,是戏不对。戏不对的时候,靠提示词修很痛苦。
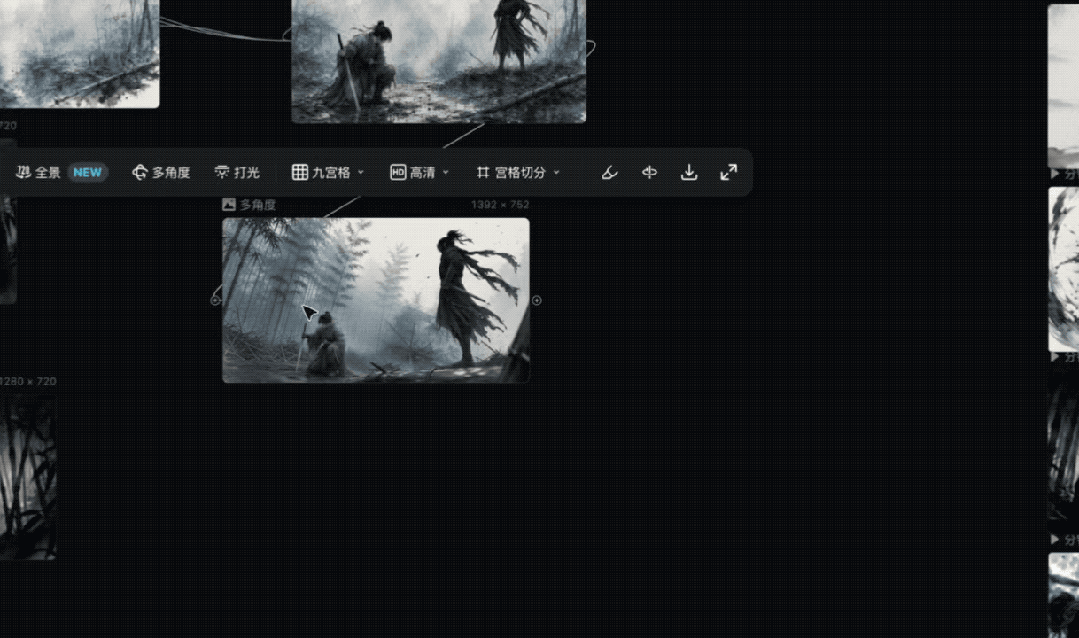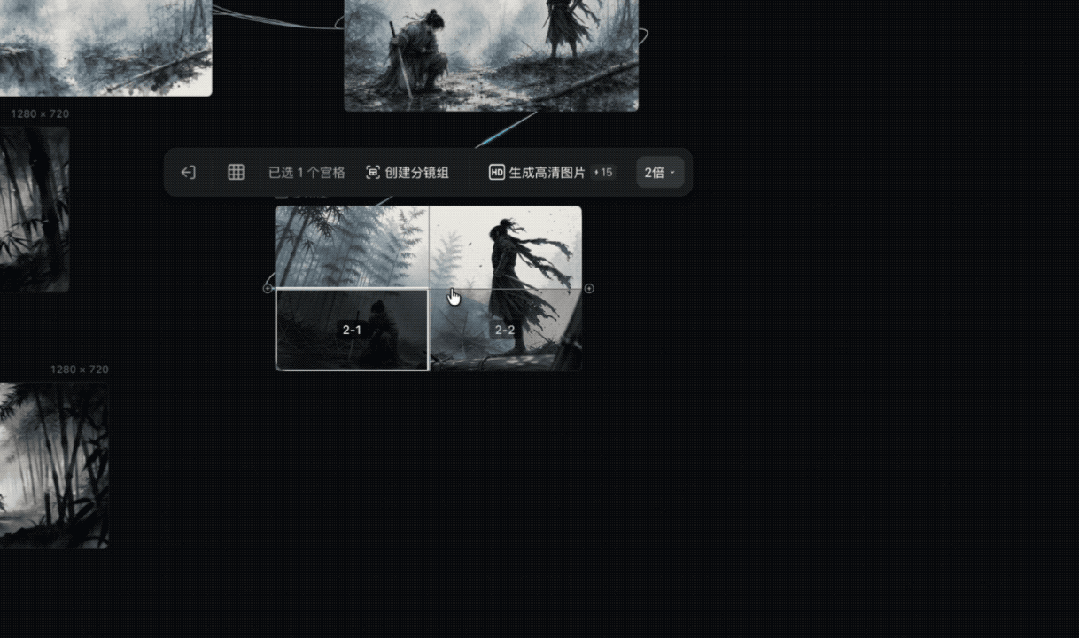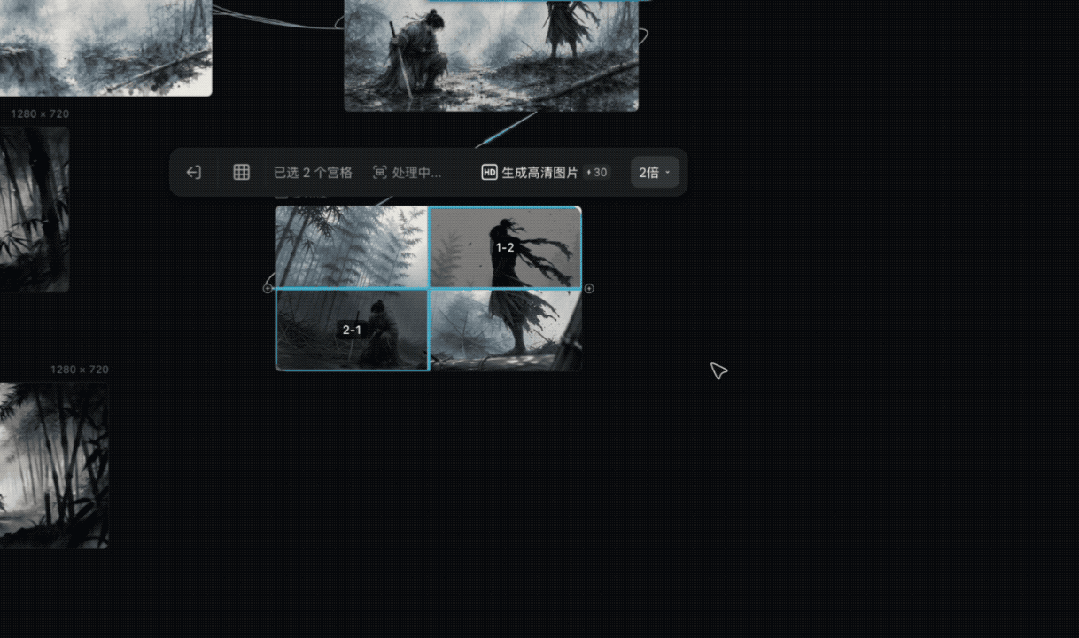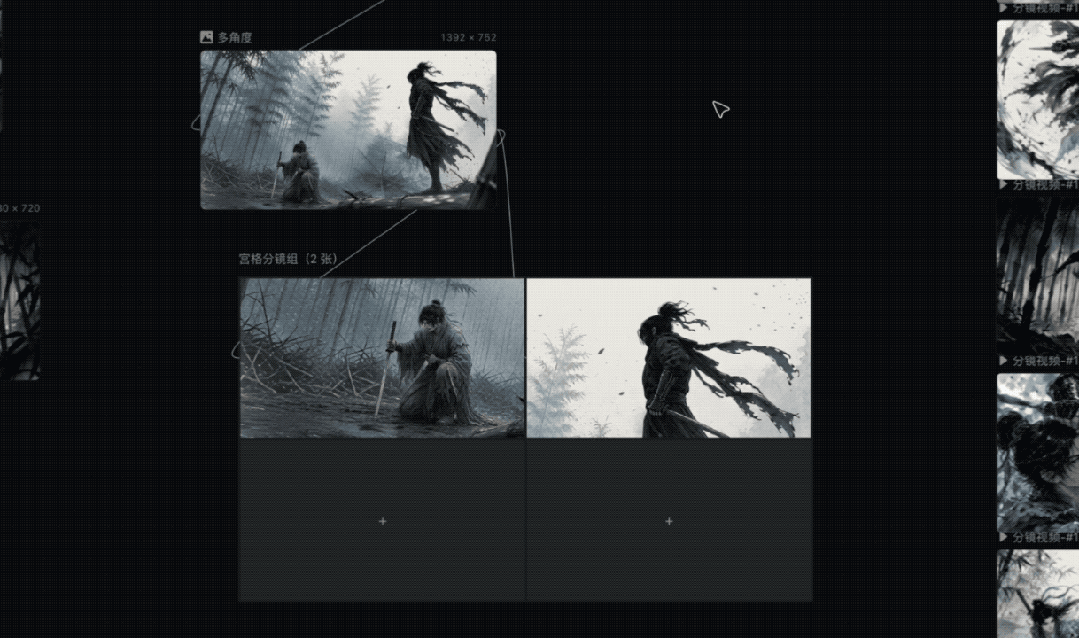
等图片效果出来后,我发现这张图片可以做做文章,弄个不同的镜头角度,搞个分镜接在后面,当做杀手再次出手时的首帧参考图。
说干就干,我就点击图片,打开多角度编辑器,可以看到这里面有鱼眼、倾斜、全景等等预设视角,我直接围绕当前画面手动调整视角,然后生成即可。
同样一个动作,换了个镜头角度,出来的感觉完全不一样。
这时候我继续往下走一步,直接用宫格拆分功能。
这个功能让我很快就能搞定想要的特写分镜头,不用再单独去写提示词,说画面元素不要改动,给哪哪一个特写镜头,或者简单粗暴的去裁剪图片。
后面的一些镜头,我基本也是按照这个思路往下推进,我就不再冗余的介绍了。
把所有分镜图搞定后,再用视频模型把每个分镜头生成出来,最后拼接成完整短片就好了。
在我生成分镜头的时候,有几段整体效果不错,但开头总喜欢给你来一段慢悠悠的起手动作,就会显得很呆。
我直接点击视频,用剪辑功能,把时间轴拖一拖,想要的部分选取,去掉前面那些没用的铺垫。

整个过程其实没有想象中那么复杂,更像是在搭乐高。把脑子里的画面一点点摆出来就行。
我又顺手试了一个完全不同的题材,两个人在咖啡馆里谈判。
听起来比武打戏简单得多,但实际做过 AI 视频的人应该都知道,这种双人对话的镜头特别容易翻车。
我直接点开导演台,先摆距离、再摆朝向。
接着把正打、反打、过肩镜头和侧面双人镜头全部提前搞出来,当做参考图,后面生成的时候,就不会再出现离谱情况了。
最后的效果:
总之,凡是涉及人物关系、空间关系和镜头调度的场景,它都特别有用,场景越复杂,效果越能明显体现出来。
写在最后

https://www.liblib.tv/
说真的,有了 3D 导演台这个工具,我感觉折磨我们很久的 AI 视频抽卡问题,到这儿应该算是被彻底解决了。
当然,3D 导演台也不是所有场景都得用。
它真正派上用场,是在动作和站位比较复杂的时候,或者那种用提示词怎么写都说不准的镜头,这时候直接上导演台,比反复修改提示词抽卡省事多了。
如果说 Seedance 2.0 的发布意味着视频模型本身的成熟,那这一次导演台这样的工具,意味着的是模型之外那一层的成熟,也就是 Harness,或者说 AI 创作工具的成熟。
我是真觉得,这种创新的重要程度,一点都不亚于模型本身的提升。
