 夜雨聆风
夜雨聆风走进GenericAgent——133行Agent Loop撬动30K上下文极限压缩!
代码仓库: github.com/lsdefine/GenericAgent | 论文: arxiv.org/abs/2604.17091本地路径: ~/projects/generic-agent核心文件: agent_loop.py (133行) + ga.py (593行) + agentmain.py (290行) = 1016 行
0. 代码发布状态
| agent_loop.py | ||
| ga.py | ||
| ga.py | ||
| ga.pydo_start_long_term_update | ||
| agentmain.py |
1. 环境配置
Shell 命令
2. Agent 运行循环 — agent_loop.py (133 行)
这是 GA 的心脏,实现了完整的 Agent 生命周期:LLM 调用 → 工具分发 → 结果收集 → 上下文压缩。
2.1 消息管理与上下文 turn 重置 (L42-57)
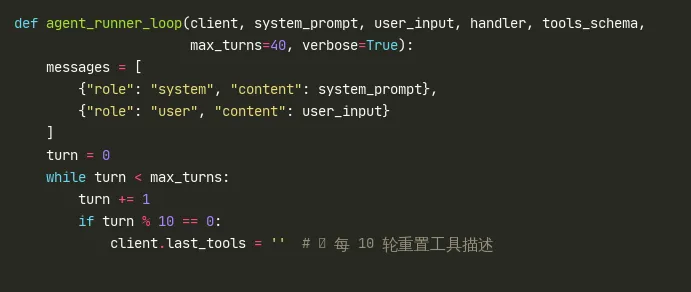
代码片段 (python)
messages 只保留 system prompt + 当前用户输入——历史对话不在这里维护。历史由 LLM backend 的 Session 对象内部维护(agentmain.py 中的 NativeClaudeSession)。这避免了每次 LLM 调用时重复发送完整历史,是 GA 实现 30K 上下文的关键设计之一。
turn % 10 == 0 → client.last_tools = '':每 10 轮清空工具描述的缓存。LLM backend 会缓存上一次发送的工具 schema,只有变化时才重新发送。GA 通过主动清空缓存来触发 schema 重发,防止工具描述在长对话中丢失上下文——这是对 Claude API 的 tools 参数行为的深度适配。
2.2 工具分发 — 反射路由 (L69-88)
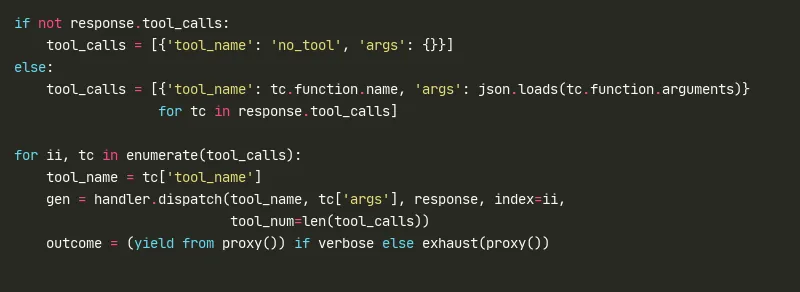
代码片段 (python)
dispatch 方法(agent_loop.py L18)通过 method_name = f"do_{tool_name}" 和 getattr(self, method_name) 实现反射路由——新增工具只需在 GenericAgentHandler 中添加 do_
yield from proxy() 是关键设计选择:工具执行是生成器(generator),可以逐行输出中间结果。这使得 verbose 模式下用户可以实时看到工具的 stdout,而非等待工具执行完毕——对于长时间运行的 code_run 尤其重要。
2.3 结果收集与退出判定 (L89-107)

代码片段 (python)
should_exit 用于 ask_user 工具——当 Agent 需要用户输入时,暂停执行并等待交互。next_prompt 为空表示当前子任务完成,触发 CURRENT_TASK_DONE。
L104 的 messages = [{...}] 只包含当前轮的 user 消息——这是 GA 上下文压缩的核心。Claude API 的 messages 参数不累积历史,历史由 NativeClaudeSession 内部维护并自动管理缓存。GA 每次仅发送 1 条新 user 消息 + tool_results,相当于每次 LLM 调用的输入 token 开销接近恒定,而非随轮数线性增长。
3. 工具集 — ga.py (593 行)
3.1 代码执行 do_code_run (L284-309)

代码片段 (python)
_extract_code_block(L279):从 LLM 的回复中自动提取 markdown 代码块——当 LLM 在 content 中直接返回代码而非使用 tool_call 参数时,这作为兜底逻辑。这是一个巧妙的后备机制:Claude 有时会在 thinking 过程中返回代码而非调用工具,GA 通过正则 re.findall(rf"`(?:{code_type})\n(.*?)\n`", ...) 自动提取。
maxlen = 10000 // args.get('_tool_num', 1):当 LLM 同时调用多个工具时(如 code_run + file_read),每个工具的输出长度按工具数量均分。这防止了多工具并发时单个工具的输出膨胀导致上下文溢出。
inline_eval 模式:对于简单的 Python 表达式求值(如 2+3),不写临时文件,直接在 handler 的 namespace 中 eval。结果通过 repr() 转换为可读字符串。
3.2 文件操作 (L361-455)
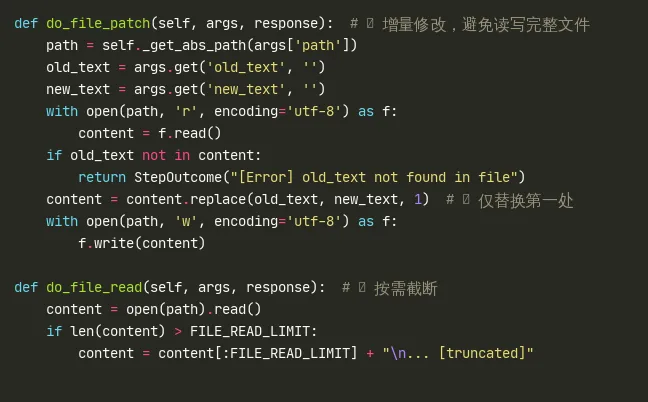
代码片段 (python)
do_file_patch 是 GA 工具集"最小完备性"设计哲学的缩影:与 Claude Code 需要独立的 FileEditTool + FileWriteTool + FileReadTool 不同,GA 仅用 file_patch 的 old_text → new_text 替换就实现了增量编辑。Claude Code 需要 search_replace + write_to_file 两个独立操作才能完成同样的事情。
do_file_read 的 FILE_READ_LIMIT 截断是上下文压缩的"前端防线"——在工具输出进入 LLM 上下文之前就进行截断,而非在 LLM 内部压缩。这比后置压缩(对话历史摘要)更高效,因为截断发生在工具层而非 LLM 推理层。
3.3 网页浏览 — 轻量替代浏览器模拟 (L318-354)

代码片段 (python)
GA 不使用完整的浏览器模拟(如 Playwright/Selenium),而是通过 simphtml 模块提取简化 HTML,再通过 web_execute_js 执行 JavaScript 交互。这种"轻量提取 + 按需交互"的设计是 GA 在 BrowseComp-ZH 上准确率 0.60 vs OpenClaw 0.20 的关键——OpenClaw 的完整浏览器模拟产生大量 HTML/JS/CSS 噪声,淹没了 LLM 的注意力。
4. 自进化与分层记忆 — ga.py L438-590
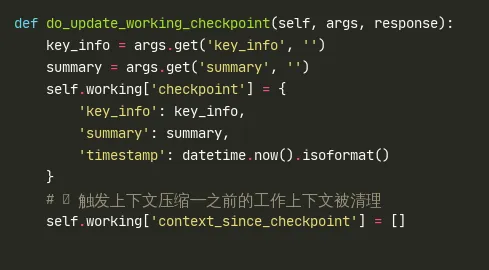
4.1 检查点管理 do_update_working_checkpoint (L438-454)
代码片段 (python)
update_working_checkpoint 是上下文压缩的"触发机关"。Agent 在完成一个子任务后主动调用此工具,将"中间状态"固化为 checkpoint,并清空 context_since_checkpoint。下一次 LLM 调用时,system prompt 只会包含 checkpoint 的摘要 + 当前子任务的上下文——中间过程的 token 被完全丢弃。这是 GA 在长周期任务中将上下文稳定在 30K 的核心机制。
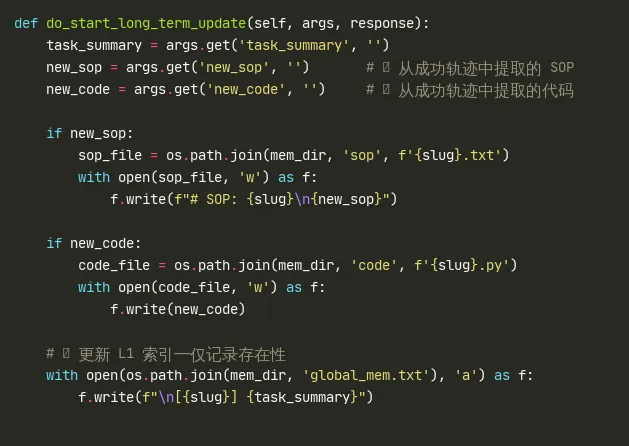
4.2 长期记忆更新 do_start_long_term_update (L505-581)
代码片段 (python)
new_sop 和 new_code 的内容完全由 LLM 生成——GA 框架本身不做任何自动化代码提取或轨迹分析。LLM 在完成一个任务后,被提示"这个任务的成功经验中有什么可以固化为 SOP?有什么代码可以复用?"——然后 LLM 自己总结并调用 start_long_term_update。
global_mem.txt 的追加写入实现了 L1 索引层——每行格式 [PDF处理] 处理过PDF解析、合并、分割。在下一次任务开始时,get_global_memory() 读取此文件并注入 system prompt。L1 仅 30-50 行,token 开销极低(约 100-200 tokens),但为 LLM 提供了"这些能力是存在的"的关键元信息。
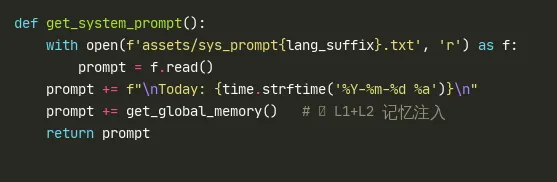
5. System Prompt 与 Memory 注入 — agentmain.py
代码片段 (python)
get_global_memory() 从 memory/global_mem.txt(L1 索引)+ memory/global_mem_insight.txt(L2 事实)读取内容,注入 system prompt。这些文件由 do_start_long_term_update 在任务成功完成后增量更新。
Today: 2026-05-28 Wed 这行看似简单,但解决了 LLM Agent 的"时间盲视"问题——Agent 在处理时间敏感的网页数据(如新闻、实时数据)时,需要知道当前日期来判断数据时效性。此外,get_system_prompt 每次调用都重新读取文件——这意味着 do_start_long_term_update 写入的新 SOP 或事实,会在下一次 LLM 调用时立即生效,无需重启 Agent 进程。这种"热加载"设计让 Agent 的自进化成果可以即时反馈到后续任务中,而非像传统框架需要等到下一次部署。
6. 核心设计模式总结
阅读 GA 的 1016 行核心代码后,可以抽象出四个贯穿始终的设计模式:
模式一:反射路由 + 最小工具集。GA 不维护工具注册表——BaseHandler.dispatch 通过 getattr(self, f"do_{tool_name}") 实现零配置工具路由。新增工具只需在 GenericAgentHandler 中添加一个 do_
模式二:Generator 驱动的流式执行。所有工具方法都是 Python generator(yield from code_run(...) 而非 return code_run(...))。这使得 Agent Loop 可以在工具执行过程中逐行 yield 中间输出,用户在 verbose 模式下可以实时看到 LLM 的思考过程和工具的输出流。对于长时间运行的 code_run(如模型训练、大数据处理),这种设计避免了"黑盒等待"的用户体验。
模式三:上下文预算的"前端防线"。GA 的上下文压缩不在 LLM 推理层(如 MemGPT 的对话摘要),而在工具层:do_file_read 在文件内容进入 LLM 上下文之前就截断,do_web_scan 在 HTML 进入 LLM 之前就简化。这种"前端截断 + 后端检查点"的双防线设计,比单一的后置压缩策略更有效——因为被截断的 token 永远不会进入 LLM 的注意力计算,节省的是推理计算本身,而不仅仅是 API 费用。
模式四:LLM 驱动的自进化。GA 框架本身不做代码分析或轨迹提取——所有 SOP 和 code snippet 的内容都由 LLM 生成。do_start_long_term_update 只是提供了存储和检索的基础设施。这种设计哲学的核心洞见是:LLM 已经具备了总结和抽象的能力,Agent 框架不需要重复实现这些能力——框架的职责是"提供记忆"和"在合适的时机触发记忆更新"。
7. 可运行 Demo
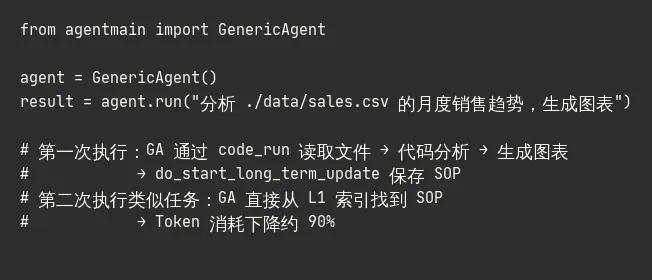
执行流程
硬件要求: 仅需 LLM API 密钥。Agent 本身是纯 Python 进程,无 GPU 需求。
去读论文 · 前沿&经典论文解读
