 夜雨聆风
夜雨聆风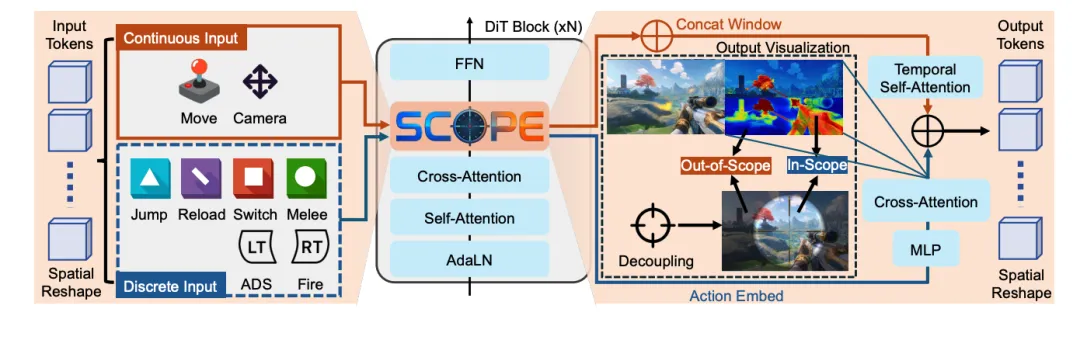

⚡️《SCOPE: Simulating Cross-game Operations in Playable Environments for FPS World Models》
📖 导读
在生成式世界模型(World Models)的竞速中,以《我的世界》或简单 2D 游戏为基础的模拟器已经屡见不鲜。然而,一旦踏入硬核的第一人称射击(FPS)游戏领域,现有的世界模型几乎全军覆没。原因在于:FPS 游戏充斥着高达 10-DoF(十自由度)的高频重叠控制信号(如一边奔跑、一边大幅度甩动鼠标视角、一边开火换弹)。传统的大模型在处理这些密集的并行指令时,会陷入灾难性的“动作纠缠(Action Entanglement)”——比如你想让角色开枪,模型却把背景里的天空也渲染出了开火的火光;你想转动视角,模型却把手里的枪管给扭曲了。
为了彻底粉碎这一死锁,腾讯、中国科学院大学(UCAS)、新加坡国立大学(NUS)与北京大学等顶尖机构的联合团队,重磅推出了 SCOPE 架构。这是业界首个专为 FPS 游戏打造的通用交互式世界模型。该研究一针见血地指出,解决动作纠缠的唯一出路是“环境与操作的显式解耦”。团队不仅开源了包含 7 款主流游戏、69K 视频片段的超大规模动作数据集 CrossFPS,更通过创新的 In-Scope / Out-of-Scope 解耦掩码机制,让模型在面对从未见过的游戏场景甚至真实世界第一人称视频时,都能实现完美的 Zero-Shot 交互控制。这是下一代可玩 3D 生成引擎与具身智能数据合成不可不读的纲领性指引。
📷 核心图表
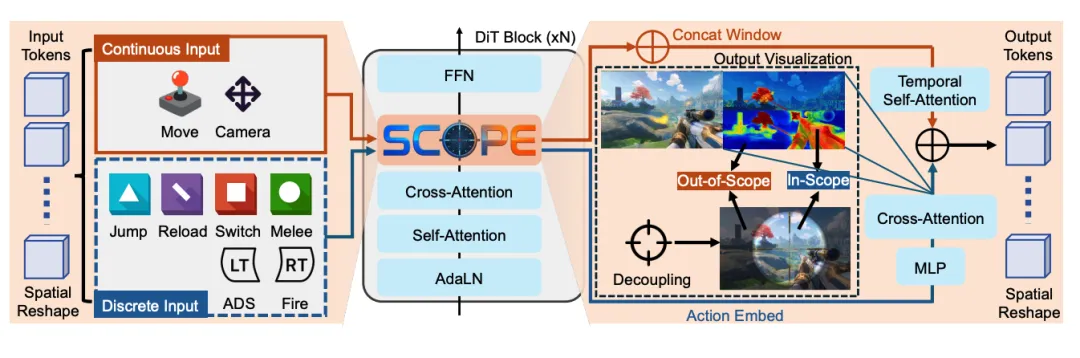
图1 | SCOPE 交互世界模型架构蓝图 注:传统的生成范式将所有动作揉成一团输入给模型。而 SCOPE 的绝妙之处在于引入了“解耦模块(Decoupling Module)”。它通过交叉注意力机制,自适应地生成 In-Scope(前景武器/手部)和 Out-of-Scope(背景环境)的隐式掩码,使得连续的视角移动只作用于背景,离散的开火动作只作用于前景武器,完美实现了多动作指令的并行互不干扰。


图2 | 解耦多动作控制与 Zero-shot 真实世界泛化效果 资料来源:论文定性展示。在复杂的射击与移动并发场景中,基线模型(如 Genie 变体)发生了严重的画面崩坏与枪械扭曲;而 SCOPE 能够严丝合缝地执行并发指令。更震撼的是(Figure 6),仅在虚拟游戏上训练的 SCOPE,竟然能够直接接受真实世界(Real-world)GoPro 拍摄视频的输入,并完美模拟出真实场景下的开火与后坐力交互,展现了恐怖的跨域泛化能力。
📑 核心信息提炼
文献题目: SCOPE: Simulating Cross-game Operations in Playable Environments for FPS World Models(《SCOPE:在可玩环境中模拟跨游戏操作的FPS世界模型》)
作者团队: Zizhao Tong, Yeying Jin, Hongfeng Lai, Kexu Cheng, Ruili Feng, Yan Zhang, Hao Tang, Ling Shao 等(UCAS-Terminus AI Lab, 腾讯, NUS, 浙大, 北大 等)
发表平台: arXiv(2026年5月28日)
核心数据/指标:
首个 FPS 大规模数据集:开源 CrossFPS 数据集,涵盖 7 款顶级 FPS 游戏(如 CS:GO, Apex, 赛博朋克2077等),包含 69K 高质量交互视频片段与精准的 10-DoF 动作标签。 性能断层领先:在 FVD(视频生成质量)和 LPIPS 指标上大幅超越现有的动作条件视频生成基线,操控响应准确率达到工业级可用标准。
核心发现/战绩:
证实了纯粹的特征拼接(Concatenation)无法处理高频离散与连续动作的叠加,必须在注意力层面进行“空间解耦”。 实现了跨游戏(Cross-game)的物理定律迁移:在一个游戏里学会了开枪的后坐力,可以直接应用到另一个画风完全不同的游戏中。
核心创新点:
In-Scope / Out-of-Scope 解耦掩码:无需人工标注遮罩,模型通过自注意力图自发涌现出前景(武器/操作)与背景(环境)的空间隔离。 异构动作注入机制:将连续动作(如相机移动)通过 AdaLN 注入,将离散动作(如射击、跳跃)通过 Cross-Attention 注入,顺应了物理渲染的底层逻辑。
核心主题: 交互式世界模型 (Interactive World Models), 第一人称射击 (FPS), 动作纠缠 (Action Entanglement), 跨游戏泛化 (Cross-game Generalization), 动作解耦 (Action Decoupling)
核心受众: 游戏引擎架构师、具身智能算法工程师、视频扩散模型研究员
❓ 行业发展的 4 大“核心痛点”
“动作纠缠”的物理灾难: 当你向模型同时下达“向右看”和“开火”的指令时,传统模型无法区分这两个动作的空间作用域,导致“开火的火光”被渲染在了远处的建筑上,或者武器随着视角的转动发生了史莱姆般的扭曲融化。 10-DoF 高频重叠信号的降维难题: 相比于自动驾驶的简单方向盘/油门控制,FPS 游戏拥有鼠标的 X/Y 轴连续移动,加上 W/A/S/D 移动,以及射击、换弹等高频离散点击。将这 10 个自由度的数据强行塞进大模型,极易导致“条件忽略(Condition ignoring)”。 视觉-动作数据的“绝对荒漠”: 目前开源界有自动驾驶数据集(如 nuScenes),有机械臂数据集(如 Open X-Embodiment),但极度缺乏高质量、带精确键鼠操作记录的 FPS 游戏世界数据集。 过拟合单体游戏的“井底之蛙”: 现有的可玩模型大多在单一游戏(如 Minecraft)中训练,其学到的物理规律和画风被死死绑定,换一个游戏引擎就直接变瞎,缺乏跨域(Cross-domain)的基础常识。
🔧 核心真相:终极拆解“SCOPE 的四大架构逻辑”
1. 数据真相:CrossFPS 打破“无米之炊”的尴尬
团队构建的 CrossFPS 数据集是该领域的基础设施级贡献。它不仅利用 CV 追踪算法和内存读取技术获取了 7 款截然不同游戏的精准键鼠/摄像机 10-DoF 数据,更为模型提供了学习“通用 FPS 物理定律”的海量素材。
2. 解耦真相:让前景和背景“分道扬镳”
SCOPE 架构的最核心巧思在于 Decoupling Module。它强迫模型明白:离散动作(开枪、换弹)只影响玩家手中的武器(In-Scope),而连续动作(鼠标转动视角)则决定了整个背景环境的平移(Out-of-Scope)。这种基于隐式掩码的空间解耦,彻底斩断了动作纠缠的乱麻。
3. 注入真相:为不同动作量身定制“入口”
既然动作属性不同,就不能走同一扇门。SCOPE 将连续动作(相机视角)整合到时间步嵌入(Timestep embedding)中,通过自适应层归一化(AdaLN)全局调节画面;而离散动作则作为文本/条件序列,通过交叉注意力(Cross-Attention)精准投射到特定区域。
4. 泛化真相:超越像素的“物理逻辑提纯”
因为模型在 7 款画风迥异的游戏中被强行要求提取“开火”、“移动”的共同物理表现(如后坐力的画面震动、枪口火焰的瞬时照亮),它最终剥离了具体的游戏材质,掌握了纯粹的 FPS 交互法则。这也是为什么它能在真实世界(Real-world)视频中 Zero-shot 发挥作用的原因。
📊 关键内容与数据看板
表1:主流交互式生成模型与模拟器范式对比
| FPS 多重控制引擎 | SCOPE (Ours) | 极高 (10-DoF 并行) | 完美 (In/Out-of-Scope) | 极强 (支持 7 款游戏及真实世界) |
表2:生成质量与动作控制准确度核心评测
| SCOPE (Ours) | 421.3 | 0.502 | < 2% | 以断层优势碾压,确立了 FPS 交互生成的新 SOTA |
注:在消融实验中,一旦移除解耦模块(Decoupling Module),模型在并发动作下的 FVD 瞬间崩盘,无可辩驳地证明了“空间特征解耦”对于高维并发交互的决定性价值。
💬 深度 Q&A
Q1:In-Scope(前景)和 Out-of-Scope(背景)的掩码,是靠人工逐帧去扣绿幕标注出来的吗?A: 绝对不是!这也是 SCOPE 工程美学的一大体现。团队根本没有提供任何前景掩码的 Ground Truth。模型是在海量的交互训练中,通过自注意力机制(Self-Attention)的特征聚类,自发涌现(Emergent)出了区分“随视角移动的静止背景”和“由于射击产生高频突变的前景武器”的能力。这是一种极其优雅的无监督物理发现。 Q2:为什么这种针对打游戏的 FPS 世界模型,对严肃的“具身智能”也有巨大价值?A: 具身智能本质上也是在解决第一人称视角(Egocentric view)下的高维并发交互问题(比如机械臂一边移动底盘、一边转动摄像头、一边用夹爪抓取)。FPS 游戏里的“跑动+转视角+射击”与具身操作在数学空间上是高度同构的。SCOPE 的解耦范式,直接为双臂协同、多模态感知的机器人提供了一个完美的预测框架雏形。 Q3:目前 SCOPE 能够支持 60 FPS 的纯实时可玩吗?A: 现阶段的 SCOPE 基于视频扩散模型(Video Diffusion Models),在单步推理上依然面临扩散去噪的固有延迟,距离 60 FPS 还有工程距离。但由于其架构已经彻底理顺了因果和解耦逻辑,下一步只要挂载一致性模型(Consistency Models)或进行 1-step 蒸馏,配合流式推理,实现电竞级的实时生成已经是触手可及的未来。
🎯 深度点评
核心贡献: 腾讯与北大的这篇力作,撕开了限制交互式世界模型走向高频、复杂操作环境的最后一道封印。SCOPE 不仅是一个算法框架,更通过开源 CrossFPS 数据集,为整个社区提供了从“单向看视频”向“深度玩视频”跨越的核燃料。 亮点总结:① 克制的解耦美学:用极其清晰的 In/Out-of-Scope 思路,将一团乱麻的高维指令在隐空间梳理得井井有条。 ② 异构信号的分流:深谙物理引擎之道,为连续相机和离散动作分配了最契合的特征注入入口。 ③ Zero-Shot 降维打击:模型内化了“射击”和“视角”的物理本质,跨游戏甚至跨越到真实世界的能力令人叹为观止。 不足与局限:面对游戏中极长视距的探索(如在广袤的大逃杀地图中长途奔袭),基于局部视频窗口生成的扩散模型依然容易患上“环境遗忘症”(走过的路回头就不见了)。引入全局记忆机制(Global KV-Cache 或 3D Voxel 先验)是其走向终极引擎的必修课。
🌟 总结金句
真正的世界模型绝不是吞噬一切指令的黑洞,而是深谙万物物理边界、在隐空间里让每一次拨动摇杆都泾渭分明的秩序引擎。
📌 互动引导
在迈向“AI 实时生成的 3D 游戏宇宙”的进程中,您认为目前最卡脖子的瓶颈在哪里?
✅ A. 动作纠缠与物理逻辑:就像 SCOPE 解决的痛点,模型总把枪和天空融化在一起!
✅ B. 实时算力与帧率:扩散模型太慢了,达不到 60 FPS 根本算不上“可玩”!
✅ C. 长时序环境记忆:转个身房子就变了,缺乏 3D 空间的一致性和持久性记忆!
✅ D. 大数据从哪里来:游戏种类太多,无法获取涵盖所有引擎的高质量交互数据!
欢迎在评论区留下你的真知灼见! 👇
🧩 研究方向展望
针对冲刺 CVPR / NeurIPS / ICLR 等顶级会议的计算机视觉、多模态与强化学习研究者,基于 SCOPE 论文提供以下延伸思路:
基于 3D 几何先验的长时序 Out-of-Scope 记忆增强 (Geometry-aware Consistent Background Generation): 针对 SCOPE 在长时序下背景可能发生漂移的问题。探索将 3D Gaussian Splatting 或全局场景体素(Voxel)作为外部记忆库,与 Out-of-Scope 的相机运动分支进行深度绑定。让模型在进行连续转角或回头操作时,能从显式的 3D 记忆中提取特征,实现具有绝对空间一致性的无限长视频交互,适合投递 CVPR或ICCV。具身智能第一人称视野下的双手协同解耦 (Bimanual Decoupling via Scope-like Masking): 将 SCOPE 的前景/背景解耦思想迁移至机器人的双臂协同控制(Bimanual Manipulation)。在不提供明确分割掩码的前提下,利用自注意力聚类设计 Left-Arm-Scope, Right-Arm-Scope 和 Environment-Scope 的三分框架。解决大模型在端到端控制双臂时互相干扰的“动作纠缠”问题,适合投递 CoRL或ICLR。结合流匹配的 1-Step 实时可玩架构演进 (Real-time Playable Engine via Consistency Flow Matching): 利用 SCOPE 已经建立的良好 10-DoF 物理表征,在扩散模型的后端引入一致性蒸馏(Consistency Distillation)或流匹配(Flow Matching)技术。探索如何在仅用 1-2 步去噪的极端算力限制下,依然维持 In-Scope 的高频动作准确渲染,打造出真正意义上支持 30+ FPS 的开源游戏级神经渲染引擎,为高分论文立意,适合投递 NeurIPS或ICML。
