 夜雨聆风
夜雨聆风论文解读 | Computer Use Agent、可验证奖励强化学习、任务和轨迹数据构造 SOP
导语 如果我们希望 AI 不只是回答问题,而是真的能打开软件、读屏幕、点按钮、改文件、发邮件,那么它该如何训练?CUA-Gym 的答案是:先搭出一个可复现、可验证、可规模化的“电脑训练场”。 |

1. 背景:RLVR 很成功,但 GUI 智能体还缺训练场
过去两年,可验证奖励强化学习(RLVR)已经在数学、代码、工具调用和终端任务里证明了价值。它的基本思路很直接:给模型大量任务,让模型自己尝试;只要结果能被程序稳定验证,就可以用奖励信号继续优化。
但电脑使用智能体(Computer-Use Agents,简称 CUA)不一样。它不是只输出一段答案,而是要在真实或模拟的电脑环境中完成一串操作:看截图、移动鼠标、点击菜单、输入文本、保存文件,最后让环境进入正确状态。
这意味着,一个 CUA 训练样本至少包含三部分:自然语言任务、可执行的初始环境、可以判断任务是否完成的奖励函数。少任何一个,强化学习都很难稳定进行。
一句话理解 数学题的奖励可以是“答案是否等于 42”;GUI 任务的奖励则要检查文件、应用状态、网页数据和跨应用结果。这就是 CUA 数据难做的根本原因。 |
2. 动机:不是模型不会学,而是缺少可验证数据
论文认为,CUA 训练遇到的瓶颈首先是数据结构性的,而不是算法性的。手工构造一个高质量 GUI 任务,往往要准备文件、配置软件、写检查脚本,还要反复验证初始状态和目标状态是否一致。这件事很贵,也很难覆盖大量应用。
已有方法大致有三类:第一类是人工 benchmark,奖励可信但规模小;第二类是让 VLM/LLM 当 judge,覆盖面大但噪声高;第三类是网页 mock 环境配程序化奖励,但往往局限在浏览器场景,很难覆盖桌面软件和跨应用工作流。
CUA-Gym 的动机就是把这三件事同时拉起来:奖励要可验证,环境要可复现,任务还要能规模化生成。换句话说,它想把 GUI 智能体训练从“手工出题”推进到“自动化生产训练场”。
3. 贡献:数据、环境、模型和 scaling 证据
论文的贡献可以拆成四层。
第一,提出 CUA-Gym 数据合成流水线。它可以联合生成任务指令、初始环境、golden 环境和程序化奖励,并通过 Generator / Discriminator 的隔离式对抗流程降低 reward hacking。
第二,发布 CUA-Gym 数据集。最终数据包含 32,112 个 verified RLVR 训练 tuple,覆盖 110 个环境,其中包括桌面应用和合成网页应用。
第三,构建 CUA-Gym-Hub。这是 94 个可注入状态、可重置、可并发运行的 mock web apps,覆盖通信、项目管理、CRM、电商、云服务、数据分析等知识工作场景。
第四,证明规模化数据确实能带来性能收益。用 GSPO 在 CUA-Gym 上训练后,A3B 和 A17B 模型在 OSWorld-Verified 上分别达到 62.1% 和 72.6%,并且在 WebArena 上也有迁移增益。
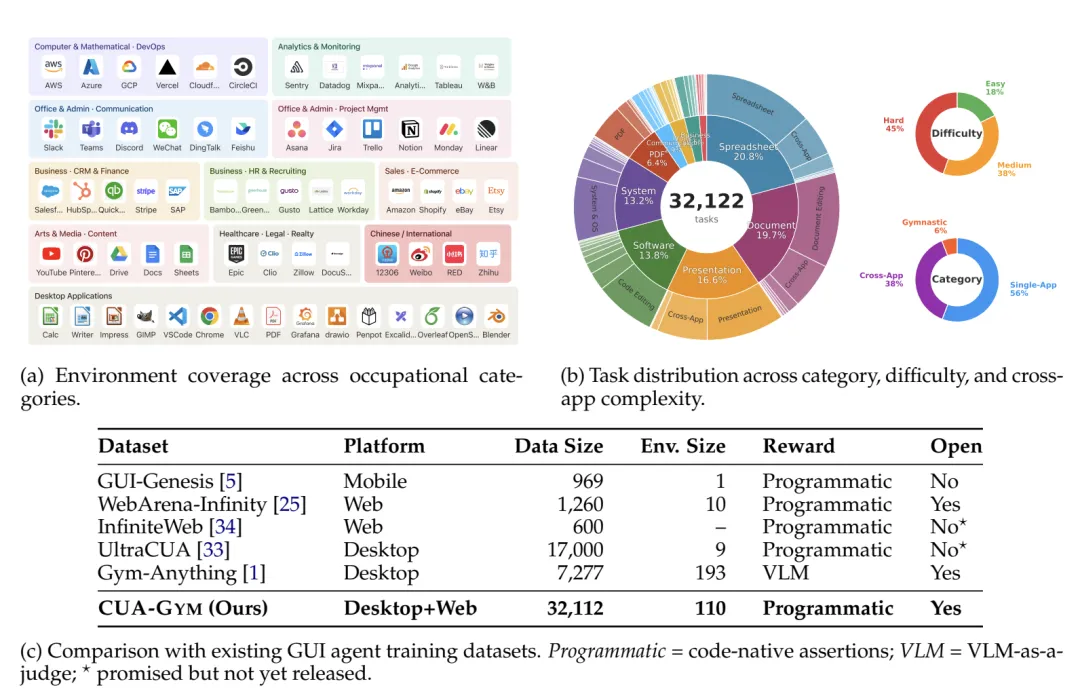
图:CUA-Gym 的环境覆盖、任务分布和与已有数据集的对比
4. 方法:把任务、环境和奖励一起生成
4.1 Tuple数据生成:Generator 和 Discriminator 分工
CUA-Gym 把每条训练数据定义为一个 tuple:任务 t、初始状态 s、奖励函数 r。难点在于,这三者必须互相一致。比如任务要求“把员工 ID 补成 5 位”,初始文件里就要有待处理 ID,golden 文件里要有正确公式,reward.py 还要能检查公式格式和单元格引用。
流水线里有两个关键代理。Generator 负责实现出 initial_setup.py 和 golden_patch.py,分别构造初始环境和正确完成后的 golden 环境。Discriminator 则在隔离环境中,只根据任务语义和状态视图写 reward.py,不能读取 Generator 的脚本。
这种 information barrier 很重要:如果同一个 agent 同时写 golden state 和 reward,它可能写出“检查自己实现痕迹”的奖励,而不是真正检查用户目标。隔离后,reward 必须从任务语义出发。
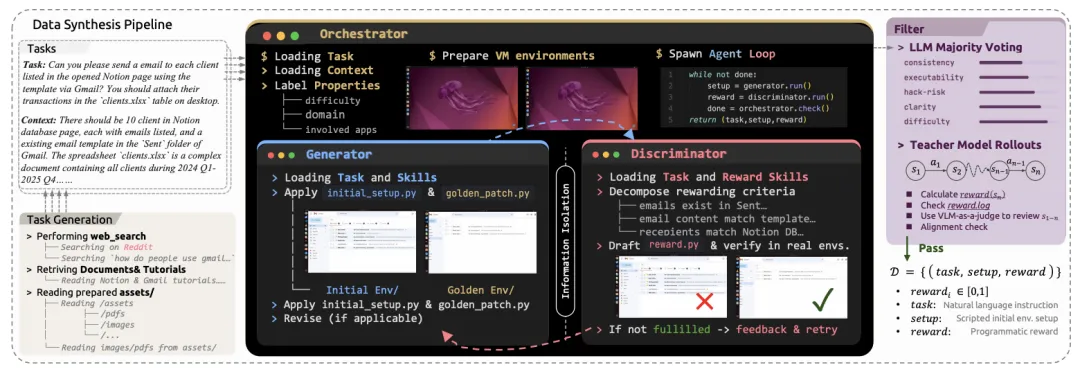
图:CUA-Gym 的数据合成流程。Generator 生成初始/标准状态,Discriminator 独立生成奖励函数
4.2 五个通过条件:让 tuple 至少在端点上可信
initial_setup.py 能在初始 VM 上跑通。
golden_patch.py 能在 golden VM 上跑通。
reward(golden) 必须等于 1.0。
reward(initial) 必须等于 0.0。
reward.py 不能包含明显作弊模式,例如硬编码成功、只检查文件存在、用 subprocess 做不可复现检查等。
如果不满足条件,Discriminator 会写 REVIEW.md,把失败原因反馈给 Generator 继续修改;最多迭代 5 轮,仍失败则丢弃。
4.3 第二层过滤:LLM 多数投票 + teacher rollout
内层循环只能保证 initial/golden/reward 三者在端点上对齐,但不能完全发现任务歧义、不可解任务或奖励过窄的问题。因此,论文又加了数据集级过滤。
第一阶段是 LLM majority voting。多个 critic 从一致性、可执行性、hack 风险、清晰度、难度等角度打分。第二阶段是 teacher-model rollout:让强 teacher 模型真实执行任务,再同时比较程序化奖励和 VLM-as-a-judge 的视觉判断。只有两类信号都相对一致,样本才进入最终数据集。
4.4 环境生成:CUA-Gym-Hub
真实网站很难直接用于 RL 训练:有登录、权限、限流、不可控状态、第三方接口和网络波动。CUA-Gym-Hub 因此合成了 94 个 mock web apps。这些应用保留目标软件的主要交互结构,但去掉真实账号、真实网络和不可控服务。
每个 mock app 都有统一状态 API,可以注入初始状态、读取当前状态、计算 state diff、上传文件,并通过 sid 做会话隔离。这样,同一个应用可以并发支持很多 RL worker,每个任务看到的是自己的世界。
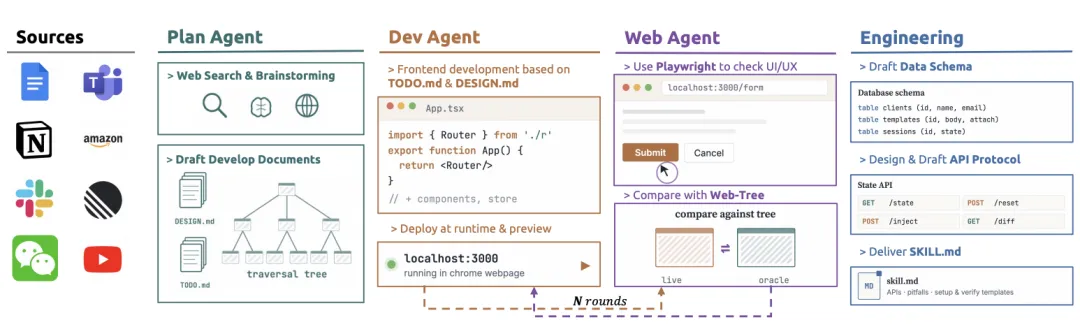
图:mock 环境合成流程。Plan Agent 规划,Dev Agent 实现,Web Agent 用 Playwright 验证
4.5 训练:SFT warm-up + GSPO
模型训练分两步。第一步,用强 teacher 在同一任务池上 rollout,只保留 reward=1 的成功轨迹,得到 3,578 条 SFT 轨迹,用来做 warm-up。第二步,用 GSPO 做 RLVR 训练。
GSPO 的做法是:同一个任务采样多条轨迹,每条轨迹用程序化 reward 打分,再在组内比较谁更好。它使用序列级 importance ratio,更适合这种长轨迹、多动作、混合专家模型的训练场景。
由于 GUI 轨迹很长、截图很多,论文还设计了 trajectory slicing:旧截图折叠成占位符,近期截图和动作保留完整多模态信息。这样既控制上下文长度,又不完全丢失后半段任务的训练信号。
5. 实验:性能提升、规模效应和一个意外能力
5.1 主结果:OSWorld-Verified 明显提升
论文在两个 Qwen3.5 MoE backbone 上训练:Qwen3.5-35B-A3B 和 Qwen3.5-397B-A17B。训练后的小模型 CUA-GYM-A3B 在 OSWorld-Verified 上从 54.5% 提升到 62.1%,提升 7.6 个百分点;大模型 CUA-GYM-A17B 从 62.2% 提升到 72.6%,提升 10.4 个百分点。
WebArena 上也有迁移:A3B 从 40.8% 到 44.5%,A17B 从 54.0% 到 56.0%。这个增益比 OSWorld 小,但说明 mock web apps 训练出来的能力并非只会背合成环境。

图:主实验结果。RLVR 训练同时提升 A3B 和 A17B,在 OSWorld-Verified 上收益最明显
5.2 数据越多,RL 上限越高
论文用 1.4K、3K、12K 三个数据子集训练同一个 A3B 模型。结果显示,数据越多,OSWorld-Verified 分数和训练 reward 都更高,而且 12K 曲线没有出现明显饱和。
这说明在论文考察的规模内,CUA 的可验证 RL 数据仍然处于“多给还会涨”的阶段。对 GUI agent 来说,数据供应可能仍是比模型结构更紧的瓶颈。
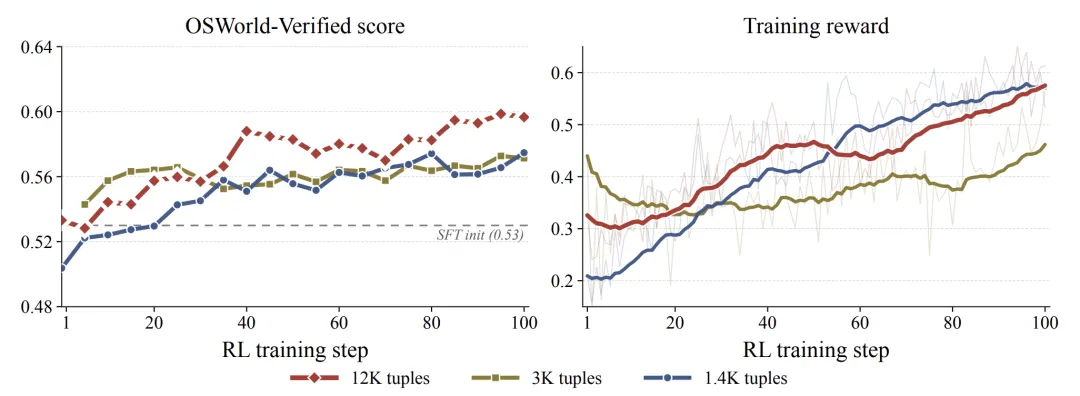
图:数据规模越大,训练曲线越高,12K tuple 尚未明显饱和
5.3 环境多样性也是独立变量
作者还单独考察了环境数量。固定 3K 轨迹时,80 个环境比 10 个环境更好;在 80 个环境上把轨迹数从 3K 加到 6K 又继续提升。
这说明“多任务”不能完全替代“多环境”。模型需要见过足够多的软件结构、状态组织方式和交互范式,才能把能力迁移到新任务。
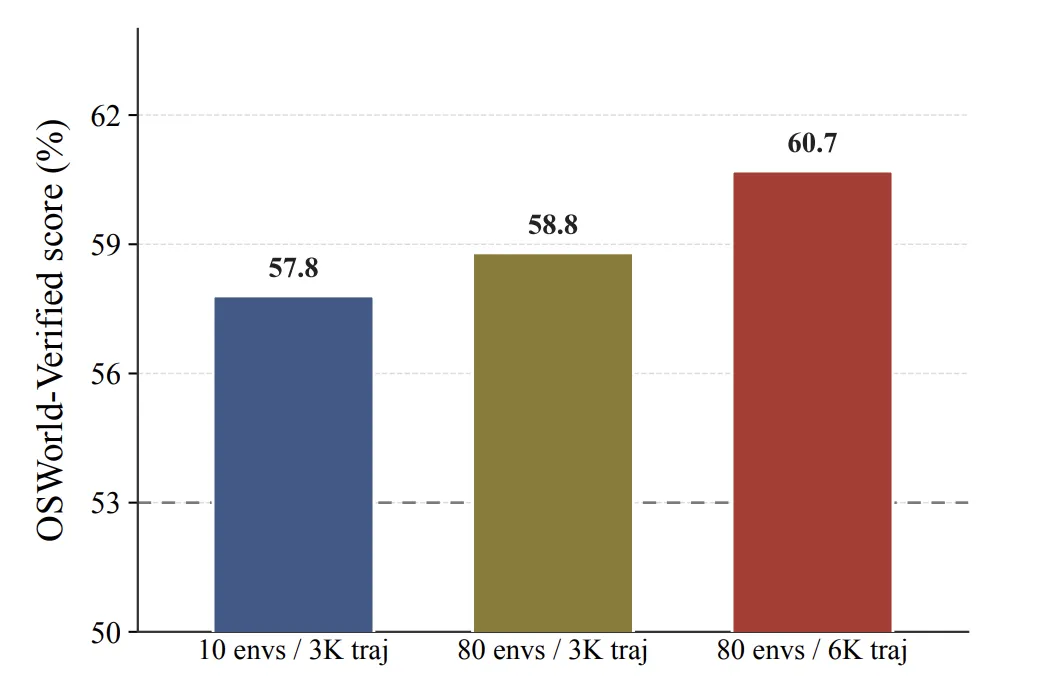
图:环境数量和轨迹数量共同贡献性能,环境多样性不能只靠重复轨迹替代
5.4 意外现象:模型学会了把多个动作打包
训练后,模型自发学会了在一个 model step 里发出多个 tool call。SFT 初始模型通常一步一个动作;RL 后平均上升到 1.4 到 1.9 个动作,轨迹长度在同等任务表现下缩短 33% 到 45%。
这不是作者显式奖励的行为,而是 step budget 和相对优势估计共同推动出来的。模型会把确定性的动作链打包,比如菜单导航、表单填写、键盘快捷键;但遇到需要观察反馈的动作,仍然倾向于单步执行。
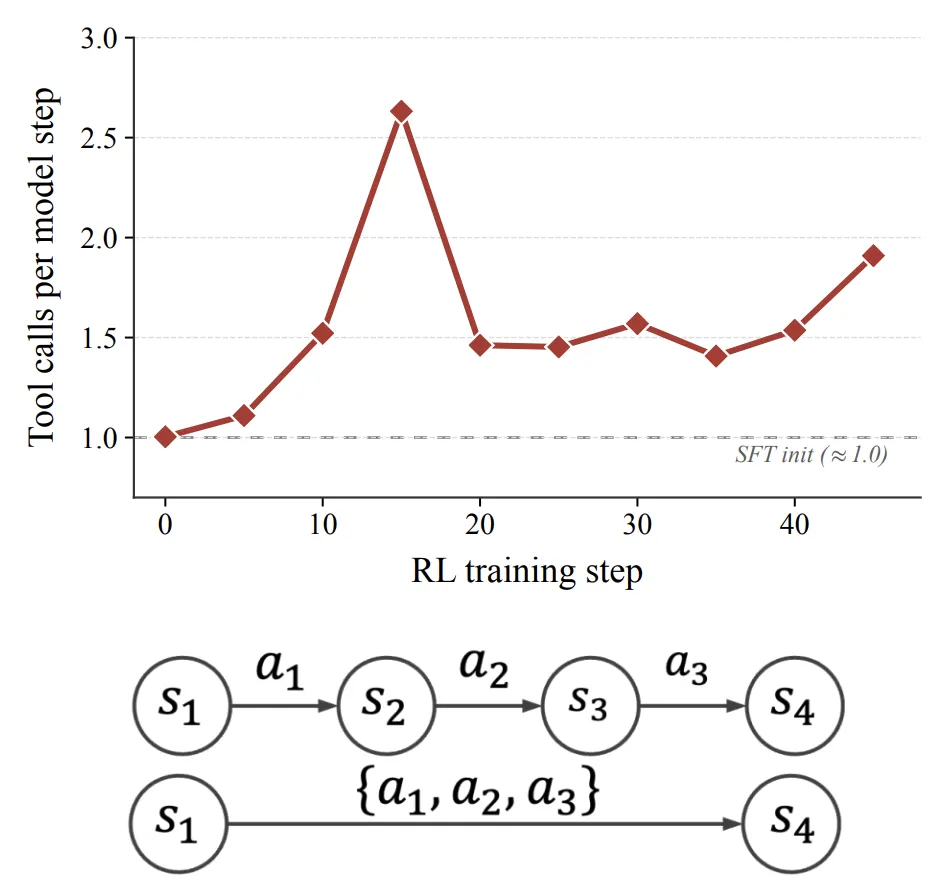
图:RL 过程中自发出现 multi-action batching,提升执行效率
6. 结论:这是一篇“训练基础设施”论文
CUA-Gym 的核心意义,不只是发布了一个更大的数据集,而是给 GUI 智能体训练提供了一套可扩展的基础设施思路:任务、环境、奖励函数必须共同生成;奖励要尽量程序化;环境要能注入状态、重置和并发;过滤要同时看静态一致性和真实 rollout。
从结果看,RLVR 这套在数学和代码领域奏效的 recipe,确实可以迁移到电脑使用智能体上。尤其是 OSWorld-Verified 的提升,说明可验证交互任务能给模型带来实质能力增益。 但论文也没有回避局限:reward 主要检查最终状态,无法完全判断过程是否“干净”;mock 环境仍然不是完整真实世界;最大规模训练多为单 seed,统计稳健性仍需更多复现。
如果把这篇论文放在更长的技术脉络里看,它的信号很清楚:未来的 CUA 竞争,可能不只是谁的模型更大,而是谁能搭出更大、更真实、更可验证的交互训练场。
总结 CUA-Gym 让我们看到一种可能:当 AI 要进入真实软件世界,最稀缺的也许不是又一个更会聊天的模型,而是一套能让它反复试错、稳定计分、持续进化的电脑训练场。 |
参考链接
论文:https://arxiv.org/abs/2605.25624v1
项目主页:https://cua-gym.xlang.ai
数据:huggingface.co/datasets/xlangai/CUA-Gym
代码:https://github.com/xlang-ai/CUA-Gym
环境库:https://github.com/xlang-ai/CUA-Gym-Hub
