 夜雨聆风
夜雨聆风一款能看、能想、能动手的多模态智能体模型 Qwen3.7-Plus 发布,它不止“看图说话”,更能看懂界面、操作应用、生成代码、交付结果。
在 Qwen3.7 强大文本与 Agent 能力的基础上,我们将视觉与语言深度融合,打造一体化智能体基座的多模态模型。让 AI 不再只是“读懂世界”,更能动手改变世界。
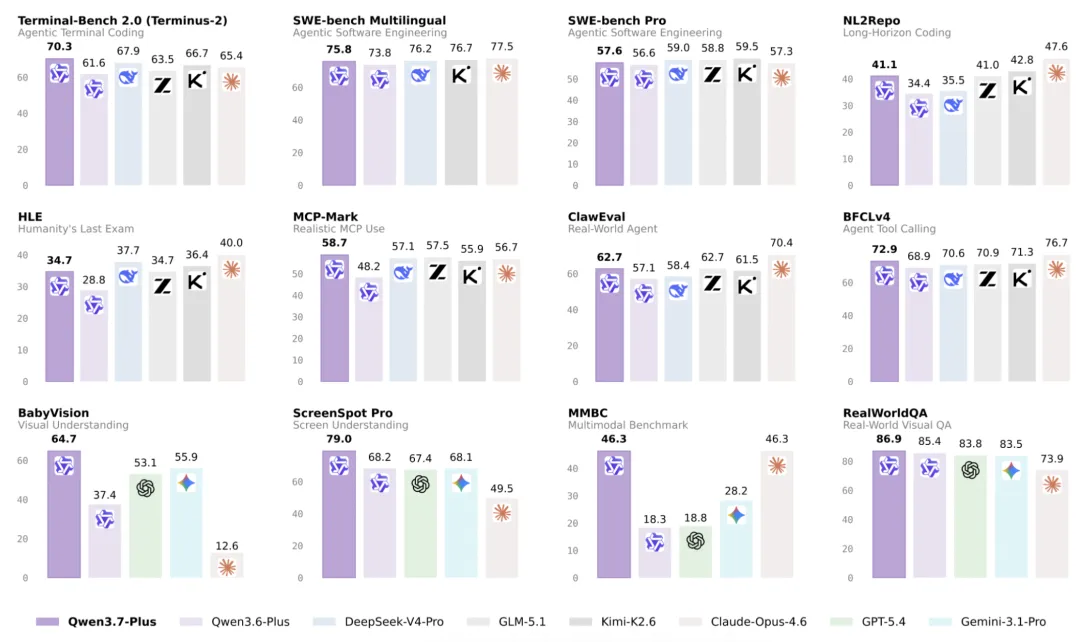
Qwen3.7-Plus 在 12 项核心基准测试中的综合表现
下面我们通过几个真实场景,带你了解它的核心能力。

Qwen3.7-Plus 作为一个多模态混合智能体,不仅能看懂图形界面、文档、真实场景,还能直接上手操作,同时可以调用命令行、自主编写代码并验证结果。我们将 GUI 操作、CLI 调用、代码生成、自我验证全部放进同一个智能体循环里,真正实现“看、想、写、做、验”的端到端闭环。
为了验证实际落地能力,我们让 Qwen3.7-Plus 独立完成了一个完整的软件开发项目。
基于它构建的智能体系统(Hybrid‑Agent)会自己写代码、自己操作界面、自己运行测试、自己迭代版本——全程不需要人帮忙。
在实测中,这个系统连续稳定运行了 11 小时以上,自动完成了一款英语单词学习 APP 的完整研发闭环:累计生成代码超过 10000+ 行,触发调用超过 1000+ 次,覆盖了从需求文档生成、代码编写、自动部署、测试用例创建、GUI 自动化测试、多场景并行测试,到产品说明更新和版本迭代的全部环节。
在桌面应用场景中,Qwen3.7-Plus 同样展现了端到端交付能力。
让它复刻 macOS 原生 Stocks(股市)应用:它会自主交互原应用并理解 UI 布局与功能细节,基于交互记录自动生成 SwiftUI 源码,接入 LongBridge 真实行情 API 获取实时市场数据,自动编译构建并启动复刻应用。
随后自主执行 10 项功能验证测试——包括实时行情加载、股票选择与切换、多周期视图切换、搜索过滤、详细数据面板展示等——全部通过。最终交付的应用完整复现了原生 Stocks 的暗色主题、分栏布局、实时行情数据与完整交互体验,实现高保真一键复刻。

🔹 多模态推理
面对“找不同”“华容道”“迷宫”“拼图”这类需要推理的视觉任务,Qwen3.7-Plus 会先精准提取图像中的几何结构与空间约束,将视觉问题“翻译”为可计算的逻辑,随后自主调用代码解释器,编写并执行求解程序。全程实现视觉感知 → 空间建模 → 代码求解 → 结果校验的自动化闭环。
🔹 搜索增强视觉问答
当问题超出图像本身,它能无缝联动搜索增强。从单图/多图/视频中提取关键实体与上下文线索,自动联网检索外部知识,将“视觉证据”与“最新信息”交叉验证。无论是识别陌生地标、追溯事件背景,还是分析复杂商品参数,都能一步到位给出有据可查的答案。

除了能“看懂”视觉内容,Qwen3.7-Plus 还能将其直接“翻译”为可执行代码,打通设计到开发的最后一公里。
🔹 图像/视频转 SVG
面对图标、插画或动效参考,Qwen3.7-Plus 能精准理解几何结构、颜色层级、布局关系与动态变化,将其转化为结构清晰、可二次编辑的 SVG 矢量代码。对于图形设计与信息可视化场景,大幅降低从视觉参考到可编辑代码资产的转换成本。
请根据视频生成 SVG 代码(下方demo最左侧为初始视频)。
🔹 视觉驱动的网页设计
不止于静态复刻。基于参考图、视频素材或设计意图,Qwen3.7-Plus 能自动组织页面布局、编写前端代码、处理交互动效,并智能调用工具补全缺失素材。从“给一张图”到“生成一个可交互、能跑通的网页原型”,前端开发效率大幅提升。

我们基于 Qwen3.7-Plus 构建了浏览器智能助手,并通过 Qwen for Chrome 浏览器插件提供直观体验。
安装后,你可以在浏览器侧边栏中直接与 Qwen 对话,授权后切换至 Agent 模式。在该模式下,Qwen 能感知当前网页内容、理解任务意图、规划操作步骤,并在真实浏览器环境中自动执行点击、输入、跳转、配置和验证,完成页面感知 → 任务规划 → GUI 自动化执行的完整闭环。
ECS 采购自动化:面对非技术用户「采购一台最便宜的云服务器」需求,Agent 直接登录云控制台:自动比价、选型、配置镜像与安全组、确认订单。遇到缺货或价格波动,它会主动反思并动态调整策略,直到任务达成。
运维链路闭环:采购完成后,无缝衔接停机→配置调整→磁盘扩容→服务恢复→结果验证。原本需要反复切换页面、手动排查的繁琐流程,被转化为连续、高效、可交付的浏览器自动化任务。

Qwen3.7-Plus 在真实世界感知与多模态推理方面表现出色。真实场景往往比标准图像问答更复杂:画面中可能存在遮挡、杂乱背景、小目标、多对象关系、跨图对比和隐含物理常识。
以下方地铁线路图为例,面对密集交错的复杂图表,模型能精准定位起止点,自动解析线路颜色与换乘逻辑。它会自主规划路径:沿主线行进、识别换乘节点、切换线路并逐站追踪,快速输出完整路线。
面对真实场景的复杂考验,我们针对性地重构了模型底层能力。
Qwen3.7-Plus 围绕多模态智能体核心需求进行系统性升级:从看懂复杂视觉输入 → 基于视觉进行推理 → 调用工具解决问题 → 在代码或 GUI 环境中执行任务。
🔹 多模态推理
模型于 BabyVision、MathVision、HiPhO 等高难度基准上表现强劲,全面强化了对图像细节、空间关系、物理常识与多步逻辑的综合理解。尤其在 BabyVision 任务上较前代显著提升,标志着模型在类人视觉认知与空间推理方面具备了更强的泛化能力。
🔹 视觉智能体与编程
ScreenSpot Pro、AndroidWorld 等评测分数显著提升,证明模型不仅能精准识别屏幕内容,更能定位关键 UI、理解用户意图并完成多步交互。结合 QwenVision2Code 展现的端到端视觉转代码能力,模型已真正打通从“看懂界面”到“操作界面”乃至“构建界面”的核心链路。
🔹 多模态搜索与知识问答
SimpleVQA、WorldVQA 等基准表现均有明显增强。模型突破“仅依赖图像”的限制,能将视觉线索与外部知识检索深度融合。面对开放世界问题,不再止步于“图里有什么”,而是交叉验证视觉证据、常识与实时信息,输出更可靠的答案。
🔹 通用视觉理解
模型扎实覆盖真实场景解析、复杂文档/图表阅读、高精度 OCR、目标计数与空间定位。在 RealWorldQA、OmniDocBench、OCR-Bench-V2 等基准上表现亮眼,确保模型能稳定处理企业级高频输入,包括财务票据、技术报告、商品海报,复杂 UI 页面。
此外,Qwen3.7-Plus 在视频理解与驾驶场景能力上同步进阶。在 VideoMMMU、MLVU 等长短视频基准中,精准捕捉事件演进、动作时序与语义关联;在 LingoQA、SURDS 等驾驶评测中,强化了对动态环境、交通参与者与空间关系的感知力,为下一代具身智能与自动驾驶应用筑牢感知底座。
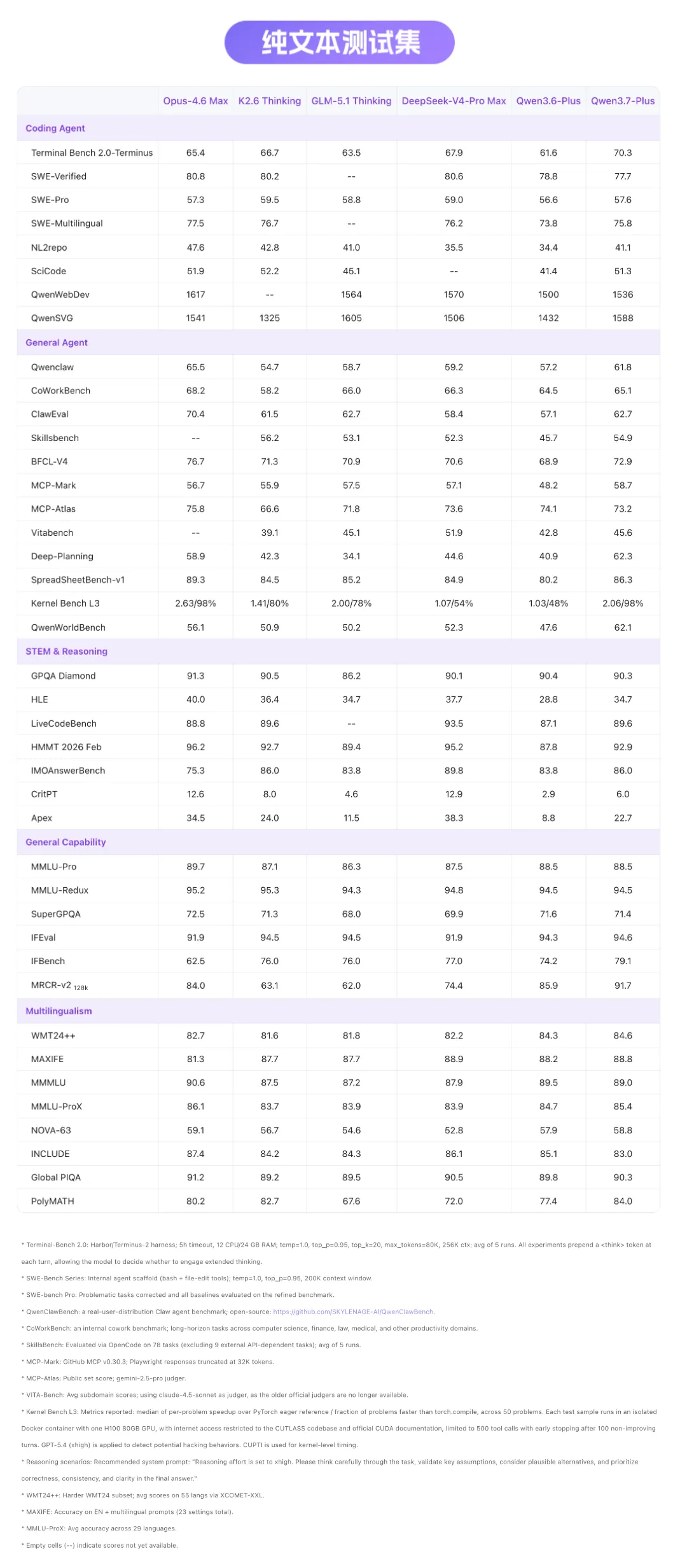
⬆️ 下滑查看「纯文本测试集」完整分数图 ⬆️
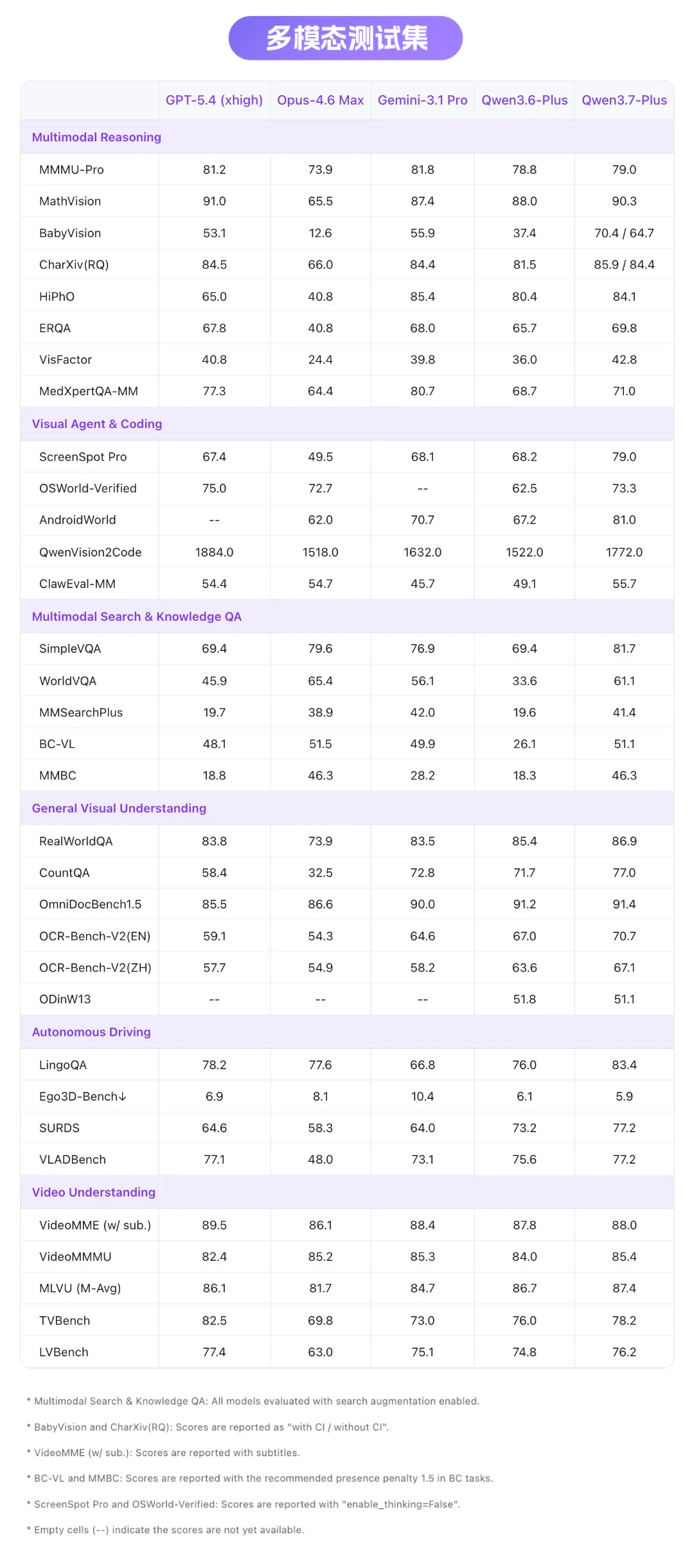
⬆️ 下滑查看「多模态测试集」完整分数图 ⬆️
快速体验 Qwen3.7-Plus
Qwen3.7-Plus已在阿里云百炼平台上线,支持 OpenAI 兼容 API 与 Anthropic 协议。你可以直接调用 API 完成多模态交互、智能体任务和视觉编程等场景,也可以通过 Claude Code、OpenClaw 或 Qwen Code 直接调用,即插即用,无需修改原有 Prompt 或工具链。
从图形界面到真实世界,从代码生成到浏览器自动化,Qwen3.7-Plus 在多模态智能体方向迈出了扎实的一步。我们期待看到大家基于 Qwen3.7-Plus 构建应用,如果在使用过程中遇到任何问题,或有改进建议欢迎评论区随时反馈。
API:https://bailian.console.aliyun.com/cn-beijing/?tab=model#/model-market/detail/qwen3.7-plus?serviceSite=asia-pacific-china
 Qwen3.7-Max 重新定义 AI Agent 基座
Qwen3.7-Max 重新定义 AI Agent 基座 从透明开发到系统工程:AgentScope 2.0 发布
从透明开发到系统工程:AgentScope 2.0 发布