 夜雨聆风
夜雨聆风👆 点击上方「迷斯特的小宇宙」,加「星标」不错过精彩内容
RAG 的质量问题,很多时候从 PDF 被读成一坨字符串的那一刻就已经开始了。
这两年做 RAG 和 Agent,大家很容易把注意力放在 embedding、向量数据库、rerank、上下文窗口、Agent 框架上。它们都重要,但在真实文档场景里,还有一个更早的环节经常被低估:文档解析。
run-llama/liteparse 这次冲上 GitHub Trending Rust,信号不在于“又多了一个 PDF parser”。它更像是把一个原本藏在后台的环节推到前台:PDF、Office、图片、扫描件这些非结构化输入,能不能被稳定、快速、可追溯地转换成模型可以使用的结构化上下文。
如果解析层做得粗糙,后面的向量库只能检索到粗糙的文本。标题丢了,表格散了,页码没了,引用位置不可回溯,Agent 再会调用工具,也只能在坏输入上做推理。
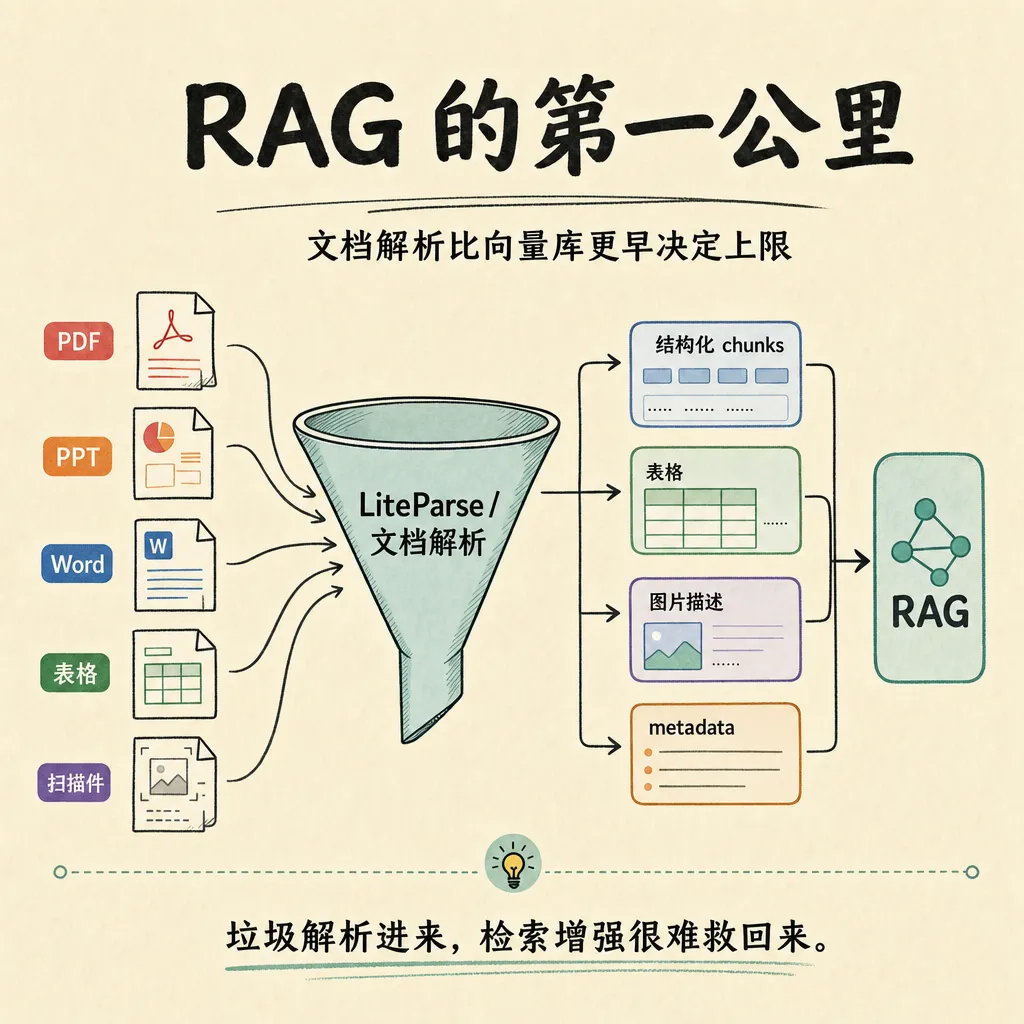
图 1:RAG 文档解析第一公里
第一公里
RAG 的第一公里,是从原始文件到可检索上下文的那段路。
这段路通常包括几个步骤:文件读取、格式转换、文本抽取、OCR、版面恢复、坐标保留、chunk 切分、metadata 标注。很多系统会把这些步骤压缩成一句“把 PDF 转成文本”,但工程上差别很大。
一个普通 PDF 可能包含原生文字、图片、表格、页眉页脚、脚注、多栏排版、嵌入字体和扫描页。Office 文档还会带来标题层级、批注、表格、分页和导出差异。网页则有导航、广告、正文、动态内容和 DOM 顺序问题。
这些东西在向量库之前就已经决定了三件事:
• 模型到底能看到什么事实;
• 检索时能不能定位到正确片段;
• 用户追问“出处在哪”时,系统能不能回到原文位置。
向量库负责召回,文档解析负责把事实变成可召回的形态。前者解决“去哪找”,后者决定“有没有东西可找”。
LiteParse 的位置
LiteParse 的官方定位很明确:本地运行、开源、无云依赖、无 LLM、无需 API key 的高速文档解析工具。它用 Rust 写核心链路,围绕 PDFium 做文本抽取,配合 Tesseract 或外部 OCR server 做识别,最后输出文本、JSON、bounding boxes 和页面截图。
它不负责把文档“理解”成业务字段,也不靠多模态模型重写整份 PDF。LiteParse 解决的是一个更基础的问题:把文档页面上的文字、位置和页面图像稳定取出来,并尽量保留空间关系。
这点对 Agent 很关键。Agent 经常需要的不止是一段 Markdown,还包括可回溯的位置证据:
• 这句话在第几页;
• 这条数据来自表格哪一行;
• 这个引用能不能高亮到原文区域;
• 用户上传了 200 页 PDF,能不能先快速抽取,再按需截图给视觉模型。
LiteParse 的 textItems、bounding boxes 和 screenshot 能力,正好面向这类工作流。解析结果里有坐标,截图里有页面图像,系统就可以把“文本答案”重新绑定到“页面位置”。这比只给模型一段纯文本更适合做可审计的 RAG。
结构很轻
LiteParse 的核心链路可以简化成四层。
第一层是输入适配。PDF 直接进入解析;DOCX、XLSX、PPTX 和图片会先通过 LibreOffice / ImageMagick 转成 PDF。这样核心逻辑可以集中在 PDF 页面模型上。
第二层是文本抽取。PDFium 负责从 PDF 里取出原生文字和页面结构。对于 born-digital PDF,这条路径通常比纯 OCR 更快,也能少引入识别错误。
第三层是 OCR。默认使用 Tesseract,也可以外接 HTTP OCR server。LiteParse 定义了一个很简单的 OCR API:POST /ocr,上传图片和语言,返回文本、bbox、confidence。团队可以把 EasyOCR、PaddleOCR 或自研 OCR 包成同一接口。
第四层是空间恢复。LiteParse 会把原生文本和 OCR 结果合并,再做 grid projection,输出带版面关系的文本或 JSON。
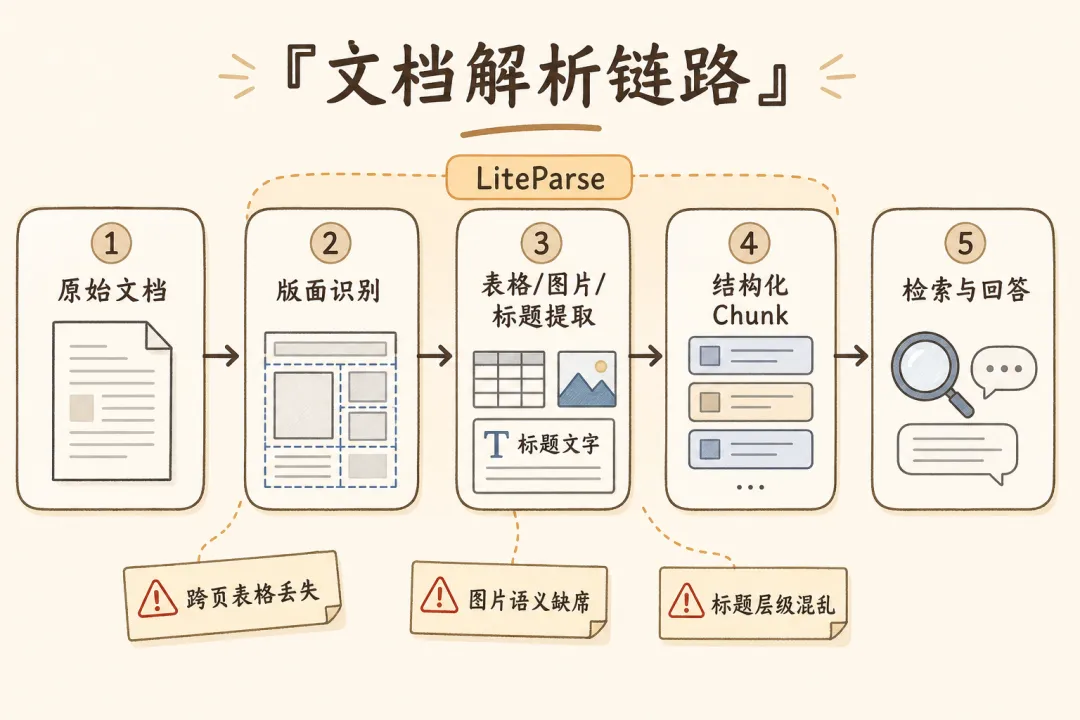
图 2:LiteParse 解析链路
这套结构的好处是工程边界清楚:解析器不承担所有智能任务,只把“页面上有什么、在哪里”稳定交给后面的 RAG / Agent。复杂理解可以留给后续模型,原始定位信息不要在第一步丢掉。
代码入口
LiteParse 的 CLI 入口很直接:
# 基本文本解析
lit parse document.pdf
# 结构化输出,保留页面和 text items
lit parse document.pdf --format json -o output.json
# 只解析指定页
lit parse document.pdf --target-pages "1-5,10,15-20"
# 生成页面截图,给视觉模型或引用高亮使用
lit screenshot document.pdf -o ./screenshots在 TypeScript 里,核心用法也很薄:
import { LiteParse } from "@llamaindex/liteparse";
const parser = new LiteParse({ outputFormat: "json", ocrEnabled: true });
const result = await parser.parse("document.pdf");
for (const page of result.pages) {
for (const item of page.textItems) {
console.log(`[${item.x}, ${item.y}] ${item.width}×${item.height} ${item.text}`);
}
}这段代码的价值集中在 textItems。每个文本项带坐标,后面可以做三件事:
• chunk 时保留页码、区域、标题邻近关系;
• 检索命中后,用坐标回到原文区域;
• 对高风险答案做 visual citation,把引用框画到截图上。
RAG 系统里很多“引用不准”的问题,根源在解析时没有保留可回溯信息。只存一段 Markdown,答案生成以后很难再证明它来自页面的哪个区域。
四条路线
现在文档解析工具很多,容易被写成工具列表。更有用的比较方式,是看它们解决的是哪一层问题。
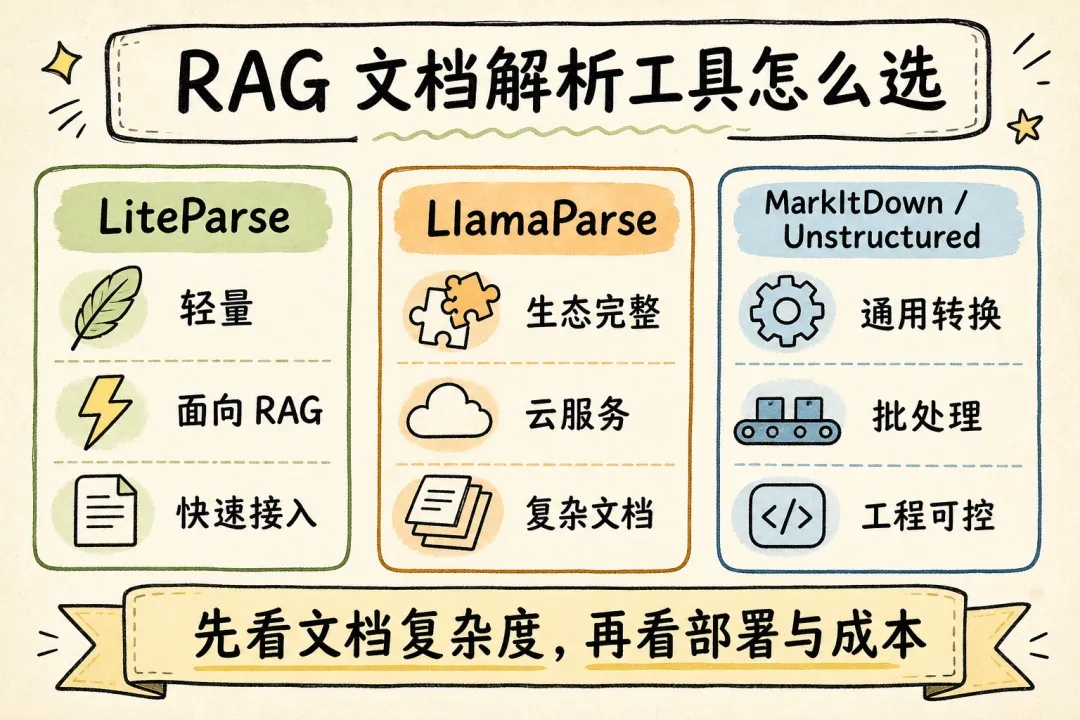
图 3:文档解析路线对比
| 工具 | 更适合 | 工程取舍 |
|---|---|---|
| LiteParse | 本地快速解析 PDF / Office 转 PDF 后的文档,保留 bbox 和截图 | 复杂扫描件、复杂表格、多栏版面可能需要更强解析器 |
| MarkItDown | 多格式文件快速转 Markdown,喂给 LLM 或轻量脚本 | 更关注 Markdown 文本,不强调空间坐标和可视化引用 |
| LlamaParse | 复杂文档、云端生产管线、高质量结构化输出 | 有云服务成本、隐私合规和网络依赖 |
| Unstructured | 文档 ETL、partition、connectors、批处理 ingest | 依赖更重,部署和文档类型适配成本更高 |
MarkItDown 的优势是“把各种文件转成模型爱读的 Markdown”。它适合快速接入 Office、网页、PDF、音频等多种输入,也适合轻量自动化脚本。问题是,Markdown 一旦成为唯一中间表示,空间关系就容易被抹平。
LlamaParse 的优势是复杂文档质量。LiteParse README 也明确提示:dense tables、多栏、图表、手写内容、扫描 PDF 这类场景,用 LlamaParse 会得到更好的结果。这个提示很重要,因为它说明 LiteParse 并不试图覆盖所有解析场景。
Unstructured 更像文档 ETL 框架。它的 partition、connectors、批处理和平台能力适合完整数据管线,但依赖也明显更重。团队要处理大量来源、复杂部署、企业级 ingest 时,它的覆盖面有价值;如果只是在本地 Agent 里解析用户上传的 PDF,可能会显得重。
LiteParse 的位置在中间偏左:本地、快速、轻量、可追溯。它不替代 LlamaParse,也不替代 Unstructured;它给 Agent 和 RAG 提供一个更低成本的解析起点。
为什么是 Rust
LiteParse 用 Rust 写,价值不在趋势标签。
文档解析在 Agent 系统里通常是热路径。用户上传文档以后,系统要尽快给出可检索文本;批量知识库构建时,解析器要跑大量文件;本地 Agent 还会受到 CPU、内存、启动时间和二进制分发的限制。
Rust 在这里的收益比较实际:
• 核心解析链路适合做成跨语言 native binding;
• Node.js、Python、Rust、WASM 可以共享同一套能力;
• 本地 CLI、服务端、浏览器侧都能复用核心逻辑;
• 对长文档和批处理任务,性能与内存更容易控制。
LiteParse 当前提供 Node.js/TypeScript、Python、Rust 和 Browser/WASM 包。这个组合对前端和客户端团队尤其有意思:文档解析不一定只发生在后端,某些隐私敏感或离线场景,可以把 WASM 解析放在浏览器侧;某些桌面端或本地 Agent,可以直接用 CLI 或 native binding。
这会把“文档上传到云端解析”从默认路径改成可选项。
上限在哪里
LiteParse 的边界同样要说清楚。
第一,Office 和图片的多格式支持,本质上依赖转 PDF。LibreOffice 和 ImageMagick 要进入部署环境,容器镜像、沙箱权限、字体、中文渲染都要测试。解析器 API 很轻,不代表部署一定零成本。
第二,Tesseract 是稳定的默认 OCR,但在复杂票据、低清扫描、混合中英文、手写、旋转文字上,不一定是最优解。LiteParse 提供外部 OCR server 接口,意味着团队要为高质量 OCR 自己选型、部署和评估。
第三,bounding boxes 不等于表格理解。坐标能帮助恢复位置和引用,但它不能自动保证表格语义、跨页表格、合并单元格、图表含义都被正确理解。对这些场景,云端复杂解析器或视觉模型仍然有价值。
第四,本地解析不等于合规完成。文件留在本地只是减少一类风险;日志、缓存、临时文件、截图、embedding 存储、权限隔离同样要设计。
这些边界不该被写成 LiteParse 的缺点。它们是文档解析层本来就有的工程现实。好的解析器应该把边界暴露出来,少用“智能解析”四个字把问题盖住。
怎么选
如果要给工程团队一个简单选择,我会这样分:
• 用户上传 PDF,希望本地快速解析、保留坐标、给 Agent 做引用:优先看 LiteParse。
• 多种文件要统一转 Markdown,重视接入速度和脚本体验:优先看 MarkItDown。
• 文档复杂度高,表格、扫描件、图表、多栏版面是主战场:优先看 LlamaParse 或同类云解析。
• 企业知识库 ingest,要接数据源、批处理、partition、平台化管理:优先看 Unstructured。
落地前要做自己的基准测试。LiteParse 仓库里也有 eval utils,可以用 QA pass rate、latency、memory usage 去比较 liteparse、pymupdf、pypdf、markitdown。这比看 README 里的形容词可靠。
测试集不要只放干净论文 PDF。至少要覆盖你业务里的几类坏文档:扫描版合同、复杂表格、PPT 导出的 PDF、中文报告、多栏论文、带图片的手册、页眉页脚很多的财报。RAG 的解析质量,应该按你的文档分布来评估。
小结
LiteParse 值得关注,是因为它代表了一类基础工具的回归:RAG / Agent 需要更好的模型,也需要更可靠的输入层。
过去很多 Demo 会把“加载 PDF”写成一行代码,然后把复杂性推给向量库和大模型。生产系统绕不过这一步。文件格式、OCR、布局、引用、权限、缓存、评估,都会在真实数据里冒出来。
文档解析正在从后台工具变成 AI 应用的基础能力。对中大型团队来说,这一层未来可能会像日志、搜索、特征抽取一样,被单独设计、监控和评估。
LiteParse 给出的答案偏工程派:本地、快、可嵌入、保留位置、支持多语言绑定。它不负责把所有文档理解问题一次性解决掉,但它把第一公里修得更清楚。
RAG 的优化不要只盯着向量库。先检查你的解析层:模型看到的文本,是否还能回到原文的位置。
迷斯特的小宇宙,客户端技术背景,大前端技术、AI前沿技术分享,偶尔写写生活日记。
如果这篇文章对你有启发,点个「在看」或转发给朋友,是对我最大的支持 🙏
