 夜雨聆风
夜雨聆风一、文档解析器工厂架构
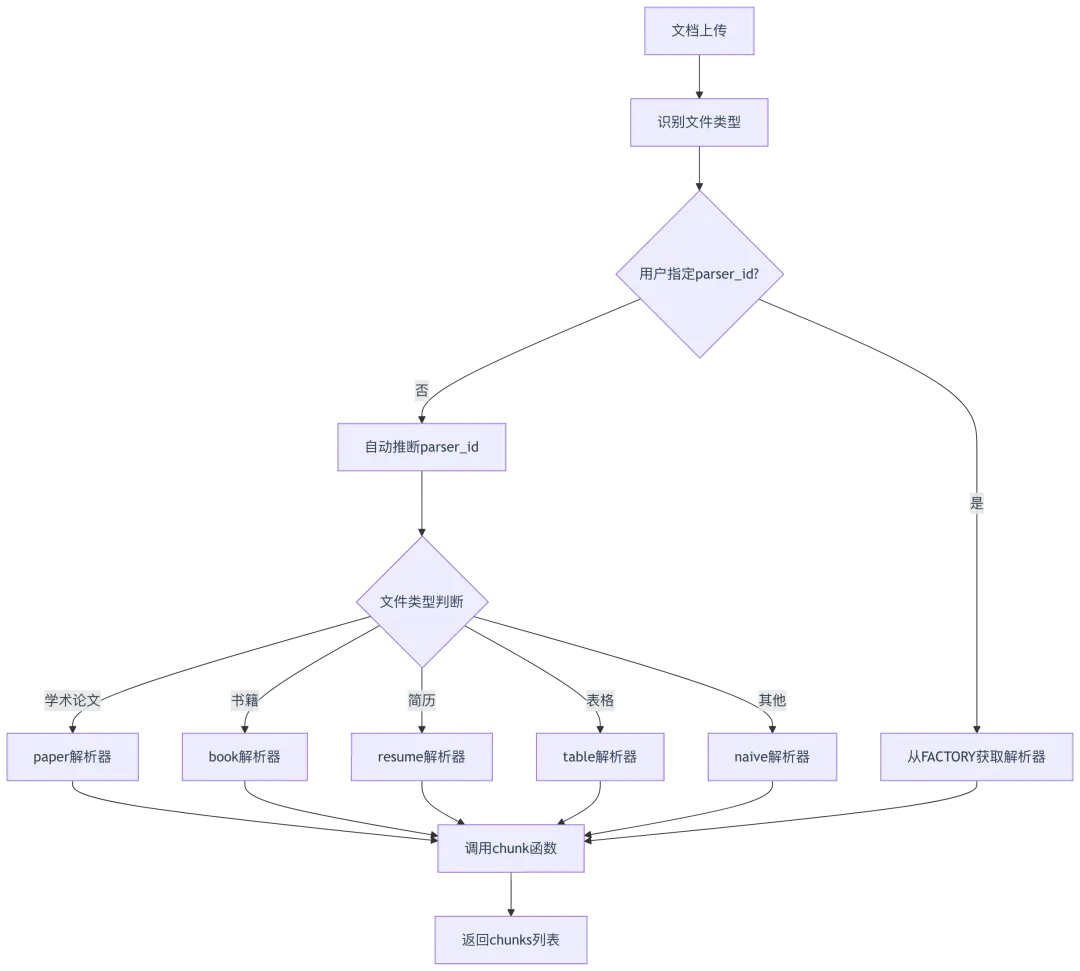
1.1 解析器工厂映射表
源码位置:rag/svr/task_executor.py:84-101
FACTORY = {"general": naive, # 通用解析器ParserType.NAIVE.value: naive, # Naive解析器(默认)ParserType.PAPER.value: paper, # 学术论文解析器ParserType.BOOK.value: book, # 书籍解析器ParserType.PRESENTATION.value: presentation, # 演示文稿解析器ParserType.MANUAL.value: manual, # 手册文档解析器ParserType.LAWS.value: laws, # 法律文档解析器ParserType.QA.value: qa, # 问答文档解析器ParserType.TABLE.value: table, # 表格文档解析器ParserType.RESUME.value: resume, # 简历解析器ParserType.PICTURE.value: picture, # 图片解析器ParserType.ONE.value: one, # 单页文档解析器ParserType.AUDIO.value: audio, # 音频解析器ParserType.EMAIL.value: email, # 邮件解析器ParserType.KG.value: naive, # 知识图谱解析器(使用naive)ParserType.TAG.value: tag # 标签解析器}
解析器分类表:
naive | |||
paper | |||
book | |||
manual | |||
laws | |||
qa | |||
table | |||
resume | |||
presentation | |||
picture | |||
audio | |||
email | |||
tag |
解析器选择流程图:
二、Paper学术论文解析器
2.1 Pdf类继承关系
源码位置:rag/app/paper.py:31-141
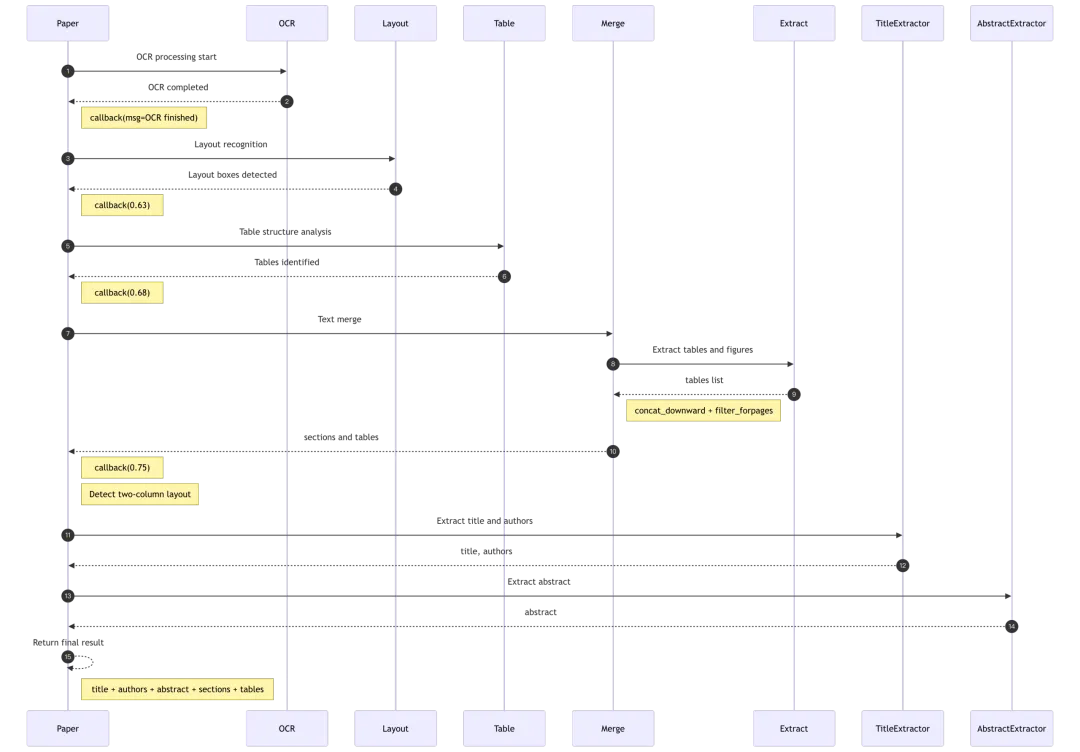
class Pdf(PdfParser): # 第31行:继承PdfParser基类def __init__(self):self.model_speciess = ParserType.PAPER.value # 第33行:指定为PAPER类型super().__init__()def __call__(self, filename, binary=None, from_page=0, to_page=100000, zoomin=3, callback=None):from timeit import default_timer as timer# 第38-48行:OCR阶段start = timer()callback(msg="OCR started")self.__images__(filename if not binary else binary, zoomin, from_page, to_page, callback)callback(msg="OCR finished ({:.2f}s)".format(timer() - start))# 第50-53行:布局识别start = timer()self._layouts_rec(zoomin)callback(0.63, "Layout analysis ({:.2f}s)".format(timer() - start))# 第55-58行:表格分析start = timer()self._table_transformer_job(zoomin)callback(0.68, "Table analysis ({:.2f}s)".format(timer() - start))# 第59-65行:文本合并start = timer()self._text_merge()tbls = self._extract_table_figure(True, zoomin, True, True)column_width = np.median([b["x1"] - b["x0"] for b in self.boxes])self._concat_downward()self._filter_forpages()callback(0.75, "Text merged ({:.2f}s)".format(timer() - start))# 第68-74行:双栏布局处理if column_width < self.page_images[0].size[0] / zoomin / 2:logging.debug("two_column...................")self.boxes = self.sort_X_by_page(self.boxes, column_width / 2)for b in self.boxes:b["text"] = re.sub(r"([\t ]|\u3000){2,}", " ", b["text"].strip())# 第75-78行:定义章节开始模式def _begin(txt):return re.match("[0-9. 一、i]*(introduction|abstract|摘要|引言|keywords|key words|关键词|background|背景|目录|前言|contents)",txt.lower().strip())# 第80-88行:跳过首页处理if from_page > 0:return {"title": "","authors": "","abstract": "","sections": [(b["text"] + self._line_tag(b, zoomin), b.get("layoutno", "")) for b in self.boxes ifre.match(r"(text|title)", b.get("layoutno", "text"))],"tables": tbls}# 第89-106行:提取标题和作者title = ""authors = []i = 0while i < min(32, len(self.boxes) - 1):b = self.boxes[i]i += 1if b.get("layoutno", "").find("title") >= 0:title = b["text"]if _begin(title):title = ""breakfor j in range(3):if _begin(self.boxes[i + j]["text"]):breakauthors.append(self.boxes[i + j]["text"])breakbreak# 第108-122行:提取摘要abstr = ""i = 0while i + 1 < min(32, len(self.boxes)):b = self.boxes[i]i += 1txt = b["text"].lower().strip()if re.match("(abstract|摘要)", txt):if len(txt.split()) > 32 or len(txt) > 64:abstr = txt + self._line_tag(b, zoomin)breaktxt = self.boxes[i]["text"].lower().strip()if len(txt.split()) > 32 or len(txt) > 64:abstr = txt + self._line_tag(self.boxes[i], zoomin)i += 1break# 第134-141行:返回解析结果return {"title": title,"authors": " ".join(authors),"abstract": abstr,"sections": [(b["text"] + self._line_tag(b, zoomin), b.get("layoutno", "")) for b in self.boxes[i:] ifre.match(r"(text|title)", b.get("layoutno", "text"))],"tables": tbls}
学术论文解析流程图:
2.2 chunk函数实现
源码位置:rag/app/paper.py:144-344
def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, **kwargs):"""Only pdf is supported.The abstract of the paper will be sliced as an entire chunk, and will not be sliced partly."""# 第150-152行:解析器配置parser_config = kwargs.get("parser_config", {"chunk_token_num": 512,"delimiter": "\n!?。;!?","layout_recognize": "DeepDOC"})if re.search(r"\.pdf", "", filename))}doc["title_sm_tks"] = rag_tokenizer.fine_grained_tokenize(doc["title_tks"])# 第225-246行:摘要处理(作为独立chunk)abstr = paper.get("abstract", "")if abstr:abstr = re.sub(r"\n", " ", abstr)d = copy.deepcopy(doc)d.update({"content_with_weight": abstr, "abstract_kwd": "abstract"})tokenize_chunks(d, abstr, doc, eng=lang.lower() == "english")res.append(d)# 第248-270行:章节分块sections = paper.get("sections", [])for txt, layout in sections:if re.match(r"(text|title)", layout):txt = re.sub(r"\n", " ", txt)sections.append((txt, layout))# 第272-290行:Token分块chunks = []for txt, layout in sections:if len(txt) < 32:continued = copy.deepcopy(doc)d.update({"content_with_weight": txt})tokenize_chunks(d, txt, doc, eng=lang.lower() == "english")chunks.append(d)# 第292-310行:表格Token化res.extend(tokenize_table(tbls, doc, lang.lower() == "english"))return res
关键技术点:
- 摘要独立分块
(第225-246行):学术论文摘要作为独立chunk,不进行切分 - 标题Token化
(第204-223行):文档名作为title_tks,用于检索权重提升 - 布局类型过滤
(第248-270行):仅处理text和title布局类型,忽略其他布局 - 图表包装
(第195-202行): vision_figure_parser_pdf_wrapper处理表格和图片
三、Book书籍解析器
3.1 Book Pdf解析实现
源码位置:rag/app/book.py:32-58
class Pdf(PdfParser):def __call__(self, filename, binary=None, from_page=0, to_page=100000, zoomin=3, callback=None):from timeit import default_timer as timer# 第36-39行:OCR阶段start = timer()callback(msg="OCR started")self.__images__(filename if not binary else binary, zoomin, from_page, to_page, callback)callback(msg="OCR finished ({:.2f}s)".format(timer() - start))# 第41-44行:布局识别start = timer()self._layouts_rec(zoomin)callback(0.67, "Layout analysis ({:.2f}s)".format(timer() - start))# 第46-49行:表格分析start = timer()self._table_transformer_job(zoomin)callback(0.68, "Table analysis ({:.2f}s)".format(timer() - start))# 第50-56行:文本合并(与paper不同)start = timer()self._text_merge()tbls = self._extract_table_figure(True, zoomin, True, True)self._naive_vertical_merge() # 第53行:简单垂直合并(不检测双栏)self._filter_forpages()self._merge_with_same_bullet() # 第55行:相同项目符号合并callback(0.8, "Text extraction ({:.2f}s)".format(timer() - start))return [(b["text"] + self._line_tag(b, zoomin), b.get("layoutno", "")) for b in self.boxes], tbls
Book与Paper解析对比表:
__images__ | __images__ | ||
_layouts_rec | _layouts_rec | ||
_table_transformer_job | _table_transformer_job | ||
_concat_downward | _naive_vertical_merge | ||
_filter_forpages | _filter_forpages_merge_with_same_bullet | ||
3.2 chunk函数层次化合并
源码位置:rag/app/book.py:61-177
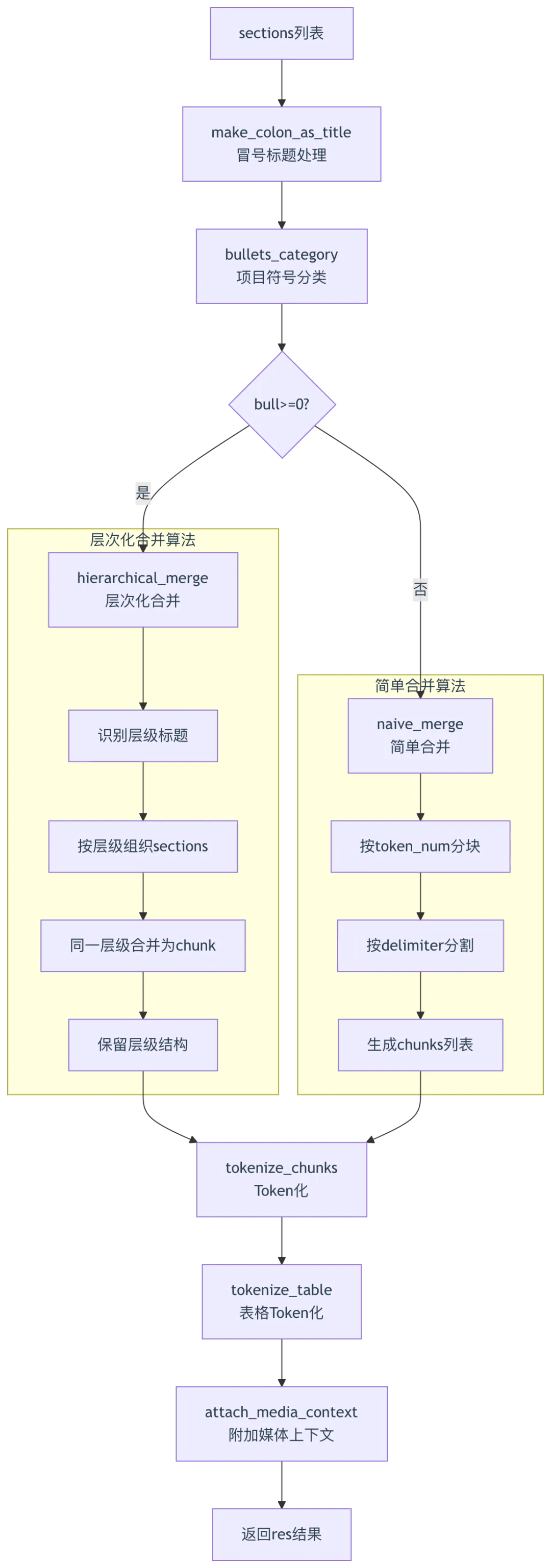
def chunk(filename, binary=None, from_page=0, to_page=100000, lang="Chinese", callback=None, **kwargs):"""Supported file formats are docx, pdf, txt.Since a book is long and not all the parts are useful, if it's a PDF,please set up the page ranges for every book in order eliminate negative effects and save elapsed computing time."""parser_config = kwargs.get("parser_config", {"chunk_token_num": 512, "delimiter": "\n!?。;!?", "layout_recognize": "DeepDOC"})doc = {"docnm_kwd": filename, "title_tks": rag_tokenizer.tokenize(re.sub(r"\.[a-zA-Z]+", filename, re.IGNORECASE):callback(0.1, "Start to parse.")doc_parser = naive.Docx()main_sections = doc_parser(filename, binary=binary, from_page=from_page, to_page=to_page)sections = []tbls = []for text, image, html in main_sections:sections.append((text, image))tbls.append(((None, html), ""))remove_contents_table(sections, eng=is_english(random_choices([t for t, _ in sections], k=200))) # 第84行:移除目录tbls = vision_figure_parser_docx_wrapper(sections=sections, tbls=tbls, callback=callback, **kwargs)sections = [(item[0], item[1] if item[1] is not None else "") for item in sections if not isinstance(item[1], Image.Image)]callback(0.8, "Finish parsing.")# 第91-121行:PDF解析elif re.search(r"\.pdf", filename, re.IGNORECASE):callback(0.1, "Start to parse.")txt = get_text(filename, binary)sections = txt.split("\n")sections = [(line, "") for line in sections if line]remove_contents_table(sections, eng=is_english(random_choices([t for t, _ in sections], k=200)))callback(0.8, "Finish parsing.")# 第130-135行:HTML解析elif re.search(r"\.(htm|html)", filename, re.IGNORECASE):callback(0.1, "Start to parse.")try:from tika import parser as tika_parserexcept Exception as e:callback(0.8, f"tika not available: {e}. Unsupported .doc parsing.")return []binary = BytesIO(binary)doc_parsed = tika_parser.from_buffer(binary)if doc_parsed.get("content", None) is not None:sections = doc_parsed["content"].split("\n")sections = [(line, "") for line in sections if line]remove_contents_table(sections, eng=is_english(random_choices([t for t, _ in sections], k=200)))callback(0.8, "Finish parsing.")# 第157-164行:层次化合并make_colon_as_title(sections) # 第157行:冒号标题处理bull = bullets_category([t for t in random_choices([t for t, _ in sections], k=100)]) # 第158行:项目符号分类if bull >= 0:chunks = ["\n".join(ck) for ck in hierarchical_merge(bull, sections, 5)] # 第160行:层次化合并else:sections = [s.split("@") for s, _ in sections]sections = [(pr[0], "@" + pr[1]) if len(pr) == 2 else (pr[0], "") for pr in sections]chunks = naive_merge(sections, parser_config.get("chunk_token_num", 256), parser_config.get("delimiter", "\n。;!?")) # 第164行:简单合并# 第166-176行:Token化处理eng = lang.lower() == "english"res = tokenize_table(tbls, doc, eng)res.extend(tokenize_chunks(chunks, doc, eng, pdf_parser))table_ctx = max(0, int(parser_config.get("table_context_size", 0) or 0))image_ctx = max(0, int(parser_config.get("image_context_size", 0) or 0))if table_ctx or image_ctx:attach_media_context(res, table_ctx, image_ctx)return res
层次化合并算法流程图:
四、其他解析器实现概览
4.1 Manual手册解析器
特点:识别层级标题、保留操作步骤结构
关键逻辑:
提取操作步骤(Step 1、Step 2等) 按步骤分块,保持步骤完整性 支持PDF、DOCX格式
4.2 Laws法律文档解析器
特点:识别条款编号、提取法条结构
关键逻辑:
识别条款编号(第一条、第二条等) 按条款分块,保持法条完整性 提取条款标题和内容
4.3 QA问答文档解析器
特点:提取问答配对、保持QA完整性
关键逻辑:
识别问答模式(Q:、A:) 按问答配对分块 提取问题和答案作为独立chunk
4.4 Table表格文档解析器
特点:表格优先解析、保持表格完整性
关键逻辑:
优先提取表格结构 表格HTML转换为chunk 支持Excel、PDF表格
4.5 Resume简历解析器
特点:结构化信息提取、简历字段识别
关键逻辑:
提取个人信息(姓名、联系方式) 提取教育经历、工作经历 按简历字段分块
4.6 Presentation演示文稿解析器
特点:Slide分块、保持演示结构
关键逻辑:
每个Slide作为独立chunk 提取Slide标题和内容 支持PPTX、PDF格式
4.7 Audio音频解析器
特点:语音转文本、音频转录
关键逻辑:
调用语音识别API转录音频 按时间戳分块音频内容 支持MP3、WAV格式
4.8 Email邮件解析器
特点:邮件结构解析、保持邮件完整性
关键逻辑:
提取邮件头(发件人、收件人、主题) 提取邮件正文 按邮件分块
五、Token化与分块算法
5.1 tokenize_chunks函数
源码位置:rag/nlp/__init__.py(推测)
def tokenize_chunks(chunk, doc, eng, pdf_parser=None):"""Token化chunk内容"""# 内容Token化chunk["content_ltks"] = rag_tokenizer.tokenize(chunk["content_with_weight"])chunk["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(chunk["content_ltks"])# 位置信息(如果有pdf_parser)if pdf_parser and hasattr(pdf_parser, "page_images"):chunk["page_num_int"] = pdf_parser.get_page_num(chunk)chunk["position_int"] = pdf_parser.get_position(chunk)return chunk
5.2 tokenize_table函数
def tokenize_table(tbls, doc, eng):"""Token化表格内容"""res = []for tbl in tbls:d = copy.deepcopy(doc)d["content_with_weight"] = tbl[0][1] # 表格HTMLd["content_ltks"] = rag_tokenizer.tokenize(tbl[0][1])d["table_kwd"] = "table"res.append(d)return res
六、设计模式与技术决策总结
6.1 核心设计模式
| 工厂模式 | ||
| 模板方法 | ||
| 策略模式 | ||
| 装饰器模式 |
