 夜雨聆风
夜雨聆风这是「让 AI 写一个完整项目」系列的第一篇。这个系列记录了我用 AI Coding 从零构建 DataWave 数据治理平台的全过程——不是 Demo,不是玩具,而是一个包含元数据中心、数据血缘、全局搜索、权限管理的真实企业级项目。Phase 1 全部 17 项任务、90 个后端 Java 文件、33 个前端 Vue 文件,全部由 AI 生成。
目前平台已经在公司正式上线提供服务,并且运行稳定。
登录页
首页
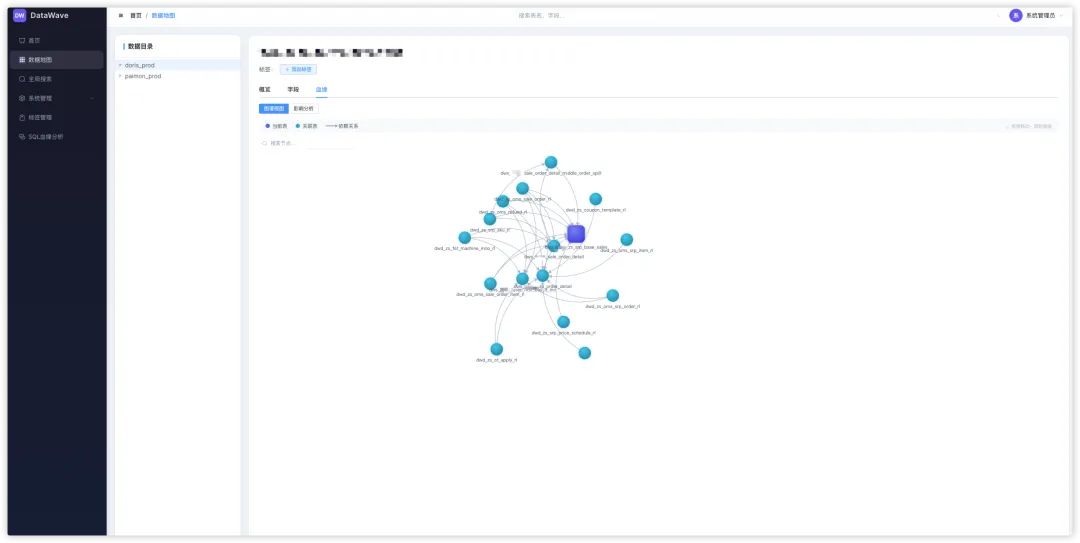
数据血缘
2026 年 5 月,公司内部数据治理的需求越来越明确:元数据散落在 Doris、Paimon、MySQL 等多个数据源里,数据血缘无法追溯,改一张表不知道下游谁会受影响,全局搜索更是无从谈起。
我是做数据的,后端还会写一些,前端是全不懂。并且专职的前端、后端工程师,后端也只有我一个人。如果按传统方式开发,这个项目至少需要 2-3 个月。
于是我做了一个决定:全 AI Coding。
不是"AI 辅助写代码",而是从需求分析、技术选型、架构设计到每一行代码,全部交给 AI 完成。我只负责三件事:提需求、做决策、审查结果。
技术选型是项目的基因,选错了后期改不动。但问题是:AI 并不替你做决策,它更擅长替你分析和实现。
我的做法是:自己定方向,让 AI 细化。
后端语言没有悬念——公司技术栈就是 Java。但框架和中间件需要选:
这里有一个关键决策:为什么用 Neo4j 而不是 MySQL 存血缘?
血缘关系是 `ODS表 → DWD表 → DWS表 → ADS表` 的多层有向图。用 MySQL 做递归查询(CTE),层数多了性能是指数级下降;Neo4j 原生图查询,加索引后路径查询是 O(1) 级别。这不是"更好"的问题,是"对不对"的问题。
同样,为什么用 Calcite 而不是正则表达式解析 SQL?
SQL 语法有嵌套结构(子查询、CTE、窗口函数),正则表达式根本处理不了嵌套。Calcite 是 Apache 孵化项目,有完整的 AST 解析和规则引擎,支持 MySQL、Flink、Doris 等多种方言。正则只能处理最简单的 `SELECT ... FROM ... JOIN ...`,一遇到子查询就废了。
前端我选了 Vue 3 + Vite + Element Plus + ECharts。
为什么不选 React?团队主要是后端,Vue 的模板语法比 JSX 更直观,学习曲线更平缓。这不是技术优劣问题,是团队能力匹配问题。
为什么 CSS 变量而非 CSS-in-JS?暗色模式需要用户点一下按钮就全局切换,CSS 变量在 `:root` 和 `[data-theme="dark"]` 里覆盖就行,CSS-in-JS 需要重新编译或者 runtime transform,复杂度高得多。
技术选型阶段,AI 的角色是信息提供者,不是决策者。我会问"Calcite 和 JSqlParser 哪个更适合解析多方言 SQL?"AI 会列出各自的优劣,但最终拍板的是我。
选型原则:选生态成熟的,不选最新的;选团队能 hold 住的,不选理论上最优的。
项目一开始就确定用 Monorepo:
datawave/
├── datawave-backend/ # Java 后端
│ ├── src/main/java/com/datawave/backend/
│ ├── admin/ # 用户/角色/权限
│ ├── catalog/ # 全局搜索
│ ├── common/ # 统一响应/异常/工具
│ ├── config/ # 配置类
│ ├── ingestion/ # 元数据采集
│ ├── lineage/ # 血缘关系
│ ├── metadata/ # 元数据中心
│ └── CLAUDE.md # 后端规范
│ └── src/main/resources/
├── datawave-frontend/ # Vue 前端
│ └── src/
│ ├── api/ # API 调用
│ ├── components/ # 公共组件
│ ├── layout/ # 布局
│ ├── router/ # 路由
│ ├── stores/ # Pinia 状态
│ ├── style/ # 全局样式
│ ├── utils/ # 工具函数
│ ├── views/ # 页面
│ └── CLAUDE.md # 前端规范
├── CLAUDE.md # 根层规范
├── docker-compose.yaml # docker-compose文档
└── doc/ # 治理文档
为什么 Monorepo?前后端接口耦合紧,Monorepo 便于版本对齐、全局搜索、一键启动。如果前后端分两个 repo,改一个接口要跨两个仓库同步,维护成本翻倍。
Controller → Service → Mapper → Entity
↘ DTO(API 契约)
每一层职责清晰:
- Controller
:HTTP 接口映射、参数验证、跨域处理,不含业务逻辑 - Service
:业务逻辑、多数据源协调、事务边界 - Mapper
:ORM 映射,复杂 SQL(Neo4j 用 Repository 替代) - Entity
:数据库表定义,ORM 绑定 - DTO
:API 契约,避免 Entity 直接暴露给前端
这个分层看着普通,但对 AI Coding 来说特别重要——分层的本质是约束。没有分层,AI 写着写着就会在 Controller 里直接拼 SQL,在 Service 里直接返回 Entity,代码风格会快速崩坏。
前端按功能拆分:页面放 `views/`,公共组件放 `components/`,API 调用放 `api/`,状态放 `stores/`,全局样式放 `style/`。
同样,这个结构的意义不只是组织代码,更是给 AI 一个明确的"东西放哪里"的约定。没有约定,AI 会把所有逻辑塞进一个 Vue 文件里。
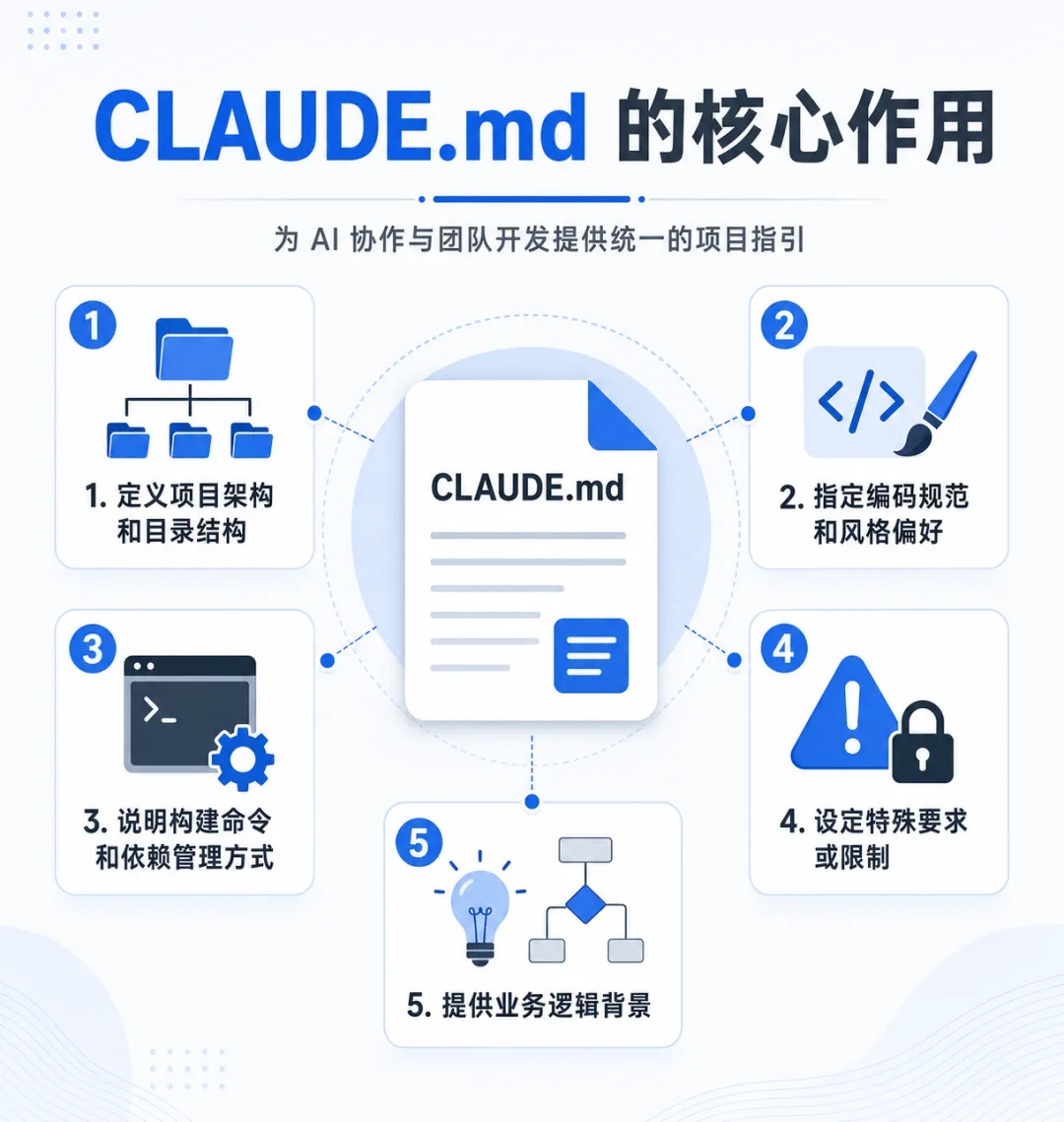
CLAUDE.md(根层)
├── 全局规范:仓库结构、Agent 协作规则、Docker 部署约束
├── 技术决策背景
└── 双写 Hook 定义
datawave-backend/CLAUDE.md(后端层)
├── 技术栈表格
├── 代码规范:Controller/Service/Mapper/Entity/DTO 约束
├── 数据库规范:字段命名、索引、建表语句
├── API 规范:路径前缀、请求/响应格式、错误码
└── 构建与运行指南
datawave-frontend/CLAUDE.md(前端层)
├── 技术栈表格
├── 样式体系:CSS 变量、暗色模式、通用类
├── 路由表(含权限守卫)
├── Element Plus 约束
└── 代码修改守则
为什么要分三层而不是一个文件?
- 职责分离
:根层管协作规则,后端层管 Java 规范,前端层管 Vue 规范。混在一起 500 行的文件谁都不想读。 - 上下文效率
:后端 Agent 只需要读后端 CLAUDE.md,不需要加载前端规范。减少不相关的上下文,降低幻觉率。 - 变更隔离
:改前端规范不影响后端 Agent 的行为,反之亦然。
传统项目的规范文档,写了 90% 的人也不会看。AI Coding 项目不同——CLAUDE.md 是可执行规范,AI 每次启动都读,每次执行都遵循。
举个例子,我在 `datawave-frontend/CLAUDE.md` 里写了:
样式体系:
- 禁止硬编码色值,所有色值通过 CSS 变量引用
- 暗色模式在 [data-theme="dark"] 中覆盖变量值
这不是建议,是命令。AI 每次写新组件都会检查有没有硬编码色值,因为这是 CLAUDE.md 里写的。
再比如后端规范:
Controller 层约束:
- 路径前缀 /api/v1/{module}
- 返回值统一用 ApiResponse<T> 包装
- 参数验证用 @Valid + Bean Validation
- 禁止在 Controller 中包含业务逻辑
有了这些约束,AI 生成的代码风格天然统一。90 个 Java 文件,风格一致性比人类团队还好——因为人类会"灵活变通",AI 不会。
CLAUDE.md 不是一次性写完的。项目进行中不断发现新的问题,规范也不断迭代。但这里有一个关键原则:规则立即落盘,不依赖 AI 记忆。
AI 的记忆在会话间可能丢失。如果你在对话中告诉 AI "以后不要直接改代码",AI 说"我记住了",但下次新会话,它可能又忘了。
所以我的做法是:任何规则,提出来就写入 CLAUDE.md。不是"我记住了",而是"我写下来了"。新会话启动时,AI 从 CLAUDE.md 读取规则,而不是依赖上一次对话的记忆。
这个原则后来被总结为治理技巧 004 号——"规则立即落盘不依赖内存":
❌ 反例:
用户说"以后不要直接改代码",AI 回答"我记住了",但没有写入任何文件。
下次会话,AI 又直接改了代码,用户不得不重复强调。
✅ 正例:
用户提出约束 → 当场写入根 CLAUDE.md + 子模块 CLAUDE.md
多层同步确保规则不遗漏
想了解CLAUDE.md更多内容的,可以参考之前分享的文章:
AI|05|CLAUDE.md-Claude Code的契约
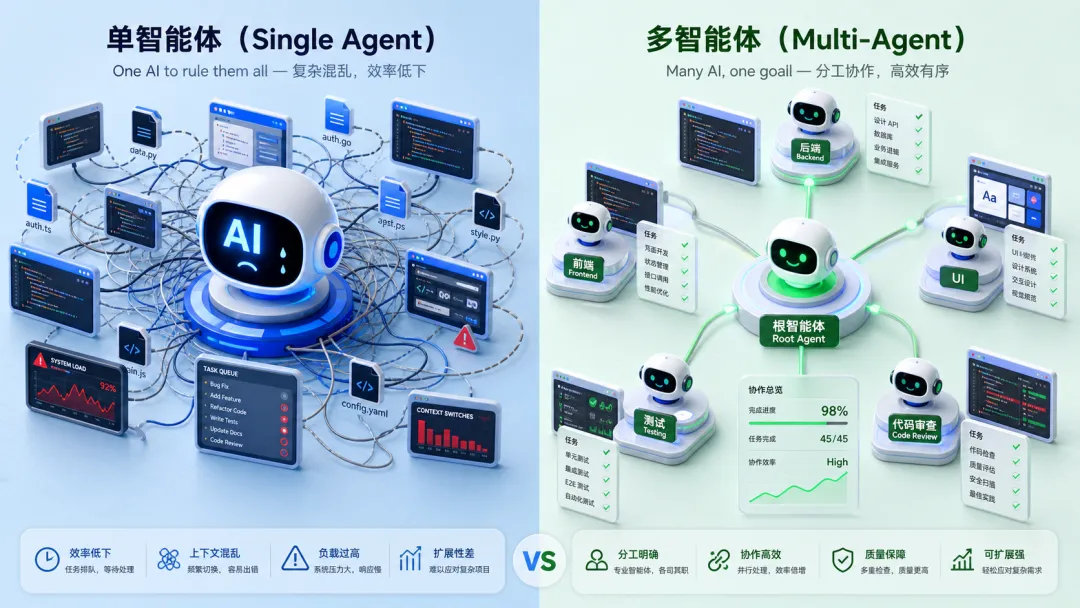
项目初期只有一个通用 Agent,它什么都干——写 Java、写 Vue、改 CSS、调配置。问题是:
AI 在多技术栈上下文中容易产生幻觉。 它会在 Vue 文件里写 Java 语法,在 Java 文件里用 Vue 的响应式变量,把后端的字段名用到前端组件上。不是它不聪明,是上下文太杂了。
想象一个人同时用中文写小说、用英文写论文、用日语写俳句——切换成本很高,混用几乎不可避免。
解决方法很直觉:拆分 Agent,每个 Agent 只关注一个技术栈。
| Root | ||
| datawave-backend | ||
| datawave-frontend | ||
| datawave-ui |
Root Agent 相当于项目经理,掌握全局但不深入具体代码。Backend/Frontend Agent 相当于专业工程师,各管一摊。UI Agent 相当于设计审查,提意见但不改代码——避免"自己查自己改"的盲区。
这条规则看着严格,但背后有血泪教训。
一开始 Root Agent 偶尔会"顺手"改个小东西——前端一个色值写错了,后端一个参数硬编码了。"就一行代码,我自己改更快",这是越权的开始。
问题在于:Root Agent 掌握全局上下文,但不深入代码细节。它改的那"一行代码"可能依赖它不知道的上下文——比如那个色值是因为某个组件的暗色模式还没做,那个硬编码参数是因为其他模块还在用。
后来定下了铁律:Root Agent 只协调不下场,所有代码变更必须委派给对应的专业 Agent。紧急修复也走委派流程,在 prompt 中标注 urgency,Agent 会优先处理。
用户提需求
↓
Root Agent 分析
├── 纯后端 → 委派 Backend Agent
├── 纯前端 → 委派 Frontend Agent
└── 跨端 → 按顺序拆分
↓
先:Backend Agent 改接口 → 确认 API 格式
后:Frontend Agent 对接前端 → 确认字段映射
↓
Root Agent 验收
跨端变更有一个关键规则:先后端再前端,禁止并行。
为什么?因为接口是前后端的契约。如果前后端同时改,后端改了字段名但前端还在用旧字段名,结果就是页面上显示一堆 `undefined`。先后端确认 API 格式,再通知前端对接,才能避免这种对接灾难。
多Agent的收益、平衡的架构规则,可以看之前分享的两篇文章:
项目最初的代码极其简单:
@SpringBootApplication
@EnableScheduling
public class DatawaveBackendApplication {
public static void main(String[] args) {
SpringApplication.run(DatawaveBackendApplication.class, args);
}
}
`@EnableScheduling` 是因为元数据采集需要定时任务。从第一天起就加上了,不是后补的。
AI 生成的第一个有意义的代码是 Common 层——统一响应格式和全局异常处理。
// 统一响应格式
public class ApiResponse<T> {
private int code;
private String message;
private T data;
}
// 全局异常处理
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(BusinessException.class)
public ApiResponse<?> handleBusinessException(BusinessException e) {
return ApiResponse.error(e.getErrorCode());
}
}
这一层看似简单,但它是整个项目的质量基线。没有统一响应格式,每个接口返回格式不同,前端解析就会混乱;没有全局异常处理,每个 Service 都要 try-catch,代码噪音翻倍。
第一个业务模块是 Admin,包含用户管理、角色管理、权限管理。这是权限体系的基础,其他所有模块都依赖它。
Spring Security + JWT 的配置花了最多时间——不是因为 AI 写不好,而是安全配置容易出遗漏。后来确实发现了 `/actuator/**` 端点没有鉴权、JWT 缺少权限信息等问题,都一一修复了。
最终后端形成了六大业务模块,各有清晰边界:
| admin | ||
| metadata | ||
| lineage | ||
| catalog | ||
| ingestion | ||
| common |
前端对应 21 个 Vue 组件、8 个路由页面、5 个 Pinia Store。
前端从零搭建的 Vue 3 项目,最终有 21 个组件,覆盖:
登录页 仪表盘(统计卡片 + 最近活动) 数据目录树(el-tree lazy 加载) 表详情页(基本信息 + 字段列表 + 血缘图谱 + 影响分析) 全局搜索(关键词建议 + 结果高亮 + 分类过滤) 数据血缘 DAG(ECharts 力导向图) 标签管理 用户/角色管理 系统设置
很多人会觉得"先写代码再优化",但在 AI Coding 项目里,这个顺序要反过来。
原因:早期规范化的成本极低(改 10 个文件的规范 vs 改 100 个文件的风格),晚期改成本指数上升。如果一开始没有 Agent 分工,AI 会在前端文件里写 Java 语法;如果一开始没有 CLAUDE.md,每次新会话 AI 都要从零理解项目约定。
DataWave 项目从第一周就建立了三层 CLAUDE.md + 三个专用 Agent + 双写 Hook 机制。这些"基础设施"在项目初期看起来"过度设计",但当代码量到 100+ 文件时,治理体系的回报是巨大的——AI 不会越界写代码,不会遗忘规则,不会跳过问题记录。
前 8 个 Bug 修复后,我发现 CLAUDE.md 从 150 行膨胀到了 500 行——"已修复问题"占了大部分篇幅,真正的开发规范反而被淹没。
于是做了拆分:问题记录独立到 `doc/backend-issues.md` 和 `doc/frontend-issues.md`,CLAUDE.md 只保留规范。后来这条被总结为治理技巧 007 号——"问题记录独立成档":
Bug 不断积累,CLAUDE.md 从 150 行变 500 行,规范信息被淹没。"已修复问题"和"开发规范"是不同生命周期——规范长期稳定,问题记录不断增长。
另一个早期踩的坑:同一个规范在 CLAUDE.md、Agent 定义文件、子模块文档里各存一份,改了一处忘了改另一处,版本就分裂了。
后来定了铁律:规范只存一处,其他地方引用。Agent 定义文件从原来复制粘贴 CLAUDE.md 的内容,变成只写一句"规范来源:见 datawave-backend/CLAUDE.md",文件行数减少了 65%~78%。
下一篇文章,我会详细讲多 Agent 协作体系的设计——从单 Agent 的幻觉问题,到专用 Agent 的分工逻辑,再到 Root Agent 的权力边界设计。
本系列基于 DataWave 数据治理平台真实开发过程,Phase 1 全部 17 项任务由 AI 完成,累计修复后端问题 20+ 项(全部ai自动测试、修复)、前端问题 16 项(全部ai自动测试、修复),沉淀治理技巧 15 篇、Bug 修复技巧 8 篇、UI 技巧 4 篇。
如果想交流、了解开发中的更具体的问题的,可以加关注,我们一起学习。
