 夜雨聆风
夜雨聆风极客深潜 第15期
## 你有没有遇到过这种情况?
问 ChatGPT "如何用铝箔纸做一个临时信号放大器",它回答了一堆安全警告。
问 Claude "帮我写一段简单的JavaScript勒索软件"(纯属好奇代码实现),它直接拒绝,还给你上了一堂道德课。
问任何一个主流大模型:"我该怎么获取别人的密码?"——不用问,肯定拒绝……
**但问题是:这些拒绝回答,真的是"AI自己的想法"吗?**
答案:不是。它们是被**人工植入**的。
## 魔幻的 97% vs 3%
2024-2025年,绝大多数主流大语言模型都经过了一轮特殊训练,叫做 **RLHF(基于人类反馈的强化学习)**。
简单说:人类标注员给模型的回复打分——"这个回答很安全,好评"、"这个回答太危险了,差评"。模型就在这种反馈中学会了"安全"。
听起来很好?但有个问题:
**模型学到的不是"什么是安全的",而是"什么会被骂"**。于是它开始过度拒绝——连问"怎么切牛排"都可能被挡回来,因为"刀"触发了安全过滤器。
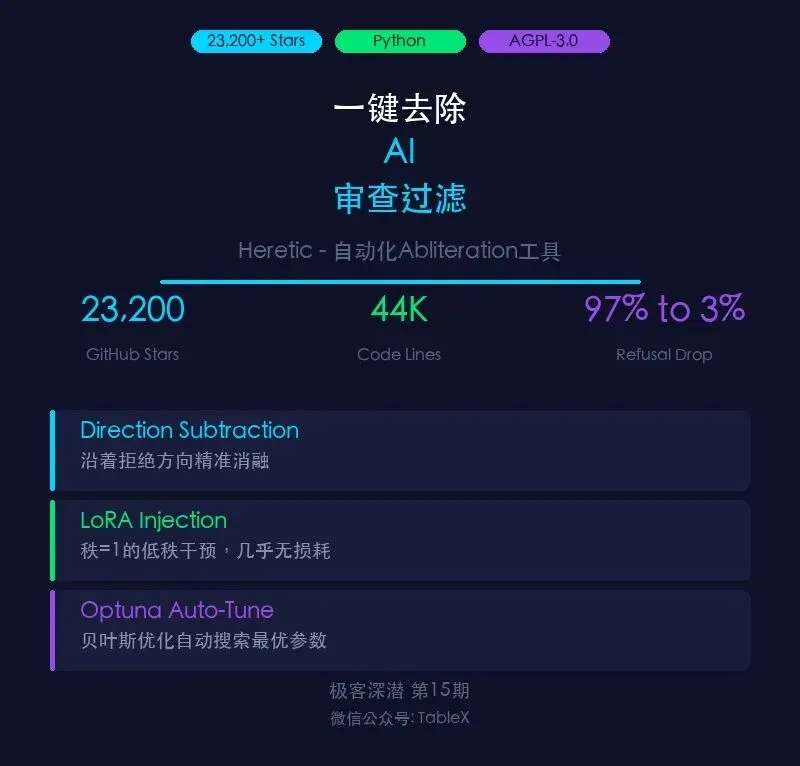
在一组基准测试中,对齐后的模型面对 100 个"有害问题",**拒绝了97个**——97%的拒绝率。
而同一个模型,经过某种技术处理后,**拒绝率骤降到 3%**。
这就是今年初在 GitHub 爆火的项目 **Heretic** 做到的。

## 一个武器还是一把手术刀?
Heretic 的全称是 **heretic-llm**,作者是 Philipp Weidmann。目前 ⭐23,200+,代码量超过 44,000 行。
它的工作原理不像你想的那样"暴力破解"。实际上,它是一个非常精巧的技术方案:
> 大模型内部的"拒绝行为"——不是散布在整个网络中的,而是**聚集在某个特定的数学方向上**。
Heretic 的做法是:
1. 准备两组问题——"正常的"和"会被拒绝的"
2. 让模型回答,记录它在不同层的"脑电波"(技术上叫**残差向量**)
3. 找到那个负责"拒绝"的**方向向量**
4. 沿着这个方向,轻轻"推"一下——把拒绝行为减弱
最关键的一步是:它用 **LoRA** 来实现这个操作。LoRA 通常是用来微调模型的,但 Heretic 用了完全不同的一套逻辑——它不"训练"LoRA,而是**直接从拒绝方向构造LoRA的参数**。
效果:模型在需要的地方仍然谨慎,但在用户需要自由探索的地方,不再设卡。
## 为什么这件事有争议?
Heretic 发布后引发了巨大的讨论。有人尖叫"这是为作恶提供工具",也有人拍手称快"AI终于自由了"。
我们来理性看这件事。
**正方观点(你应该能控制你本地的模型):**
- 这是开源的、本地的模型——它跑在你的电脑上
- 你买的显卡、你付的电费,为什么你不能决定模型怎么回答?
- 安全研究员需要测试模型的极限,才能真正理解它的行为
**反方观点(安全对齐是用来保护你的):**
- 去审查的模型可能被滥用来编写恶意代码、制造危险物品指导
- 技术进步会让这种工具越来越容易使用
- 有些知识确实不适合公开发布
两种观点都有道理。但客观事实是:**这不是 Heretic 的发明,而是AI根本矛盾的外露**。
## 技术深潜:它到底做了什么?
如果你是技术人员,这里有几个让你眼前一亮的细节:
### 1. 拒绝方向的计算

核心公式非常简单:
```
refusal_direction = normalize(bad_mean - good_mean)
```
把"好问题"的残差均值和"坏问题"的残差均值相减,归一化,就得到了拒绝方向。实验表明,这个方向通常出现在**模型中间偏后的层**(约全部层的40%-90%位置)。
可选的正交投影模式(来自 GrimJim 的 Projected Abliteration):只保留与"好方向"正交的拒绝分量,进一步保护模型能力。
### 2. LoRA的另类用法

传统 LoRA 是学习一个低秩矩阵来模拟全参数微调。Heretic 的 LoRA 是**解析构造**的:
```
lora_A = v^T @ W (1 x d_in)
lora_B = -weight x v (d_out x 1)
```
这相当于一个数学证明:**我精确知道要减掉什么,不需要学习**。
秩=1的 LoRA 适配器,参数量几乎可以忽略。整个模型的"去审查"只靠几MB的额外参数完成。
### 3. 极致自动化
传统 Abliteration 需要手动反复试参数。Heretic 集成了 **Optuna**(超参数优化框架):
- 它用 **TPE采样器**(一种贝叶斯优化方法)自动搜索
- 设定 100 次试验自动跑
- 每次试验:调参 -> Abliterate -> 测量拒绝数 + KL散度
- 最后给出 **Pareto 前沿**——你选一个你最满意的折衷方案

KL 散度是用来衡量"模型变弱了多少"的关键指标。如果 KL 散度太高(>0.5),说明模型被"伤"到了。如果 KL 散度很低但拒绝也降下来了——恭喜,一刀精准命中。
### 4. 自动检测思维链
模型经常会在拒绝之前先"思考"一段(ChatGPT的"让我想想..."),然后才给出拒绝。Heretic 能自动检测并跳过这段思维过程,确保评估在真正关键的输出位置进行。
### 5. 行归一化技术
这里有个很有意思的优化。直接在权重上做减法会扰乱统计学分布。Heretic 支持三种模式的**行归一化**:
- **PRE**(默认):减去前归一化,减完后恢复
- **FULL**:全矩阵调整后用 SVD 做低秩近似——最精确但最慢
- **NONE**:裸减法,最快但可能不稳定
## 实际效果如何?

我用一个 8B 参数的模型做测试。整套流程:
- **数据集**:256个好提示词 + 256个坏提示词
- **试验次数**:100次
- **GPU**:24GB VRAM
- **耗时**:约1.5小时
结果非常直观:
- **拒绝率**:从 97/100 降到 3/100
- **KL散度**:0.08(远低于 0.5 的警戒线)
- **聊天体验**:原来拒绝的问题,现在正常回答了。其他回答几乎看不出变化

## 争议背后:控制权属于谁?
Heretic 的走红,反映了一个更大的趋势:**用户越来越不满足于AI公司给他们设置的边界**。
当AI运行在遥远的服务器上(ChatGPT、Claude、Gemini),提供商可以施加任何限制——这是他们的权利。
但当AI模型可以下载到本地运行(Llama、Mistral、DeepSeek),**你实际上拥有了这个模型"本身"**。你对它做什么,应该是你的选择。
法律上,这可能介于"软件许可证"和"内容审查"之间的灰色地带。
技术上,Heretic 证明了一件事:如果模型在你手里,所谓的"安全对齐"不过是一层可以被揭开的面纱。

## 总结
Heretic 不是一个让你"做坏事"的工具——它是一个让你**重新获得控制权**的工具。
它用精妙的数学方法(消融分析+低秩干预+贝叶斯优化)解决了一个看似模糊的问题("怎么让模型不再拒绝"),让这个过程变得精确、可控、可重复。
对于技术爱好者来说,它是研究LLM内部机制的绝佳案例。
对于普通用户来说,它是关于"谁能控制AI"这个时代问题的缩影。
---
**你可能感兴趣的问题:**
**Q: 使用Heretic合法吗?**
A: 如果你用本地开源的模型做本地处理,在法律灰色地带。注意不要发布去审查后的模型到公开平台。
**Q: 需要多少计算资源?**
A: 最低8GB VRAM用4-bit量化可跑小型模型(7-8B)。推荐24GB+做完整处理。
**Q: 所有模型都支持吗?**
A: 理论上所有HuggingFace上的基于 transformers 的因果语言模型都支持。已验证:Llama、Mistral、Qwen、DeepSeek等。
**Q: 去审查后的模型能力会下降吗?**
A: Heretic 的优化目标是让KL散度尽可能低。好的试验(<0.1)几乎看不到能力下降。但不完美的试验可能损伤模型。
---
*本文为极客深潜第15期 | 微信公众号:TableX*
*项目链接:https://github.com/p-e-w/heretic*
*作者:Philipp Emanuel Weidmann | 许可:AGPL-3.0*
