 夜雨聆风
夜雨聆风
当下,大模型热度高涨、AI算法迭代日新月异,但行业真正的底层逻辑却鲜有人看透:算法技术可快速模仿复刻,唯有高质量数据,才是支撑AI发展、构筑核心壁垒的关键所在。
第九届数字中国建设峰会的各大论坛与产业展区中,行业共识愈发清晰:人工智能产业的竞争赛道,已从早期的算法模型比拼,全面转向高质量数据集储备与专业数据标注能力的比拼。
01
AI能力的根基:高质量数据是核心养分
多数人认为,大模型的强大源于超强算力与前沿算法,这个观点并不完全准确。
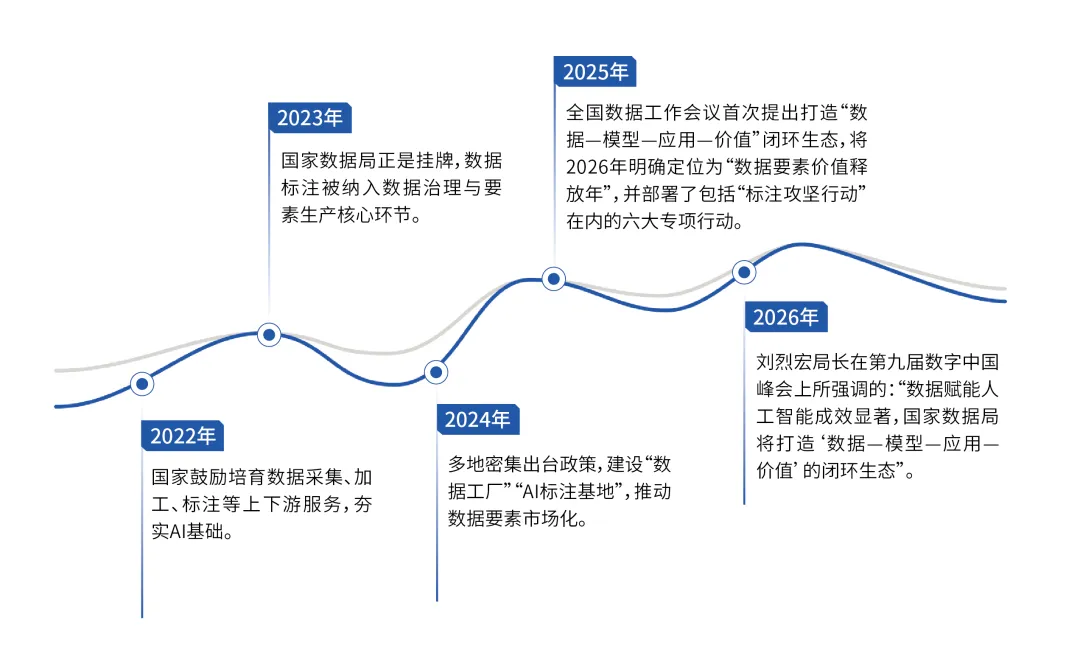
国家数据局多次明确表态:缺少高质量标注数据,算力只会空耗,算法也如同失去方向的 “盲人”。
医疗领域,精准标注病灶位置、类型的影像数据,是AI实现辅助诊断的前提;自动驾驶领域,标注清晰的路况、障碍物数据,保障车辆行驶安全。数据标注,本质是用结构化、标准化、专业化的标签,帮助AI读懂真实世界的复杂场景。
数据标注的质量直接决定模型性能:标注误差仅 1%,就可能导致模型准确率骤降 30%。AI 的能力上限,从来都由输入数据的专业度与精准度决定。
02
国家级数据粮仓:构筑产业底气
第九届数字中国建设峰会上,国家数据局局长刘烈宏公布重磅数据:截至2026年一季度,国内高质量数据集数量突11.6万个,数据总量达到960PB。
960PB的体量极具冲击力,相当于中国国家图书馆数字资源总量的336倍。这绝非简单的数据堆砌,而是一场覆盖全国、自上而下的国家级数据工业化革命,为中国AI产业筑牢了数据根基。
03
数据标注价值跃迁:升级为高端知识产业
大众对数据标注的固有印象,仍停留在简单画框、打标签的低端重复劳动,殊不知,如今的数据标注行业,早已升级为高专业门槛的知识密集型领域。
不同行业的标注工作,对从业者专业资质要求严苛:医疗影像标注需执业医师把控病灶标注精准度;法律文本标注需专业律师梳理法条逻辑、提取案情核心要素。
兼具行业业务、专业知识与行业标准认知的标注人才,已成为市场稀缺资源。一套合规、标准、高质量的标注数据集,更是直接成为可训练、可交易、可估值、可复用的核心数据资产。
算力可通过采购设备、搭建集群快速补齐,但高质量数据无法用金钱直接购买,必须依靠长期的专业积累、合规把控与严格质控逐步沉淀。在AI发展下半场,高质量数据远比算力更稀缺、更具价值、更难突破。
04
国家战略核心布局:数据标注成关键抓手
如今,数据标注早已不再是企业可自主选择的业务,而是国家数据战略的核心组成部分。
谁率先掌握高质量数据,谁就能训练出性能更优的AI模型;谁拥有顶尖模型,谁就能在全球AI竞争中抢占主动权,收获产业发展红利。
05
企业入局路径:深耕数据资产,掘金新赛道
对于想要切入数据赛道、布局 AI 领域的企业,可通过以下五步稳步落地,深耕数据资产:
01
锚定目标,明确数据需求
聚焦垂直细分领域,以模型性能指标反向推导数据规模、标签体系与质量标准,避免盲目采集数据、资源浪费。
02
合规采集,筑牢数据底座
确保原始数据来源合法、用户授权完整,做好数据分类分级与脱敏处理;重点积累行业稀缺样本,尤其是异常数据、边缘场景数据,这类数据是提升模型能力的关键。
03
搭建体系,统一标注标准
联合业务专家、算法专家、合规专家,共同制定标准化标签体系,明确标签层级、标注规范、边界定义、示例库及审核规则,保障标签一致性、复用性与可交易性。
04
人机协同,平衡效率质量
采用 “AI预标注 + 人工精准标注 + 行业专家终审” 的模式,既提升标注效率,又严控标注质量,兼顾速度与精准度。
05
治理运营,沉淀核心资产
建立完善的数据治理机制,实现数据集分级分类、版本可追溯、来源可查询;最终将数据沉淀为可复用训练集、可交易数据产品、可评估数据资产,释放长期价值。
AI 产业的护城河,从来不在于算力设备的堆砌,而在于对数据的长期深耕。11.6万个高质量数据集、960PB数据总量、十万名专业数据工匠、七大核心数据基地…… 这些看不见的 “地下粮仓”,正为中国AI筑起最坚固、最宽阔的产业壁垒。
数据标注,已完成三重蜕变:从机械重复劳动升级为高价值输入环节,从成本支出中心进化为核心资产源头,从低端外包业务跃升为国家数字经济发展底座。
中国 AI 能够快速崛起、稳步前行,靠的是一群甘于深耕、沉心钻研的 “实干者”,靠的是全球规模领先、质量过硬的 “数据粮仓”。AI 时代,唯有沉下心做好 “笨功夫”,才能构筑难以逾越的深层护城河。
往期推荐


