 夜雨聆风
夜雨聆风从坪山中学公园才回到家,QCC突然问道:“上次讲到注意力,还没讲完呢。现在能讲讲吗?”
“可以,今天我们就学术性地讲讲注意力是什么样子的,但是你不能打磕睡哦”。我打开电脑开始找曾经的学习笔记时,听到QCC说:“有哪么夸张吗?”
“你不信呀,不信就继续看吧”,我笑道。
什么叫注意力机制?
重点在于“注意力”这个词,比如在日常生活中老师上课说到“大家请注意”,那么注意力就集中在老师讲课的内容上面,这就叫注意力,即把精力主要关注到内容上。
假设上课内容有A、B、C、D等内容,老师说大家要尤其注意到A,那么人的目光会对A关注得多一些,而B、C、D会少一些,重要的内容注意力大,不重要内容的注意力小。
如果将其放在神经网络中,也就是调整参数W,对于需要聚焦的内容分配权重大一些,其它内容小一些,所以注意力其实就是关注的权重。
通过这种方式,注意力就能够引导神经网络将计算资源集中在关键的信息上,而减少对无关或次要信息的关注。

注意力机制的公式来源
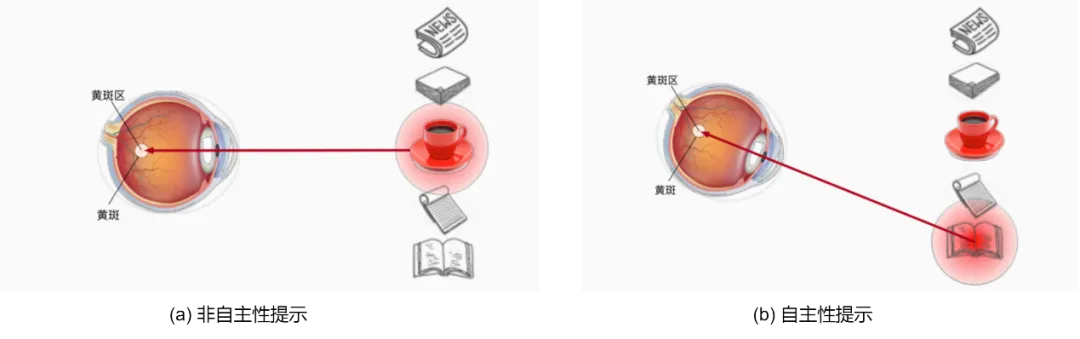
注意力从视觉感观可以分为自主性提示和非自主性提示。
假设我们面前有5个物品,一份报纸、一篇论文、一杯咖啡、一本笔记本和一本书,所有纸制品都是黑白印刷的,但咖啡是红色的,咖啡杯在感观视觉中比较突出,不由自主地会引起人们的注意,所以我们会把视力最敏锐的地方放在咖啡上,这就是非自主性提示。
喝了咖啡,我们会变得兴奋并想读书,重新聚集眼睛,然后看书。此时选择的书受到认知和意识的控制,因此注意力在基于自主性提示去辅助选择时将更为谨慎,我们受主观意愿推动,选择的力量也就更强大,因此“自主性提示+非自主性提示=注意力=权重”,如下图所示。
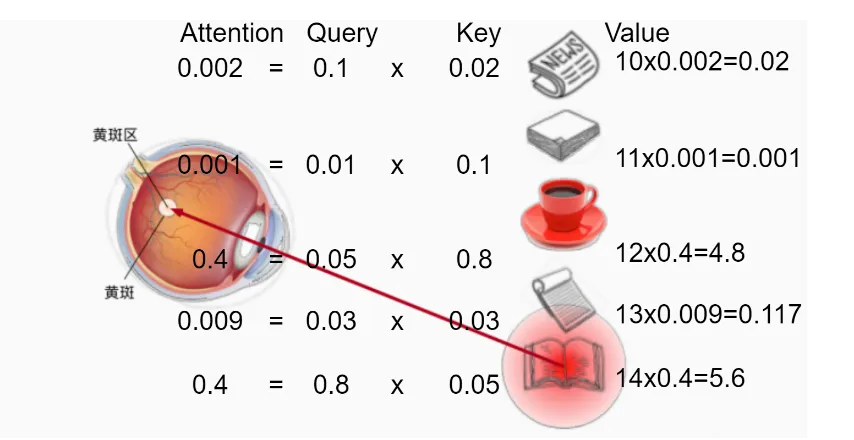
任何客观物体都可以描述为向量,设客观物体Value=[10,11,12,13,14],物体的特征值Key=[0.02,0.1,0.8,0.03,0.05],假设没有自主性提示,那么最后关注结果就是[0.02×10, 0.1×11, 0.8×12, 0.03×13, 0.05×14]。
现在需要观察到书,因此需要引入自主性提示,设Query=[0.1,0.01,0.05,0.03,0.8],那么其注意权重可以简化表述为[(0.02×0.1),( 0.1×0.01),( 0.8×0.05),( 0.03×0.03),( 0.05×0.8)],即注意权重为[0.002 , 0.001 , 0.4 , 0.009 , 0.4],那么最后关注到的事情就是[0.002×10, 0. 001×11, 0.4×12, 0. 009×13, 0.4×14]= [0.02, 0.001, 4.8, 0.117, 5.6],那么这个向量就代表,在自主性提示和非自主性提示两个因素综合作用的情况下对外界信息吸收的多少,因此可认为注意力的结果就是加权然后相乘,如下图所示。
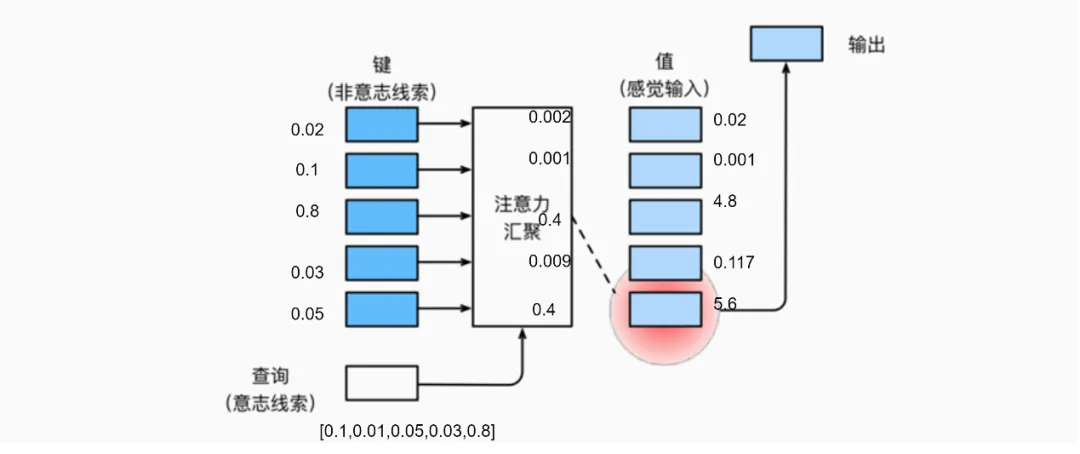
总结可知,注意力机制通过注意力汇聚将自主性提示(Query)看书,和非自主性提示(Key),结合在一起,实现对感观输入(Value)面向的物体进行倾向性不同权重的选择,如下图所示。
然后将上图转换为注意力机制的表达,可如下:
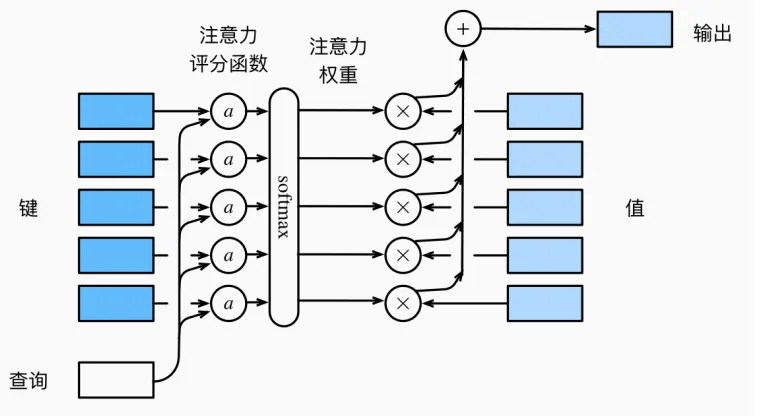
在图中的注意力机制中,采用softmax函数的主要原因是确保输出的注意力分数在多维情况下具有互斥性和归一化特性。
softmax函数会将所有的注意力分数转换到0和1之间,并且所有维度的分数之和等于1。这样有利于计算和比较不同维度的注意力分数,使得模型能够更聚焦地分配注意力资源,同时保持计算的稳定性和可解释性。



根据反向传播算法的原理,在训练神经网络时会根据损失函数的梯度更新参数W。
因此,注意力权重的结果会受到参数W的影响。通过训练网络模块能够学习到如何最佳地调整Query和Key,从而更准确地聚焦于输入数据中的重要部分,同时减少对不重要部分的关注。
在面对全局信息时,注意力机制的作用尤为重要。
因此,所有姓Q的人的年龄加权平均值为19岁。通过这种方式,注意力机制帮助我们在处理全局信息时聚焦于最相关的特征(即姓Q的人的年龄),并有效地计算出他们的年龄平均值。
在这个例子中,我们通过注意力机制成功地从全局信息中提取出了与查询“所有姓Q的人的年龄平均值”最相关的特征,并据此计算出了准确的结果。这不仅提高了模型的性能,还增加了其解释性和透明度。
在面对复杂的全局信息时,注意力机制能够帮助模型聚焦于最相关的特征,优化信息处理和决策过程,从而提升模型的整体表现。通过这种方式,注意力机制在处理复杂数据和任务中展现出强大的能力和价值。
“所以你讲了这么多,注意力到底是个啥子嘛?”QCC揉了揉眼睛,打了个哈欠。
“注意力,就是让模型自动决定。对于当前任务,输入里的哪些部分更重要,哪些部分不那么重要。重要的多看几眼,不重要的扫一眼。计算方式就是Q和K相乘得到权重,再对V加权求和。”
“那Q、K、V这些向量是从哪里来的?”
“不是人工指定的,是模型自己学出来的。通过可学习的参数矩阵W,把输入的词嵌入变换成Q、K、V。训练的时候,模型不断调整W,让注意力权重越来越准——该聚焦的聚焦,该忽略的忽略。”
QCC点点头:“所以我总结一下。注意力就是一套打分系统。每个词都有自己最原始的特征Key,代表它本身是什么。Value代表它包含什么信息。你想查什么,就生成一个Query。Query和Key一对比,就知道该给每个词分配多少注意力权重,最后用这个权重去加权Value,得到最终的结果。”
“完全正确。你get了。”
“那当然,”QCC合上笔记本,站起身,“不过下次别讲这么学术了,我真的打瞌睡了”
“OK,OK,下次整通俗点”,我笑道。
