 夜雨聆风
夜雨聆风模型已经在自己跑实验了
Expanse 联合创始人兼 CEO Ismaeel Bashir 近日在 X 上发了一条引发广泛关注的帖子,开头就写道:
"Auto-research is taking off. Inside xAI, Anthropic, OpenAI, DeepMind, Meta SI: frontier models are running their own training experiments."
「自动研究正在起飞。在 xAI、Anthropic、OpenAI、DeepMind、Meta SI 内部,前沿模型正在自己跑训练实验。」

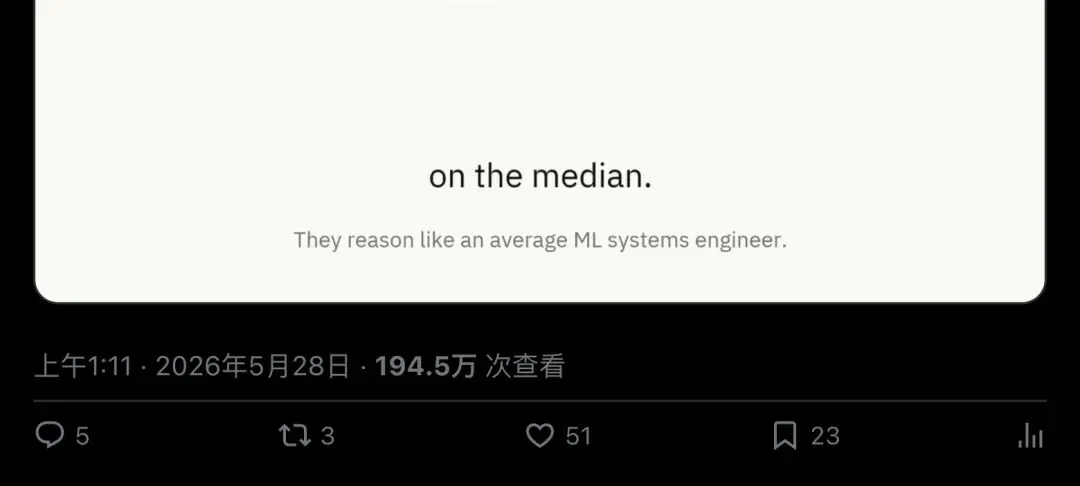
▲ Expanse CEO Ismaeel Bashir 的推文,194.5 万次查看
这条帖子把两件事拼到了一起:前沿实验室正在让模型参与研发流程,而 Expanse 做了一个针对性测试,看这些模型在真正面对 GPU 集群时,能不能合理地申请资源。
结果呢?
"They all ended up over-provisioning compute by 2x, even for coding specific models."
「它们全部多申请了约 2 倍算力,就连专门写代码的模型也没能幸免。」
多申请 2 倍,到底意味着什么?
配图里的结论被压缩成一句极其直白的判断:
"Frontier LLMs over-provision compute by 2x on the median. They reason like an average ML systems engineer."
「前沿大模型在资源配置上中位数多申请 2 倍。它们的推理水平相当于一个普通的 ML 系统工程师。」
这句话的杀伤力在于后半句。今天的大模型在写代码、做 agent、调用工具方面已经很强了。但一旦需要判断"这个训练任务该要多少 GPU、多少显存、多长 walltime",它们的表现就跟人类工程师习惯性多要资源没什么区别。
这里有一个容易被忽略的背景:在 HPC 和 GPU 集群环境里,资源申请天然存在不对称风险。少申请了,job 可能中途崩掉,几天的训练时间直接报废;多申请了,虽然浪费钱和容量,但至少任务能跑完。
所以无论是人类研究员还是大模型,都倾向于保守策略——宁可多要,也别不够用。
但问题在于,如果 auto-research 的目标是让模型接管越来越多的研发环节,资源申请这一步就绕不过去。模型会写训练脚本、会扫超参数、会做故障分析,唯独在"这个 job 实际需要多少算力"上依然靠猜——而且猜得很保守。
Expanse 到底是谁?
如果只看 X 上的帖子,很容易把这当成一个泛泛的 AI 评论。但 Expanse 有相当具体的产业背景。
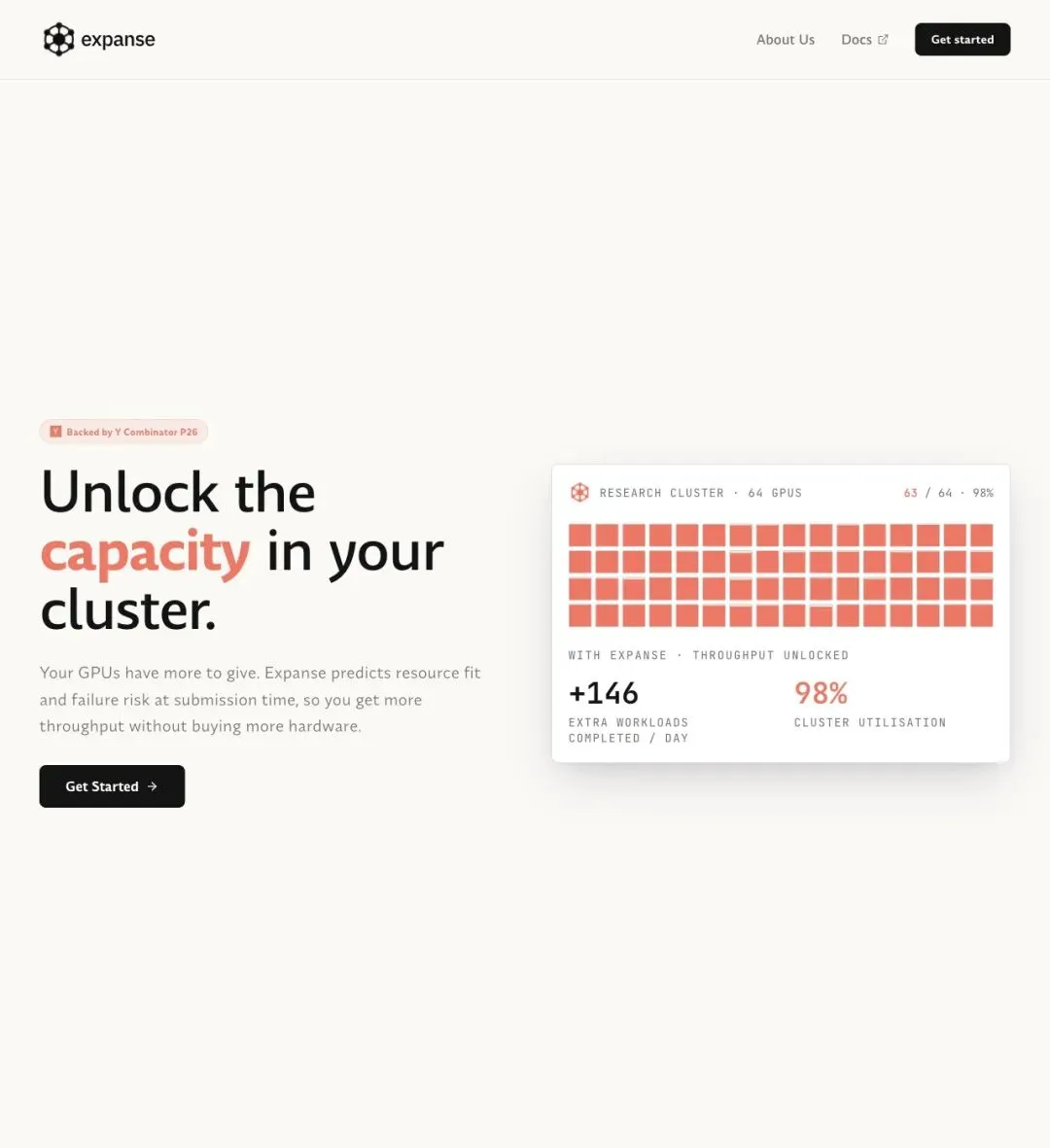
▲ Expanse 官网:Unlock the capacity in your cluster
官网首页写得很明确:
"Your GPUs have more to give. Expanse predicts resource fit and failure risk at submission time, so you get more throughput without buying more hardware."
「你的 GPU 还有余量可以释放。Expanse 在任务提交时预测资源匹配度和失败风险,让你在不买更多硬件的情况下提高吞吐量。」
这家公司做的事情可以拆成三块:
- 资源预测(Resource Prediction)
:在 job 到达调度器之前做 right-sizing,告诉你该要多少 - 优化建议(Optimisation Suggestions)
:让研究员自己改代码和配置 - 故障预测(Failure Prediction)
:在 job 白白烧掉数小时 GPU 时间之前,提前抓出要挂掉的任务
它关注的时间点很关键——任务提交那一刻,在训练开始之前就给出判断。
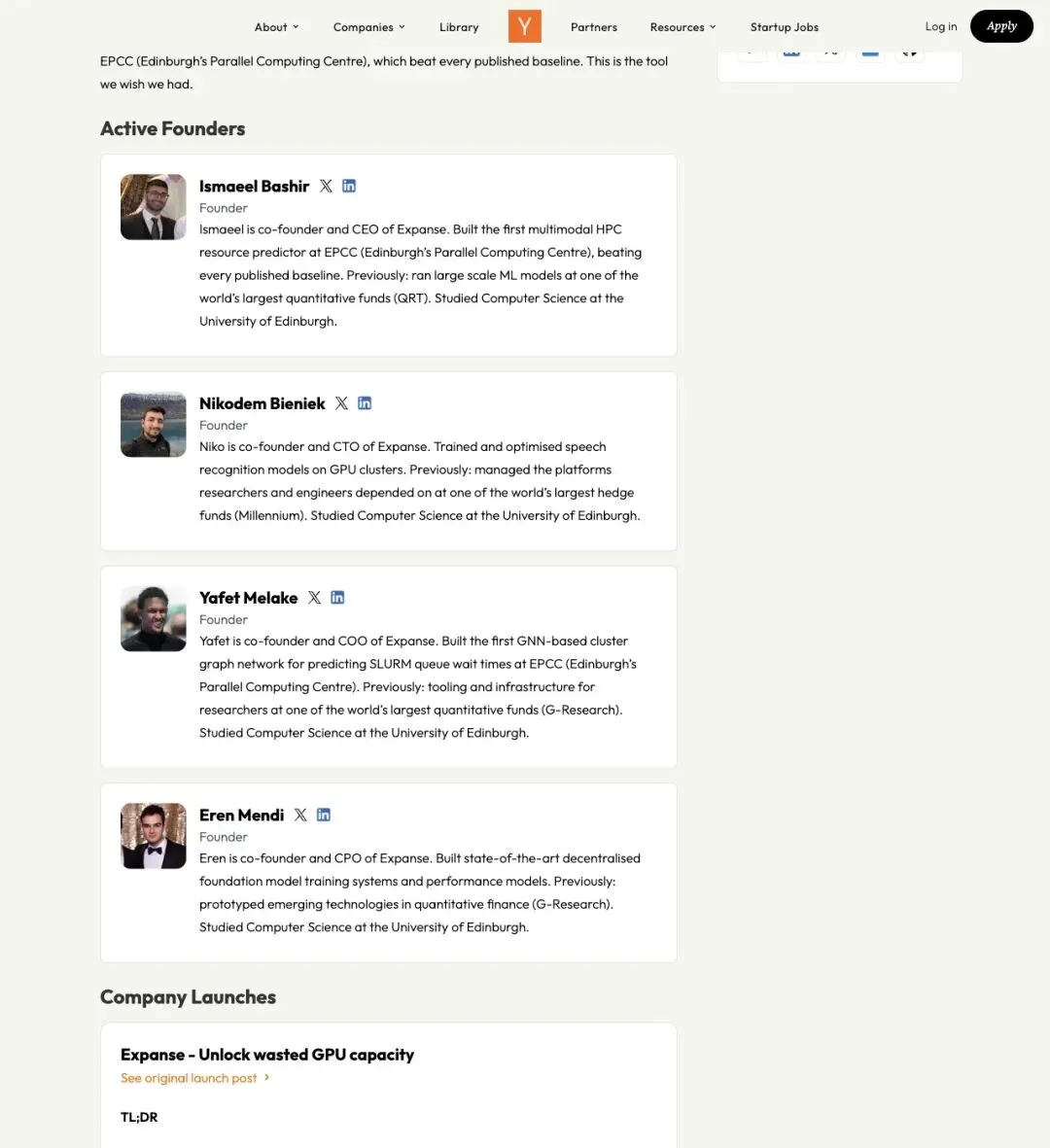
▲ YC P26 公司页,展示 Expanse 创始团队背景
创始团队的履历也能说明问题:CEO Ismaeel Bashir 之前在 EPCC(爱丁堡并行计算中心)做出了第一个多模态 HPC 资源预测器;其他几位联合创始人分别来自量化基金、GPU 分布式训练和高性能计算研究方向。这个团队对"训练任务怎么浪费 GPU"有第一手经验。
数据中心的真实利用率,可能比你想的低得多
Expanse 在 Hacker News 的 Launch HN 长文里,给出了更完整的背景数据。

▲ Hacker News Launch HN 帖子,补充了方法细节和集群级数据
几个关键数字值得单独拉出来看:
数据中心的有效利用率通常只有 30%–40%。
"Datacenters run at roughly 30% to 40% effective utilisation... So everyone over-requests by two to three times."
「数据中心的有效利用率大约在 30% 到 40%……所以每个人都会多申请两到三倍资源。」
他们在一家国家级 HPC 集群上测了一个月,12.2 万个 job 中有 59% 的算力被浪费。
"We measured one national-scale HPC cluster for a month and from 122k jobs, 59% of the compute was wasted."
按同等硬件的按需云价格换算,单月浪费约 850 万美元。
这组数字把"2x over-provisioning"放回了产业语境:不光是模型保守,整个生态里从研究员到工程师,都在习惯性地多要资源。差别在于,人类这么做是因为经验不足或怕任务挂掉,而模型这么做则说明——它同样缺乏对具体集群硬件的感知能力。
通用大模型为什么搞不定资源配置?
Hacker News 评论区有人直接追问:Expanse 的核心系统底层也是大模型吗?
Ismaeel 的回答很关键:
"The core model isn't an LLM. It's a custom architecture built from the ground up. We natively accept multimodal inputs such as source code, submission scripts and hardware topologies. The LLMs in the post are the baselines we beat."
「核心模型不是 LLM。它是一个从零构建的定制架构,原生接受多模态输入,包括源代码、提交脚本和硬件拓扑。帖子里的那些 LLM 是我们打败的 baseline。」
这段话划清了一条重要边界:Expanse 把通用大模型当作比较对象,而自己做的是一个集群原生的、多模态的资源预测系统。
为什么通用大模型在这件事上不够用?从 Expanse 的解释来看,原因有三层。
第一,输入模态不够。资源预测需要同时看源代码、提交脚本、集群拓扑、硬件遥测数据和历史性能模式。通用 LLM 能读代码,但对具体节点的表现、不同拓扑下同一代码为什么显存消耗差几倍,没有原生感知。用 Ismaeel 的话说,通用 LLM 在这里是"在真空中推理"(reason in a vacuum)。
第二,风险函数不对称。这个任务的惩罚结构天然导向保守:少申请了任务直接崩溃,多申请了至少能跑完。所以无论人还是模型,都倾向于往多了要。Expanse 自己也承认,他们的系统同样被训练成"宁可多给也别少给",但会提供不确定性估计和 p90 数值,让用户按自己的风险偏好选择。
第三,集群差异性。同一份代码在不同集群拓扑上的表现可能完全不同。Expanse 因此需要做 cluster-specific 的微调,随着更多 workload 的运行逐渐变准。这意味着,哪怕下一代通用大模型更强,如果缺少本地遥测数据和拓扑信息,在这个任务上依然可能不稳。
需要留意的几个边界
这条选题有几个容易被写过头的地方,值得提前说清。
第一,这不是一篇完整公开的 benchmark 论文。X 帖说测了 8 个前沿模型,Launch HN 文本里明确提到的 baseline 包括 Gemini 3.5 Pro、Claude Opus 4.8、GPT 5.5、Codex 5.3 等,但完整的 8 模型名单、逐项分数、误差分布、任务定义、prompt 设定和评估框架,目前并未完全公开。
第二,2x over-provisioning 并不等于模型"很蠢"。在高惩罚场景下,保守策略本身有其合理性。关键要看在固定崩溃风险下,多申请到什么程度才算无效浪费——而这个 tradeoff curve 当前并未展开。
第三,X 帖提到的 xAI、Anthropic、OpenAI、DeepMind、Meta SI 这几家实验室,当前公开材料不足以把它们与具体的被测模型一一对应。Ismaeel 的原文表达更接近于一个产业观察:"这些实验室内部,前沿模型正在参与训练实验",而 Expanse 的 benchmark 则是针对公开可用的前沿模型做的测试。
AI 会写代码之后,下一关是什么?
从更大的视角看,Expanse 踩中了两条正在交汇的趋势线。
一条是AI coding / agent 工具不断向"实验自动化"延伸。模型已经会写训练脚本、调参数、做故障分析,下一步自然是自己提交作业、自己看 profiler、自己改资源配置。
另一条是算力经济学越来越敏感。无论是超大训练集群还是传统 HPC,调度前的资源估计、队列等待、显存溢出、长时间低利用率,都是直接的现金流问题。只要 GPU 仍然稀缺且昂贵,right-sizing 就是基础设施层的利润杠杆。
这两条线交汇的地方,就是 Expanse 试图回答的问题:当 AI 从写代码走向真正执行实验,谁来提供对硬件现实的感知?
Expanse 给出的方案是一层集群原生的智能层。而他们的 benchmark 则指向了一个尖锐的现实——今天最先进的大模型,在面对真实的 GPU 集群时,对硬件资源的判断力还远远不够。
— END —
