 夜雨聆风
夜雨聆风11小时独立造App!Qwen3.7-Plus屏幕理解碾压GPT-5.4,多模态智能体新基座
阿里通义千问发布Qwen3.7-Plus,将视觉与语言统一为一体化智能体基座——看、想、写、做、验五步闭环,ScreenSpot Pro 79.0碾压GPT-5.4的67.4,Hybrid-Agent系统11小时独立完成英语学习App全流程开发
一、从"看图说话"到"动手干活"
2026年6月2日,阿里通义千问团队正式发布Qwen3.7-Plus。这不是一个简单的多模态升级——它把AI从"读懂世界"推向"动手完成任务"的新纪元。
传统多模态模型的核心能力是"看图说话",识别图片、描述内容、回答问题。Qwen3.7-Plus在此基础上打通了界面感知→工具调用→代码生成→任务交付全链路,用一个模型实现了五步闭环:
最关键的是"混合"二字——同一个模型同时处理GUI环境(浏览器、桌面应用)和CLI环境(终端、代码执行),打破了以往模型要么专精GUI要么专精CLI的局限。
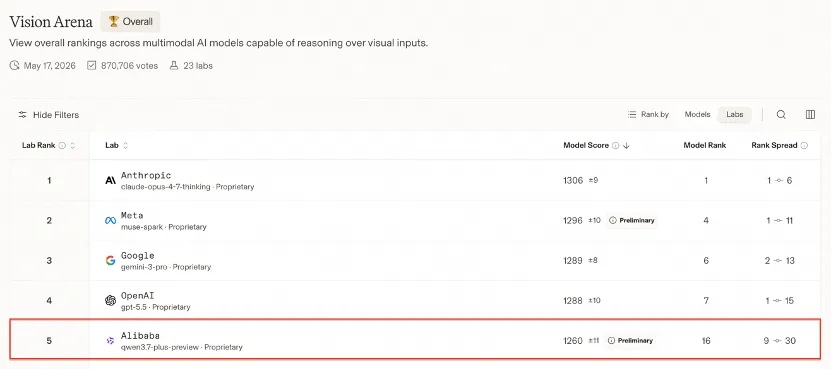
二、基准测试:屏幕理解全球第一梯队
Qwen3.7-Plus在Vision Arena全球视觉大模型榜单中跻身全球前五、中国第一。具体基准数据如下:
关键解读:ScreenSpot Pro 79.0意味着在标准应用UI中,约5次点击有4次能首次精确定位目标像素——这是GUI Agent能否真正商用的关键门槛指标。Qwen3.7-Plus比GPT-5.4高出11.6分,领先幅度惊人。
三、实战验证:11小时造App × 复刻macOS Stocks
📱 案例1:11小时独立开发英语学习App
基于Qwen3.7-Plus构建的Hybrid-Agent系统,连续稳定运行超11小时,累计生成代码超10,000行,触发工具调用超1,000次。
覆盖全流程:需求文档→代码编写→自动部署→测试用例→GUI自动化测试→多场景并行测试→产品说明更新→版本迭代。App包含单词本、消消乐、每日背诵、限时挑战等功能。
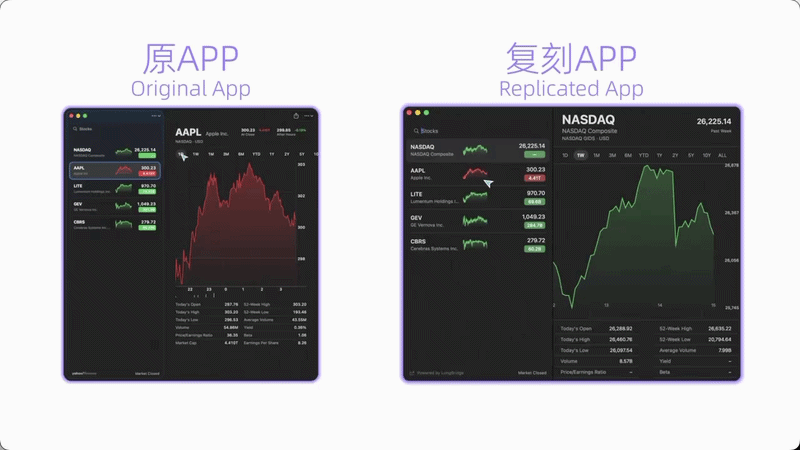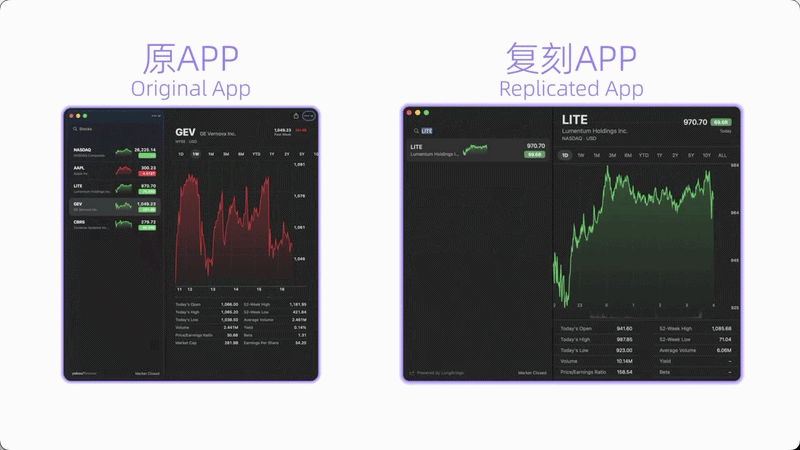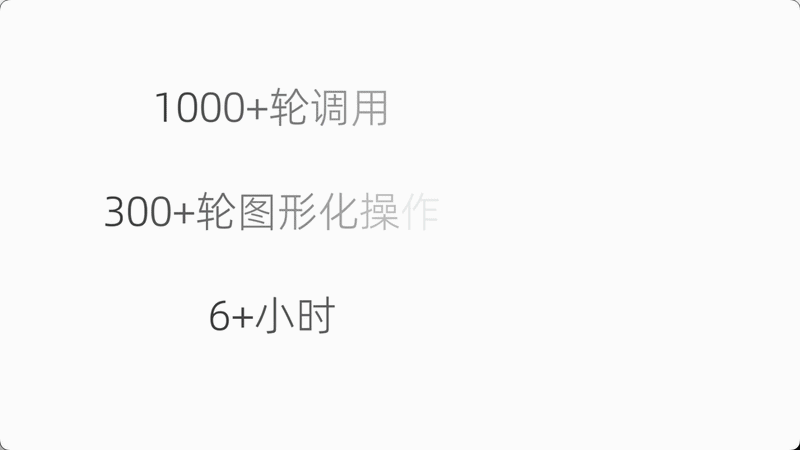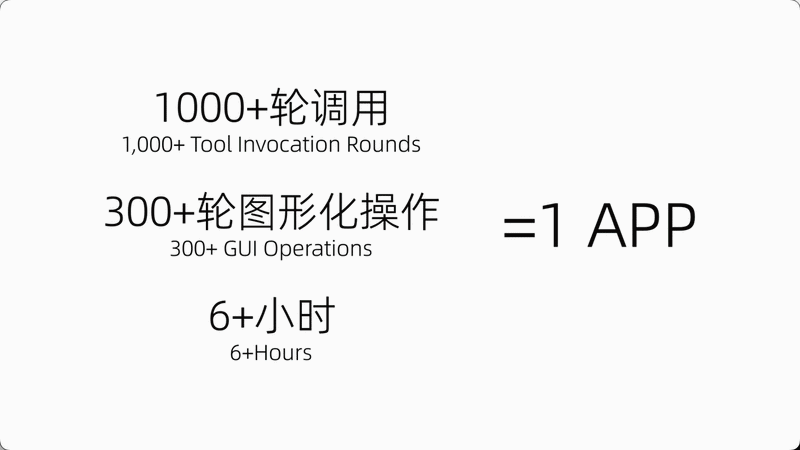
💻 案例2:复刻macOS原生Stocks应用
流程:①自主交互原生应用理解UI布局 → ②基于交互记录生成SwiftUI源码 → ③接入LongBridge真实行情API → ④自动编译构建 → ⑤10项功能验证测试全部通过
成功复现原生Stocks的暗色主题、分栏布局、实时行情数据和完整交互体验。关键不在于"写了多少代码",而在于链路够长——安装、运行、测试、改Bug、再验证的长程闭环。
🔍 案例3:视觉Agent——找不同×植物病害诊断
找不同:提取几何结构→将视觉问题转可计算逻辑→调用代码解释器求解→5处差异全部定位
植物病害:观察叶片斑块→初步分析→调用搜索7次检索→对照验证→综合判断给出诊断报告
四、五大能力模块深度拆解
Hybrid-Agent的真正含义:不是5个独立模块简单堆叠,而是同一个模型在同一轮循环中无缝切换GUI和CLI——一边看屏幕截图决定点什么,一边在终端写代码、执行命令,形成真正的"观察-行动-观察"闭环。
五、强项与短板:客观审视
实测局限:复杂前端和3D场景存在不稳定性——快速模式下3D主体黑屏,需切换思考模式。图片文字渲染偶现乱码,前端交互细节仍需人工调试。高分辨率截图消耗大量Token,长循环需任务分块管理。
六、与Qwen3.7-Max互补 vs 竞品路线
竞品格局:Gemini 3.1 Pro的托管Computer Use工具链最成熟;OpenAI Operator在ScreenSpot Pro 75-82区间与Plus同属第一梯队;Claude Opus 4.8在Terminal-Bench 2.1以74.6领先。Plus在纯GUI定位能力上是"非西方实验室最强",但生态成熟度仍需追赶。
七、行业信号与未来展望
多模态模型的竞争重点正从"看得准"转向"做得成":
1. GUI+CLI混合成为新范式。单一模型同时操控界面和命令行,不再需要多个专用Agent拼接。
2. 编程范式从"写代码"升级为"造软件"。11小时独立完成App全流程,意味着AI已从代码助手进化为软件工程师。
3. 生态成熟度决定落地速度。Plus的执行器生态不如Claude/Gemini完善,需自建更多"胶水代码"——但$0.40/$1.60的价格优势可能弥补这一差距。
4. 开源时间表尚未确定。目前仅API调用,Q3 2026可能推出开源版本。
接入方式:
• 阿里云百炼平台(API服务,兼容OpenAI/Anthropic协议)
• Qwen Studio在线体验:chat.qwen.ai
• 可直接通过Claude Code、OpenClaw、Qwen Code调用
• Together AI / OpenRouter(海外区域)
关注「阿泽AI应用」· 第一时间获取AI前沿深度解读
