 夜雨聆风
夜雨聆风近日,Soul App AI 团队(Soul AI Lab)联合西北工业大学音频语音与语言处理研究组 ASLP@NPU 团队及Moonstep AI,正式开源端到端多人对话转录模型SoulX-Transcriber。
作为一款面向长音频、多说话人场景设计的语音理解模型,SoulX-Transcriber 能够直接从多人对话音频中生成包含时间戳、说话人身份和转录文本的结构化结果,实现对“谁在什么时候说了什么”的统一理解与建模。
针对当前端到端语音大模型在多人多轮对话场景中普遍存在的说话人区分能力不足、快速轮次切换下身份追踪不稳定,以及多人语音重叠场景性能下降等问题,SoulX-Transcriber设计了涵盖说话人轮次切换预测、目标说话人提取、说话人验证、说话人日志等在内的多个与说话人属性相关的多任务预训练框架,显著提升了模型对说话人特征的建模能力和复杂对话场景下的转录准确性。
多人对话识别转录是语音领域的重要能力要求之一。在拥有强“语音”标签的Soul,语音生成、语音对话等语音能力是团队推进AI社交技术基建的核心布局,也拥有了一定的能力积累。
此次开源SoulX-Transcriber,是团队面向行业输出的全新解决方案。在公开基准测试中,SoulX-Transcriber在AISHELL-4、AliMeeting等多人会议数据集上,取得了领先Gemini-3.1-Pro等模型对应功能的表现(具体测试结果可见下文),欢迎点击下方链接体验。
Demo Page:
https://soul-ailab.github.io/soulx-transcriber/
Technical Report:
http://arxiv.org/abs/2606.02400
Source Code:
https://github.com/Soul-AILab/SoulX-Transcriber
HuggingFace:
https://huggingface.co/Soul-AILab/SoulX-Transcriber

效果展示
SoulX-Transcriber效果,音频内容源自开源数据测试集
行业痛点:
为什么多人对话转录如此困难?
近年来,语音识别技术已经取得显著进步,但真实世界中的多人对话理解仍然面临巨大挑战。
与传统单人语音识别不同,真实长对话往往同时包含:多人交替说话、重叠语音(Overlap Speech)、长时间上下文依赖 、噪声与混响 、情绪变化 、非标准口语表达、音色相似等主要问题,并且还具有:打断、停顿、插话、远场语音、多说话人快速切换等复杂交互行为。传统多说话人ASR系统通常仅关注依赖VAD切分结果的“逐句转写”,缺乏:
长上下文建模能力
多说话人一致性建模
结构化音频理解能力
因此在真实会议、播客、访谈、直播等场景中,往往会出现说话人混乱、时间轴错位、文本断裂、长程语义丢等问题。而一个合格的识别系统,不仅需要识别“说了什么”,还需要准确判断“是谁说的”和“什么时候说的”。
SoulX-Transcriber:
统一建模“谁、何时、说了什么”
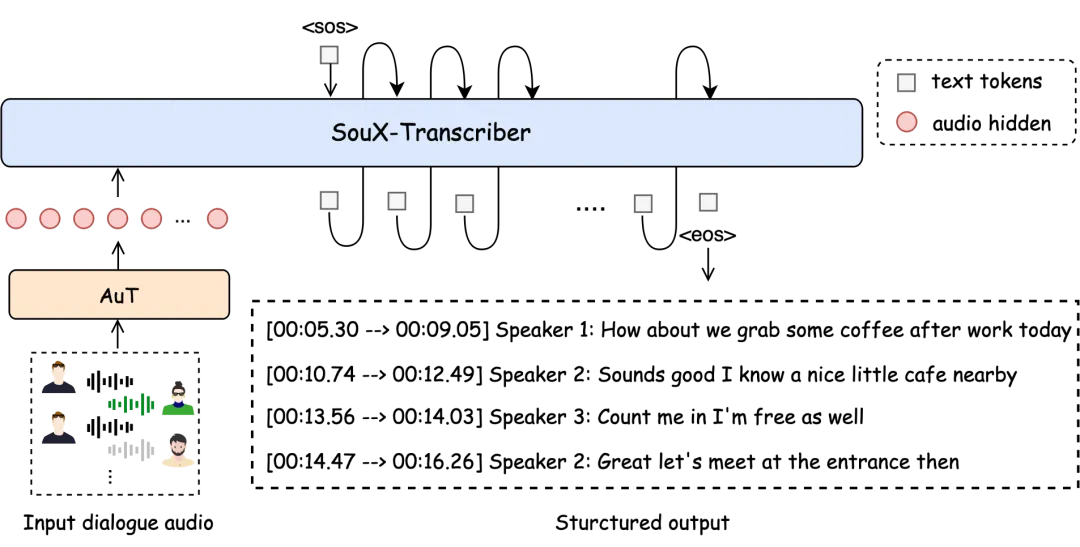
传统多人语音识别系统通常采用多阶段级联方案,需要依次完成语音检测、说话人分离、说话人聚类和语音识别等多个步骤。这种方式虽然易于实现,但容易产生误差累积,一旦前面环节出现错误,后续结果也会受到影响。
SoulX-Transcriber采用统一的端到端框架,将说话人身份、时间边界和转录文本纳入同一模型进行联合建模,实现从原始音频到结构化结果的直接生成。
面对复杂多人对话,系统能够同时完成:
谁在说(Who)
什么时候说(When)
说了什么(What)
从而获得更加稳定和一致的转录结果。
让模型真正学会区分不同说话人
多人对话识别的核心难点之一,在于模型是否具备足够强的说话人辨别能力。为此,SoulX-Transcriber 设计了专门面向说话人建模的两阶段训练方案。
第一阶段通过多任务联合训练,让模型同时学习说话人切换预测、目标说话人提取、说话人验证、多说话人转录以及通用语音识别等任务,从多个角度强化对说话人特征的理解能力。相关任务的具体定义如下:
Speaker Turn prediction:说话人轮次切换预测,该任务在多人对话数据中预测说话人语音对应的文本边界,在训练数据中,以符号"<turn>"作为边界预测的目标。
Target Speaker Extraction and Recognition:目标说话人提取与识别,该任务旨在已知目标说话人的参考语音后,到目标多说话人数据中提取所有属于该目标说话人的语音并进行语音识别,在训练的时候也将目标说话人的时间戳边界作为训练的目标。
Speaker Verification:说话人验证,该任务旨在给定了,两个说话人的语音片段,让模型判断是否属于同一个说话人,强化模型对说话人音色的辨别能力;
Speaker Diarization and Automatic Speech Recognition:说话人分割与识别,该任务旨在给定多说话人对话音频片段,直接生成时间戳边界、说话人标签以及转录文本的结构化输出;
Automatic Speech Recognition:自动语音识别,通过引入多领域数据维持识别能力并提升泛化性,为第二阶段的训练打下基础;
第二阶段则利用高质量标注数据进行监督微调,进一步提升模型在真实多人对话场景中的稳定性和泛化能力。这种训练方式无需修改底层模型架构,即可显著增强模型对相似音色说话人、快速轮次切换以及复杂多人交互场景的处理能力。
构建更真实的多人对话训练数据
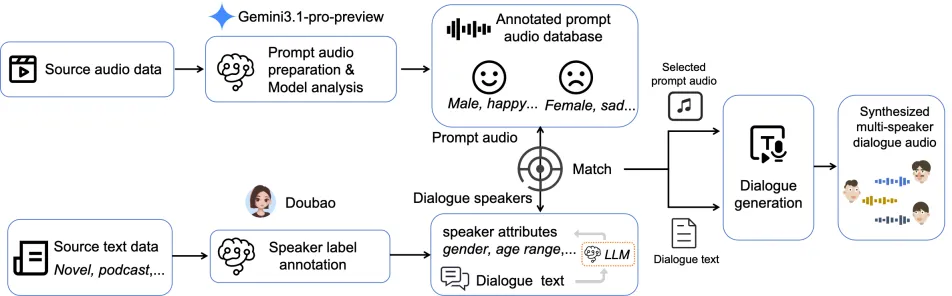
除了模型训练策略之外,SoulX-Transcriber还构建了一个基于多人多轮语音合成的多说话人对话语音数据生成体系。与伪标签对话数据相比,基于生成的对话语音数据在说话人身份、对话结构和对话组成方面具有更好的可控性。
它还能够可扩展地构建涉及声学相似说话人和复杂多说话人交互的困难训练样本,而仅通过自动标注系统很难获得这些样本。整个构建系统包括四个阶段:对话文本构建、参考音频构建、说话人参考匹配和对话音频生成。具体见下图所示:
多项公开基准测试达到领先水平
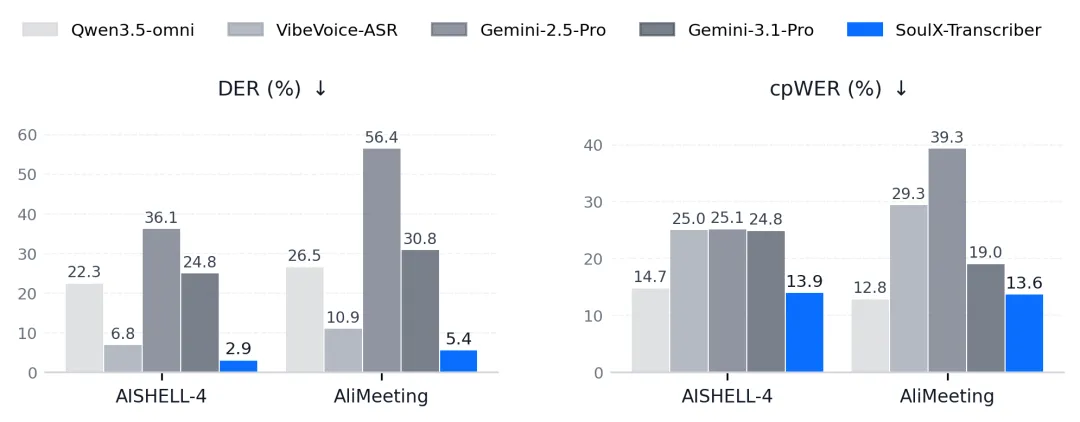
在公开基准测试中,SoulX-Transcriber在 AISHELL-4、AliMeeting 等多人会议数据集上取得了领先表现。除了常规测试集外,团队还进一步构建了5分钟长音频测试集,以验证模型在长时间上下文中的稳定性。
结果表明,SoulX-Transcriber在长音频场景下依然能够保持准确的说话人追踪能力和转录质量,有效降低长对话中常见的身份漂移和归属错误问题。与此同时,在覆盖日常对话、影视内容和播客等不同领域的内部测试集中,SoulX-Transcriber同样展现出良好的泛化能力。值得注意的是,虽然模型训练数据以中文为主,但在英文多人对话场景中依然保持了较强的识别和说话人归属能力。
依托模型表现,未来,SoulX-Transcriber将能够在多人会议、在线教育等领域应用落地。
SoulX-Transcriber之外,此前,Soul AI团队在语音领域还开源了播客语音合成模型SoulX-Podcast、歌声合成模型 SoulX-Singer、全双工语音对话控制模块SoulX-Duplug,团队持续围绕语音方向夯实技术基建,面向核心垂类方向,为行业提供更专精的具体解决方案。
同时,在实时数字人生成方向,团队还陆续开源了SoulX-LiveAct、SoulX-FlashTalk、SoulX-FlashHead等模型,受到了AI开发者的广泛关注。
在思考AI社交核心能力的过程中,聚焦实时AI交互的多模态方案,Soul以清晰的技术路线探索和应用落地,推进自身基础设施升级,也携手开发者社区,共同推动智能交互时代的发展和技术产业化落地新阶段的到来。
