 夜雨聆风
夜雨聆风
AI Agent · 2026.06 · 工程实践
最近在 GitHub 上冲浪时,挖到一个很有意思的项目——harness-engineer,来自我本人(Twsa)。stars 还是 0,但背景很有来头:这个项目从 OpenAI、Anthropic、Microsoft、Meta、Google 这些头部公司的 100+ 项目里蒸馏经验,打磨出一个 6 维度框架加 10 条启发式原则的技能框架。
说实话,现在市面上讲 AI Agent 的文章要么在吹 GPT-5 有多强,要么在教你怎么写 prompt。但真正做过的都知道,光有模型不够,你得解决:Agent 怎么循环执行、上下文怎么管理、工具怎么设计、多 Agent 怎么协作、生产环境怎么部署……这些工程问题才是真正的深水区。harness-engineer 瞄准的正是这个痛点。
核心维度:6 个方向,覆盖 Agent 开发全链路
Agent Loop——计划 → 行动 → 观察 → 调整 → 循环。这套闭环做过 RPA 或者游戏 AI 开发的朋友应该很熟悉,但把它显式地引入到 LLM Agent 架构里,其实是对传统"调 API 等结果"模式的根本性升级。Agent 不再是"一问一答",而是持续感知环境、做出决策、影响环境、再感知的循环体。 Context Engineering——把上下文视为有限资源,注意边际收益递减。这点太重要了。我见过太多人恨不得把整个知识库都塞进 prompt 里,觉得"给越多信息 Agent 越聪明"。但现实是,上下文窗口越满,注意力越稀释,模型反而容易迷失重点。这个框架给出的解法是:静态内容放前面,可变内容放后面,用结构化方式管理上下文生命周期。 Verification——生成器和评价器必须分离。类比 GAN(生成对抗网络)的思路,用独立的验证模块来判断输出质量,而不是让 Agent 自我评估。这直接解决了一个老大难问题:Agent 说自己干完了,怎么知道真的干完了? Memory——用结构化持久化替代人工记忆。Session 切换时,上下文怎么恢复?长期积累的经验怎么积累?这块很多项目都选择"往向量数据库一存了事",但框架更强调结构化——你的记忆得有 schema,不是随便塞进去的黑箱。 Multi-Agent——编排拓扑比模型选择更重要。用哪个模型不重要,Agent 之间怎么分工、怎么通信、怎么协作才重要。这对国内很多团队来说是实际痛点:大家都盯着"该用 GPT-4 还是 Claude",却忽略了架构设计的价值。 Production Patterns——Harness 是模型与现实之间的"操作系统"。这是整个框架最核心的心智模型:Harness 负责 prompt 构建、工具调度、上下文管理、终止判断,说白了就是给 LLM 模型套上一层工程化的"运行环境",让它不只能"想",还能"做"。
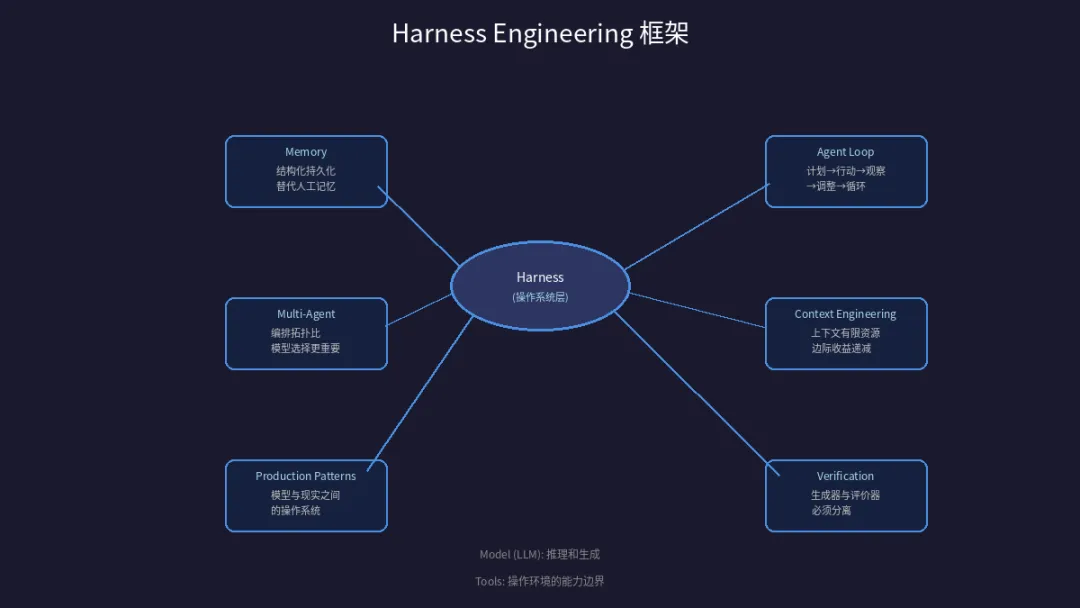
10 条启发式原则:工程师视角的实战经验
HE1:从简单模式开始,逐步增加复杂度——别一开始就搞多 Agent 协作,先跑通单 Agent 闭环再说 HE2:给 Agent 地图,不给手册——告诉它目标在哪,而不是 step-by-step 步骤 HE3:每个 Milestone 有明确的 Done When——验收标准要清晰,不能"感觉差不多了" HE4:工具设计原则:Scope 清晰 + 自包含 + 可组合——每个工具只做一件事,但可以拼起来用 HE5:Session 间交接产物必须可恢复——中断后能接着干,不是从头再来 HE6:压缩不是银弹,设计好过压缩——别一味想着压缩 prompt,好的设计比压缩技巧更重要 HE7:Schema 即契约,Action 需枚举——接口要严谨,枚举所有可能的动作 HE8:Sandbox 是训练问题,不只是配置问题——沙箱环境要能真训练 Agent 的决策能力 HE9:评测 = 单元测试思维,不是基准跑分——要能复现、要能自动化、要有覆盖率 HE10:生产部署 = 渐进 + 可观测 + 可中断——不能一键全量,要灰度、要监控、要随时能停
为什么值得推荐
第三,落地性强。不是那种"给你一堆论文链接"的理论派,而是给出了可直接参考的框架和原则。6 个维度、10 条原则,结构清晰,照着做至少不会跑偏太多。
有什么局限?
还有一个潜在的点:国内大模型适配。框架主要基于 OpenAI、Anthropic 这类海外模型的经验,国内百度、阿里、智谱的 API 在工具调用、上下文窗口等方面有差异,直接照搬可能会遇到一些水土不服。

写在最后
如果你正在做 AI Agent 相关的项目,或者在思考怎么把"调 API"升级成"做产品",这个框架值得花半小时过一遍。工程化这条路没有捷径,但至少可以少走一些前辈已经踩过的坑。

欢迎点在看、转发给做 AI 开发的朋友
