 夜雨聆风
夜雨聆风深耕法律 AI 多年,我们在服务众多企业法务团队的过程中,高频收到两类“灵魂提问”:
SaaS 产品能不能随着使用,持续贴合我们企业的个性化业务?
如果私有化部署的核心优势是依托自有数据持续优化,那实施费用,对应的实际价值到底是什么?
这两个疑问,归根结底指向同一个行业本质命题:SaaS产品存在哪些天然技术上限?私有化部署高昂造价,又匹配了哪些独有的商业与技术价值?
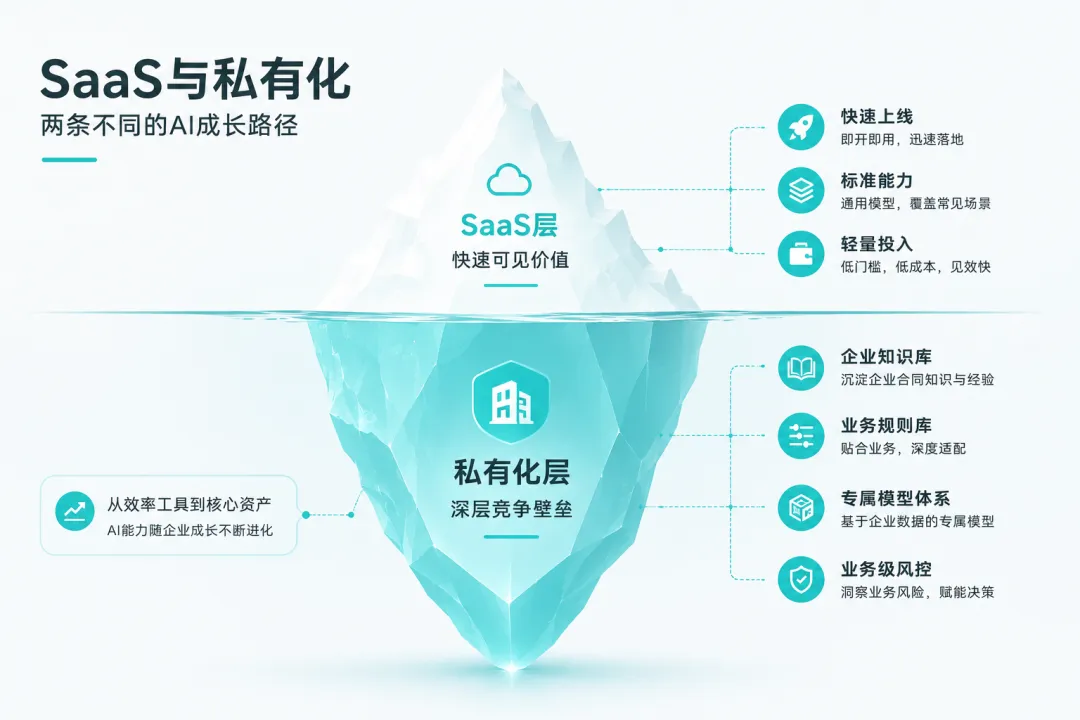
本文尝试从技术底层 + 商业成本双维度,把底层逻辑摊开来讲,帮正在选型的企业建立科学判断。
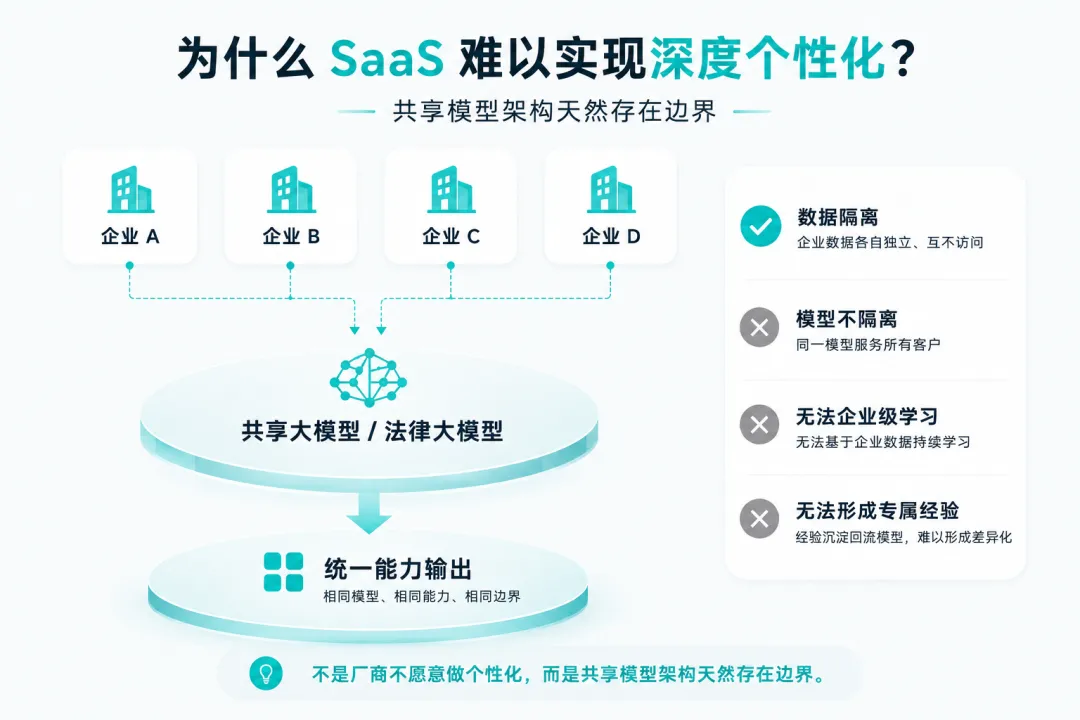
很多企业误以为 SaaS 无法适配专属业务,是厂商出于成本不愿定制。事实恰恰相反——厂商同样希望产品持续贴合客户,但多租户共享架构从底层锁死了深度个性化的技术空间。
1. 多租户共享模型:所有人的“老师”是同一个
当前主流的 SaaS 合同 AI,底层是一个共享的大模型(或经过法律领域预训练的垂直模型),部署在云端,所有租户调用同一套模型参数。
这意味着什么?
若放开权限、允许单家企业数据微调共享模型,会直接改动全局参数,导致其余所有租户审查逻辑、风控结论异常。这在技术管控与商业合规上完全行不通。
2. 数据隔离 ≠ 知识隔离,RAG也难根治适配短板
SaaS 标配的数据加密、分库存储,仅实现存储层级的数据隔离,做不到推理环节的私有知识定制化调用:
RAG检索增强方案局限:依靠上传企业文档构建知识库、审查时调取片段补充答案,一方面涉密央企、金融机构受 “数据不出域” 管控,无法把内部制度、涉密合同上传厂商云端;另一方面 RAG 仅能实现 “查资料式补全内容”,没办法让模型深度理解企业独有交易模式、非标用语习惯。 独立向量数据库治标不治本:即便单独搭建租户向量库,检索后的内容仍要送入共享大模型解析生成结论,公有模型本身不具备企业业务理解力,检索无法从根源提升个性化审查精度——它只是在“翻书”,并没有真正“学会”。
3. 联邦学习,在法律风控场景有壁垒
从理论上看,联邦学习可以本地训练、仅回传参数,兼顾隐私与迭代。但落地法律风控场景,存在无法规避的现实短板:
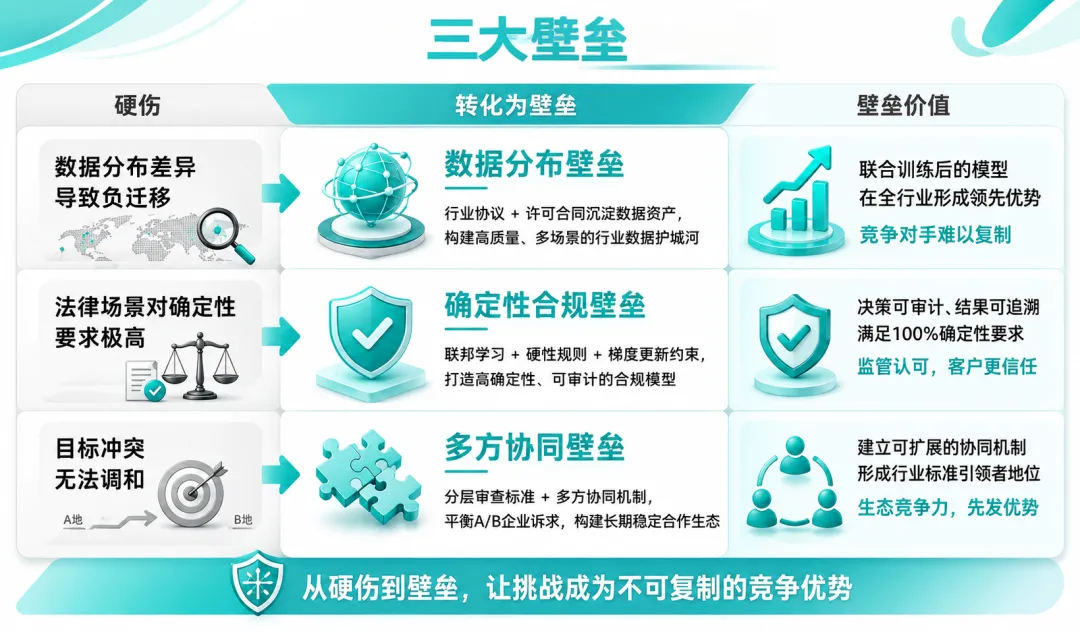
看懂SaaS天然短板,便能厘清私有化定价逻辑:私有化交付不只是一套软件授权,而是企业内部合同知识全链路数字化基建项目,再来拆解私有化部署的成本结构。
先说结论:私有化交付的不是一套软件,而是一次企业合同知识的数字化重建。
1.算力与硬件投入:适配大模型运行的专属基础设施
传统的企业软件私有化部署,通常是“装应用、配数据库、调网络”。AI系统完全不同,它需要一个能跑大模型的推理环境,这是与传统IT本质不同的基础设施需求。
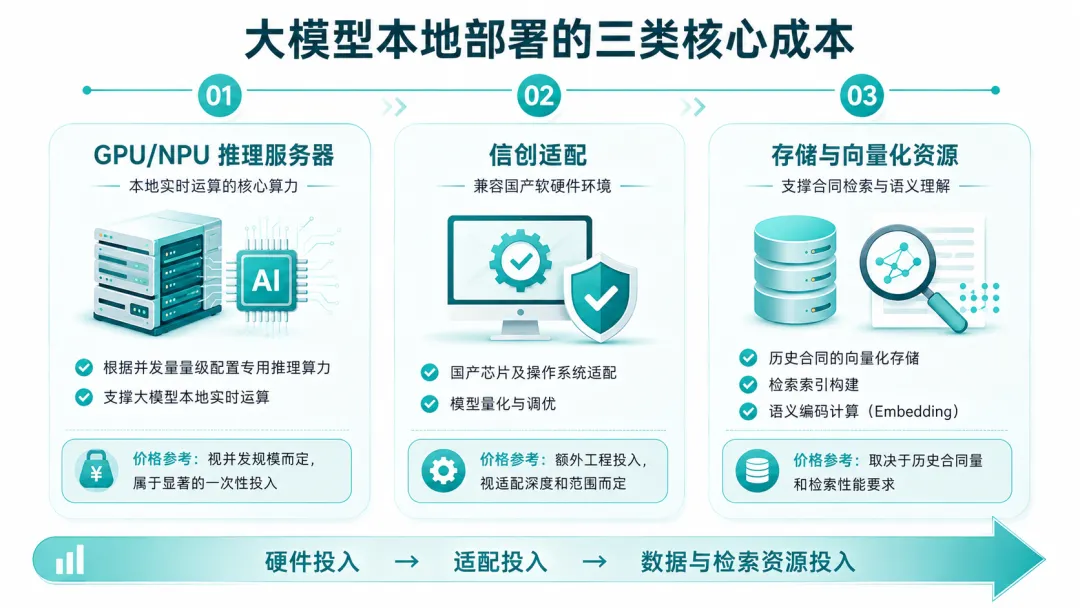
这部分成本是刚性的,也是一次性的。它买的不是软件授权,而是在企业内网里跑起一个模型的物理基础。
2.知识工程:私有化最核心、最易被忽视的隐性成本
企业数十年沉淀的法务知识分散在历史合同、内部制度、资深法务经验三处,载体杂乱、非标准化,把零散隐性知识转化为AI可读可用的数据资产,就是知识工程的核心工作,也是决定AI落地效果的关键。
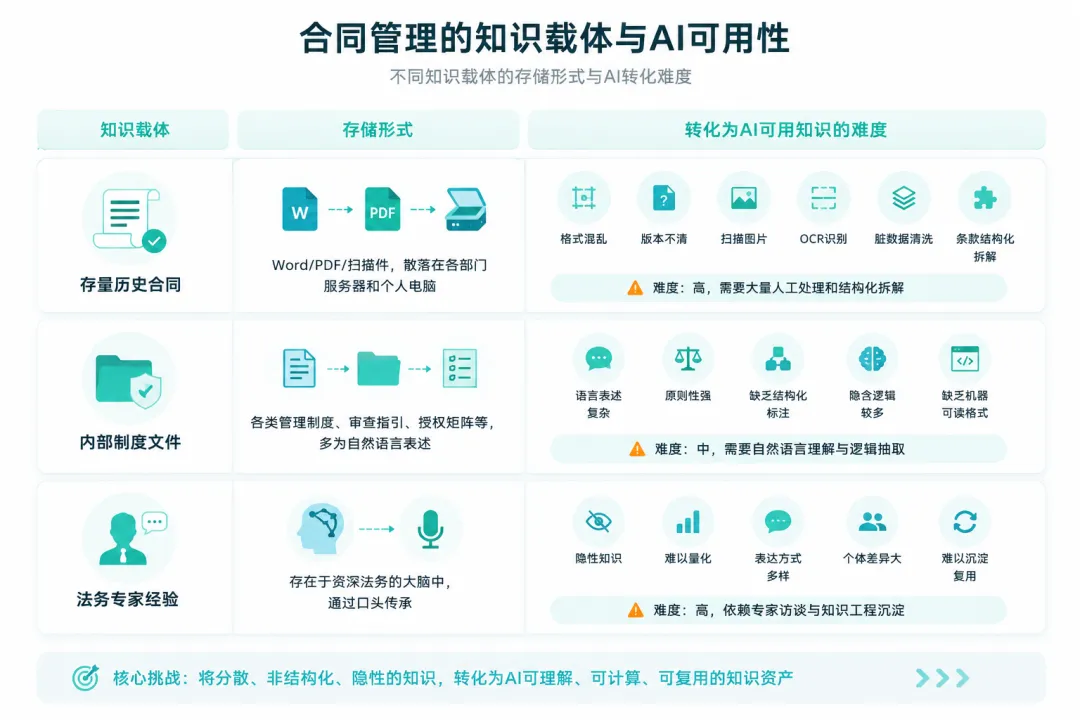
将这些分散的、非标准化的隐性知识转化为AI可理解、可执行的数字化资产,就是知识工程(Knowledge Engineering)的核心工作,具体包括合同全量清洗结构化、审查规则公式化、非标用语标注归类;需要法律专家 + 算法工程师联合驻场落地,周期从数周至数月不等。
知识工程的质量直接决定了上线后AI是否“懂行”。这项工作通常需要算法工程师、法律专家和客户法务团队紧密配合,投入周期从数周到数月不等。它的本质是帮企业做一次合同知识的数字化基建——基建质量决定了上面跑的所有应用的体验上限。
3.持续运营成本:“越用越准”不是自动发生的
SaaS的订阅费隐含了厂商持续的运维和模型升级。私有化交付后同样需要持续投入,配套常态化的运营。
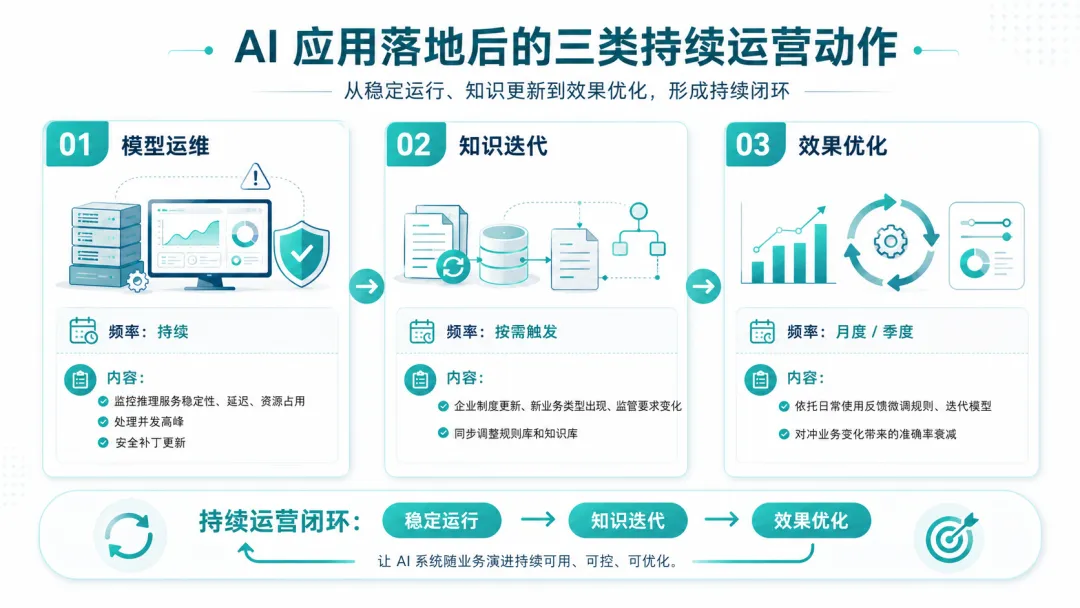
该部分投入,是保障AI持续适配业务、稳步精进的长效投入。
4.合规审计成本:可解释性是刚性需求
国央企和金融机构对AI审查结论有一个不可妥协的要求:凭什么说这条有风险?依据是什么?能不能溯源?这要求私有化部署必须具备完整的可解释性工程。

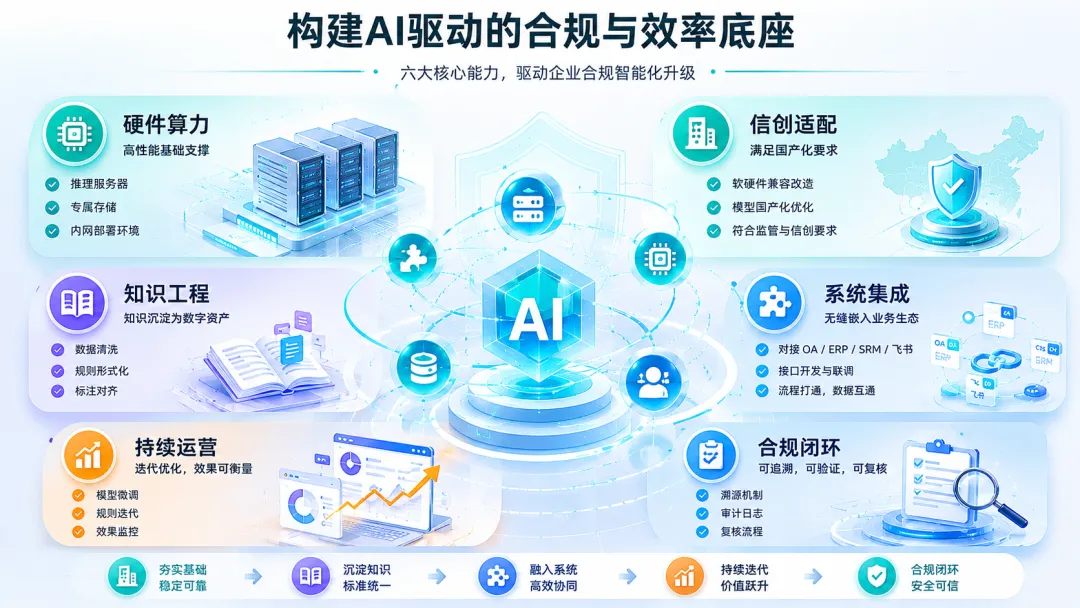
总结:私有化部署的“贵”,贵在它交付的不是一个标准化工具,而是一个需要结合企业私有知识进行定制、实施、运营的AI 法务成长体系。
那么,私有化部署后,这个体系究竟是如何实现“越用越准”的?我们将在下一篇文章中,从双轨架构、知识注入路径和数据飞轮三大维度逐层拆解,详解产品价值逻辑,说清投入成本物有所值的底层原因。
- End -
MeFlow是一款AI原生的合同全生命周期管理(CLM)系统,以MeFlow Agent为核心,让AI不仅能理解合同与业务场景,还能在系统中真实执行操作,覆盖合同全流程,在安全可控的前提下,实现人机协同的智能合同管理。
幂律已经建立起成熟的落地执行方案,如需了解更多有关幂律提供的「智能合同管理」解决方案的信息,欢迎扫描二维码和我们交流。

