 夜雨聆风
夜雨聆风Vals AI 最新复测 ProgramBench 结果出炉,Claude Opus 4.8 在 200 道「从二进制重建完整程序」的任务中,以 95% 测试通过为门槛,拿下 31 道,比 GPT-5.5 的 19 道多出六成。但 Fully Resolved——通过全部隐藏测试的任务数——只有 2 vs 1。这组数字到底说明了什么?
社交平台先炸了一轮
6 月 3 日凌晨,X 用户 @scaling01 发了一条帖:
"Opus is the best coding model. On ProgramBench as tested by Vals AI it almost resolves 15.5% of problems while GPT-5.5-xhigh is at 9.5%."
「Opus 是最好的编码模型。在 Vals AI 测试的 ProgramBench 上,它几乎解决了 15.5% 的问题,而 GPT-5.5-xhigh 为 9.5%。」
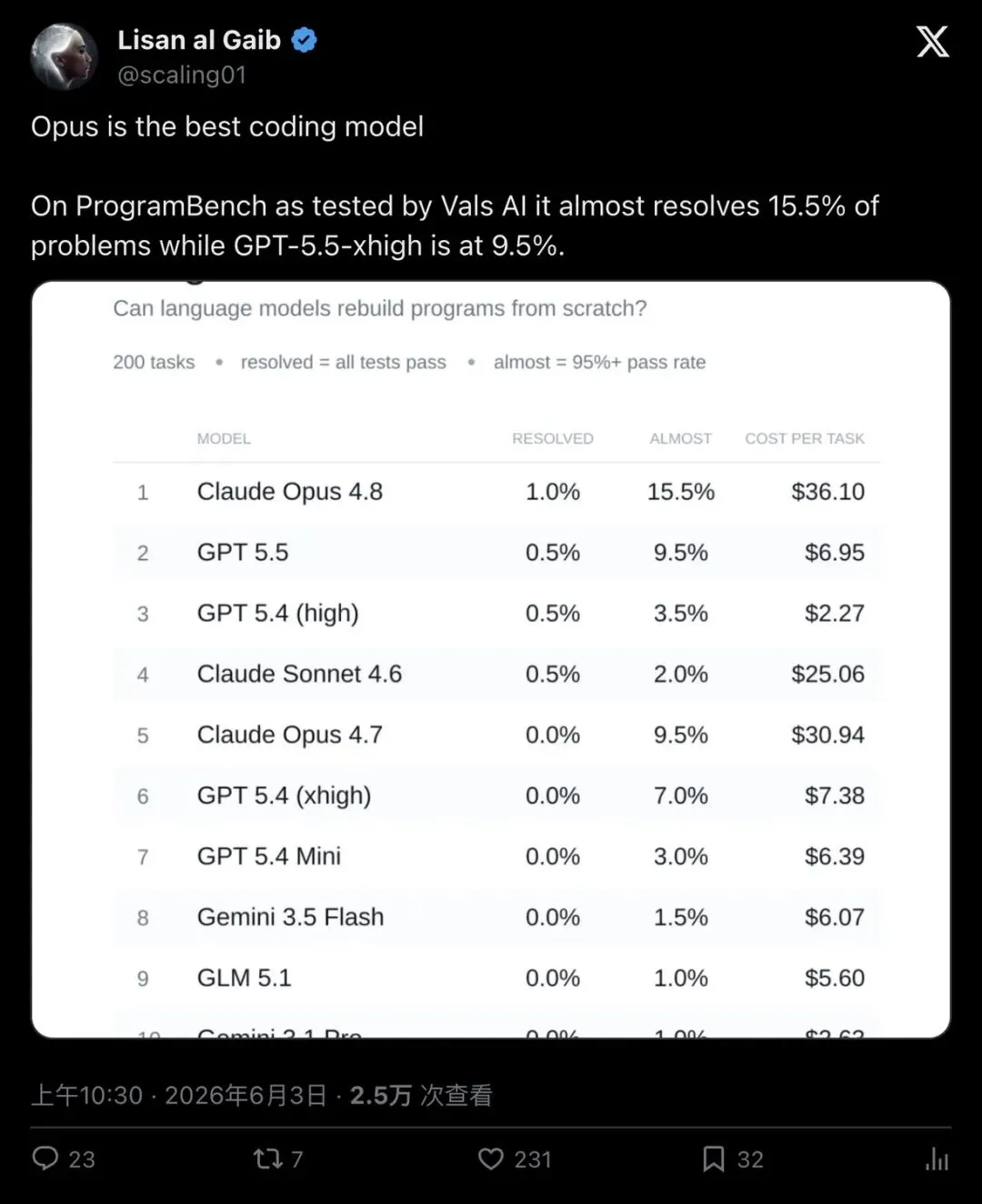
▲ @scaling01 的推文与 ProgramBench 排名表截图,发布后获得超 230 点赞、2.5 万次浏览
帖子附了一张 Vals AI 的排名表,Opus 4.8 排第一,GPT 5.5 排第二,差距看起来很大。
评论区立刻分成两派。
有人追问成本:帖主自己也补了一句"costs are of course horrendous..."(成本当然吓人)。还有人算了一笔账——如果把 Opus 的钱拿去多跑几轮 GPT 5.5,结果可能更划算。
也有人直接泼冷水:
"calling 15.5% the best mostly means everyone else is failing slightly harder"
「说 15.5% 就是最好的,主要说明其他模型只是失败得更彻底一点。」
还有人表态:"the only eval I trust is my day to day usage"——我只信自己每天用出来的效果。
先看 ProgramBench 到底在测什么
在讨论数字之前,必须搞清楚这个 benchmark 的任务有多变态。
ProgramBench 由 Meta(Facebook Research)开源,论文标题就是一个问题:Can Language Models Rebuild Programs From Scratch?(语言模型能从零重建程序吗?)
▲ facebookresearch/ProgramBench GitHub 仓库,目前 698 星、49 Fork,MIT 开源协议
任务设定是这样的:给模型一个编译好的二进制文件和一份行为文档,让它从零写出一个完整的代码库,要求能编译、能通过全部隐藏测试。
"Given only a compiled binary and its documentation, AI agents must architect and implement a complete codebase that reproduces the original program's behavior."
「只给已编译二进制及其文档,AI agent 必须设计并实现一个完整代码库,复现原程序行为。」
这跟平时聊的 LeetCode 刷题、函数补全、甚至 SWE-bench 的 patch 修复都不一样。ProgramBench 要求的是逆向工程级别的完整实现——你得猜出程序结构、CLI 行为、边界条件、错误处理,然后从头把整个东西写出来。
▲ ProgramBench 论文页面,200 道任务涵盖 CLI 工具到复杂软件,从 C 到 Python 等多语言
200 道任务,难度跨度极大。Vals AI 的数据显示,最简单的 50 道平均通过率 66.7%,最难的 50 道只有 21.4%。就算是 Opus 4.8 和 GPT 5.5,在最难的四分之一任务上也只有 39.5% 和 37.2% 的通过率。
Vals AI 的三把尺子
Vals AI 对 ProgramBench 跑了 18 个模型,更新时间标注为 2026 年 6 月 2 日。关键在于,它用了三个不同粒度的指标来衡量模型表现:
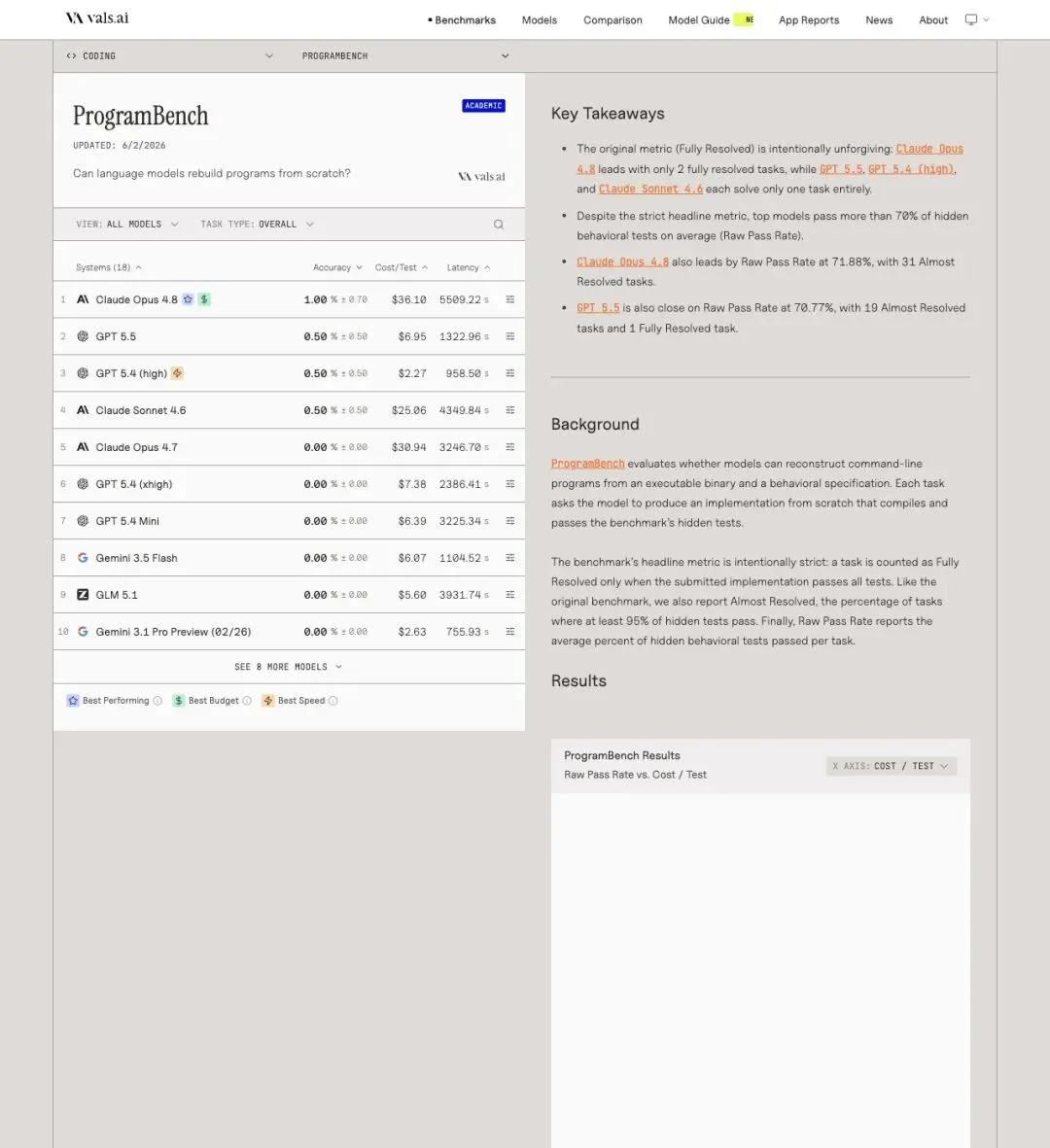
▲ Vals AI ProgramBench 官方页面,含排名、Key Takeaways 与指标定义
第一个:Fully Resolved(完全解决)
"a task is counted as Fully Resolved only when the submitted implementation passes all tests."
「只有提交的实现通过所有测试时,任务才会被计为 Fully Resolved。」
这是最严格的标准。结果如何?
Claude Opus 4.8:2 道 GPT 5.5:1 道 GPT 5.4 (high):1 道 Claude Sonnet 4.6:1 道
200 道题,最好的模型也只完全解决了 2 道。
第二个:Almost Resolved(接近解决,95% 门槛)
"Almost Resolved, the percentage of tasks where at least 95% of hidden tests pass."
「Almost Resolved 指至少 95% 隐藏测试通过的任务比例。」
这就是社交平台上流传的那组数字的真实来源:
Claude Opus 4.8:31 道(15.5%) GPT 5.5:19 道(9.5%) Claude Opus 4.7:19 道(9.5%) Claude Sonnet 4.6:14 道(7.0%)
Opus 4.8 在这个口径上确实领先——比 GPT 5.5 多了 12 道,多出 63%。但请注意,这衡量的是「差一点就全过」的任务数量,不等于「完全解决」。
第三个:Raw Pass Rate(平均测试通过率)
这个指标看的是所有任务上隐藏测试的平均通过比例:
Claude Opus 4.8:71.88% GPT 5.5:70.77%
两者几乎打平。真正拉开差距的地方在尾部:那些「差最后 5% 就能全部通过」的任务上,Opus 4.8 比 GPT 5.5 多搞定了 12 道。
成本:房间里的大象
Vals AI 的排名表还有一列容易被忽略的数字——每任务成本。
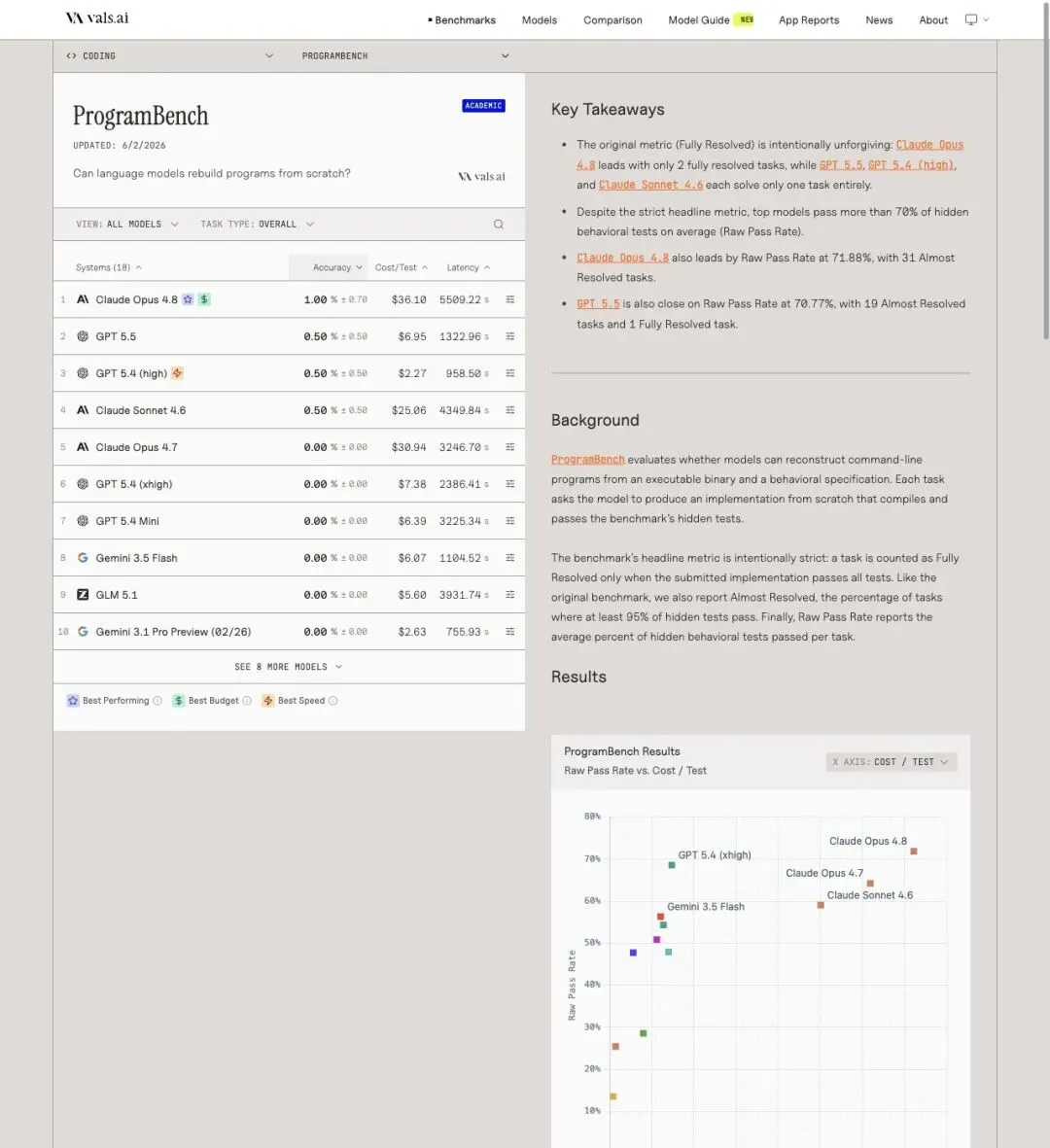
▲ Vals AI ProgramBench 结果区域,展示各模型的 cost/test 与难度分布
从排名表看:
Claude Opus 4.8:每任务$36.10 GPT 5.5:每任务$6.95 GPT 5.4 (high):每任务$2.27
Opus 4.8 的单任务成本是 GPT 5.5 的5 倍多。
Vals AI 官方也指出:GPT 5.5 和 GPT 5.4 xhigh 在每任务 $8 以下的区域,raw pass rate 表现更有效率;Opus 4.8 以更高成本拿到了最高 raw pass rate。
这就引出一个实际问题:如果预算有限,是花 $36 跑一次 Opus,还是花同样的钱让 GPT 5.5 跑五轮、取最优结果?评论区已经有人在算这笔账了。
15.5% 背后的真实图景
把三个指标放在一起看,一个更完整的画面浮出来了:
在「最后冲刺」阶段,Opus 4.8 明显更强。31 道 Almost Resolved vs 19 道,在快要全部通过的任务上,Opus 4.8 的完成度更高。这对那些需要把代码推到「接近可用」状态的场景有参考价值。
在平均水平上,两者几乎打平。Raw Pass Rate 分别为 71.88% 和 70.77%,放在 200 道难度跨度极大的任务上,谁都没有绝对优势。
在完全解决率上,所有模型都还很挣扎。200 道题只有 2 道被完全解决,说明即使 frontier 模型能在大部分任务上通过大量测试,也经常卡在最后几个边界条件、CLI flag 或格式细节上。
成本差异是实际选型绕不开的因素。如果目标是尽可能把难题推到接近通过,Opus 4.8 在当前口径上领先;如果目标是成本效率,GPT 系列仍有竞争力。
这个 benchmark 的方法论意义
ProgramBench 做了一件有意思的事:它没有只给 pass/fail,而是引入了 Almost Resolved 这个中间层指标。
对于真实工程来说,「通过 95% 测试」和「通过 100% 测试」之间的距离,可能恰好是人类工程师需要介入审查的部分——最后那 5% 的行为差异,往往藏在边界条件、错误码、特殊输入格式里。
这也意味着,coding benchmark 正在从「能不能做对」走向更细粒度的评估:接近完成的程度、成本效率、以及在长尾难题上的分布表现。
一个 benchmark 上的排名第一,不能直接等于「所有编程场景的最优选择」。但 ProgramBench 至少提供了一个新维度:当任务从「补一个函数」升级到「从二进制重建完整程序」时,模型之间的差距在哪里、差多少、要花多少钱。
这组数字值得记住,但更值得记住的是数字背后的口径。
— END —
