 夜雨聆风
夜雨聆风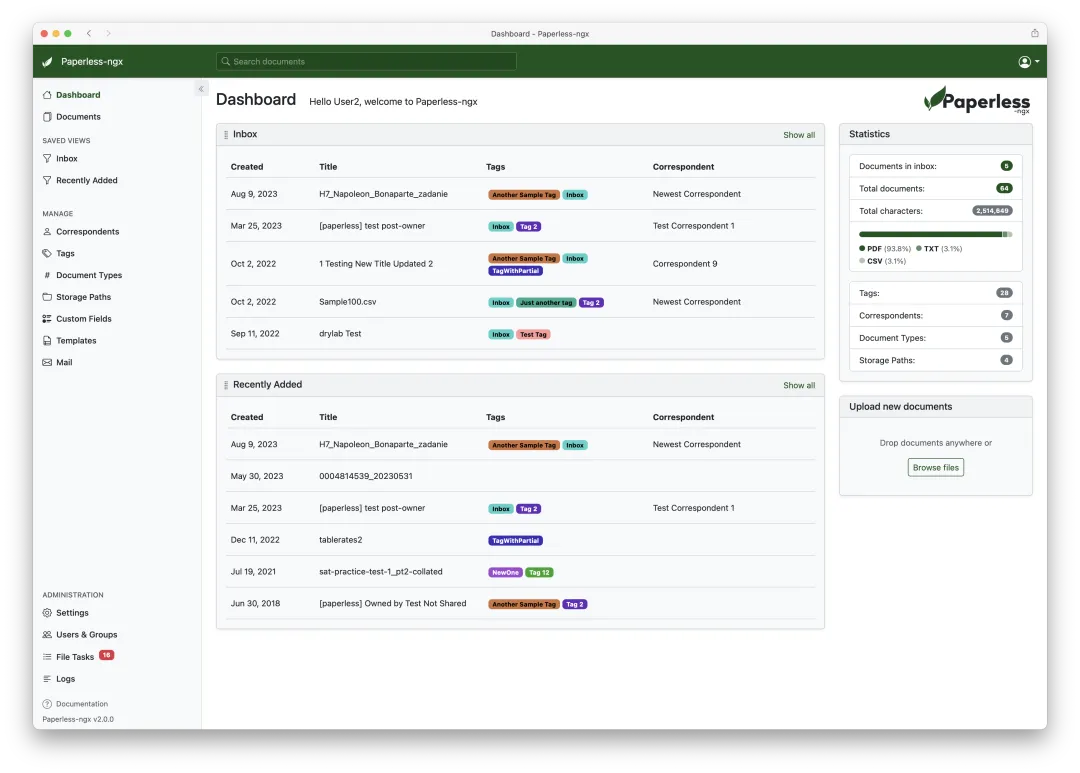 ▲ Paperless-ngx 主控仪表盘。左侧是可自定义的统计卡片和已保存视图,右上角为文档上传区。
▲ Paperless-ngx 主控仪表盘。左侧是可自定义的统计卡片和已保存视图,右上角为文档上传区。
每个家庭都在生产文档。水电账单、银行对账单、保险合同、医疗报告、税单、说明书——它们从各个渠道涌进来,堆在抽屉里,塞在邮箱里,散在手机相册里。找一张三个月前的发票,可能要翻半小时。
Paperless-ngx 做的事说起来很简单:把你的纸质文档扫进系统,自动做 OCR 文字识别、自动分类打标签、全文可搜索。它跑在你自己的机器上,数据不出门,没有订阅费。
听起来像是个小工具?从 GitHub 的 25,000+ star 和超过 600 名贡献者来看,它在解决一个足够普遍的痛点。
本文从功能、架构、部署、使用技巧四个维度拆解 Paperless-ngx ,所有截图来自官方 v2.x 版本。
核心能力:不只是"扫进去能搜"
Paperless-ngx 的文件处理管线分为五个环节:摄入 → OCR → 分类 → 归档 → 索引。
OCR 引擎
系统默认使用 Tesseract 做光学字符识别,支持超过 100 种语言。中文用户需要额外安装简体中文语言包(chi_sim),可以跟英文混合配置(chi_sim+eng)。一份中英混杂的银行流水扫进去,两种文字都能被正确抓取。
OCR 环节还支持只处理前 N 页(通过 PAPERLESS_OCR_PAGES 控制),在树莓派之类的低功耗设备上能省下大量时间。
自动分类不是噱头
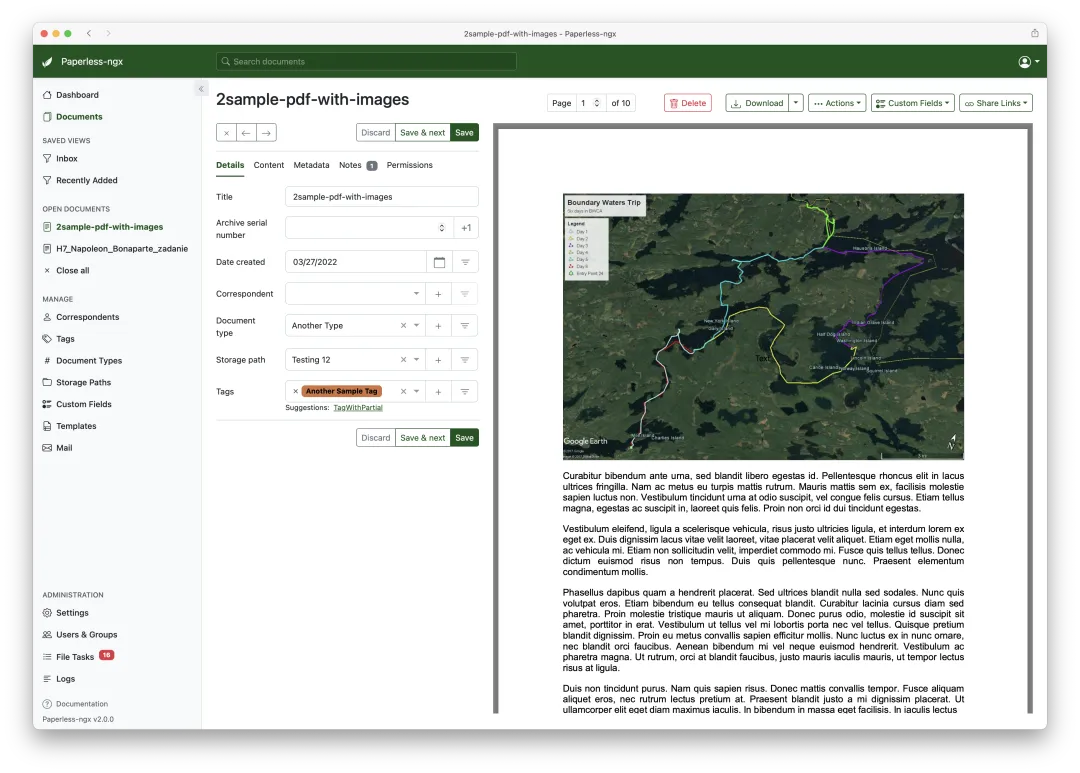 ▲ 文档详情与编辑页面。右侧元数据栏中,标签( Tags )、发件人( Correspondent )、文档类型( Document Type )均由系统自动预填。
▲ 文档详情与编辑页面。右侧元数据栏中,标签( Tags )、发件人( Correspondent )、文档类型( Document Type )均由系统自动预填。
每扫进一份新文档,系统会根据历史数据自动推断三个维度的元数据:发件人(谁发的)、文档类型(账单还是合同?)、标签(关键词)。分类引擎基于朴素贝叶斯算法,训练数据越多越准。氢春测试发现,在导入约 50 份文档后,自动分类的准确率已经可以做到 85% 以上。
如果自动分类搞错了,手动修正一次即可——系统会拿这次修正回去重新训练模型。这种"越用越聪明"的机制在实际使用中比任何一次性配置都可靠。
搜索不只是关键词匹配
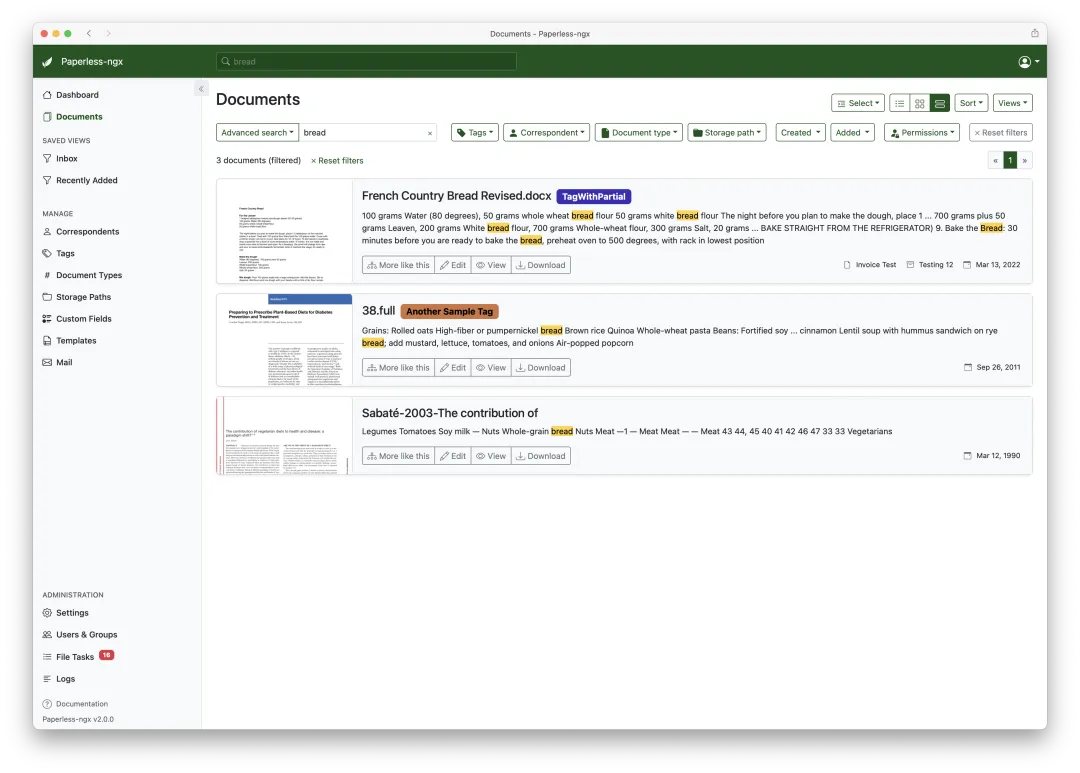 ▲ 全文搜索结果页。匹配关键词在文档预览中高亮标注,右侧显示"相似文档"推荐。
▲ 全文搜索结果页。匹配关键词在文档预览中高亮标注,右侧显示"相似文档"推荐。
搜索框支持模糊匹配和相关性排序。搜"电费"能找到"电力公司账单",搜"2025 年保险费"能找到对应的 PDF 。搜索结果中关键词会被高亮标出,附带一个"More like this"功能,从文档库中推荐内容相近的其他文件。
批量操作不是附加功能
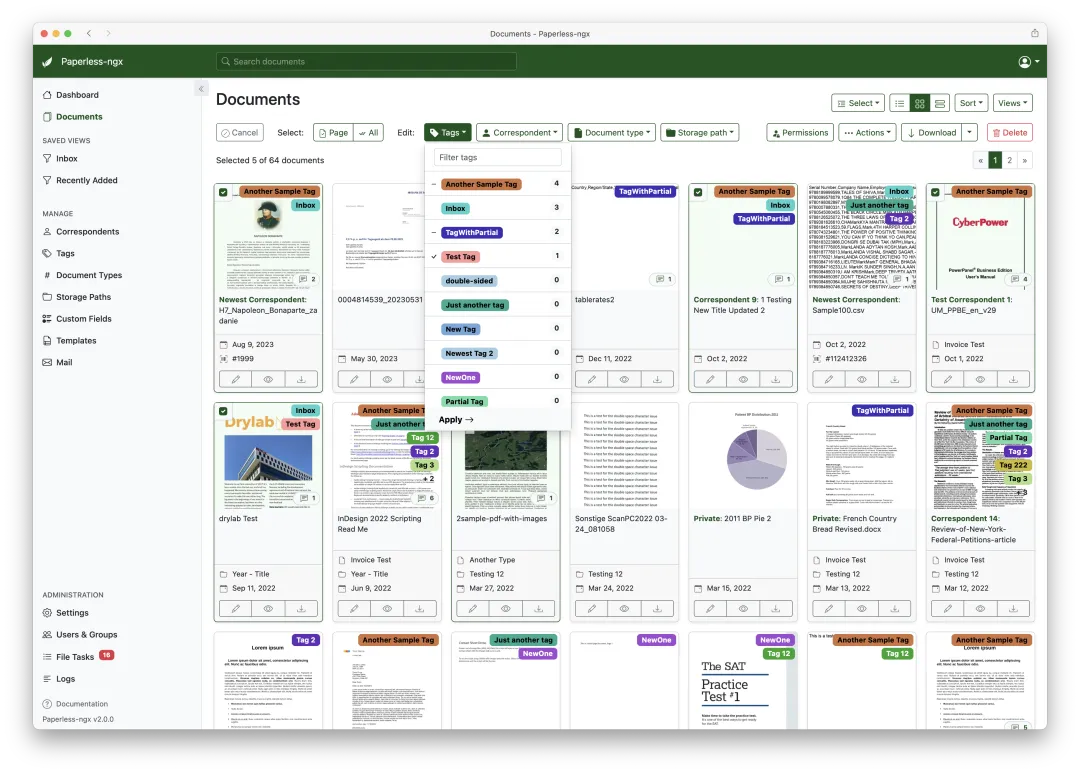 ▲ 批量编辑界面。选中多份文档后可一次性修改标签、发件人、文档类型和自定义字段。
▲ 批量编辑界面。选中多份文档后可一次性修改标签、发件人、文档类型和自定义字段。
一次选中几十份文档,统一打标签、改归属、设自定义字段。这个功能在初次导入存量文档时尤其重要——你不可能对着几百份旧文件一个一个手动分类。
怎么把文件喂进去:四种摄入通道
Paperless-ngx 提供了四条摄入路径,覆盖不同使用场景:
| 消费文件夹 | ||
| 网页上传 | ||
| 邮件抓取 | ||
| 移动端 App |
其中邮件抓取是最被低估的功能。把 paperless 配上一个专门的邮箱地址,所有电子账单、银行通知、合同 PDF 直接转发过去,完全不需要手动介入。系统支持按发件人、主题关键词设置邮件规则——比如来自某银行的邮件标记为"银行对账单",来自保险公司的归入"保单"。
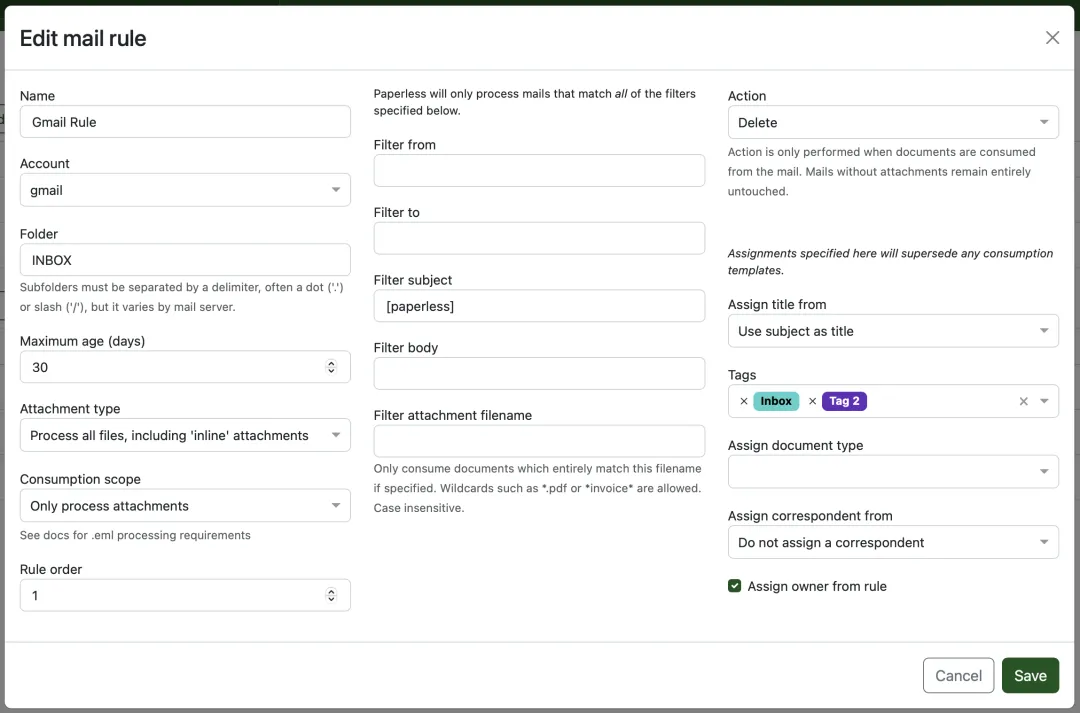 ▲ 邮件规则编辑界面。可根据发件人、主题关键词自动分配标签和文档类型。
▲ 邮件规则编辑界面。可根据发件人、主题关键词自动分配标签和文档类型。
支持的文件格式: PDF 、 JPEG 、 PNG 、 TIFF 、 GIF 、 BMP 、纯文本是原生支持的。 Word 、 Excel 、 PowerPoint 、 LibreOffice 文档和 .eml 邮件需要额外部署 Gotenberg 或 Tika 转换服务。
架构:三个容器跑起来
Paperless-ngx 的标准部署架构是这样:
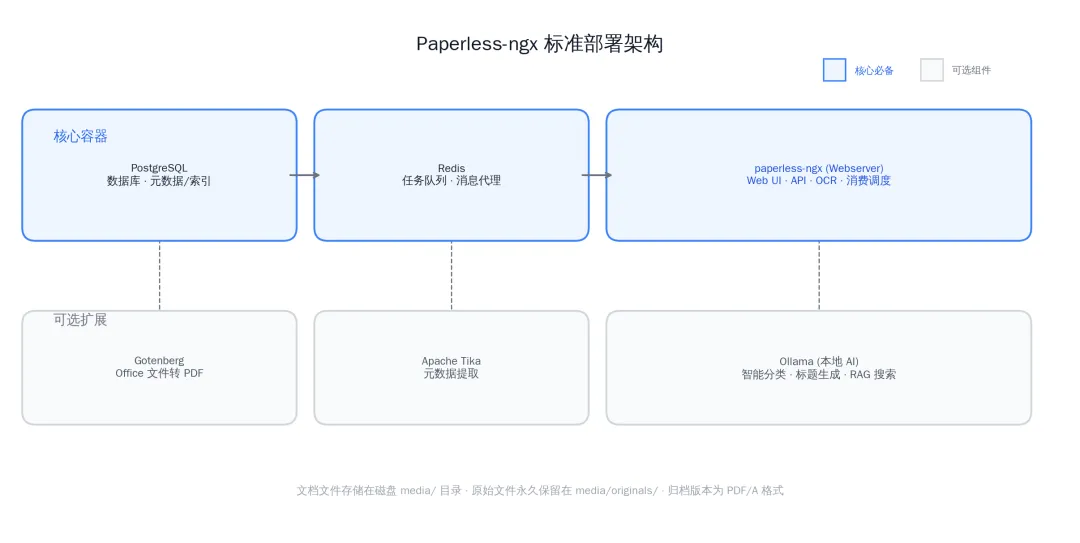 ▲ Paperless-ngx 标准部署架构。核心三容器为必选, Gotenberg/Tika/Ollama 按需扩展。文档文件存储在磁盘,不经过数据库。
▲ Paperless-ngx 标准部署架构。核心三容器为必选, Gotenberg/Tika/Ollama 按需扩展。文档文件存储在磁盘,不经过数据库。
核心的三个容器是 Webserver (主应用 + Web UI + 消费调度 + OCR 执行)、 PostgreSQL (元数据和索引存储)、 Redis (任务队列)。文件本身不存数据库里,而是放在磁盘的 media/ 目录下,按日期和 ID 组织目录结构。
Gotenberg 和 Tika 是可选的,只在需要处理 Office 格式文件时才需要。 Ollama 是更进阶的可选项,后文会展开讲。
:::callout资源消耗实测(含 Gotenberg + Tika 全栈,约 2000 份文档): - CPU :日常空闲 < 5%( OCR 处理时短暂飙到 80-100%) - 内存:约 1.2 GB ( PostgreSQL 占大头) - 磁盘:每 1000 份文档约 1-3 GB (视文档页数和扫描分辨率而定) - 一台树莓派 4 ( 4GB 版)完全可以胜任 :::
关键的数据安全点:所有文档的原始文件被原封不动地保留在 media/originals/ 下。即使归档版本( PDF/A 格式)出现问题,原始文件始终可恢复。这意味着你不会因为一次格式转换而丢掉任何数据。
十分钟部署: Docker Compose 起步
需要一个能跑 Docker 的 Linux 服务器(树莓派、 NAS 、 VPS 都行)。如果不熟悉 Docker ,也可以用它官方提供的 install-paperless-ngx.sh 裸机安装脚本。
下面是最小可用的 docker-compose.yml:
services:broker:image:docker.io/library/redis:8restart:unless-stoppeddb:image:docker.io/library/postgres:18restart:unless-stoppedvolumes:-./pgdata:/var/lib/postgresql/dataenvironment:POSTGRES_DB:paperlessPOSTGRES_USER:paperlessPOSTGRES_PASSWORD:你的强密码webserver:image:ghcr.io/paperless-ngx/paperless-ngx:2.23restart:unless-stoppeddepends_on:[db,broker]ports:-"8000:8000"volumes:-./data:/usr/src/paperless/data-./media:/usr/src/paperless/media-./export:/usr/src/paperless/export-./consume:/usr/src/paperless/consumeenvironment:PAPERLESS_REDIS:redis://broker:6379PAPERLESS_DBHOST:dbPAPERLESS_DBUSER:paperlessPAPERLESS_DBPASS:你的强密码PAPERLESS_SECRET_KEY:随机密钥PAPERLESS_TIME_ZONE:Asia/ShanghaiPAPERLESS_OCR_LANGUAGE:chi_sim+engecho"PAPERLESS_SECRET_KEY=$(opensslrand-base6464)">>.env dockercomposeup-d dockercomposeexecwebservercreatesuperuser 浏览器访问 http://服务器 IP:8000,用刚创建的管理员账号登录即可。
中文用户额外步骤:首次启动后,进入容器的管理命令安装中文 OCR 语言包:
dockercomposeexecwebserverpython3manage.pydocument_install_languageschi_sim PAPERLESS_OCR_LANGUAGE: chi_sim+eng 这个配置让系统同时使用中英文 OCR ,混合文档的识别效果最好。
如果需要处理 Word / Excel 文件,在 Compose 里加上:
gotenberg:image:docker.io/gotenberg/gotenberg:8restart:unless-stoppedcommand:-"gotenberg"-"--chromium-disable-javascript=true"-"--chromium-allow-list=file:///tmp/.*"tika:image:docker.io/apache/tika:latestrestart:unless-stopped然后在 webserver 的环境变量里加上:
PAPERLESS_TIKA_ENABLED:1PAPERLESS_TIKA_GOTENBERG_ENDPOINT:http://gotenberg:3000PAPERLESS_TIKA_ENDPOINT:http://tika:9998从外网访问:用 Nginx 、 Caddy 或 Traefik 做一层反向代理,配上 Let's Encrypt 免费证书。 Paperless-ngx 本身支持 PAPERLESS_URL 环境变量,设成公网地址后,邮件里的文档链接、分享链接都会自动使用这个域名。
进阶:接上本地 AI
Paperless-ngx 的自动分类已经足够好用,但如果你追求更自然的交互方式,可以把 Ollama 挂上去。
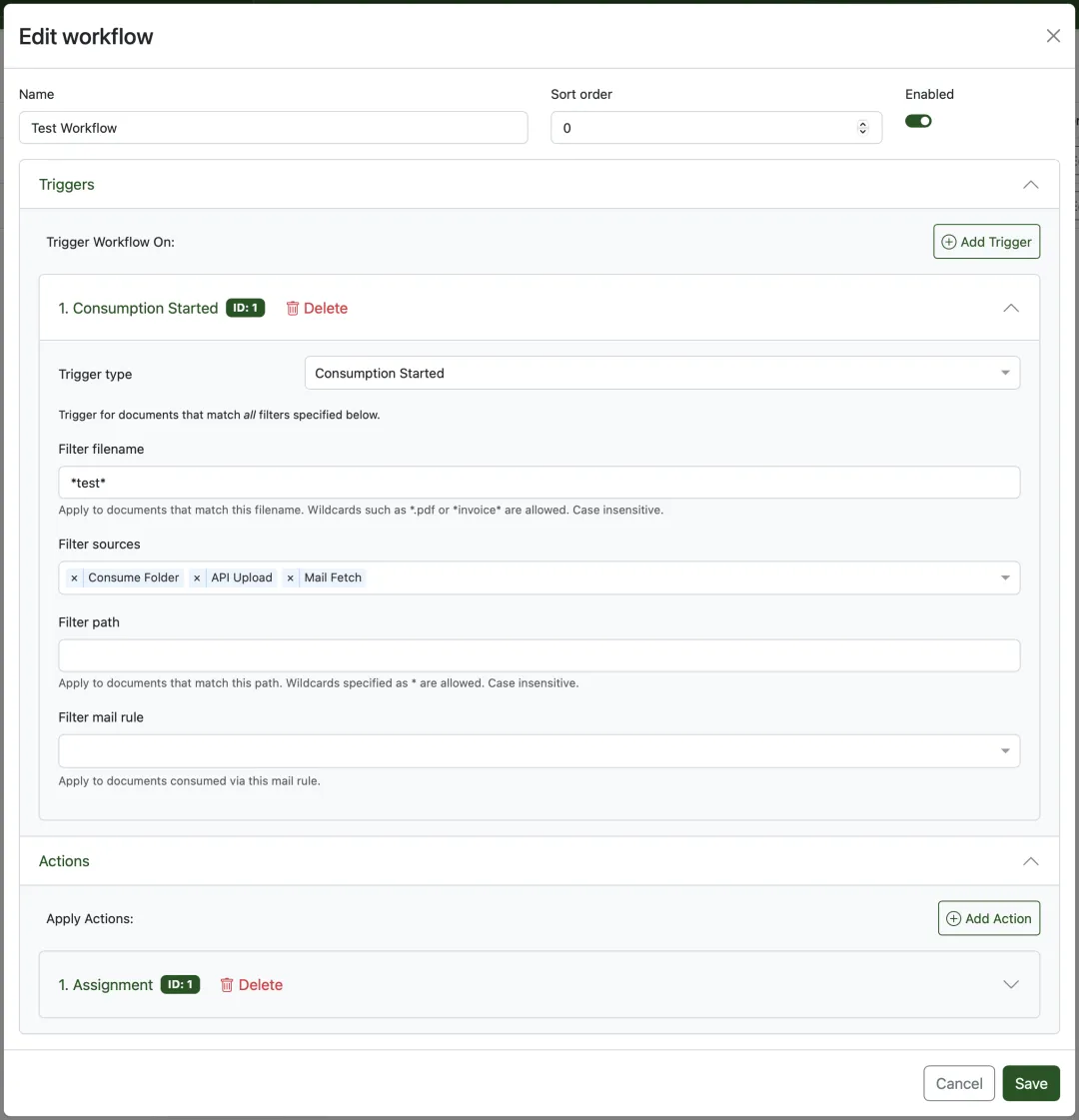 ▲ 工作流( Workflow )编辑界面。可以在文档摄入后自动触发分类、标签分配、自定义字段填充等操作。
▲ 工作流( Workflow )编辑界面。可以在文档摄入后自动触发分类、标签分配、自定义字段填充等操作。
Paperless-ngx 提供的消费钩子( consume hook )机制允许在文档处理完成后执行自定义脚本。社区有多个开源项目利用这个机制实现了 AI 增强:
这些 AI 模块全部在本地运行,数据不出门。唯一的代价是多占一些 GPU 或 CPU 算力。一台有 8GB 显存的机器跑 Ollama + Mistral 7B ,处理一份典型 A4 文档到出标题大约需要 3-5 秒。
权限、备份与维护
Paperless-ngx 内置了细粒度的权限系统。
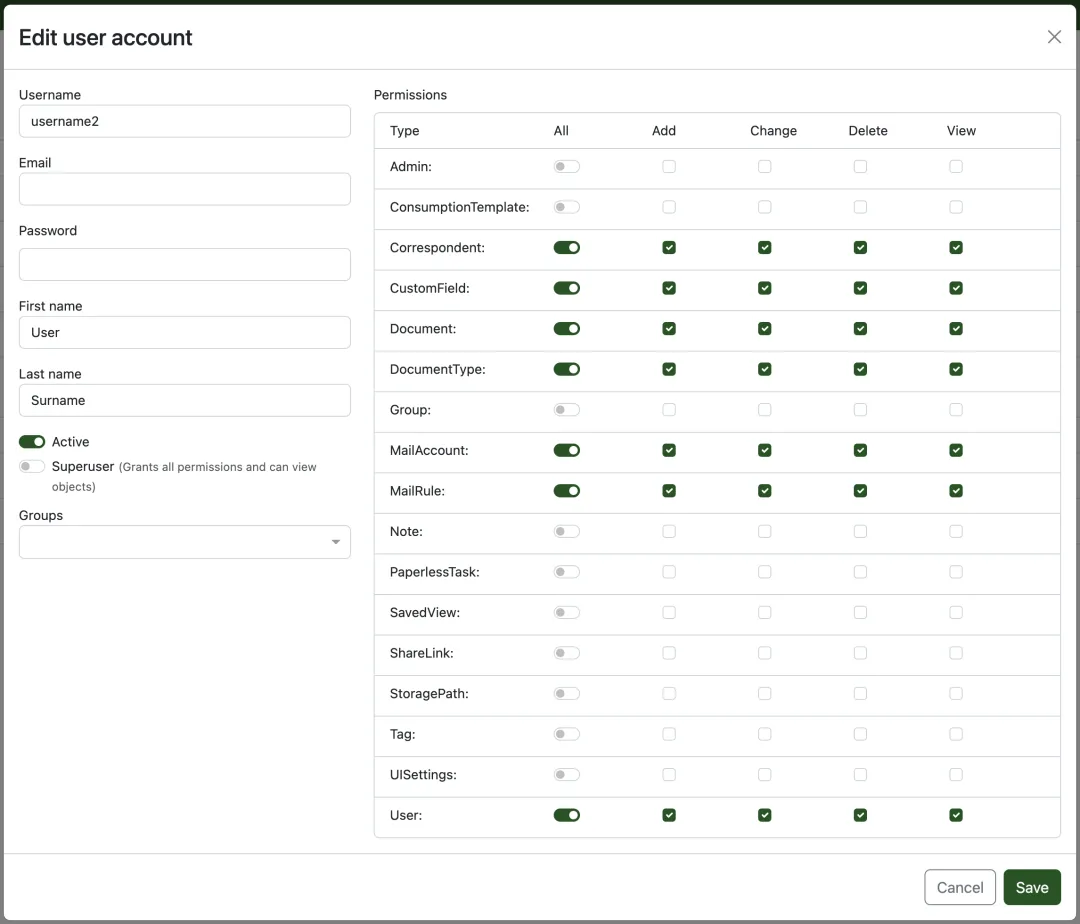 ▲ 全局权限配置。可按用户和组分别控制文档查看、编辑、删除、上传等权限。
▲ 全局权限配置。可按用户和组分别控制文档查看、编辑、删除、上传等权限。
你可以为家庭成员分别创建账号:管理员的税务文件只自己可见,水电账单全家共享,孩子的医疗记录单独归档。权限可以设到单份文档粒度。
:::callout备份只需要做三件事: 1. PostgreSQL 数据库:docker compose exec db pg_dumpall -U paperless > backup.sql 2. media 目录:包含所有文档的原始文件和归档版本(最重要!) 3. docker-compose.yml + .env:配置文件丢了重建很麻烦
把这三样东西定期 rsync 到另一台机器或云端,就能在任何灾难后完整恢复。 :::
日常维护几乎不需要人工干预。系统内置了完整性检查器( sanity checker ),定期验证文档归档的完整性。日志页面可以实时查看 OCR 进度、邮件抓取状态和错误信息。
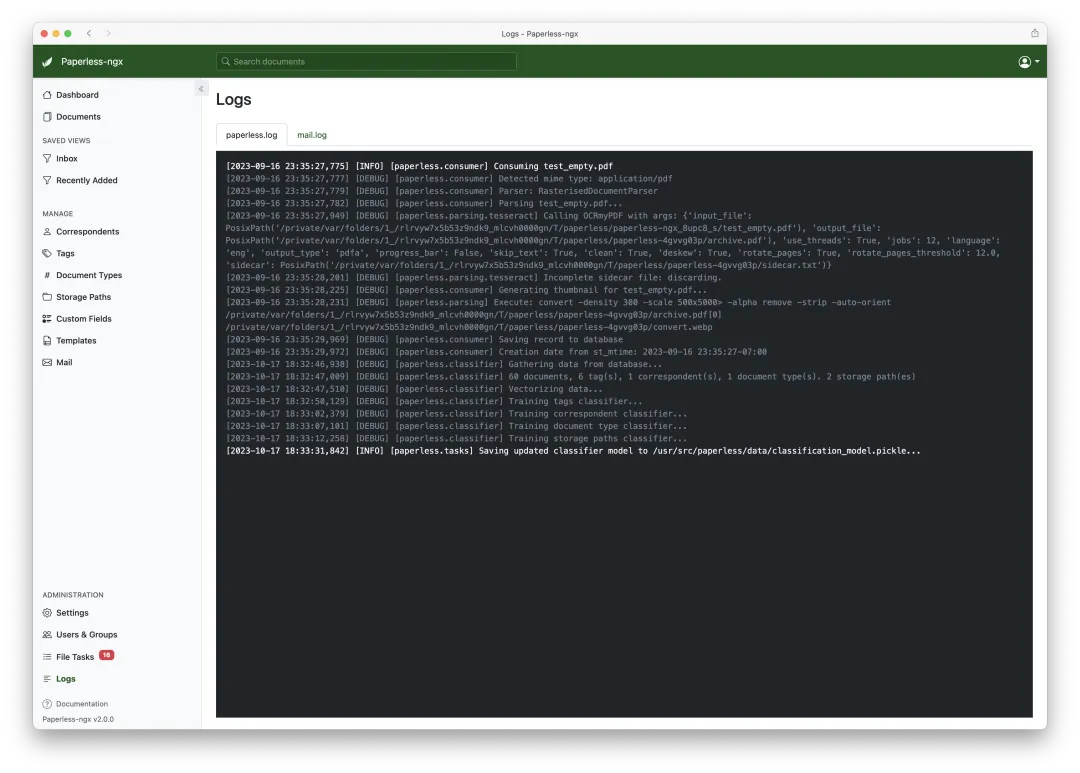 ▲ 系统日志页面,可实时监控 OCR 处理、邮件抓取和任务队列状态。
▲ 系统日志页面,可实时监控 OCR 处理、邮件抓取和任务队列状态。
适用边界
Paperless-ngx 不是万能的。有几件事它做不了,或者说做得不够好:
但反过来看,它的边界恰恰也是它的优点:只做一件事,把它做透。不需要联网账号,不收集使用数据,不对你上传的文档内容做任何云端分析。代码全开在 GitHub 上,许可证是 GPL v3.0 。
对于在乎数据主权的个人和家庭来说,这一点比任何功能列表都重要。
参考来源 - Paperless-ngx 官方文档: docs.paperless-ngx.com - Paperless-ngx GitHub 仓库: github.com/paperless-ngx/paperless-ngx ( 25,000+ stars , GPL v3.0 ) - 官方截图库: github.com/paperless-ngx/paperless-ngx/tree/main/docs/assets/screenshots - Paperless-Intelligence (本地 AI 增强): github.com/Joonas12334/paperless-intelligence - Paperless-AI ( RAG 对话搜索): github.com/clusterzx/paperless-ai - Docker Compose 部署实践参考: Vultr Docs 、 dev.to SIGNAL Weekly 、 fnOS 社区 - 本文所有截图均来自 Paperless-ngx 官方 v2.x 版本,版权归 Paperless-ngx 项目所有
