 夜雨聆风
夜雨聆风
我见过太多AI项目了,Demo的时候大家都觉得牛,一上线就拉胯😅,真不是模型不行,是运营模式压根没跟上,这次IBM Think 2026,他们掏出了一套企业AI运营模式蓝图,说白了就三个词:混合云、治理、规模化,而且这不是画饼,是一套能落地的框架👍。
IBM在Think 2026上放了个大招——一套企业AI运营模式蓝图,核心就三个词:混合云、治理、规模化。但别急着抄作业,先看看它到底想解决什么问题:为什么模型不是瓶颈?怎么让AI从Demo真正跑起来?
首先别急着看IBM发了什么产品,先搞清楚为什么他们要提“AI运营模式”这个词,很多公司砸钱买GPU、调参数,结果一到生产环境就扑街,数据不一致、权限乱得像蜘蛛网、模型版本还用Excel管理,每次更新手动操作——这哪是搞AI,分明是给运维添乱。
IBM这个蓝图的核心思想特别直白:把AI当成和数据库、ERP一样的关键业务系统来运营,别当实验品,这就意味着要有清晰的SLA、变更管理、事故响应、成本核算,说白了,AI运营模式就是企业IT运营模式在AI上的延伸,只不过多了模型管理、数据漂移、可解释性这些新坑。
对技术负责人来说,下次立项别光问“准确率多少”,还得问“上线了谁盯着?模型怎么回滚?日志存多久?”,这些问题不琢磨清楚,AI项目永远停留在Demo阶段🤷。
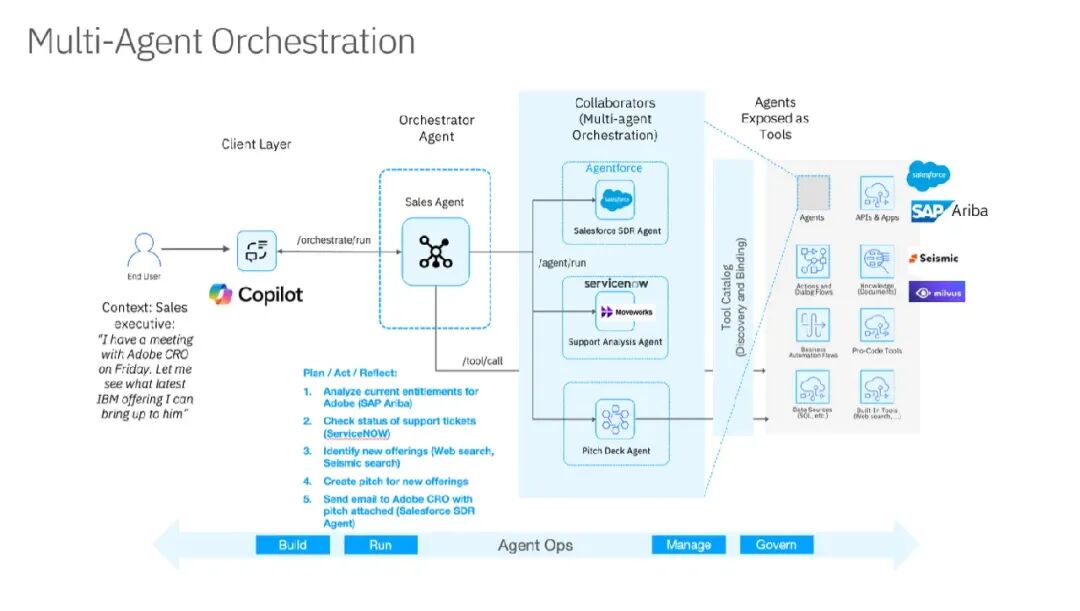
IBM这次在Think 2026上又提混合云,但比之前实在多了:AI工作负载必须能在本地、私有云、公有云之间灵活调度。原因很简单——数据主权和延迟摆在那,比如金融公司交易数据不能出域,但模型训练又需要大算力,混合云几乎是唯一解。
但混合云也真的坑,很多企业折腾五六年了,结果两边都不讨好:本地云管不好,公有云也发挥不出弹性,IBM这次在运营模式里专门强调统一管理平面——不管模型跑在哪,都用同一套工具部署、监控、治理,对架构师来说,这算是减少运维复杂度一个明确的信号。
另外还有个细节,蓝图里特别提了边缘AI,工厂、零售店、医院这些地方,数据不能全传回中心,得在本地做推理,混合云从数据中心延伸到边缘,才算是完整的AI底座😅。

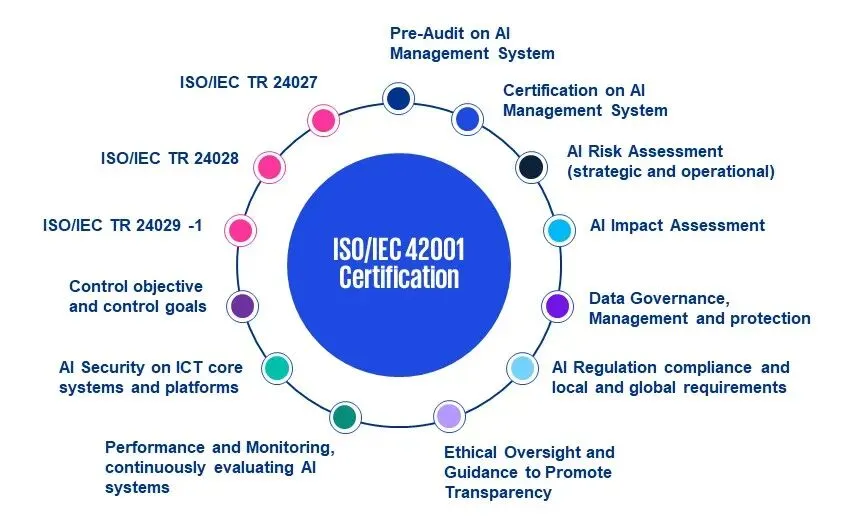
这次IBM把治理提到了和计算、存储同等的位置,说白了,没有治理的AI就是定时炸弹,模型偏见、数据泄露、合规违规,任何一个都够公司喝一壶,IBM蓝图要求从数据采集那一刻就上标签、设权限,模型上线前必须过公平性测试,推理过程全程审计。
问题是,很多公司一提到治理就想到“加流程、加审批”,然后效率立马断崖式下跌,IBM的做法是自动化治理:用策略引擎动态控制权限,用内置的偏见检测工具在训练时自动报警,而不是靠人工审计,这很务实😮——不增加太多额外负担,但把底线守住了。
对我们来说,规划AI平台时就把治理模块纳入选型清单,别想着以后补,预算里也要留出合规工具的份子,另外可以看看ISO 42001等AI管理标准,IBM的蓝图也和它对齐。
IBM蓝图再好,也得结合你自家公司的实际情况,我建议技术负责人拿它当检查清单,先问自己三个问题:
第一,业务目标真的清楚吗?别是“用AI提升效率”这种虚话,得是“将客服首次解决率从60提到80%”。
第二,数据准备好了没有?不是问你有没有数据,而是数据能不能标注、能不能访问、合不合规。
第三,团队有没有运营AI的能力?没有的话,先上云托管服务,再慢慢培养能力。
IBM透露了几个客户案例,比如一家制造商用混合云加IBM的AI运营平台,模型更新周期从两周缩短到两天,关键点是他们先统一了数据湖,再治理了模型权限,注意顺序:先做数据,再上AI,别搞反。
成本控制也是一个容易忽视的点,蓝图里建议给每个模型做“成本账单”,算力、存储、人力都列清楚,让业务部门看到自己用的AI到底花了多少钱,才会逼他们去优化。一句话:没有成本意识的AI运营,迟早被财务砍预算。
很多团队在纠结自建还是采购AI平台,IBM的蓝图给了一个挺清楚的分界线:如果你的核心业务靠模型差异化吃饭(比如推荐算法、风控模型),而且团队有工程实力,那可以考虑自建核心框架;如果只是用通用能力(比如语音识别、OCR),直接买成熟的云服务或IBM的Watsonx套件就行。
IBM的混合云运营模式还提供第三种选择:在它的底座上构建自己的治理层,不用从零写Kubernetes编排,这对需要灵活但不想重造轮子的团队是个不错的折中,关键要评估:你团队里有没有懂MLOps的人?没有就别硬上自建,否则运营成本会吃掉所有收益😬。
最后提醒一句:不管自建还是采购,平台必须支持模型可解释性和审计,IBM蓝图特别强调了这一点,因为2026年各国AI监管法案密集落地,没有可解释性的模型未来可能被禁用。

如果这篇文章对你有所帮助,欢迎顺手分享、收藏、点赞、在看,你的支持就是我继续写下去的动力。




