工业级PDF智能解析AI应用横空出世!6000页PDF一键解析条目化!在汽车、航空航天、芯片等高合规性行业,系统工程师或需求分析师每天面对的首要任务,往往不是分析需求本身,而是处理承载需求的载体——一份动辄数百页、上千页的PDF需求文档。这些来自客户、主机厂的PDF版本的需求文件,格式五花八门:打字版、扫描版、图文混排版……它们是企业研发流程中的“第一道关卡”。传统做法是什么?人工拆解,打开文档,逐段复制,手动填充系统,核对层级关系。这个方法看似稳妥,实则是企业研发效率的最大漏点之一。它把高薪聘请的工程师,硬生生拖入了“数字搬运工”的角色——投入100%的时间在“搬砖”上,用来“分析”的时间所剩无几。
它吞噬的不仅是时间,更是研发团队真正的创造力和核心竞争力。
当企业依赖人工进行文档结构化时,实际上是在付出三重“隐性成本”:文档的规模与处理时间成正比。一份数百页的文档,往往意味着数人天的投入。这直接导致了项目启动周期的延长,特别是当多个项目并行或文档密集交收时,人力瓶颈极为突出。人的注意力是有限的。在长时间、高强度、重复性的“文字搬运”工作中,字段遗漏、层级错乱、编号错误等问题难以根除。更棘手的是,这些错误往往在审计环节或项目后期才暴露,此时纠错的成本是指数级的。最昂贵的成本,是隐性的“机会成本”。当系统工程师、需求分析师将大量精力耗费在处理文档格式上时,他们本应用于分析业务逻辑、优化架构、识别风险的核心价值,就被无形中消耗了。企业的竞争力,是核心人才认知深度的总和,而这份深度不应被埋没在琐碎的“文本搬运”里。解决问题的路径,不应是让团队更加辛苦,而是应该用AI技术将“文档处理”这个环节,从人工流程中彻底解耦出来。
高远PDF智能解析插件,正是为此而生。它基于“小模型+大模型”的算法组合,将文档解析这个任务,封装成了一个极度简单的操作——上传,然后等待。
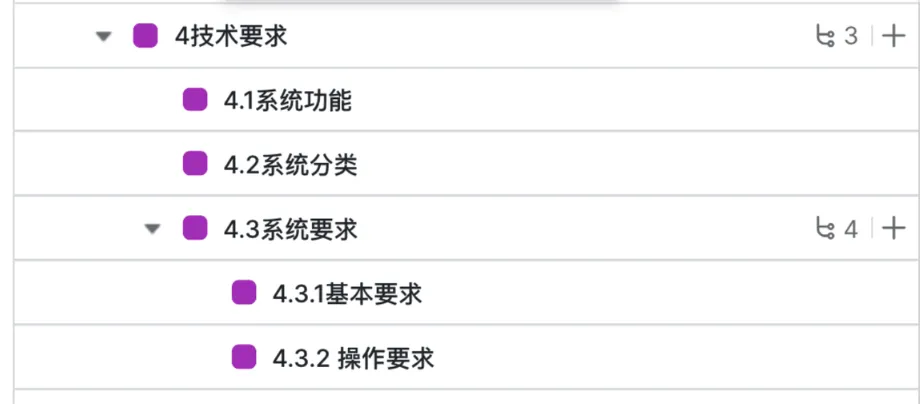
•全格式兼容:支持打字版、扫描版、图文混排的PDF、有无大纲的PDF,且对文档长度无上限(实测支持数千页)。• 智能层级还原:自动识别文档大纲(如1, 1.1, 1.1.1),并自动区分“需求(Requirement)”和“说明(Information)”等信息类型,完成精准打标。• 坐标回溯:解析后的每一条需求,都与原文的精确位置绑定。用户点击任一需求,均可秒级跳转到PDF原文中的对应段落,支持红框高亮,极大便利了审计与核对。任何技术投资都应回归到可衡量的业务价值上。我们来算一笔账:• 效率提升:文档处理时长从“数人天”级缩减至“分钟”级。• 质量保障:彻底消除因人工操作导致的格式错误和漏项。• 人才释放:让核心工程师将时间投入到更符合其岗位价值的分析与决策中,而不是低价值的“搬运”工作上。“当‘重复劳动’被工具取代,‘时间’就被真正地‘还给了’思考者。”如果您的团队也正在为“PDF文档条目化耗时、需求条目化效率低”等问题而烦恼,欢迎扫描下方二维码添加专属顾问,进一步了解本方案如何适配您企业的具体业务场景,或安排专题演示。
添加后,您可以一站式获取:
• 《高远PDF智能解析应用手册》 —— 用于团队内部评估参考
• 免费体验账号(5个名额,有效期1周) —— 提供试用同事的姓名与手机号,即可开通权限
 夜雨聆风
夜雨聆风