 夜雨聆风
夜雨聆风想搭建一个财报分析助手、公司研究助手的AI应用?或者想做一个自己的 RAG 财报知识库?相信你都会遇到这个问题:先把年报、审计报告pdf里的财务数据读出来。
财报解析最容易卡住的第一步——把表格数据拿出来
一份年报少则几十页,多则上百页,里面的财务数据通常分散在不同章节和表格中。
做财报分析时,最先需要处理的内容都很具体:资产负债表、利润表、现金流量表,合并口径和母公司口径,分行业、分产品、分地区收入数据,附注里的明细表。
这些数据散落在正文、附注和跨页表格里。只拿到一段年报全文,后续很难稳定计算指标、导出表格、做问答分析,或者回到原文核对关键数字。
财报 PDF 的难点也集中在这里。一份年报里会同时出现:
三大表 合并报表和母公司报表 跨页表格 多层表头和合并单元格 扫描页、印章、水印 附注和正文交叉引用 页眉、页脚、脚注 需要回到原文核对的关键数字
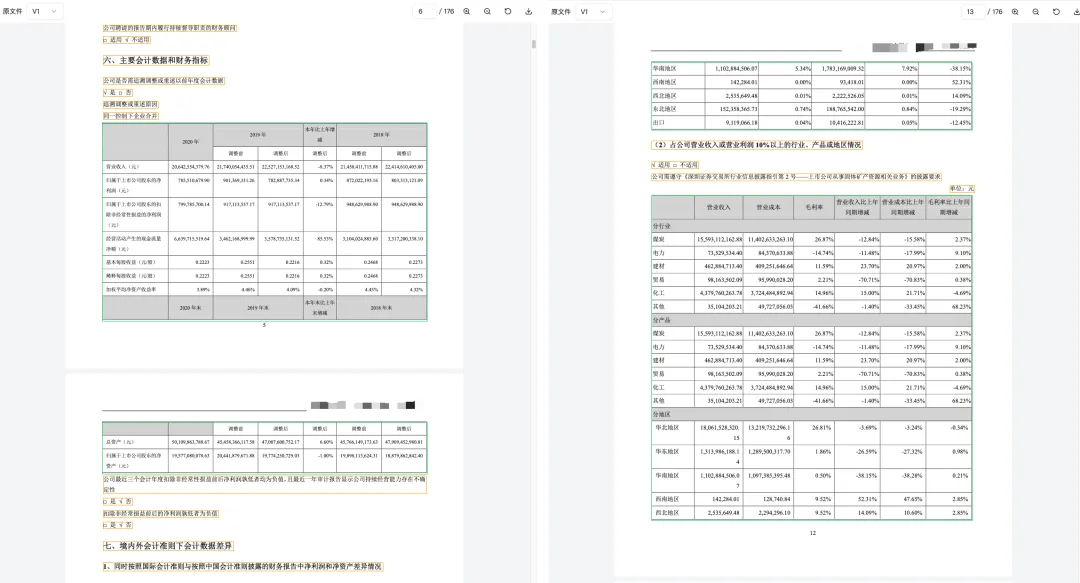
只要解析层有一个环节没处理好,后面的财务摘要、指标计算、问答检索都会受到影响。
比如你想问 AI:“这家公司经营现金流为什么变化?”
如果现金流量表没有被稳定定位,表格结构没有保留,关键数字没法回到原文,这个问题就很难可靠回答。
为什么要用工程化解析
财报解析的难点,远不止识别文字。
真实 PDF 里有表格、图片、公式、页眉页脚、脚注、跨页内容、扫描页、坐标位置和版面层级。它们共同决定了一份财报能不能被后续系统继续使用。
如果只拿到一段纯文本,那就丢失了很多关键信息:表格边界没了,数据来源没了,章节关系没了,原文位置也没了。后面再做总结、问答、抽取、校验,都会变得不稳定。
PDF2X 的工程化解析,核心在前面的判断和重建:
原生文本怎么保留,扫描页什么时候走 OCR,标题和段落怎么分层,表格边界怎么识别,跨行跨列怎么还原,公式和图片怎么处理,页眉页脚怎么剥离,最终每个对象怎么带着坐标回到原文。
Markdown 和 JSON 是输出结果,前面那套结构恢复流程才是核心。
PDF2X 怎么处理
PDF2X 先解析文档结构,再交给下游使用。
一份 PDF 经过处理后,会输出:
document.pdf.out/├── doc.md # 完整 Markdown├── doc.json # 结构化 JSON,含页面对象和坐标├── pages/ # 逐页结果└── images/ # 提取出的图片区域解析结果里,表格、文本块、图片、公式等对象都有自己的结构。JSON 中保留 bbox 坐标,可以回到原文位置。
这意味着后续可以继续做:
定位资产负债表、利润表、现金流量表 提取表格为结构化数据 按页码或坐标回溯原文 导出给 Excel、数据库或业务系统 接入 RAG / Agent 做问答和分析
财报解析的价值从这里开始:先拿到可用数据,再谈分析。
解析实例展示
这里以一份真实的年报解析展示下实际解析效果。
不能只看 AI 最后能不能生成摘要,更值得看的地方是解析过程本身:
原始 PDF 里,表格是否和正文、页眉页脚、附注混在一起 解析后,表格有没有进入 Markdown JSON 里是否保留了页面对象和位置信息 关键数据能不能回到原文位置 后续能不能继续导出、检索、切分或接入分析流程
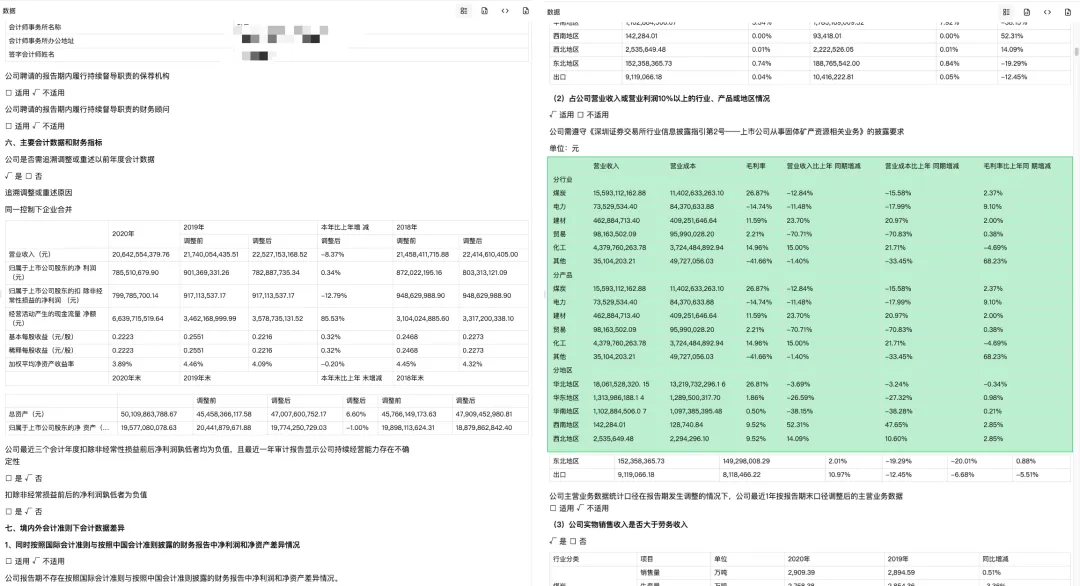
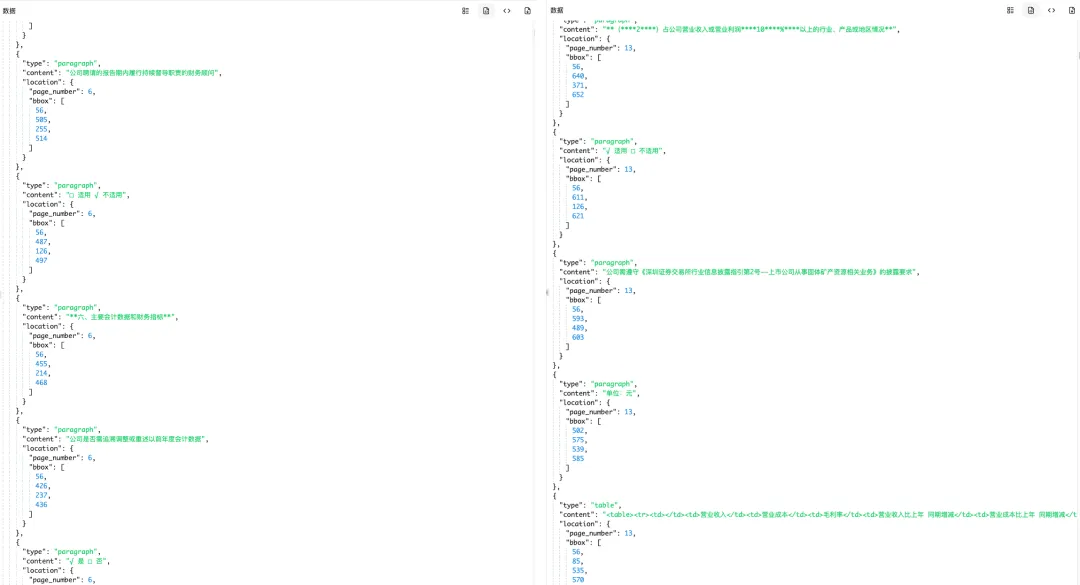
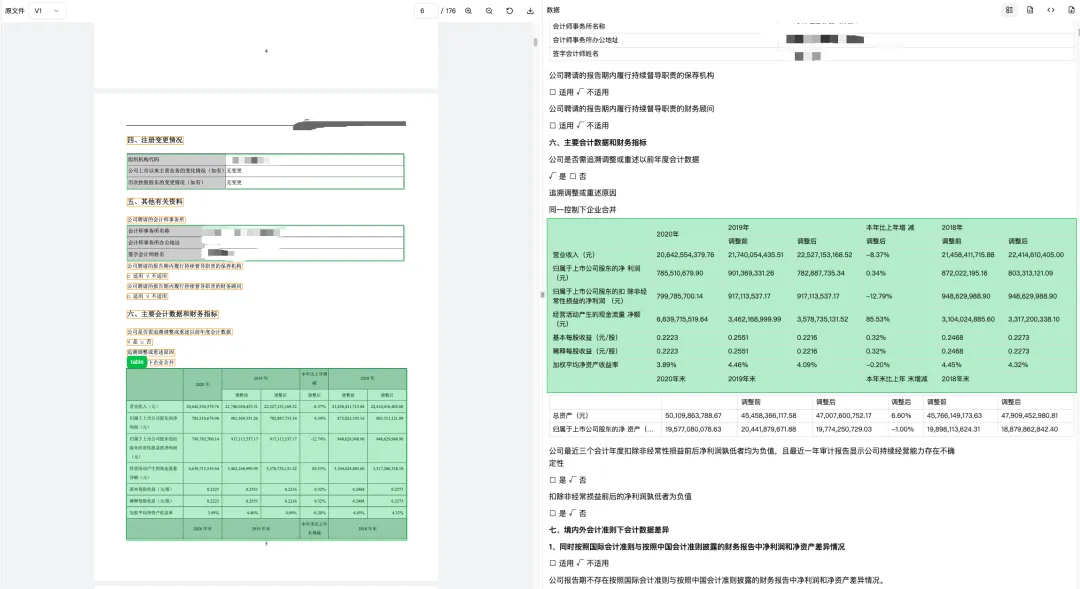
这才是财报解析真正有价值的地方:先把文档拆成能被程序继续使用、也能被人工复核的数据。
财报分析需要稳定数据入口
财报分析最终看的是判断。
但判断之前,先要有稳定的数据入口。
PDF2X 想解决的就是这个入口问题:先把复杂年报里的表格、段落、页码和位置变成可读、可查、可复核、可继续处理的数据。
这样,后面的财务指标计算、问答分析、人工核对和系统集成,才有稳定输入。
快速上手
如果你手里有难处理的财报、年报、审计报告或募集说明书,可以直接来试试。输出的 Markdown 和 JSON 可以直接接入自己的财报分析、知识库或自动化流程。
官网指路: https://pdf2x.cn/官方小程序: #小程序://PDF2x/waAWgEs6HaVuvHt开源版本:https://github.com/memect/memect-ppx命令行版本:px parse report.pdf -o output/
感兴趣参加项目共创及提交错误报告等的开发者,建议优先选择开源版本和命令行版本。
使用过程中有问题,欢迎进群交流~
若无法进群,请添加小助手wx协助入群:black156983/Grace_Guoxh



