 夜雨聆风
夜雨聆风验收会上,大屏上的数字让所有人松了口气——缺陷检出率97.3%,过杀率控制在5%以内,质检主管当场签了验收单。三个月后,产线上多了两个人,专门复核AI的每一条判定。主管私下说了一句话:「机器判的我不敢信,还得人盯着。」
这不是段子。过去三年我们在鞋服、陶瓷、食品行业跑了不下二十个AI质检项目,几乎每个都经历了同样的轨迹——上线前两周效果惊艳,第三个月开始吃灰,半年后产线工人关掉AI界面直接肉眼检。
问题出在哪。
工业AI质检已过「能不能用」的技术验证阶段,当前的核心矛盾是数据基础设施缺失导致价值无法规模兑现——92%的失败项目根因在数据工程而非算法精度,跳过数据治理谈模型优化,是本末倒置。
一、技术不背这个锅
先看一组数据。IDC 2025年发布的中国制造业AI应用调研覆盖了187家已部署AI质检的企业,结论非常扎眼:92%的项目在第一年未能达到验收时的KPI,其中78%的绩效衰减发生在部署后的第3到6个月。Gartner同期发布的工业AI成熟度报告更直接——工业AI项目中,数据采集、清洗、标注和管道维护消耗了项目总精力的71%,算法训练只占14%。
算法本身够用了。以表面缺陷检测为例,ResNet、YOLO系列的成熟模型在标准数据集上早就跑到99%以上。去年我们在某鞋厂做鞋面瑕疵检测,实验室环境下的模型准确率是98.7%,上线第一周实测也有96%——听起来不错。但到第三个月,准确率跌到了81%。
不是模型变差了。是产线变了。
那家鞋厂的车间没有恒温恒湿,夏天湿度一上来,鞋面反光度就变了,去年训练的那批图像跟现在产线上的实际画面完全是两个世界的亮度。产线上换了一批新光源之后,AI开始把正常的纹理反光判为划痕。设备科的人不知道AI的输入对这个敏感,IT的人不知道设备科换了灯,算法工程师坐在杭州远程调试,连灯换了都不知道。
这就是数据漂移。它不是算法问题,它是工程问题。
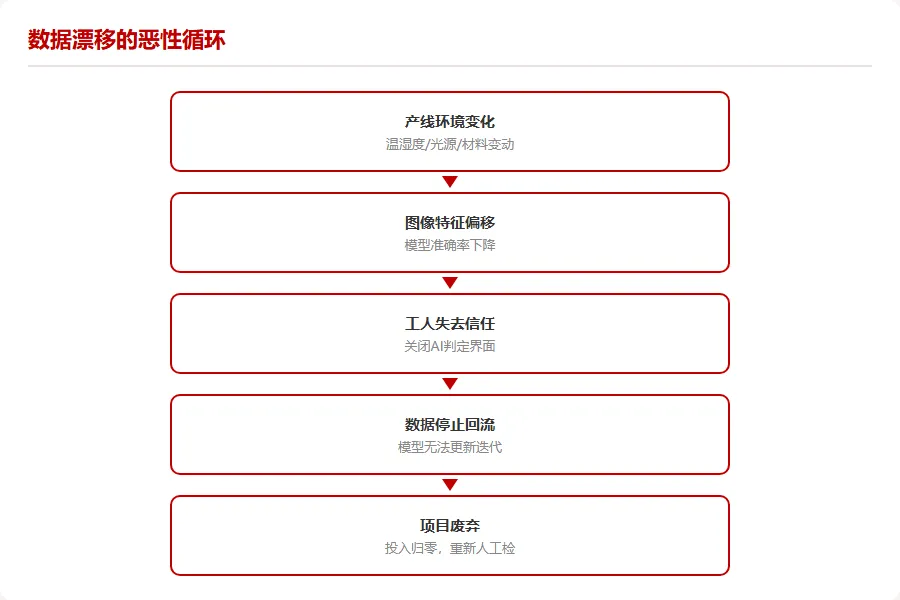 数据漂移循环
数据漂移循环
二、标注,被严重低估的工程
如果说数据漂移是慢性病,那缺陷标注就是质检AI落地最隐蔽的深坑。
制造业的缺陷标注和互联网的猫狗分类完全是两码事。猫就是猫,狗就是狗,歧义空间很小。但工业缺陷呢——一道划痕多深算缺陷、多浅可以放行?同一块鞋面,质检班长判「轻微划痕可放行」,质检员小王判「不合格」,质检员老李说「擦一下就好了不用记」。三个人三种标准,这是产线上的日常。
我们曾经为了统一鞋面缺陷的标注标准,在一个工厂待了两周。把质检员叫到一起,拿了50块典型样品,每个人独立判定,比对差异,逐块讨论分歧点,最后形成了一套7大类42子类的缺陷判定手册。光这本手册就写了40页。之后标注效率才从每天标60张提到200张,一致性从不到70%拉到92%。
但这件事哪个AI公司会写进方案里?方案里写的永远是「提供定制化标注服务,7天交付」,不会告诉你7天标出来的数据根本没法用。
更麻烦的是,缺陷的定义本身就随客户、随季节、随订单在变。出口欧美的订单比国内订单的允收标准严一个等级,运动鞋比休闲鞋的鞋面光洁度要求高一截。标注标准不是一劳永逸的,它是一个持续博弈和修正的过程。这不是技术问题,这是制造know-how的工程化。
 标注标准差异
标注标准差异
三、你以为买了AI,其实买了一套数据工程体系
很多工厂老板对AI质检的认知还停在「买一套设备,接上电,就能替掉三个人」的阶段。实际情况是,买AI质检设备只完成了整个项目20%的工作量。
剩下的80%是什么。光源选型和安装角度调试,不同材质不同颜色产品的成像参数适配,产线抖动和传输带速度对图像质量的补偿算法,缺陷样本的持续采集和标注管道维护,与MES系统的不良品数据打通,质检员对AI判定逻辑的信任建立和协作流程磨合,新品类上线时的模型再训练和部署流程。
这还没算组织层面的问题。AI质检项目的落地往往跨三个部门——IT管系统和算法,设备科管硬件和产线,品质部管判定标准和最终责任。IT说模型准确率达标了,设备科说生产线不能随便停,品质部说你们的数据我看不懂。三方博弈的结果是AI判定成了「仅供参考」,品质部自己另做一套手工报表,AI系统的数据链路实际上被绕过了。
这才是真实的AI落地,不是Demo房里跑出来的准确率曲线。
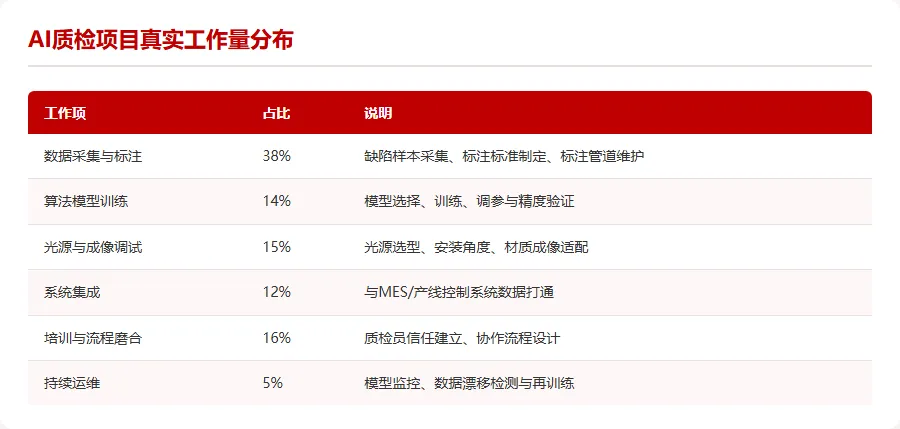 工作量分布
工作量分布
四、从「能不能用」到「能不能规模化」
一个车间、一条产线、一个品类做AI质检,咬咬牙能搞定。但当你把同一个方案复制到第二个车间时,问题就来了。
第二个车间生产的是另一种材质的产品,相机得换,光源角度得重新调,去年的标注标准至少30%要修订。第三个车间的产线速度快了30%,图像采集帧率跟不上,要么降速影响产能,要么加速牺牲精度。等你做到第五个车间,你会发现最初的技术架构根本撑不住这么多变体的管理——标注标准已经分裂成十几个版本,每个车型的模型参数独立维护,产线一调整就得重新标一遍数据。
这就是规模化困境。AI质检从单点实验到全面推广,中间隔的不是技术鸿沟,是一整套数据工程的工业化能力。
标杆企业已经给出了方向。德国的一家汽车零部件厂商把缺陷标注做成了一套「标注语言」——不是简单的Defect/No-Defect二元分类,而是一种能描述缺陷位置、形态、严重程度、根因指向的结构化描述体系。这套语言贯穿了从采集到标注到模型训练到产线反馈的全链路,不随产品换、车间换而需要重新定义。他们的标注标准更新效率比同行快4倍,新品类上线周期从6周缩到10天。
这不是什么黑科技,就是把标注这件事从「手艺活」变成了「工程活」。
 标注体系对比
标注体系对比
五、现在该做什么
第一,停止追模型精度。从98.7%提到99.1%,产线上没有感知。把精力放到三件事上:数据采集的标准化、标注标准的工程化、模型漂移的自动化监测。
第二,把数据链路当成生产系统来管。产线设备的数据采集不是IT项目,是制造工程。光源参数、相机设置、环境温湿度,这些变量如果不记录、不监控、不与模型性能做关联分析,你的AI系统就是一个黑箱,等着在某个深夜悄悄失效。
第三,接受渐进式投入。AI质检不是一次性采购项目,它是持续运营系统。每年至少要留出初始投入的20-30%做数据维护、模型迭代和产线适配。把这个写进预算,别等项目黄了再追投。
我们跑过的项目中,活过两年还有效的,没有一个是因为算法好。全都是因为有人在持续管数据。
参考文献
[1] IDC.《中国制造业AI应用市场调研报告》. 2025.
[2] Gartner.《Industrial AI Maturity Report》. 2025.
[3] 中国信息通信研究院.《工业智能白皮书》. 2024.
你在的工厂或者项目里,AI质检上线后最让你意外的问题是什么?是技术问题还是数据问题,还是有别的坑?欢迎评论区讨论。
