 夜雨聆风
夜雨聆风 用过 AI Agent 的人应该都有种熟悉的无语:每次开新会话,它都像第一次见面一样——你是谁、你喜欢什么、之前聊过什么,一概不知。
用过 AI Agent 的人应该都有种熟悉的无语:每次开新会话,它都像第一次见面一样——你是谁、你喜欢什么、之前聊过什么,一概不知。
你每开一次新对话,就得把所有背景信息重新喂一遍。
这不是你用得不对,是这个领域的一个结构性问题。
直到最近,腾讯云数据库团队开源的 TencentDB Agent Memory,第一次让这个问题看到了一些真正的解法。项目上线两个月,Star 数已经冲到 4600+。
先说说问题到底出在哪。
现在的 AI Agent 本质上是一个无状态的对话引擎。每次新会话默认白板一张,你之前跟它建立的所有交互历史、偏好、约定,全都不存在。
这就带来一个尴尬的局面:用 AI 干活的时间越长,你需要花在"喂上下文"这件事上的精力反而更多。
业界不是没想办法。目前主流方案有三条路,但每条都有硬伤:
硬塞上下文窗口是最暴力的方式——把所有历史对话拼到一起丢进去。但上下文窗口不是无限大,token 总有爆炸的一天。
上向量数据库做记忆,说白了就是存检索对。听起来合理,问题是只存不提炼。一段对话的所有细节照单全收,但关键信息和非关键噪音掺在一起,召回精度上不去。
让大模型自己做摘要,好处是压缩了体积,坏处是一旦压缩错了,细节就永远丢了。压缩本身就是有损操作,这在需要精确回忆的业务场景里是致命的。
所以这个问题的核心矛盾是:既要记住足够多的细节,又不能把上下文塞得太满拖慢推理。这个矛盾,正是 TencentDB Agent Memory 想要解决的根本命题。
02 四层记忆:不是存数据,是建档案
我仔细看了这套方案的设计,最打动我的是它的分层渐进思路。
项目把记忆分为四个层级,从底到顶,每层的抽象程度越来越高,但始终有一条完整的"证据链路"保证可回溯。
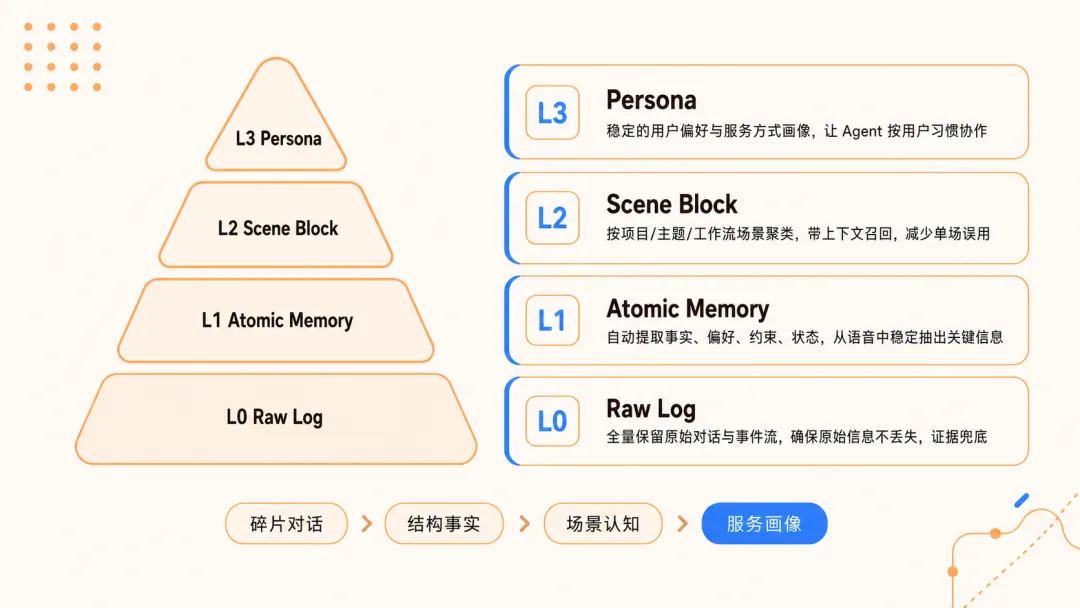 最底层的 L0 是原始对话。全部保留,一字不落。这层像你的原始硬盘备份,不做任何加工,就是纯存储,关键时候可以回查任何一句原话。
最底层的 L0 是原始对话。全部保留,一字不落。这层像你的原始硬盘备份,不做任何加工,就是纯存储,关键时候可以回查任何一句原话。
L1 是原子事实层。系统自动从对话里提取最细粒度的独立事实节点。比如你说"我用的是 NextJS",它就记下了"用户使用 NextJS"这个原子事实。你说"最近迷上了火锅",它就记下"用户喜欢吃火锅"。每个事实都带上标签和来源。
L2 是场景聚类层。这一层做的事情类似于整理相册——把相关的原子事实按主题场景打包。比如你在讨论一个后端架构时提到的表结构、接口风格、权限设计,会被自动归类到一个 Markdown 格式的场景块里,你可以直接读,甚至直接用。
L3 是用户画像层。基于下面三层的积累,沉淀出一个结构化的用户画像:你的编程习惯、技术栈偏好、项目文档风格、甚至常用的工具链偏好。这些都是推理出来的,不需要你主动填写任何表单。
这套架构最妙的设计在于:每一层的结论都能自证出处。L3 说你偏好 TypeScript,这个结论可以一路回溯到 L2 的某个场景块,场景块里的每条判断又可以查到 L1 的原始事实,事实最终可以追到 L0 的原始对话。整条证据链完整可查。
不是黑盒,不是猜的,每一个结论都有来历。
03 短期记忆的巧思:用图代替文字
长记忆解决了,但短期上下文管理其实才是烧钱的大头。
我个做过 Agent 开发的人都知道,Agent 一次复杂任务的工具调用链,能产生几十轮对话和大量日志。把这些全部塞进上下文窗口,不仅 token 烧得快,大模型在大量噪音中反而更难准确推理。
TencentDB Agent Memory 的解法值得单独拿出来讲讲。它把符号化的思路用到了记忆上。
具体做法是:完整日志不塞进上下文,而是卸载到外部文件里。上下文里只放一张用 Mermaid 语法画成的任务状态图。这张图很轻,几行语法就能包含状态、依赖关系、进度、关键节点。需要更多细节时再通过节点 ID 去外部文件里检索。
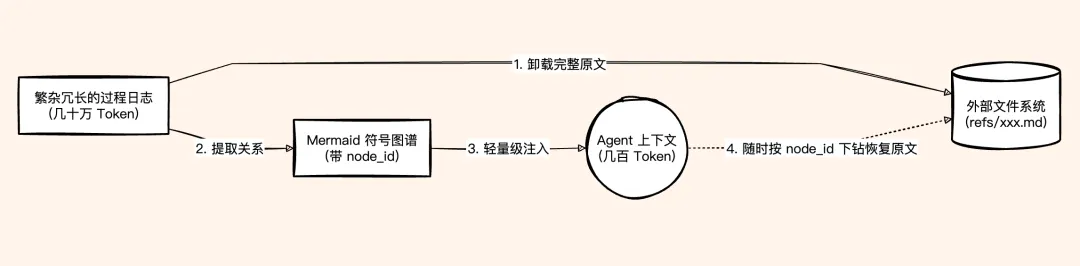 这个思路的好处是信息密度极高。一张 Mermaid 图占的 token 远远少于同等信息量的文本摘要。而且它不是线性文字,是带拓扑结构的图,大模型可以从图的连接关系里做推理,而不是死记硬背标签。
这个思路的好处是信息密度极高。一张 Mermaid 图占的 token 远远少于同等信息量的文本摘要。而且它不是线性文字,是带拓扑结构的图,大模型可以从图的连接关系里做推理,而不是死记硬背标签。
实测数据也验证了这个方向:Token 消耗直接降了 50%,但任务完成率反而提高了 23%。省钱的同时活还干得更好了。
在语义检索层面,系统同时跑了 Embedding(语义匹配)和 BM25(关键词精确匹配)两路检索,然后用 RRF 做融合排序。两路互补,覆盖了"模糊找"和"精确找"两种场景。
04 效果怎么样?看数据说话
说再多架构设计,不如直接看跑出来的结果。
腾讯在 PersonaMem 基准测试上做了对比评测——同一套 Agent 任务,对比原生的 OpenClaw 和接入 Agent Memory 之后的 OpenClaw:

最有冲击力的是用户事实召回这一项。从 29.63% 到 79.07%,将近 167% 的提升。翻译成人话:你跟 AI 说过十件事,之前它只能想起来三件,现在能想起来八件。
在编程类任务上同样有明显的提升:
• WideSearch(搜索整合验证能力):成功率从 33% 提升到 50%,Token 节省 61% • SWE-bench(软件工程问题解决):通过率从 58.4% 提升到 64.2%,Token 节省 33%
数据说明一个道理:记忆不是成本,记忆是杠杆。记住更多之后,Agent 不仅干得更准,还因为不需要反复"更新上下文",反而省了大量 Token。
05 上手体验:一分钱不花也能用
这个项目目前以 OpenClaw 插件的形式发布。
如果你已经在用 OpenClaw,一行命令就能装好:
openclaw plugins install @tencentdb-agent-memory/memory-tencentdb装完默认使用本地 SQLite + sqlite-vec 做存储后端。不需要单独装数据库,不依赖外部服务,数据全在本地。零配置开机即用。
如果你用的是 Hermes Agent 框架,项目也提供了 Docker 一体化镜像——Hermes 本体、Memory 插件、Gateway 全打包在一个容器里,docker pull 下来就能跑。
如果你感兴趣自己开发适配层,新的 1.0.0-beta.1 版本也给了快速上手的入口。
06 不只是记忆:腾讯云数据库的 AI 布局
TencentDB Agent Memory 不是腾讯云单独搞的一个小工具。它是 5 月 29 日腾讯云「数据库+AI」战略发布会的一部分。
这次发布会传递了一个明确的信号:当 AI Agent 成为新的生产力单元,数据库的使命正在从"存数据"变成"支撑智能体的感知、记忆、决策与协作"。
配合 Agent Memory 一起亮相的还有几个重要产品:
DatabaseClaw——腾讯云首个数据库 Agent。不是那种回答问题的 AI 助手,而是真的能进入生产环境干活:7×24 小时自动巡检、异常诊断、慢 SQL 归因。并构建了四层安全防线,让 DBA 愿意把生产权限交出去。
TDSQL Boundless——新一代分布式数据库。在同一套架构上支持关系型事务、向量检索、全文搜索,不需要为不同数据类型维护不同的数据库。
TDSQL-C 升级版——第三代存储架构主打三个字:稳、灾、省。IO 零抖动,数据三 AZ 强同步 RPO=0,TCO 下降 200%+。
放在一起看,腾讯云在做的是一整套 Agent 时代的数据基础设施。而 Agent Memory 是这其中离开发者最近的一环——它直接解决了每个 AI 开发者都会撞上的痛点:AI 记不住人。
如果你也在做 Agent 开发,或者正在被"AI 失忆"的问题困扰,这个开源项目值得关注。
项目地址:https://github.com/TencentCloud/TencentDB-Agent-Memory
#AgentMemory #腾讯开源 #AIAgent #大模型 #开源项目
