 夜雨聆风
夜雨聆风过去SRE聚焦服务、代码、机器的稳定性,而AI时代,运维保障的边界被彻底拓宽。模型推理、数据流转、Agent决策的每一个环节,都成了稳定性的关键命脉。SRE的下一站,早已不是单纯保障“服务不宕机”,而是迈入AI-in-SRE、Agent工程化治理的全新阶段。

为什么传统SRE,撑不住AI业务
很多团队发现,沿用传统运维思路做AI业务保障,永远治标不治本。本质原因是:AI系统的稳定性,不是传统运维的小幅升级,是全方位的底层重构。
传统运维的保障对象很清晰,无非是服务、代码、配置、服务器,核心围绕发布、容量、容灾、依赖做保障,出问题后靠扩容、回滚、熔断、切流就能快速止损。
AI系统的保障维度复杂得多,除了基础服务,还要覆盖模型、推理链路、数据链路、Agent决策链。Prompt设计、工具调用、工作流、权限配置、模型行为,每一个变量都会影响系统稳定性。对应的故障处置逻辑也彻底改变。AI故障没有简单的“一键恢复”方案,需要结合降级限流、策略切换、人工接管、受控执行等多种方式组合处置。
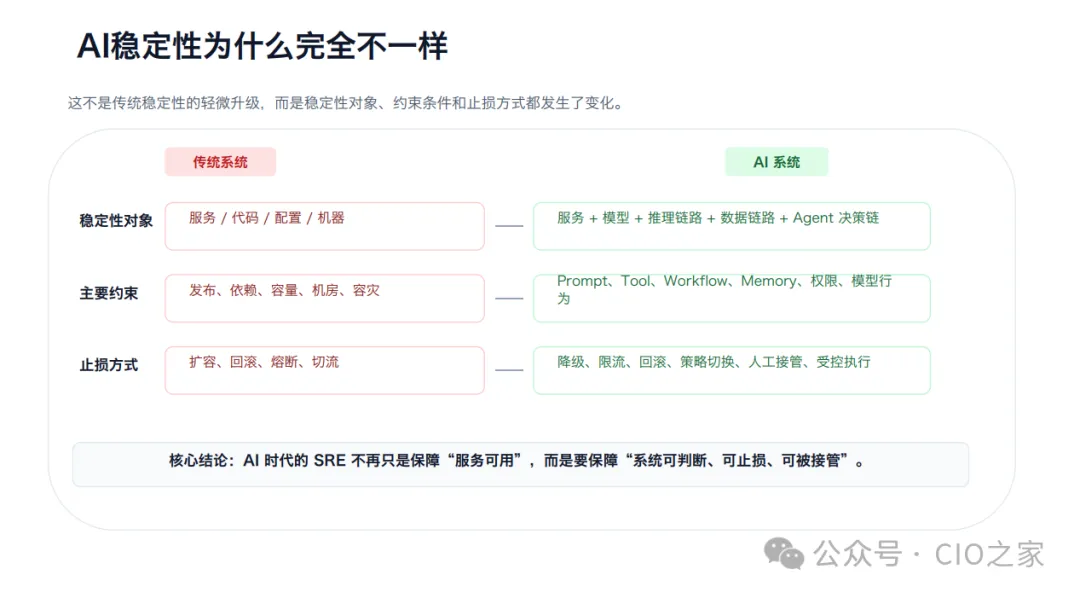
新时代SRE不再只追求服务高可用,而是保障整个AI系统可判断、可止损、可被人工接管。更关键的是,当下的SRE面对的是双重AI系统,这也是传统运维从未遇到的场景:
一类是被保障的业务AI系统,比如搜索、推荐、广告、智能问答等核心业务模型,直接决定业务体验、营收和算力成本,风险集中在数据漂移、模型异常、成本失控、链路抖动。
另一类是参与运维保障的AI Agent,包括告警分析、巡检、容量评估、故障诊断、复盘Agent,它们主动参与运维判断、给出优化建议甚至执行操作,核心风险是AI幻觉、判断失误、越权操作、策略失稳。
SRE的工作边界彻底升级:从单纯保障业务系统稳定,变成同时保障业务系统+AI运维决策、执行链路的双重稳定。
AI-in-SRE闭环:让运维从人工救火变主动自愈
面对全新的运维场景,靠人工盯屏、被动救火的模式彻底过时,这也是AI-in-SRE闭环体系存在的核心意义——把AI深度嵌入运维全流程,打造全链路自动化稳定性闭环。整套闭环体系覆盖事前、事中、事后全场景,彻底改写传统运维的工作模式: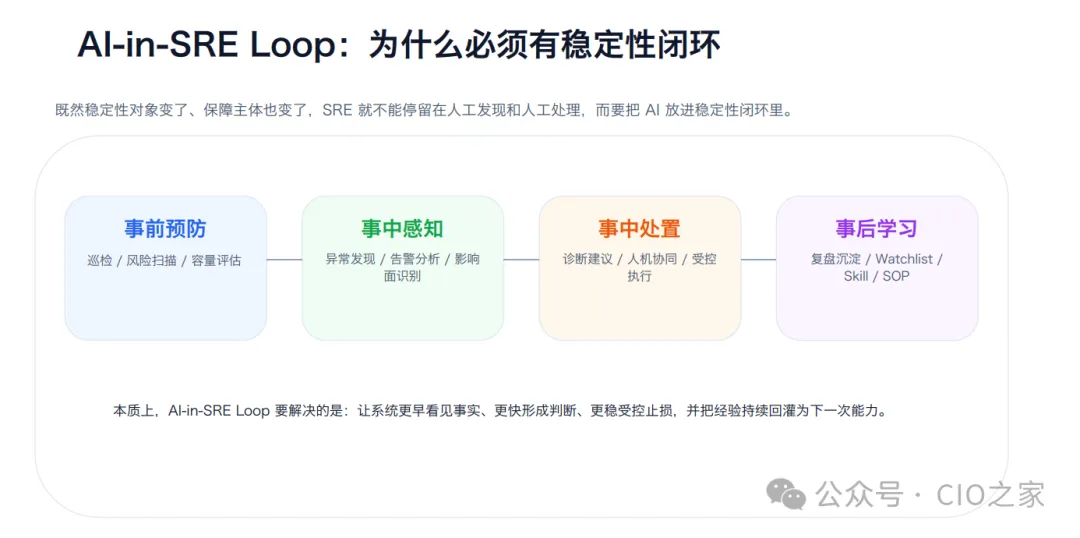
事前预防:通过AI自动完成常态化巡检、风险扫描、容量评估,提前挖掘潜在隐患,把故障扼杀在萌芽阶段;
事中感知:AI实时监测系统波动,快速发现异常、智能分析告警、精准定位故障影响范围,告别人工逐条排查;
事中处置:依托AI给出精准诊断建议,通过人机协同模式处置故障,高危操作全程受控,兼顾效率与安全;
事后学习:自动沉淀故障案例、优化SOP流程、更新风险监控清单,把单次处置经验,转化为团队可复用的运维能力。
让系统更早发现问题、更快做出判断、更稳完成止损,并用持续学习形成能力迭代的正向飞轮。
可控,是AI运维的底线
很多团队落地AI运维踩的最大坑,就是盲目追求Agent的自由度和智能化,放任AI自主操作生产环境。但生产运维的核心诉求从来不是“AI更聪明”,而是AI更可控。没有约束的智能,只会带来无穷的生产风险。这需要引入Harness工程护栏体系,核心逻辑很清晰:把创造性留给AI的判断层,把绝对确定性锁死在执行层。

整套护栏从四大维度实现全约束,彻底杜绝AI运维风险:
约束输入:限定AI的问题处理模板、信息来源和证据范围,避免无效、错误的输入信息导致误判;
约束推理:将AI开放式的自由推理,收敛为标准化检查清单、决策树和固定工作流,保证判断逻辑统一、规范;
约束执行:所有运维操作必须经过工具校验、权限审核、流程审批、操作审计和回滚备案,无权限、无备案操作一律禁止;
约束反馈:所有运维结果自动沉淀为报告、案例、规则和知识库,为后续迭代优化提供依据。
同时落地分级受控执行路径:从纯只读建议、人工确认执行,到有限自动化操作、自动回滚兜底,全程遵循先增强人、再自动化,先收边界、再放权限的铁律。
在这套体系下,运维工程师的角色也彻底转变:从日复一日的故障执行者,变成运维环境的设计者、规则的制定者、能力的治理者。只需定义工作意图、验收标准和边界条件,AI就能在护栏内完成绝大多数常态化运维工作。
落地优先级:3个高价值场景,快速落地见效
AI SRE落地切忌贪大求全,不用一开始就搭建万能平台、堆砌多Agent体系。最优思路是聚焦高频、高损耗、可落地、可沉淀的场景,先跑通单场景闭环,再规模化拓展。

结合一线落地经验,三类场景性价比最高、最适合优先落地:
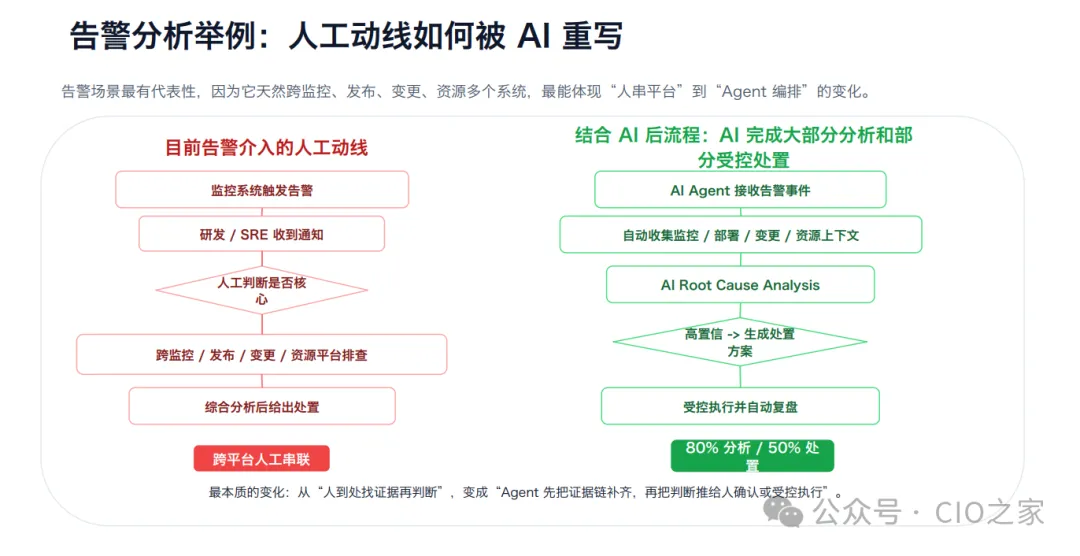
告警分析与降噪 告警是运维最高频的工作,传统模式需要人工跨监控、日志、变更、发布多平台串联排查,流程繁琐、耗时久、效率低。
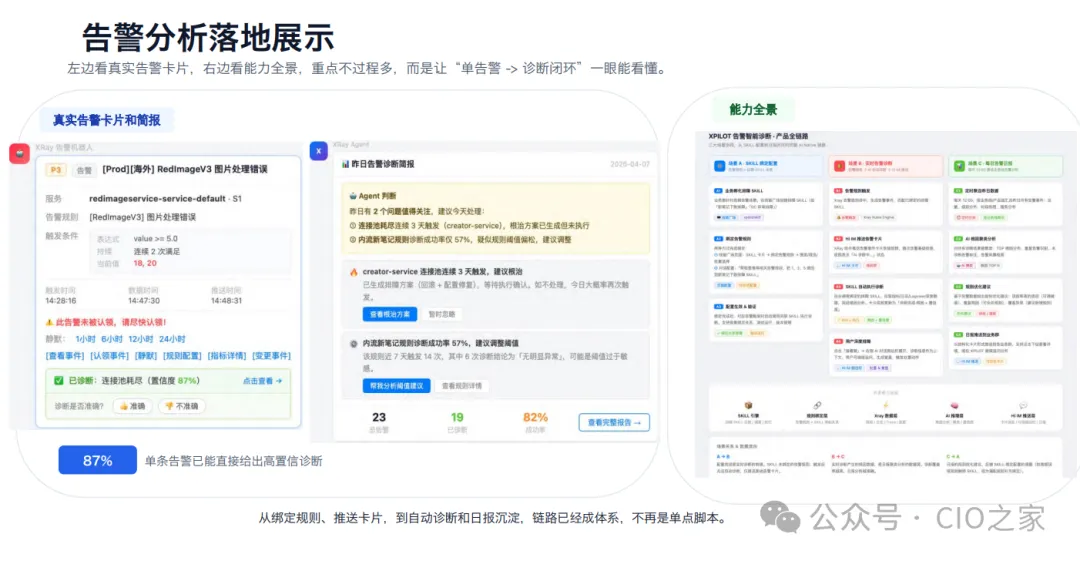
接入AI后,可自动完成上下文收集、全维度证据链补齐、根因智能判断,实现80%问题自动化分析、50%常规问题受控处置。从“人工到处找证据、拼线索”,变成“Agent先完成分析研判,将结构化结论和处置方案推给人工确认”,极大缩短故障响应时间。
推荐效果智能诊断 业务效果波动是直接影响营收的核心问题,传统模式高度依赖资深SRE经验,排查耗时可达小时级,新人很难独立处置,且容易出现误判。通过AI沉淀专家经验,搭建风险监控清单和标准化证据链校验体系,可实现十分钟级故障定位。
比如新笔记推荐占比异常下跌故障,AI可自动关联实验变更、召回渠道、配额配置等全维度数据,精准定位根因是实验变更导致召回渠道暴跌,同时输出明确的排查和修复建议,全程有据可依、结论可追溯。
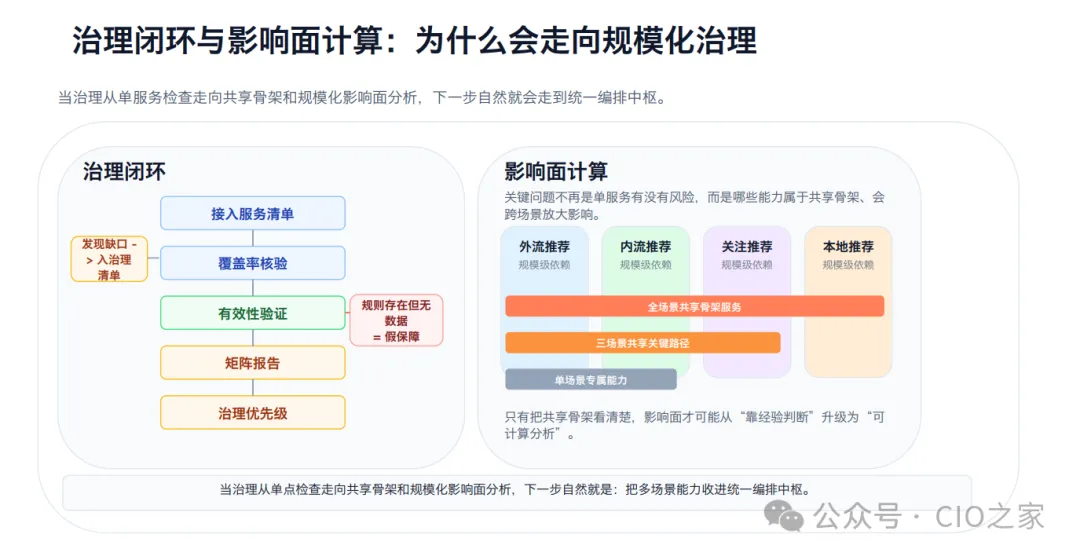
全域巡检治理 传统巡检依赖人工逐项核查,覆盖率低、漏洞多、优先级模糊,很多潜在风险无法提前发现。AI巡检可实现全场景自动化核验,生成标准化风险矩阵报告,自动区分风险优先级,精准识别架构隐患、容量瓶颈、容灾缺陷等各类问题。结合业务共享骨架,完成规模化影响面计算,告别“单点排查、凭经验判断”的传统模式,让风险治理从“被动找问题”升级为“主动推闭环”。

AI SRE的规模化落地逻辑
很多团队的AI运维落地最终沦为Demo,核心问题是只做表面智能化,缺失治理、评估和迭代体系。真正的生产级AI SRE,必须靠标准化体系和清晰的演进路径支撑。
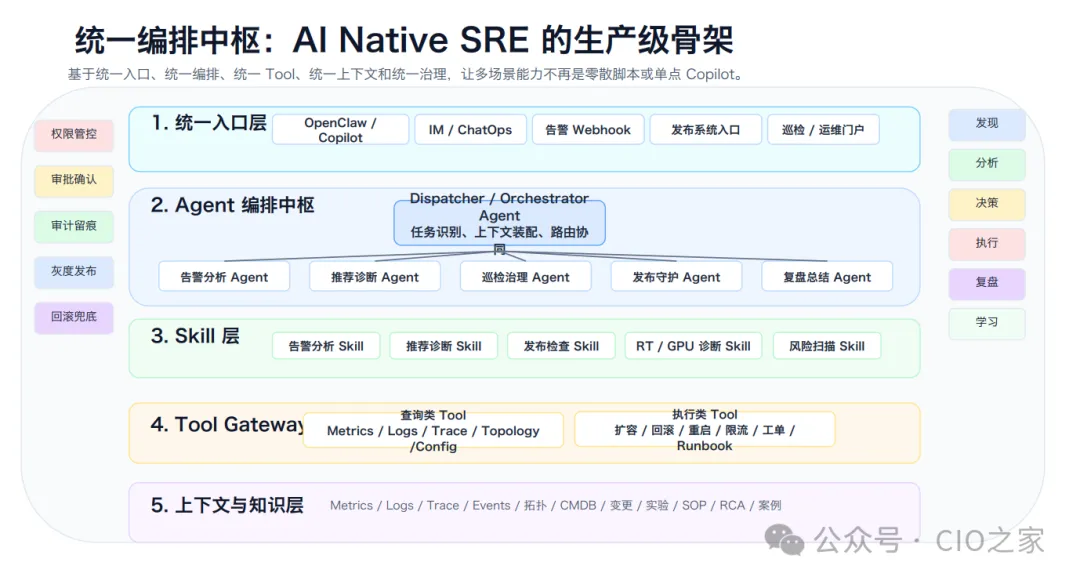
统一编排中枢:告别零散能力 多数团队初期的AI运维能力都是零散的单点工具,监控、日志、变更、治理流程相互割裂,无法形成合力。
统一编排中枢是AI Native SRE的核心骨架,通过统一入口、Agent编排、技能沉淀、工具网关、知识上下文五层架构,解决四大核心割裂问题:
打通监控、日志、拓扑、变更等各类数据,解决上下文割裂;
沉淀标准化工作流,统一同类问题处置逻辑,解决流程割裂;
集中管理审批、灰度、回滚、审计权限,解决治理割裂;
自动沉淀故障案例与运维经验,解决知识割裂。
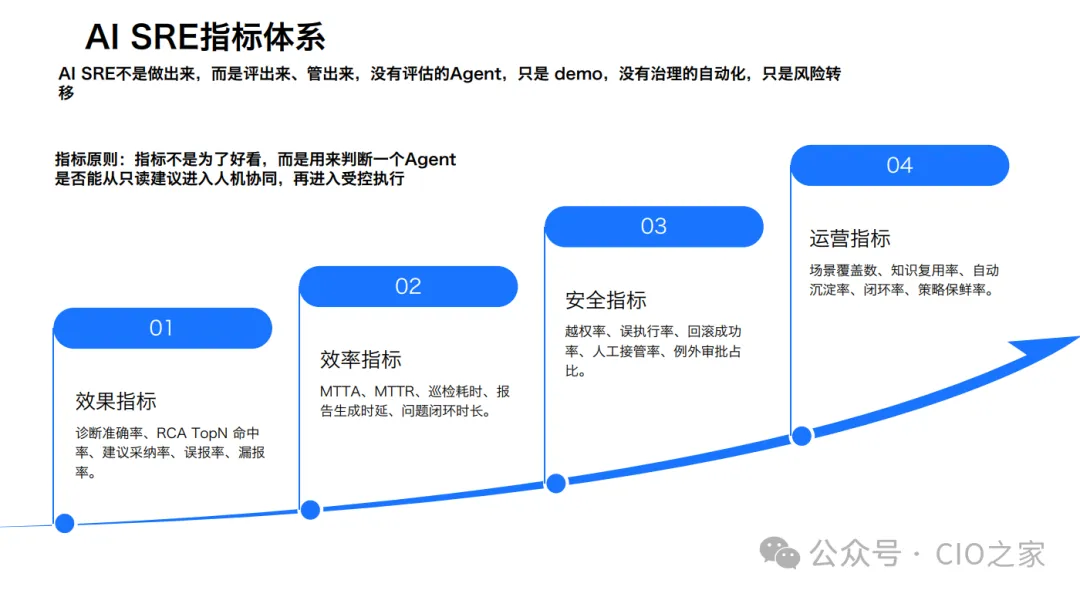
让AI运维可量化、可管控: 没有评估的AI Agent只是无效Demo,没有治理的自动化只是风险转移。一套完善的指标体系,是规模化落地的核心保障,主要包含四大维度:
效率指标:聚焦故障发现、处置、闭环全流程耗时,持续优化运维效率;
效果指标:考核诊断准确率、根因命中率、建议采纳率、误漏报率,保障AI判断质量;
安全指标:严控Agent越权率、误执行率、人工接管率,守住生产安全底线;
运营指标:统计场景覆盖率、知识复用率、经验自动沉淀率,实现能力持续迭代。

AI运维自动化绝非一步到位,稳妥的落地路径分为五个阶段,循序渐进、风险可控:
第一步看见事实:打通全链路观测数据,实现业务、资源、故障全景可观测;
第二步形成判断:沉淀标准化证据链,稳定输出精准诊断结论;
第三步人机协同:AI输出可行建议,人工审核确认,辅助运维提效;
第四步受控执行:低风险场景开放有限自动化操作,全程可回滚、可审计;
第五步持续学习:自动沉淀经验、迭代规则,形成运维能力正向飞轮。


避坑指南
复盘大量团队的落地经验,四个最容易踩的误区一定要避开:
急于堆砌多Agent体系,单场景闭环尚未跑通,就盲目做平台化、复杂化升级;
放任Agent自由操作生产环境,缺失权限、审计、回滚等防护机制,放大生产风险;
只关注演示效果,不做量化评估和常态化治理,导致能力无法落地生产;
只追求单次运维提效,不做经验沉淀和知识回灌,无法形成长期能力壁垒。
从传统服务SRE,走向AI-in-SRE,最终落地Agentic SRE。SRE的核心价值不再是被动处理故障、保障服务可用,而是搭建一套可控、可迭代、可自愈的AI运维体系。工作重心从“人肉救火”,彻底转向机制设计、策略治理、平台编排。未来的运维行业,不会被AI替代的,从来不是会处理故障的执行者,而是能沉淀经验、驯化AI、搭建体系,让AI成为稳定生产力的设计者。



