 夜雨聆风
夜雨聆风平时我们刷视频、看科普、听专家分享,总能听到高频词:高质量数据、劣质数据、数据挤压、数据迭代。很多人听得多、记不住,越听越觉得抽象,心里一直有个疑问:练AI到底靠数据数量,还是靠数据质量?这些五花八门的数据概念,到底该怎么通俗理解?
其实不用死记专业理论,也不用硬啃复杂算法。这段时间,我和几个朋友一起闲聊探讨的时候,发现了一个特别朴素、却特别通用的规律:AI数字世界、虚拟世界、元宇宙的底层逻辑,和我们真实的物理世界、自然世界、人类社会,本质是相通的,万事万物的底层原理本就高度相似。
今天我就忽发奇想,结合自己学的专业和工作场景,用大家都熟悉的大江大河、田间育种、社会治理这些生活实景,聊聊自己琢磨出来的一点思考。没有标准答案,只是真诚分享、互相探讨,大家看完也可以一起评判、一起补充新的想法。

一、一碗清水与大江大河:我们读懂数据数量与质量的专属逻辑
关于数据数量和质量谁更重要,行业里一直争论不休,各种说法五花八门,越看越让人迷糊。我们跳出专业框架,结合现实生活琢磨出了最接地气的解读,如用一碗清水、一片大江大河的对比,就能彻底讲透这个问题。
如果只是小小的一碗清水,它的容纳空间极小、容错率几乎为零。哪怕只是一点点杂质、一滴有害物质混入,整碗水都会彻底变质,完全失去原本的用处。对应到AI领域就是小众垂直模型,比如专门用于医疗诊断、农业检测、工业质检的专项AI。
这类AI没办法收集海量数据,可用的样本十分有限,完全没有容错空间。这时候,质量就是生命线,一丝错误、一点虚假数据,都会让AI学错知识、判错结果。所以这类模型训练,核心就是精挑细选、层层筛选,剔除所有劣质数据,用极致的质量弥补数据体量的不足。
但如果把视角切换到奔腾浩荡的大江大河,情况就完全不一样了。大江大河收纳百川、体量庞大,拥有极强的包容性和自我净化能力。同样一点微量杂质、有害物质汇入其中,根本无法撼动整体水质,会被海量干净的水体快速稀释、弱化,几乎不会造成任何影响。
这就是通用大AI模型的运行逻辑,它就像一片辽阔的数据大江大河,汇聚了全网海量的文字、画面、行业信息、生活数据,体量足够庞大、维度足够丰富。偶尔出现几条错误、片面、劣质的数据,根本左右不了整体的学习结果,会被亿万条优质数据对冲、覆盖、修正。
由此我们就能总结出专属的核心规律:小数据池拼精度、拼质量,大数据江河拼体量、拼包容。这不是书本上的刻板结论,而是我们结合自然实景,自己思考、推导出来的新认知。
当然我们也要理性看待,大数据的包容不代表可以放任不管。零星杂质不足为惧,但如果有人刻意批量投放劣质数据、恶意给数据江河“投毒”,日积月累也会造成局部污染,破坏整个数据生态。所以无论体量大小,守住数据质量底线,永远是AI良性发展的根基。
更有意思的是,这套逻辑和人类社会发展高度契合。我们国家超大的市场规模、海量的人口基数,就像AI的大江大河数据池,拥有超强的容错性、多样性和成长性,个别领域的短板和问题,总能被整体的发展势能慢慢优化、消化,实现稳步前行,这种超大体量才是我们走向民族伟大复兴的底气。

二、数据育种:从自然规律里,看懂AI迭代升级的真相
我们继续顺着自然和生活的逻辑延伸思考:AI之所以能越来越聪明、能力越来越强,靠的是数据的不断更新、融合与迭代。这和大自然里的作物育种、物种演化,简直是一模一样的道理,也是我们自己琢磨出来的通透感悟。
农民培育优良庄稼、果蔬品种,靠的是同种优选、跨种杂交,一代代迭代改良,淘汰劣质性状、保留优质特性,才能培育出高产、抗风险、口感更好的新品种。AI的数据优化,本质就是给数据育种,通过不同数据的组合、提纯、迭代,让AI长出新能力、练就新本领。
第一种是近缘优选融合。就像同类作物择优繁育,我们把同一领域的细分数据整合起来,比如把医疗行业的内科、外科、检验数据打通,把建筑行业的勘测、设计、施工数据整合。因为领域相通、逻辑相近,融合后的数据会更完整、精准,能稳步提升AI的专业度,几乎不会出现偏差。
第二种是跨域远缘杂交,这也是AI突破能力边界的关键,也是最容易诞生惊喜的地方。就像不同物种合理杂交能诞生新优势,不同领域的数据跨界碰撞,总能创造全新价值,漂亮聪明的混血儿就是如此。如果把气象数据、农耕数据、市场供需数据结合,AI就能预判收成、分析价格走势;把交通、气象、城市人流数据融合,就能优化城市通行方案。
不过,我们也发现了其中的隐患:跨域融合不是万能的。就像亲缘差距过大的物种杂交会出现不育不孕问题,跨度太大、逻辑完全不互通的数据强行拼接,只会产生混乱无用的“畸形数据”,干扰AI的判断,反而得不偿失。
第三种是良种回流提纯,这是我们总结出的高阶优化逻辑。从庞大的数据江河中,筛选出最真实、最权威、最干净的优质数据“良种”,再把这些精品数据回流到整个数据体系中,反哺全域数据池,带动整体数据质量持续升级。
这里藏着一个核心真相,也是我们思考后的新发现:所有迭代的上限,都取决于最初的底色。如果我们初始的数据池本身就充满偏见、错误和短板,那再多次提纯、迭代、优化,都只会不断固化问题,永远培育不出优质的AI模型。
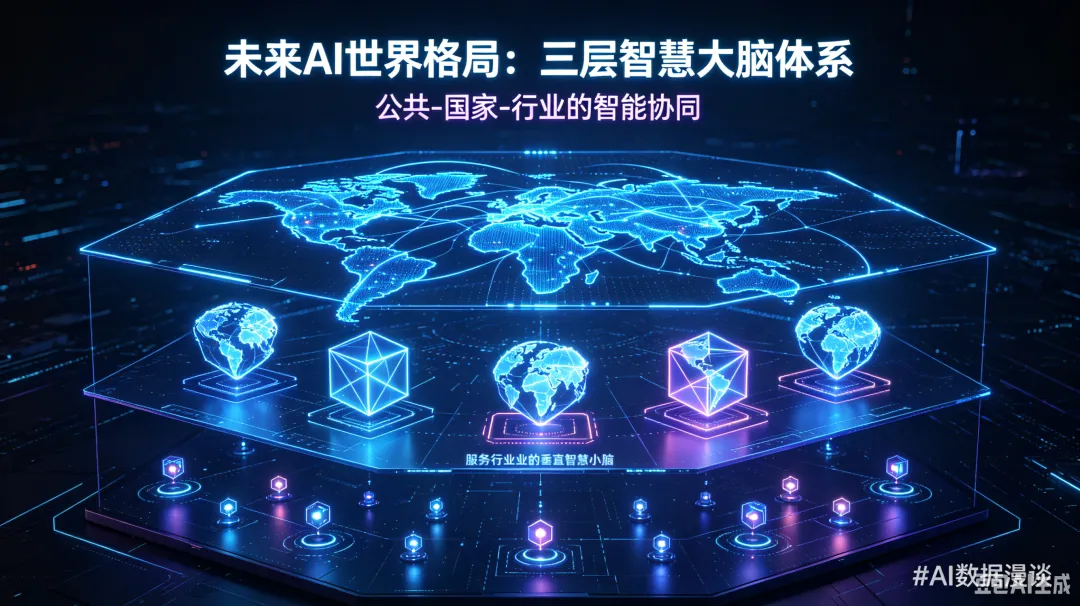
三、对标现实世界:读懂AI未来多元共生的发展格局
很多人都会畅想未来:能不能打造一个覆盖全球、包揽所有信息的超级AI大脑,搞定所有问题?以前我也觉得这个想法很浪漫,但结合现实世界的运行逻辑细细思考后,却有了不一样的看法。
我们真实的物理世界,江河湖海虽互通,却有着清晰的地域边界、规则边界、治理边界,每个区域都有专属的发展模式和管理体系。对应的数字世界、AI体系也是同理,受信息主权、隐私安全、行业规则的约束,永远不会出现一家独大的全球超级AI大脑。
结合社会治理和自然格局,我们认为未来的AI世界,一定是分层、分域、各司其职、多元共生的格局,和人类社会的治理体系完美对应:
顶层是全人类的公共智慧大脑。不分国家、不分地域,整合气候、天文、灾害防控、公共卫生等全人类共通的数据,集合全球力量,共同应对极端天气、自然灾害、公共安全等全球性难题。
中间是各个国家的专属智慧大脑。每个国家依托自身的民生、产业、政务、地理数据,搭建专属的数字底座,守护本国的信息主权、数据安全和发展权益,独立发展、互不越界。
底层是各行各业、各城各地的垂直智慧小脑。深耕农业、工业、医疗、教育、城市治理等细分场景,精准解决我们日常生活、各行各业的具体问题,让AI服务落地实处。
这套多层次、多元化的AI体系,就是我们基于现实世界逻辑,推导出来的未来AI真实形态。这也是我们国家强力推进数字中国的根本原因。

四、数据江河需要治理:AI世界和现实治理一脉相承
我们现实中的大江大河,想要永葆清澈、生生不息,离不开管护、治理和防护。如果放任污水乱排、垃圾乱倒,再辽阔的江河也会慢慢浑浊、失去生机。
AI的数据江河也是一模一样的道理,这也是我结合社会治理规律,总结出的数字生态守护逻辑。虚假数据、恶意数据、无效数据,就是数字世界的“污水和垃圾”,放任它们肆意涌入,只会慢慢污染整个数据生态,让AI判断失准、逻辑混乱、彻底失效。
所以,数字AI系统的治理,完全对标现实社会的治理体系,形成了一套完整的防护闭环,层层守护数据江河的纯净:
第一是源头安检,如同现实中的海关筛查、入口管控。所有想要进入数据体系的信息,都要提前审核筛查,虚假、违规、恶意的内容,直接在源头拦截,从根源杜绝数据污染。
第二是全域免疫,对标人体免疫系统和社会巡检机制。无数轻量化的AI程序,时刻在数据江河中巡查,自动识别、清理隐藏的劣质数据、污染数据,及时化解零星隐患,避免小问题扩散成大范围风险。
第三是规则执法,对应现实中的社会法治管理。针对刻意批量制造虚假数据、恶意破坏数据生态的行为,建立明确的规则和惩戒机制,不止清理污染,更能约束人为行为,守住数字世界的秩序底线。
除此之外,数据生态的经营也像生态环保一样,需要长期维护。我们要持续培育真实、权威的优质“清洁数据”,淘汰无效、劣质的污染数据,定期修复、定期整治,让AI的数据江河永远保持生机与活力。

通篇聊下来,相信大家也能感受到:今天所有的认知,都不是照搬书本、照搬专家结论,而是因为我们一群人一起思考、一起探讨,结合自然规律、生活实景、社会治理,琢磨出来的一点感悟。
我们用一碗清水和大江大河,读懂了数据数量与质量的取舍逻辑;用田间作物育种,摸清了AI数据迭代升级的核心方法;用现实社会的分层治理、生态保护,看懂了AI未来的格局与生态守护之道。
这也印证了我们最核心的感悟:物理世界、现实社会、数字AI、元宇宙空间,万事万物底层原理同源相通。AI从来不是脱离生活的高深科技,只是现实世界的数字化复刻与延伸。读懂了生活,就读懂了AI的底层逻辑。
以上所有观点,都是我自主思考、总结提炼的全新想法,没有标准答案。欢迎大家一起评判、一起探讨,也期待每个人能提出新的思路、新的视角,互相补充、共同完善,解锁更多AI世界的底层秘密。
