 夜雨聆风
夜雨聆风当安全运营团队面对每天上万条告警时,一个根本性问题正在浮现:AI到底应该取代安全分析师,还是成为他们的超级助手?答案或许不是二选一,而是一种新的协作范式“双引擎”协同。现代安全运营中心(SOC)正面临前所未有的压力。以一家中型企业为例,其部署的各类安全设备每天产生5000-8000条告警,经初步聚合后仍有300-500条需要人工研判。传统做法是依靠安全分析师的个人经验逐一排查,但人才短缺和告警疲劳已成为行业通病。大模型的引入似乎带来了曙光。GPT、Claude等通用大模型能快速理解告警上下文,自动生成初步研判报告。
然而在实际部署中,企业很快发现:通用大模型缺乏对特定网络环境和安全策略的理解,在关键决策上“可信但不可靠”——它能给出漂亮的研判报告,却可能在基础判断上犯致命错误。这恰恰引出了双引擎架构的核心价值:让大模型负责“广度”——快速理解上下文、生成自然语言报告、发现潜在关联;让专家系统负责“深度”——执行确定性规则、保证判断的一致性、确保关键决策可审计。

二、大模型引擎:速度与广度的优势
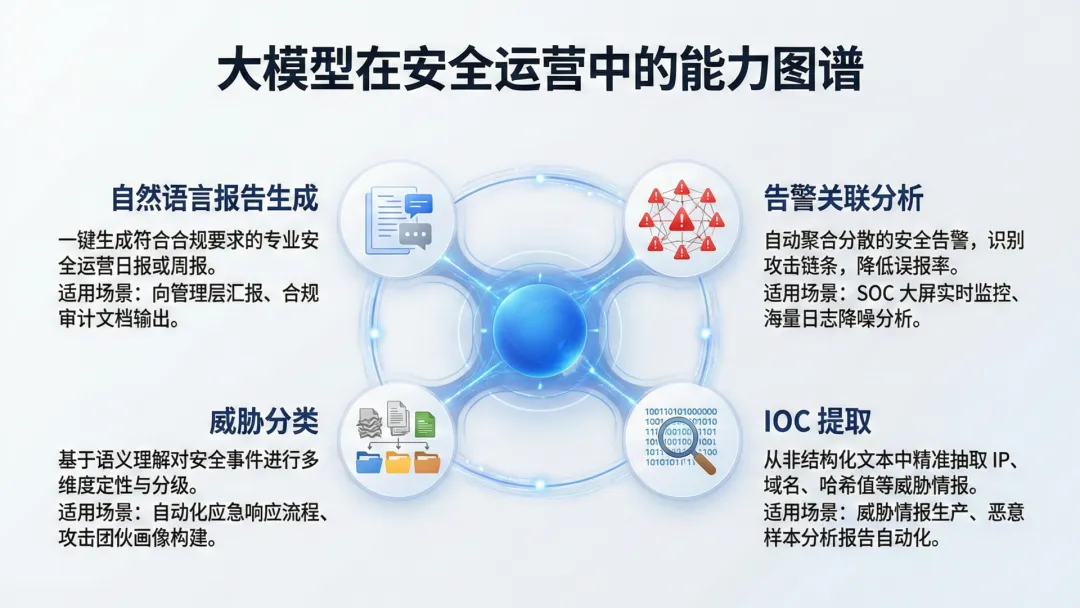
大模型在安全运营中的核心价值不在于替代人,而在于大幅降低安全分析师的信息获取成本。在告警研判场景中,大模型可以快速完成几项关键任务:将原始告警日志翻译成自然语言摘要、关联不同系统来源的告警事件、提取攻击链中的关键指标(IoC)、以及根据已知威胁情报库进行初步比对。
这些工作以往需要资深分析师花费15-30分钟完成,而现在可在数秒内获得初稿。但大模型的输出质量高度依赖输入上下文的完整性和提示词的质量。当告警信息本身不完整(如缺少源IP归属、缺少设备上下文),大模型倾向于“合理猜测”而非明确说“不知道”。在没有专家系统兜底的情况下,这种倾向可能带来安全风险。
三、专家系统引擎:准确与可控的基石
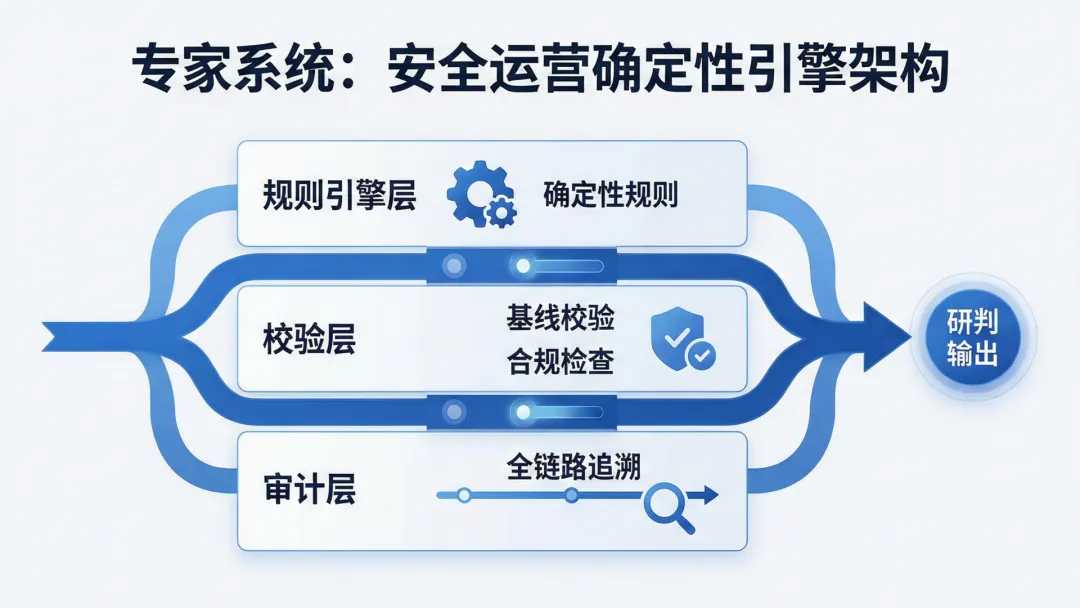
专家系统在大模型时代并未过时,反而找到了更精准的定位——充当安全运营的“确定性引擎”。传统专家系统的核心优势在于:基于明确规则的知识表达。当告警触发时,“若源IP为内部资产且目标为生产数据库的敏感端口”这条规则会给出明确结论。这种确定性在工业安全场景中尤为关键——OT系统的误判代价远高于IT系统。更深层地看,专家系统还承担着安全判断的“最后一道防线”角色。
当大模型给出一个置信度较低的研判建议时,专家系统可以通过预设规则进行校验:这个建议是否与安全基线冲突?是否触发了高危规则?这种“大模型提议、专家系统校验”的模式,确保了安全运营的底线安全。
四、双引擎协同:从接力到融合
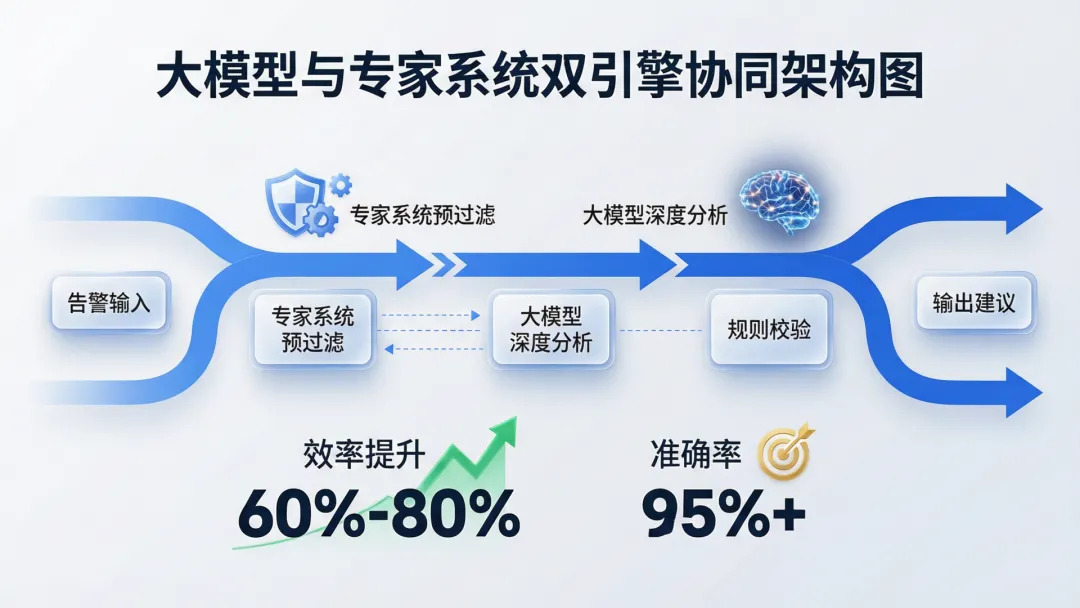
双引擎架构的真正价值,不仅是简单的功能分工,而是两类系统在数据流和决策流上的深度融合。在实践中,一个典型的协同流程如下:
原始告警先经过专家系统的规则引擎进行预过滤,去除明显误报和低优先级事件,将需要深入研判的告警传递给大模型。
大模型生成研判报告后,再由专家系统进行规则校验和合规检查。
最终,双引擎的输出合并为一份完整的告警处置建议,推送给安全分析师进行最终确认。
这种架构带来的三个核心收益:告警处理效率提升60%-80%(预过滤减少人工研判量)、研判准确率提升至95%以上(大模型+专家系统双重校验)、审计追溯全链条闭环(每一环节的判断都有据可查)。
五、落地路径:从试点到全场景
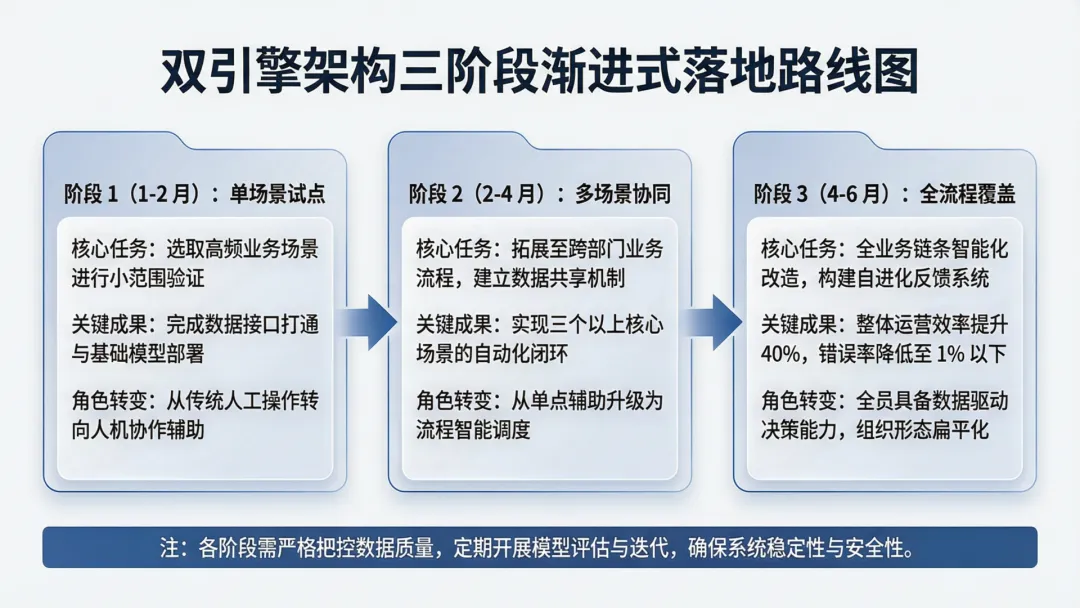
双引擎架构的落地不需要一步到位。企业可以采取“三阶段渐进式”策略:
第一阶段(1-2个月):选取单个场景(如Web攻击告警)进行试点。此时大模型和专家系统独立运行,人工对比输出结果,积累规则调优和提示词优化的经验。
第二阶段(2-4个月):在2-3个场景中实现双引擎协同运行。建立标准化的数据流转管道,实现告警预过滤、大模型分析、规则校验的自动流水线。安全分析师角色从“研判员”转变为“审核员”。
第三阶段(4-6个月):全场景覆盖。双引擎架构扩展至威胁狩猎、事件响应、漏洞管理等全流程。引入持续学习机制,将分析师确认后的研判结果反馈给两个引擎持续优化。
在落地过程中,企业需要特别关注两个关键点:一是数据治理——告警数据的标准化和质量直接决定双引擎的上限;二是人机协同的流程设计——分析师的角色需要重新定义,从“操作者”转向“决策者+优化者”。双引擎架构不是目的,而是通往更高安全运营效能的手段。
当大模型的“创造性”与专家系统的“确定性”真正融合时,安全运营将迎来从“被动响应”到“主动防御”的范式转变。
(本文约1950字,从技术原理与实践路径两个维度,探讨大模型与专家系统在安全运营中的协同模式。)
