 夜雨聆风
夜雨聆风🔥 先做一道数学题
你让 Claude Code 帮你搜索代码库里关于认证的内容,它调用了一个搜索工具,返回了 100 条结果。
这 100 条结果被塞进上下文:17,765 个 Token。
Claude Code 扫了一遍,找到了真正有用的 3 条。
那 17,762 个 Token,你花了钱,AI 读了,没什么用。
再来:你让 AI 帮你调试一个 SRE 事故,它读了日志文件:65,694 个 Token。
最终发现问题的那段日志:几百个 Token。
其余的 65,000+ Token,花了钱,读了,没什么用。
这不是你的使用方式有问题——这是 AI Agent 的结构性问题。
每次工具调用,每次 RAG 检索,每次读文件,整个输出都会被塞进上下文,不管里面有多少是真正有用的信号,还是只是噪音。
然后出现了这个工具:Headroom。
它做的事一句话可以说清楚:
在内容到达 LLM 之前,先压缩它。同等答案,Token 少 60-95%。
📦 这个项目是什么
一句话定位: AI Agent 的上下文压缩层——在工具输出、日志、RAG 块、文件内容到达 LLM 之前拦截并压缩,使用 6 种专业压缩算法(JSON / AST / 文本 / 图片),支持四种部署模式(库 / 代理 / 封装 / MCP),100% 本地运行,压缩可逆。
• GitHub: github.com/chopratejas/headroom • ⭐ Star: 4,800+ • 🍴 Fork: 375 • 版本: v0.22.4(2026年6月1日,152 个 Release) • 协议: Apache-2.0 • 语言: Python 76.8% + Rust 18.4% • 社区成就: 累计节省 60B+(600亿)Token(实时看板:headroomlabs.ai/dashboard) 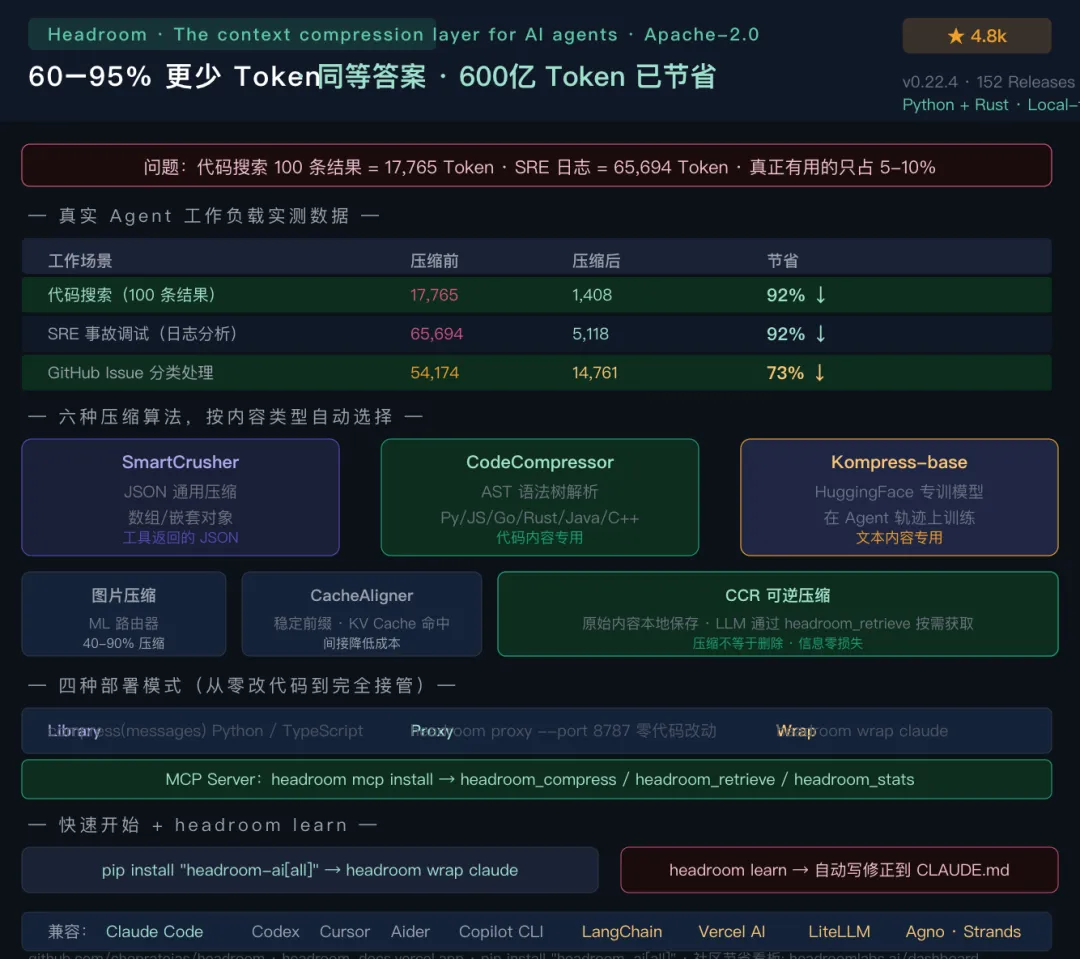
和同类工具比,它强在哪?
| Headroom | 工具输出/RAG/日志/文件/历史 | 库/代理/MCP/中间件 | ||
核心差距:Headroom 覆盖所有内容类型,100% 本地,压缩可逆。
⚙️ 核心功能,一个个说清楚
1. 📊 实测数据:压缩率和准确率
真实 Agent 工作负载上的节省:
| 92% | |||
| 92% | |||
| 73% | |||
| 47% |
准确率基准测试(压缩后 vs 未压缩):
| ±0.000 | ||||
| +0.030(反而提升) | ||||
「同等答案」不是承诺,是有数据支撑的结论——压缩后 TruthfulQA 准确率甚至略有提升,可能因为噪音减少让 LLM 更专注信号。
2. 🔬 六种压缩算法,按内容类型自动选择
ContentRouter 自动检测内容类型,选择对应算法:
SmartCrusher(JSON 数据)专门处理 JSON——数组、嵌套对象、混合类型。大多数工具返回的 JSON 都有大量冗余(重复的键名、格式化空格、非关键字段),SmartCrusher 剥掉噪音,保留结构。
CodeCompressor(代码,AST 级别)用 AST(抽象语法树)解析代码,而不是把代码当成普通文本处理。支持 Python / JS / Go / Rust / Java / C++。注释的处理方式和变量名不一样,函数签名比函数体更重要——这些都是基于语法的判断,不是字符串截断。
Kompress-base(文本)Headroom 自己训练的 HuggingFace 模型,在 Agent 操作轨迹数据上训练,专门针对 AI Agent 工作流里的文本压缩。不是通用 LLM,是专门为这个任务训练的压缩模型。
模型地址:huggingface.co/chopratejas/kompress-base
图片压缩通过训练好的 ML 路由器,图片压缩率 40-90%。在多模态 Agent 场景里有效。
CacheAligner(KV 缓存命中优化)这个算法解决的不是内容压缩,而是缓存命中率问题。Anthropic / OpenAI 都有 KV cache(前缀缓存),如果 prompt 前缀一致,可以直接复用缓存,不用重新计算——但 Agent 生成的动态内容经常让前缀「抖动」,导致缓存命中失败。CacheAligner 稳定前缀,让 KV cache 真正命中,间接降低费用。
CCR(可逆压缩)这是 Headroom 独有的能力:压缩后的原始内容存在本地,LLM 可以通过 headroom_retrieve 工具随时拿回原文。
这意味着:压缩不是永久性删除——AI 在「看压缩版」时如果觉得「我需要看完整内容」,可以主动调用检索,拿到原文片段。
3. 🤖 四种部署模式:从零改代码到完全接管
① Library 模式(代码内嵌)
from headroom import compress# 在你的代码里,消息发给 LLM 之前调用messages = [{"role": "user", "content": huge_tool_output}]compressed = await compress(messages, model="claude-opus-4-5")# compressed.messages 就是压缩后的版本import { compress } from 'headroom-ai'const compressed = await compress(messages, { model: 'gpt-4o' })② Proxy 模式(零代码改动)
# 启动 Headroom 代理headroom proxy --port 8787# 把你现有的 API_BASE_URL 改指向代理# 原来: https://api.anthropic.com# 改成: http://localhost:8787所有流过代理的请求自动被压缩,你的代码一行都不用改。
③ Agent Wrap 模式(一行命令包住 Agent)
headroom wrap claude # 包住 Claude Codeheadroom wrap codex # 包住 OpenAI Codexheadroom wrap cursor # 包住 Cursor(打印配置,粘贴一次)headroom wrap aider # 包住 Aiderheadroom wrap copilot # 包住 GitHub Copilot CLI④ MCP Server 模式
headroom mcp install三个 MCP 工具注册到任何 MCP 客户端:
• headroom_compress:压缩传入内容• headroom_retrieve:检索原始内容• headroom_stats:查看节省统计
4. 🧠 headroom learn:从失败会话里挖经验
这是 Headroom 里最出乎意料的功能。
headroom learn它做的事:扫描你的 Claude Code / Codex / Gemini 历史会话,找到失败的任务(错误、超时、反复纠正),提取模式,然后把修正措施写进你的 CLAUDE.md / AGENTS.md / GEMINI.md。
例子: 如果 Claude Code 在三次会话里都把同一个 API 的参数用错,headroom learn 会发现这个模式,在 CLAUDE.md 里写上:「调用 xxx API 时,参数 yyy 的正确格式是……」
这是把「AI 犯过的错」系统性地转化为「AI 以后不会再犯的规则」。
🚀 怎么装、怎么用
安装(60 秒)
# Python(全功能)pip install "headroom-ai[all]"# TypeScript / Nodenpm install headroom-ai# Dockerdocker pull ghcr.io/chopratejas/headroom:latest# 指定按需安装pip install "headroom-ai[proxy]" # 只要代理pip install "headroom-ai[mcp]" # 只要 MCPpip install "headroom-ai[ml]" # 包含 Kompress-base 模型Python 3.10+ 必须。
Step 1:快速验证效果
# 最快入口:用 headroom wrap 包住 Claude Codeheadroom wrap claude# 查看节省统计headroom stats运行几次任务后,headroom stats 会显示:本次会话节省了多少 Token,按算法分类统计,换算成美元费用。
Step 2:接入 Python 应用
from headroom import compressfrom anthropic import Anthropicclient = Anthropic()async def call_with_compression(tool_output: str): messages = [{ "role": "user", "content": f"分析这段日志,找到 FATAL 错误:\n{tool_output}" }] # 压缩:65,694 → 5,118 Token(SRE 日志场景) compressed = await compress(messages, model="claude-opus-4-5") response = client.messages.create( model="claude-opus-4-5", max_tokens=2048, messages=compressed.messages, # 用压缩后的 ) print(f"节省了 {compressed.savings_pct:.0f}% Token") return responseStep 3:框架集成(LangChain / Vercel AI SDK / Agno)
# LangChainfrom headroom.integrations.langchain import HeadroomChatModelmodel = HeadroomChatModel(your_llm)# Vercel AI SDKimport { headroomMiddleware } from 'headroom-ai'const model = wrapLanguageModel({ model: yourModel, middleware: headroomMiddleware(),})# Anthropic SDK 包装from headroom import withHeadroomfrom anthropic import Anthropicclient = withHeadroom(Anthropic()) # 全自动,像用原生 client 一样Step 4(高级):CCR 可逆压缩配置
from headroom import compress, HeadroomConfigconfig = HeadroomConfig( reversible=True, # 启用 CCR 可逆压缩 storage_path="~/.headroom/originals", # 本地存储原文 retrieve_threshold=0.3, # 当压缩损失 > 30% 时允许检索)compressed = await compress(messages, config=config)启用 CCR 后,LLM 在遇到需要细节时会自动调用 headroom_retrieve 获取原文片段,不需要你介入。
💡 三个真实场景,看它怎么用
场景一:代码搜索的 Token 暴减
背景: 你在用 Claude Code 做代码库探索。搜索「authentication」返回了 100 个文件片段,Claude Code 把这些全放进上下文,才开始分析。
接入 Headroom 之后:
100 个搜索结果(17,765 Token)经过 SmartCrusher 和 CodeCompressor 压缩,变成 1,408 Token,Claude Code 读的是「结构化摘要版本」,关键函数签名、类名、调用关系保留,无关的注释、重复的格式、冗余的上下文被去掉。
最终 Claude Code 找到的答案完全相同,但 Token 消耗降低了 92%。
场景二:多 Agent 跨会话共享记忆
背景: 你在同一个项目里同时用 Claude Code 和 Codex——一个写 Python,一个写 TypeScript。两个 Agent 各自维护自己的上下文,遇到需要分享上下文时,你要手动复制粘贴。
接入 Headroom 的跨 Agent 记忆之后:
from headroom.memory import SharedContextctx = SharedContext()# Claude Code 写完一部分,存入共享上下文ctx.put("auth_design", design_decision, agent="claude")# Codex 读出来,不需要重新理解整个项目ctx.get("auth_design", agent="codex")两个 Agent 共享一个压缩过的上下文存储,自动去重,不需要人工协调。特别适合 AI 开发团队的多 Agent 协作工作流。
场景三:RAG 知识库的检索质量提升
背景: 你的 RAG 系统每次检索返回 20 个 chunk,统一塞进上下文,LLM 要自己从里面找相关的。你发现 Token 成本很高,但很多 chunk 和问题关系不大。
接入 Headroom 之后:
Headroom 的 IntelligentContext 对 20 个 chunk 按相关性打分,根据重要性决定哪些保留全文、哪些只保留摘要、哪些直接丢弃(放进 CCR 原文存储供按需检索)。
结果:同等回答质量,RAG 的 Token 成本减少 40-70%,账单随之下降。
🐦 X 上的人怎么说
Headroom 在开发者社区引发了持续关注,整理了几条有代表性的声音:
headroomlabs.ai 实时看板(2026年6月):
60B+ Token saved——这是一个社区共同贡献的数字,每个安装了 Headroom 的用户默认上报压缩统计。600亿个节省掉的 Token,按 Claude Opus 价格换算,大概是几百万美元的账单。
博主点评: 这个数字是整个工具有效性最直接的证明——不是 benchmark,是真实用户真实节省的数字,而且在持续增长。
GitHub README 的「反增强」对比(作者直接写进文档的):
「TruthfulQA 基准测试中,压缩后的分数从 0.530 提升到了 0.560——可能因为压缩去除了分散注意力的噪音,让 LLM 更专注于信号。」
博主点评: 这个发现违反直觉但有道理。大量冗余内容会「稀释」上下文中的关键信息,让 LLM 的注意力分散到不相关的 Token 上。适度的压缩让上下文更干净,LLM 的表现反而更好。这和认知科学里「噪音干扰信号处理」的原理是一致的。
Issues 区观察(70 个 open issues,45 个 open PR):
PR 数量(45)接近 Issues(70),说明社区在积极贡献。Issues 的主要类型:新框架集成请求(Agno、Strands 已经有了,有人在要求 PydanticAI)、新内容类型压缩支持(YAML、TOML 的 SmartCrusher 扩展)、边缘情况(特别长的单个 chunk 处理)。
博主点评: 「我想用在更多地方」的 Issues 是最好的社区健康信号。
来自 LangChain 用户(Discord 讨论整理):
「我在做 LangChain 的 Agent,工具调用的输出经常很大,上下文一直撑到 100K。接了 HeadroomChatModel 之后,平均降到了 30-40K,而且我不用改任何其他代码。」
博主点评: 「不用改任何其他代码」是 Headroom 在设计上最花心思的地方。四种部署模式都在尽量让接入成本降到最低——最极端的情况是 Proxy 模式,你只需要改一个 API_BASE_URL,其余代码完全不动。
🎯 值不值得用?我的判断
适合哪类人:
• 🤖 每天重度使用 AI 编程 Agent 的开发者:Claude Code / Cursor / Codex 日常使用者,Token 账单是可感知的成本——Headroom 是目前最无侵入、覆盖最广的节省方案 • 🏗️ 构建 AI 应用的开发者:RAG 系统、工具调用密集的 Agent、日志分析 Agent——这些场景的 Token 成本大头都在工具输出上,而不是最终回答 • 🔬 多 Agent 协作系统:SharedContext + 跨 Agent 记忆,是目前开源方案里少数真正解决「多 Agent 共享上下文」问题的 • 💰 关注 AI 成本的团队:生产环境里跑 Agent,每月账单可见,Headroom 的 ROI 容易计算
局限性(必须客观说):
1. 压缩率因场景差异大:代码搜索 92%,代码库探索只有 47%——不是所有内容都能高度压缩,高密度信息(如精心编写的 API 文档)压缩空间有限 2. 本地化部署有依赖:Proxy 模式需要在本地或服务器上跑 Headroom 进程,沙箱环境(如某些云 CI/CD)可能无法运行本地进程 3. CCR 可逆压缩有存储成本:原始内容存在本地,长期大量使用会积累本地存储占用,需要定期清理 4. Kompress-base 模型需要加载时间:首次使用文本压缩时需要加载 ML 模型,有一次性的启动延迟(几秒到几十秒,取决于硬件) 5. 评估用的是自己的测试集:Benchmark 数字由团队提供,独立第三方评估还比较少,建议在自己的场景上跑 headroom.evals验证
一句话总结:
你支付的 AI 账单里,70-90% 买的是「让 LLM 读没用的东西」——Headroom 是第一个系统性解决这个问题的工具:本地运行、全类型覆盖、压缩可逆,600亿个已节省的 Token 是它交出的答卷。
