 夜雨聆风
夜雨聆风你好,我是程序员无隅
引言:很多人第一次学最长公共子序列时,最痛苦的不是代码,而是不知道 dfs(i,j) 到底代表什么。只要状态定义没想清楚,二维表和一维优化都会变成硬背。本文就用 LeetCode 1143 把 LCS 拆开:先从题意和样例看清“有序匹配”,再从记忆化搜索推到二维 DP,最后讲透 pre 和 tmp 为什么能压缩空间。

一、先引入题目:LeetCode 1143 在问什么?
1. 题目要求
题目给定两个字符串 text1 和 text2,要求返回它们的最长公共子序列长度。如果不存在公共子序列,返回 0。
换成人话就是:
从两个字符串里各自删掉一些字符,剩下来的内容要保持原来的顺序,然后问最多能对齐出多长。
2. 子序列的三个限制
可以删除字符:不需要每个字符都留下。
不需要连续:中间可以跳过一些字符。
相对顺序不能变:原来谁在前,选出来之后还得在前。
3. 先用样例建立直觉
先看题目样例:
输入:text1 = "abcde", text2 = "ace"输出:3解释:"ace" 是两个字符串的最长公共子序列
再看两个边界感更强的例子:
输入:text1 = "abc", text2 = "abc"输出:3输入:text1 = "abc", text2 = "def"输出:0
4. 抓住五个关键词
所以这题可以先压成五个关键词:
两个字符串子序列不要求连续相对顺序不变求最长长度
5. 先别和“公共子串”混淆
看到这里,先别急着套 DP 模板。
这题最容易和“最长公共子串”混在一起:公共子串要求连续,而公共子序列允许中间跳过字符。比如 abcde 和 ace,a -> c -> e 中间跳过了 b 和 d,但相对顺序没有变,所以它是合法的公共子序列。
所以 LCS 的核心不是找一段连续内容,而是在两个字符串里做 有序匹配。
接下来真正要解决的是:怎么把这种“有序匹配”拆成可以递推的小问题。
二、解题切入点:为什么从最后两个字符看?
1. 先找能缩小问题的角度
动态规划最关键的一步,不是先建表,而是先找到一个能把大问题拆小的观察角度。
LCS 这题最自然的切法,就是看两个前缀的最后一个字符:
text1[i] 和 text2[j]因为子序列只要求相对顺序不变,所以如果最后两个字符能匹配,它们就可以放到公共子序列的最后;如果不能匹配,就说明这两个字符不能同时作为结尾,只能先丢掉其中一个继续试。
2. 最后两个字符只有两种决策
每一步其实只做一个判断:
如果 text1[i] == text2[j]:
这两个字符一起选,答案来自前面两个前缀 + 1如果 text1[i] != text2[j]:
这两个字符不能一起当结尾要么丢掉 text1[i]要么丢掉 text2[j]取更好的那一种
3. 后面的代码都在实现这件事
后面的记忆化搜索、二维 DP、一维优化,本质上都是在把这套判断写成代码。
三、记忆化搜索:先把 dfs(i,j) 想清楚
做动态规划,第一步不是写代码,而是定义状态。
这题最关键的状态是:
dfs(i, j) 表示:text1[0..i] 和 text2[0..j] 的最长公共子序列长度
也就是说,dfs(i,j) 不是单纯比较 text1[i] 和 text2[j] 是否相等,而是在问两个前缀字符串的 LCS 长度。
比如:
text1 = "abcde"text2 = "ace"dfs(4, 2) 表示:"abcde" 和 "ace" 的最长公共子序列长度
1. 情况一:最后两个字符相等
如果 text1[i] == text2[j],说明这两个字符可以作为公共子序列的最后一个字符。
那么当前答案就是:
前面部分的 LCS + 当前匹配上的这个字符所以转移是:
returndfs(i-1, j-1) +1人话理解:
最后两个字符已经匹配上了,接下来只需要看它们前面的部分还能匹配出多长。
2. 情况二:最后两个字符不相等
如果 text1[i] != text2[j],说明它们不能同时作为公共子序列的最后一个字符。
这时候只能丢掉其中一个:
丢掉 text1[i]:看 dfs(i - 1, j)丢掉 text2[j]:看 dfs(i, j - 1)
然后取更优的结果:
return max(dfs(i-1, j), dfs(i, j-1))这里还有一个常见问题:为什么不需要考虑 dfs(i-1,j-1)?
因为 dfs(i-1,j-1) 表示两个字符都不考虑,而 dfs(i-1,j) 和 dfs(i,j-1) 至少还多保留了一个字符。多给一个字符,LCS 长度不可能更短,所以 dfs(i-1,j-1) 已经被前两个状态覆盖了。
3. 代码思路:记忆化搜索怎么写
这段代码的思路很直接:先从完整字符串的最后一位开始问,也就是 dfs(n-1,m-1)。
dfs(i,j) 每次只关心两个前缀的最后字符:
相等:两个字符一起匹配,问题缩小到 dfs(i-1,j-1)不等:分别尝试丢掉一个字符,取 dfs(i-1,j) 和 dfs(i,j-1) 的最大值
加上 @cache 是为了避免重复计算。因为同一个 (i,j) 状态可能会被很多递归路径问到,缓存之后每个状态只算一次。
fromfunctoolsimportcacheclassSolution:deflongestCommonSubsequence(self, text1: str, text2: str) ->int:n, m=len(text1), len(text2)@cachedefdfs(i: int, j: int) ->int:# 只要有一个字符串为空,LCS 长度就是 0ifi<0orj<0:return0# 最后两个字符相等:一起匹配iftext1[i] ==text2[j]:returndfs(i-1, j-1) +1# 最后两个字符不等:丢掉其中一个returnmax(dfs(i-1, j), dfs(i, j-1))returndfs(n-1, m-1)
时间复杂度是 O(nm),因为一共有 n * m 个状态,每个状态只会计算一次。
空间复杂度也是 O(nm),主要来自缓存表和递归调用栈。
四、二维递推:把递归 1:1 翻译成表格
1. 为什么数组下标要整体 +1?
递归版本里的状态是:
dfs(i, j)但二维 DP 里通常写成:
f[i + 1][j + 1]为什么要整体 +1?
因为递归里有负数边界:
ifi<0orj<0:return0
数组不好用 -1 表示空字符串,所以递推里整体往右下角平移一格。
2. 递归状态怎么对应到二维表?
对应关系是:
dfs(i, j) -> f[i + 1][j + 1]dfs(i - 1, j - 1) -> f[i][j]dfs(i - 1, j) -> f[i][j + 1]dfs(i, j - 1) -> f[i + 1][j]
所以 f[i+1][j+1] 表示:
text1 前 i + 1 个字符和 text2 前 j + 1 个字符的 LCS 长度
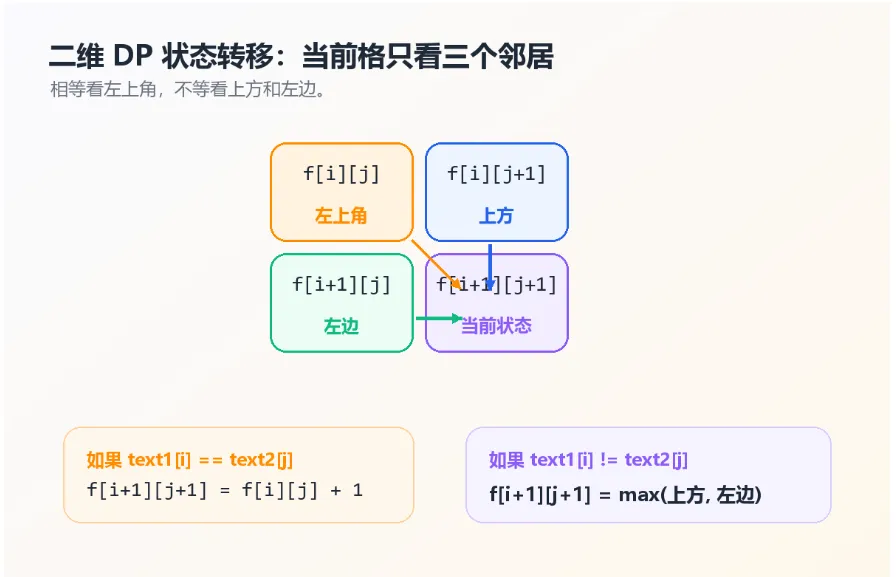
3. 状态转移怎么写?
如果当前两个字符 相等:
f[i+1][j+1] =f[i][j] +1如果当前两个字符 不相等:
f[i+1][j+1] =max(f[i][j+1], f[i+1][j])可以记成一句话:
相等:左上角 + 1;不等:上方和左边取最大。
4. 二维递推代码
二维递推代码如下:
classSolution:deflongestCommonSubsequence(self, text1: str, text2: str) ->int:n, m=len(text1), len(text2)# n + 1 行对应 text1,m + 1 列对应 text2f= [[0] * (m+1) for_inrange(n+1)]fori, xinenumerate(text1):forj, yinenumerate(text2):ifx==y:# 当前字符相等:左上角 + 1f[i+1][j+1] =f[i][j] +1else:# 当前字符不等:上方和左边取最大f[i+1][j+1] =max(f[i][j+1], f[i+1][j])returnf[n][m]
时间复杂度是 O(nm),空间复杂度也是 O(nm)。
五、一维空间优化:为什么一个数组就够?
1. 先看当前状态依赖谁
二维递推中,当前状态只依赖三个位置:
左上角:f[i][j]上方: f[i][j + 1]左边: f[i + 1][j]
也就是说,计算当前格时,并不需要整张二维表。我们只需要保留上一行的信息,以及当前行已经更新过的信息。
所以可以把二维数组压缩成一维数组。

2. f[j] 和 f[j+1] 表示什么?
一维数组写法中,内层循环必须正序遍历 j。
在更新 f[j+1] 之前:
f[j + 1] 表示上方:上一行的 f[i][j + 1]因为 j 是正序遍历,所以 f[j] 已经更新过了:
f[j] 表示左边:当前行的 f[i + 1][j]但还有一个值会被覆盖:
左上角:f[i][j]所以需要用 pre 保存左上角。
对应关系是:
pre = 左上角f[j + 1] = 上方f[j] = 左边
3. tmp 是干什么的?
代码里这一句非常关键:
tmp=f[j+1]它的作用是先保存旧的 f[j+1]。
因为旧的 f[j+1] 是上一行的值,下一轮循环会变成新的左上角。
更新完当前格后:
pre=tmp意思是:
把旧的上方值,交给下一轮当左上角使用所以一维优化可以浓缩成一句话:
pre保存左上角,tmp防止旧值被覆盖,并把旧值传给下一列。
4. 一维优化代码
一维优化代码如下:
classSolution:deflongestCommonSubsequence(self, text1: str, text2: str) ->int:m=len(text2)f= [0] * (m+1)forxintext1:# 每一行最左边对应空字符串,LCS 长度为 0pre=0forj, yinenumerate(text2):# 更新前的 f[j+1] 是“上方”,下一轮要作为“左上角”tmp=f[j+1]ifx==y:# 相等:左上角 + 1f[j+1] =pre+1else:# 不等:上方和左边取最大f[j+1] =max(f[j+1], f[j])# 当前旧值变成下一列的左上角pre=tmpreturnf[m]
也可以写成更精简的版本:
classSolution:deflongestCommonSubsequence(self, text1: str, text2: str) ->int:f= [0] * (len(text2) +1)forxintext1:pre=0forj, yinenumerate(text2):tmp=f[j+1]f[j+1] =pre+1ifx==yelsemax(f[j+1], f[j])pre=tmpreturnf[-1]
5. 为什么 j 不能倒序遍历?
这里还有一个面试里很容易被问到的小点:为什么 j 不能倒序遍历?
因为转移需要用到 f[j],它表示当前行左边的值。只有正序遍历时,f[j] 才已经被更新成当前行的结果。
如果倒序遍历,f[j] 还是上一行的值,就不能表示“左边”。
所以这题一维优化必须正序遍历 j。
6. 复杂度
一维优化后,时间复杂度仍然是 O(nm),空间复杂度降为 O(m)。
如果让较短的字符串作为 text2,空间复杂度可以进一步理解成 O(min(n,m))。
六、验证和常见坑
✅ 用样例验证一下
题目样例:
text1 = "abcde"text2 = "ace"答案:3
因为最长公共子序列是 "ace"。
再看几个边界用例:
text1 = "abc"text2 = "abc"答案:3
两个字符串完全相同,LCS 就是整个字符串。
text1 = "abc"text2 = "def"答案:0
没有任何公共字符,答案是 0。
text1 = ""text2 = "abc"答案:0
只要有一个字符串为空,LCS 长度就是 0。
⚠️ 常见坑总结
状态定义别想窄了:
dfs(i,j)不是只比较两个字符,而是表示text1[0..i]和text2[0..j]的最长公共子序列长度。二维数组行列别开反:二维数组要开成:
f= [[0] * (m+1) for_inrange(n+1)]这里 n+1 行对应 text1,m+1 列对应 text2。
别忘了 i+1 和 j+1 的含义:
i+1和j+1是为了处理空字符串边界。f0 表示 text1 为空fi 表示 text2 为空
一维数组长度要多开 1:
f= [0] * (len(text2) +1)因为代码里会访问 f[j+1]。
每一行都要重置 pre:每次外层循环开始时都要重置
pre = 0。因为每一行最左边都对应空字符串,LCS 长度是0。
七、面试话术沉淀
【问题】
最长公共子序列这题你是怎么做的?
【一句话】
最长公共子序列可以用动态规划解决,核心是定义 dfs(i,j) 或 f[i+1][j+1] 表示两个字符串前缀的 LCS 长度,然后根据最后两个字符是否相等做状态转移。
【关键词】
前缀状态最后字符比较相等左上角 + 1不等上方和左边取最大记忆化搜索二维递推一维空间优化
【项目里怎么做】
这类问题我一般先用记忆化搜索把状态定义想清楚,再 1:1 翻译成二维 DP。
如果只需要最终长度,不需要还原路径,就可以继续把二维表压缩成一维数组:用 pre 保存左上角,用 f[j+1] 表示上方,用 f[j] 表示左边。
【面试追问】
追问一:为什么相等时直接 dfs(i-1,j-1)+1?
因为两个字符相等时,可以直接作为公共子序列的最后一个字符。把它们匹配后,只需要继续求前面两个前缀的 LCS,再加上当前这个匹配字符。
追问二:为什么不等时不用考虑 dfs(i-1,j-1)?
因为 dfs(i-1,j-1) 表示两个字符都不考虑,它一定不会优于 dfs(i-1,j) 或 dfs(i,j-1)。多保留一个字符,LCS 长度不可能变小。
追问三:一维优化里的 pre 是什么?
pre 保存的是二维 DP 里的左上角状态,也就是 f[i][j]。因为一维数组更新时左上角会被覆盖,所以需要提前保存。
追问四:为什么一维优化要正序遍历 j?
因为 f[j] 要表示当前行左边的状态。只有正序遍历时,f[j] 才已经被更新成当前行结果;如果倒序遍历,它还是上一行的值,转移就错了。
八、最后总结
最长公共子序列这题,最重要的是把状态定义想清楚:
dfs(i,j) 表示:text1[0..i] 和 text2[0..j] 的最长公共子序列长度
核心转移只有两种:
iftext1[i] ==text2[j]:returndfs(i-1, j-1) +1returnmax(dfs(i-1, j), dfs(i, j-1))
递推版本就是把递归整体平移一格:
dfs(i,j) -> f[i+1][j+1]二维递推记住一句话:
相等:左上角 + 1;不等:上方和左边取最大。
一维优化也记住一句话:
pre是左上角,f[j+1]是上方,f[j]是左边,tmp用来保存旧值,防止更新时把左上角弄丢。
这题真正要练的不是代码长度,而是动态规划最核心的能力:
把大问题定义成状态,再找到它和更小问题之间的关系。
