 夜雨聆风
夜雨聆风
当中国大模型的API调用量在全球平台上首次超过美国,当MiniMax 73%的收入来自海外,当DeepSeek的开源模型被东南亚35%的开发者采用,一个不可逆的趋势正在成型:中国AI的全球化,已经从要不要出海变成了怎么出海。
引言:出海,是被逼出来的
2026年开年,中国AI行业迎来了一个微妙的拐点。
一边是国内战场的白热化,阿里、字节、腾讯、百度四大巨头在国内开启AI应用推广狂潮,月活破亿成为头部AI应用的标配,春节期间三家大厂合计砸下超过45亿人民币做红包大战,试图把AI产品塞进每一个中国用户的手机里。另一边,是创业公司在夹缝中越来越难以呼吸,大厂从通用大模型向垂直领域持续渗透,讯飞星火、百川智能等玩家虽已布局多年,但却面临越来越小的市场空间。
对于中国AI创业公司而言,国内市场正在变成一场不对等的竞争。大厂有流量、有数据、有用户基础、有生态闭环,创业公司拿什么去拼?
答案越来越清晰:出海。
但2026年的AI出海,已经不再是三年前那种做一个ChatGPT套壳产品到海外试试的草莽阶段。它正在演变成一场更加系统性的战略,有人靠开源模型撬动全球开发者生态,有人用C端产品切入海外用户的情感需求,有人通过API调用赚取美元收入,还有人在小心翼翼地探路。


为什么必须出海?
1. 国内市场的困局
把时间拨回2024年,中国大模型赛道最火热的关键词是"价格战"。从百度到阿里再到字节,各家争先恐后地把模型调用价格打到地板价,甚至免费开放API,试图用规模换用户。
到2025年下半年,价格战的后遗症开始显现:用户规模上去了,但付费意愿极低;Token消耗量暴涨,但收入增长远远跟不上算力成本。更关键的是,当大厂把AI能力内嵌到自己的生态产品里(淘宝里的AI助手、抖音里的AI剪辑、微信里的AI搜索),独立AI应用的生存空间被急剧压缩。
在中国市场,AI通用入口的日均使用时长普遍不超过15分钟,包括用户使用频率最高的豆包,人均每天也只花10分钟左右。这说明AI入口在大多数中国用户眼中仍然是用完即走的工具属性,用户没有形成深度依赖,自然也就没有强付费动力。
国内市场的付费天花板,逼迫创业公司把目光投向海外。
2. 瞄向全球付费市场
与国内不同,全球AI市场仍处于爆发式增长的早期。
根据CIC的数据,全球基础模型市场规模将从2024年的107亿美元增长至2029年的2065亿美元,年复合增长率高达80.7%。Gartner的预测更为宏观:2026年全球AI总支出将达到2.52万亿美元,同比增长44%,其中生成式AI支出占比将从2025年的约15%提升至约25%。
如果一家中国AI公司能拿下全球基础模型市场1%的份额,到2029年就意味着超过20亿美元(约合141亿人民币)的收入。
更重要的是,海外用户的付费意愿远高于国内。正如Wave Speed AI COO周德振所说:"真正商业化比较成功的AI项目,就是从第一天就去攻欧美市场的那些,因为海外用户愿意为工具付钱。"海外用户对AI生产力工具的付费接受度高,尤其是技术用户和创作者群体,他们习惯了为Notion、Figma、GitHub Copilot这样的工具按月付费,对新的AI工具同样愿意掏钱。
3. 技术平权:中国模型对于很多人已经够用了
过去,中国大模型出海最大的障碍是技术差距。当OpenAI的GPT-4横扫一切的时候,中国模型在海外几乎没有竞争力。
但这个局面在2025年被彻底改写。
斯坦福大学发布的《2026年AI指数报告》明确指出,美国和中国的模型自2025年初以来已多次在性能排名顶端交替领先。截至2026年3月,美国顶尖模型与中国顶尖模型的Elo评分差距仅为2.7%,这个差距,对于大多数应用场景来说,已经可以忽略不计。
2025年,美国发布了50个模型,中国发布了30个。但在论文发表数量、引用次数、专利产出方面,中国已呈现明显领先趋势。更重要的是,开源路线的崛起让中国模型获得了额外的竞争武器。
当技术性能的差距不是那么大的时候,价格就成了决定性因素。中国大模型API调用价格仅为美国同行的三分之一到五分之一。这背后是完整的产业链支撑,从算力基础设施到工程优化,从人才储备到市场规模,每一个环节都在拉低综合成本。

谁已经跑出来了?
大模型出海五大金刚
1. DeepSeek:用开源撕开全球市场的口子
2025年1月,DeepSeek以一种出乎意料的方式登上世界舞台。
DeepSeek-R1开源大模型上线后,凭借极低的成本(输入价格仅为GPT-4 o1的约十五分之一)和接近GPT-4 o1的性能表现,在全球开发者群体中引发震动。上线一个月后,DeepSeek在东南亚开发者群体中的占比就达到了35%。此后,这个来自中国的开源模型相继在中东以及拉美的巴西、智利等市场广受欢迎。
DeepSeek的出海逻辑极是不做C端产品,不做本地化运营,只做一件事,把最好的开源模型丢出去,让全球开发者自己用。这种策略的好处是几乎不需要海外运营团队,不需要应对各国的数据合规问题(因为模型是开源的,开发者自己部署),也不需要做用户增长,开发者社区自带传播效应。
到2025年12月,DeepSeek在全球的访问量约为3.1亿次,稳居全球AI产品榜前三。2026年4月,DeepSeek上线了专家模式,开始在产品端引入模式分层设计,同时释放了大量与Agent相关的招聘需求,信号明确:从开源模型提供商向AI平台进化。
DeepSeek的意义远不止于自身的商业成功。正如创新工场董事长李开复所言,如果坚持闭源,中国AI公司"很难打败美国"。开源路线通过众筹模式,快速实现效率创新、人才激活、生态构建和全球协同,让中国AI大模型在资源约束下实现了快速追赶。两年前,顶尖闭源模型和开源模型之间的技术时间差很大,而到2025年已缩小至半年左右。
DeepSeek已经证明了一件事:中国AI出海,开源是最低成本、最高杠杆的切入点。
2. MiniMax:出海"长期主义者"的标杆
如果说DeepSeek的出海是一把火烧开整片草原,那么MiniMax则是AI创业公司中出海的长期主义者。用两年时间,从2023年19%的海外收入占比,一路做到2025年全年的73%。
MiniMax的出海战略值得研究。
第一步:用C端产品打开市场。MiniMax旗下的Talkie(角色互动应用)是最早进入海外市场的中国AI产品之一。截至2025年9月,Talkie的付费用户数增长至139万,同比增长184%。虽然2024年底Talkie因地缘政治因素在美国和日本App Store被下架,但这反而倒逼MiniMax加速了产品矩阵的多元化。
第二步:用视频生成产品制造爆点。2024年9月上线的海螺AI海外版(Hailuo AI)成为真正的王炸。上线仅一个月,月访问量同比增长2772.92%,在全球AI产品榜增速榜登顶。从2024年10月到2025年3月,海螺AI的月访问量位列全球视频生成赛道第一,力压OpenAI的Sora和Runway。更重要的是,海螺AI实现了量价齐升,2025年前三季度付费用户远超2024年全年,ARPU(每付费用户平均收入)从36美元跳涨至56美元。
第三步:用B端API服务构建长期护城河。2026年1月MiniMax在港股上市后,其开放平台业务加速增长。M2系列文本模型在发布后日均Token消耗量达到此前的6倍以上,编码场景的消耗量更是增长超过10倍。MiniMax成为首个在OpenRouter平台上日Token消耗突破500亿的中国模型。全球头部云厂商均已部署MiniMax模型,包括Google Vertex AI、Microsoft Azure AI Foundry、Fireworks AI等。在Notion上线的M2.5甚至成为Notion首个且唯一的开源模型。
截至2025年底,MiniMax累计服务覆盖超过200个国家和地区,拥有2.36亿个人用户和21.4万家企业客户。从区域收入结构来看,亚太地区占61%、美洲地区24%、欧洲中东非洲15%,形成了多元化的全球布局。
MiniMax今天出海形成了一定的系统能力。它需要C端产品的爆发力(制造用户规模和品牌认知),也需要B端API服务的持久力(构建技术粘性和稳定收入),还需要全模态的产品矩阵(文本、语音、视频、音乐全覆盖,满足不同场景需求)。

3. Kimi(月之暗面):从掉队到逆袭的出海传奇
月之暗面的故事,是中国AI出海叙事中最戏剧性的一个部分。
2025年下半年,Kimi曾陷入增长困境。7月月活滑落至1408万,国内排名跌至第九,一度被贴上"首家掉队AI公司"的标签。公司紧急招聘海外增长运营、海外用户增长专家和国际化产品经理等岗位,出海已经是企业生存必须。
转折发生在2025年7月。Kimi推出1万亿参数的K2大模型,采用MoE架构(激活参数320亿),一举登顶全球开源模型榜首。同年11月,Kimi进一步推出K2 Thinking版本,在智能体工具调用能力测试中以93%的得分创下第三方机构最高纪录,超过OpenAI和Anthropic等海外闭源旗舰模型。2025年12月,K2 Thinking在Hugging Face上正式开源,采用修改后的MIT许可证。2026年1月底推出的K2.5大模型进一步升级,打造"长记忆+多模态+智能体"技术能力的深度融合。
但真正让Kimi在海外出圈的,是一个谁也没预料到的事件。2026年初全球爆发的龙虾热(OpenClaw现象)。OpenClaw这款AI智能体框架在全球技术圈快速走红,而Kimi的模型因为在Agent能力上的领先表现,成为OpenClaw开发者的首选底层模型之一。数据显示,2025年9月至11月,Kimi全球付费用户数平均月度增速170%,K2 Thinking的发布推动海外API收入增长4倍。
到2026年2月,中国模型在OpenRouter平台全球Token消耗占比达到了61%,MiniMax和Kimi包揽前三名。月之暗面创始人杨植麟在内部信中透露,公司现金持有量超过100亿元人民币,短期不急于上市,并定下2026年三项战略:聚焦K3模型研发、加速商业化落地、提升员工激励。

4. 智谱AI:B端主权AI的差异化出海
如果说MiniMax和Kimi的出海是面向全球C端用户和开发者的流量型打法,那么智谱AI走的则是一条截然不同的路——B端主权AI出海,主攻政府、企业等机构客户,核心卖点是数据安全、自主可控和本地化适配。
智谱的企业基因是学术。它脱胎于清华大学计算机系知识工程实验室(KEG),由清华教授唐杰作为创始人和首席科学家发起,张鹏担任CEO,刘德兵出任董事长,核心团队均具深厚的清华背景。这种学术基因赋予了智谱在基座模型研发上的深厚积累,也决定了它的商业气质,更偏To B、更偏基础设施、更偏卖铲子。
2026年1月8日,智谱以全球AI大模型第一股的身份登陆港股,股票代码HK2513,发行价116.2港元,上市市值超511亿港元。香港公开发售获1159.46倍认购。国际资本市场对中国大模型企业的信心空前高涨。上市后不到两个月,智谱股价从发行价一路冲至近1500港元,市值接近7000亿港元,远远超过百度、京东和快手等传统互联网企业。
智谱的出海战略与MiniMax、Kimi有着本质区别。
第一,走主权AI路线,深耕政府级客户。2025年底,智谱与马来西亚合作的国家级MaaS平台和Z·UM AI人才培养实验室正式落地。这个平台基于智谱Z.ai开源基础模型构建,针对马来西亚马来语、英语、汉语的多语言环境及本地文化进行了深度优化,同时保持以主权为核心的数据安全架构,赋能政府办公、企业生产和科研教育等多个场景。这种模式的核心卖点是,你的数据留在你的国家,你的AI由你自己掌控。对于东南亚、中东等对数据主权高度敏感的新兴市场而言,这正是它们最想要的。
第二,以MaaS为核心商业模式,做AI时代的云服务。智谱的商业模式以MaaS(模型即服务)为主,类似于OpenAI和Anthropic的变现方式,交付通用智能而非定制项目,低成本地将智能赋能于无限场景。2025年上半年,MaaS业务贡献了公司84.8%的营收。2025年全年,智谱营收7.24亿元,同比增长131.9%。虽然毛利率从上年的56.3%下降至41.0%(主要因为规模扩张带来的算力成本增加),但收入规模在中国独立通用大模型开发商中排名第一。
第三,GLM-5的发布标志着智谱从基座模型向Agent模型的战略转型。2026年2月12日,智谱发布新一代旗舰模型GLM-5,率先在海外版上线。值得注意的是,GLM-5的海外版Coding plan订阅价格提高了30%-60%,API调用价格更是提升了67%-100%,这是国产大模型近期来的首次大幅提价。智谱认为自己的模型已经具备了提价权。GLM-5被直接设计为可执行任务的Agent模型,强化编程能力、工具调用与长流程执行,精准匹配B端企业的生产力需求。此前,在全球权威大模型评测榜单Artificial Analysis公布的AA智能指数中,智谱GLM-4.7模型已登顶开源模型榜首。
截至目前,智谱已拥有全球12000家企业客户、4500万开发者,模型全球下载量达6000万次,8000万台终端设备搭载其模型,形成了从技术研发到生态落地的完整B端出海体系。
智谱的出海说明主权AI和本地化部署的B端路线同样走得通。尤其是在东南亚、中东等新兴市场,政府对AI基础设施的需求正在爆发,而这些国家既不想完全依赖美国的OpenAI/Google,又缺乏自主研发大模型的能力。中国的主权AI方案恰好填补了这个空白。

5. 阿里千问(Qwen):大厂出海的集团军打法
2025年12月,美国顶级科技媒体《连线》(WIRED)发表头条文章,罕见地点名看好千问,宣称"2026年将是阿里千问(Qwen)之年"。文章指出,尽管OpenAI的GPT-5、Google的Gemini 3和Anthropic的Claude通常跑分更高,但千问、DeepSeek、智谱、MiniMax等中国模型性能也稳居第一梯队,并且越来越受欢迎,"原因在于它们既性能优异,又易于开发者灵活调整和使用"。
千问的出海底气来自阿里过往积累的一定技术能力,通义实验室、阿里云、平头哥芯片。这是马云回归后亲自命名的战略布局,三位一体,目标是成为AI时代的全栈能力提供商。
在技术层面,早在2024年6月,千问新一代模型Qwen2就在同尺寸模型基准测试中超越Meta旗下开源模型Llama3,跻身全球开源模型第一梯队。到2025年4月,Qwen3更是在多个权威基准测试中超越DeepSeek-R1和OpenAI-o1等全球顶尖模型。2026年4月,阿里发布Qwen3.6-Plus,继续强化在Agent能力上的竞争力。
在市场层面,2026年1月,千问App宣布全网月活突破1.02亿,且以42.18%的高活跃率远超行业平均水平。阿里云作为千问的全球分发渠道,覆盖全球主要云计算市场,为千问的海外落地提供了天然的基础设施优势。
千问的出海路径代表了大厂的典型打法,技术实力+云计算分发渠道+开源生态构建。
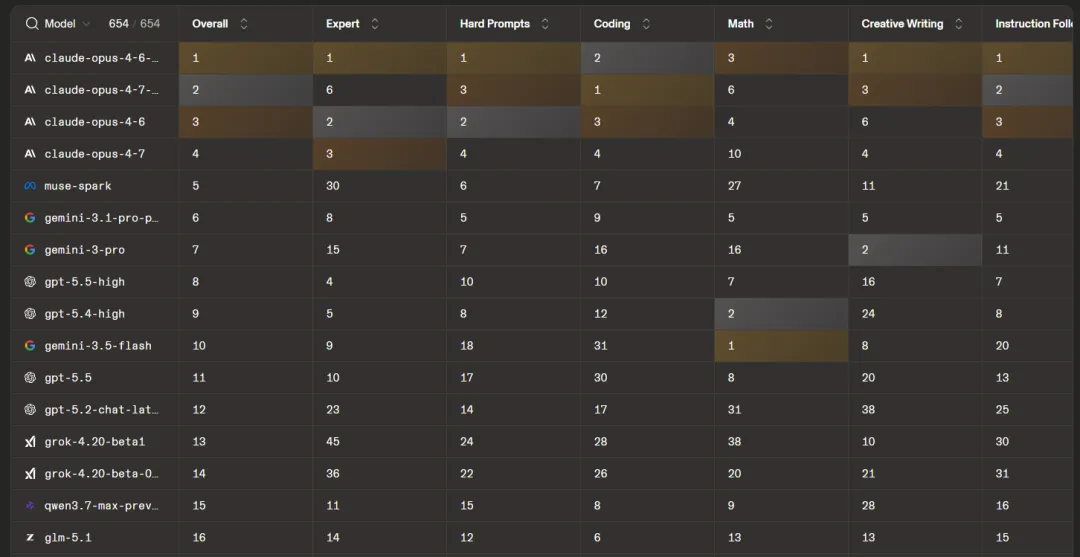
(数据来源Hugging Face)

出海路径全景图——
三种模式、三种逻辑
通过对上述样本和更广泛行业观察的梳理,我们可以将中国AI大模型出海归纳为三种核心路径:
1. 开源生态出海
这是目前中国AI出海最主流、最高效的路径。
核心逻辑是:把模型开源→全球开发者免费使用→在开发者社区中建立品牌认知和技术依赖→通过API服务和云计算变现。
这条路径的典型代表是DeepSeek和阿里千问。数据显示,在Hugging Face平台的新建模型(创建不到1年的模型)中,中国模型的下载量已经超过包括美国在内的任何其他国家。2025年2月至7月期间,中国公司的开源发布明显更加活跃,百度和月之暗面从闭源路径转向开源发布,智谱和阿里巴巴从发布模型权重扩展到构建工程系统和生态系统接口。
开源出海的最大优势是绕开了传统出海的几乎所有难题,不需要在海外设立实体、不需要大规模营销投入、不需要应对各国应用商店的审核政策、不需要处理用户数据的跨境传输问题。模型是开源的,开发者自己下载、自己部署、自己负责合规。
但开源的商业化挑战也很明显:如何从免费用户中提取付费价值?目前主要有三条路:一是高级版本付费(开源基础模型,闭源高级模型);二是API调用计费;三是通过云计算平台分发获取分成。
2. C端产品出海
这是创业公司最擅长的出海路径。
核心逻辑是:找到海外用户的刚需场景→开发本地化的AI产品→通过应用商店和社交媒体获取用户→通过订阅和内购变现。
这条路径下又分为两个主要方向:
效率工具方向。海外用户对AI生产力工具的付费意愿很强。编码助手、文档生成、数据分析等场景都是高价值市场。中国AI公司的模型已经开始融入海外主流生产力工具链,接入Cursor、OpenCloud等海外开发工具,用户从主动选择转向默认依赖,形成了高粘性的使用习惯。
情感陪伴方向。MiniMax的Talkie是这个方向的先锋。虚拟角色互动、AI陪伴和AI社交产品在海外(尤其是北美和日本市场)有着巨大的需求。这些产品的用户粘性极高,付费率远超效率工具。但挑战也很大,内容安全、未成年人保护、文化敏感性等问题,以及各国对AI拟人化互动的日趋严格的监管。
视频/图片生成方向。海螺AI(Hailuo AI)的爆发证明了这个赛道的潜力。当OpenAI的Sora迟迟未能上线时,中国的视频生成产品抢先占领了市场。海螺AI从2024年10月到2025年3月连续数月蝉联全球视频生成赛道访问量第一,证明在特定垂直赛道上,中国AI产品完全可以做到全球领先。
3. API/MaaS出海
这是一种正在快速崛起的新型出海模式。
核心逻辑是:海外开发者和企业通过API调用中国的大模型,计算在中国国内的数据中心完成,结果通过网络传回海外。本质上是用API调用的方式将中国的算力和模型能力出口到全球。
这种模式的独特之处在于:它实现了一种“无税出口”的价值交付。模型的推理计算在国内完成,不涉及硬件出口(因此绕开了芯片出口限制),不涉及用户数据的跨境传输(因为数据由海外用户自行管理),也不涉及传统贸易中的关税和物流成本。
数据显示,2026年2月中国模型在OpenRouter平台全球Token消耗占比达到61%。这意味着,全球超过一半的AI API调用量,正在流向中国模型。这种"数字贸易"模式,正在成为中国AI出海最重要的收入来源之一。
我们认为,API/MaaS出海可能是中国AI出海最具长期价值的路径。它不受单一市场政策变化的影响,不依赖应用商店的分发渠道,不需要大规模的本地化运营,且边际成本递减。只要模型足够好、价格足够低、服务足够稳定,全球开发者就会用脚投票。

未来展望——
出海的下一程
1. 从工具出海到生态出海
根据行业观察,AI出海的技术输出正在经历三个发展阶段:第一阶段是工具型应用出海,核心策略是输出标准化工具类产品,聚焦单点功能以快速占领细分市场;第二阶段是商业模式出海,核心策略是结合技术优势输出行业解决方案,赋能本地产业;第三阶段是技术生态出海,核心策略是推动技术标准与开源协作,构建全球化技术生态。
目前,大多数中国AI出海企业仍处于第一阶段和第二阶段之间。但头部企业(尤其是阿里千问和DeepSeek)已经开始向第三阶段迈进。当中国的开源模型成为全球开发者的默认选择时,一个以中国技术为底座的全球AI生态就开始成型了。
2. 资本市场估值大幅提升
2026年,中国AI企业在全球资本市场获得了前所未有的认可。
MiniMax和智谱AI相继登陆港股,受到国际投资者的追捧。OpenAI在2026年3月完成1220亿美元融资,投后估值达8520亿美元;Anthropic在2月完成300亿美元融资。在这种全球AI资本狂潮中,中国AI企业也在获得越来越多的国际资本关注。阶跃星辰在1月完成50亿元B+轮融资,刷新国内大模型单笔纪录;生数科技获近20亿元B轮融资;极佳视界两个月内融资25亿元。

全球投资者正在把中国AI企业视为不可忽视的资产类别。技术实力与资本吸引力的爆发,标志着中国AI企业已经走过了单纯的追赶阶段,开始在全球智能革命的下半场中占据核心席位。
3. Agent时代的新机遇
2026年被广泛认为是"Agent元年"。从OpenClaw的全球爆发到各大模型厂商争相强化Agent能力,AI从对话工具向自主执行的转变正在加速。
对中国AI出海企业而言,Agent时代意味着新的机遇窗口。Agent的核心价值在于替用户完成任务,这天然需要与本地生态的深度集成,连接本地的支付系统、物流网络、政务服务、医疗资源等。中国企业在TikTok、SHEIN等产品出海过程中积累的本地化运营经验,在Agent时代可能会成为新的竞争优势。

结语:
这是一场没有退路的远征
回到文章开头的那个判断,中国AI大模型出海,已经从要不要出海变成了怎么出海。
国内市场的内卷只会越来越激烈,全球市场的窗口不会永远敞开。当美国和欧洲的监管框架日趋成熟、当本土AI生态日趋完善、当地缘政治的墙壁越砌越高,留给中国AI企业出海的时间窗口,可能比我们想象的要短。
但也正是因为这种紧迫感,才让这场出海远征变得如此激动人心。
从DeepSeek用开源模型撕开全球市场,到MiniMax用C端产品和API服务双轮驱动海外增长;从Kimi凭借技术突破实现逆袭,到阿里千问以集团军打法正面推进,中国AI大模型出海的增长空间还很大。
2026年,中国AI出海的故事才刚刚开始。而最精彩的章节,或许还在后面。


