 夜雨聆风
夜雨聆风YC 的 AI-Native 组织改造最值得看的,不是它用了多少 Agent,而是它把 AI 从个人工具变成了组织基础设施:让上下文可被读取、工具可被调用、使用过程可被沉淀、权限边界可被治理、组织能力可持续改进。对企业来说,AI 落地进入深水区以后,重点会从工具采购转向组织改造。
今天想认真看一个组织案例:YC 的 AI-Native 组织改造。
这两天我听了 YC 自己的一期公开对谈,题目叫《How To Build Superintelligence Inside Your Company》。
这期节目里,YC 合伙人、Optimizely 创始人 Pete Koomen 讲了他过去一年多怎么从零搭建 YC 内部的 Agent 基础设施。
听完以后,我最有感触的,不是那些听起来很厉害的数字和机制:比如 350 多个内部工具、全员可见的 Agent 对话系统、每天晚上自动读取对话并改进技能的 Dream Cycle。
这些当然重要,但如果只看这些,很容易把 YC 的案例理解成“他们用了很多 Agent”。
我更关心的是另外一件事:
企业 AI 落地走到深水区以后,重点会从“买什么工具”,转向“组织能不能被 AI 改造”。
也就是说,AI-Native 组织不是给员工多配几个 Copilot,也不是上线几个内部机器人。它更接近一套组织基础设施改造:把企业的上下文、工具、流程、经验和权限边界,变成 Agent 可以参与运转的结构。
这也是 YC 这个案例最值得企业负责人看的地方。
YC 不是一家传统意义上的企业软件公司。
它是创业加速器,组织不大,业务密度很高,内部有大量关于创业公司、创始人、投资、财务、office hours、活动和 CRM 的工作流。
过去一年多,YC 合伙人 Pete Koomen 主导搭建了一套内部 Agent 系统。按原文描述,这套系统最早从财务场景开始,后来演化成覆盖全员的通用 Agent 基础设施。
这里有一个细节很关键。
一开始,团队不是为了“做一个 AI 战略项目”,而是看到了一个很具体的组织摩擦:财务团队要向工程师描述复杂流程,工程师再把它翻译成确定性软件,来来回回,效率很低。
于是他们换了一种思路:
为什么不能让财务团队直接用自然语言表达工作流,让 Agent 去调用必要的数据和工具?
这一步很重要。
因为很多企业做 AI,第一反应是找一个工具,做一个试点,证明某个点能不能提效。YC 这个案例不同,它不是从“员工怎么用 AI”开始,而是从“组织里的工作如何被 AI 接住”开始。
这就是本文的第一个判断:
AI-Native 组织不是个人效率工具的集合,而是一套让 Agent 能进入组织运转的基础设施。
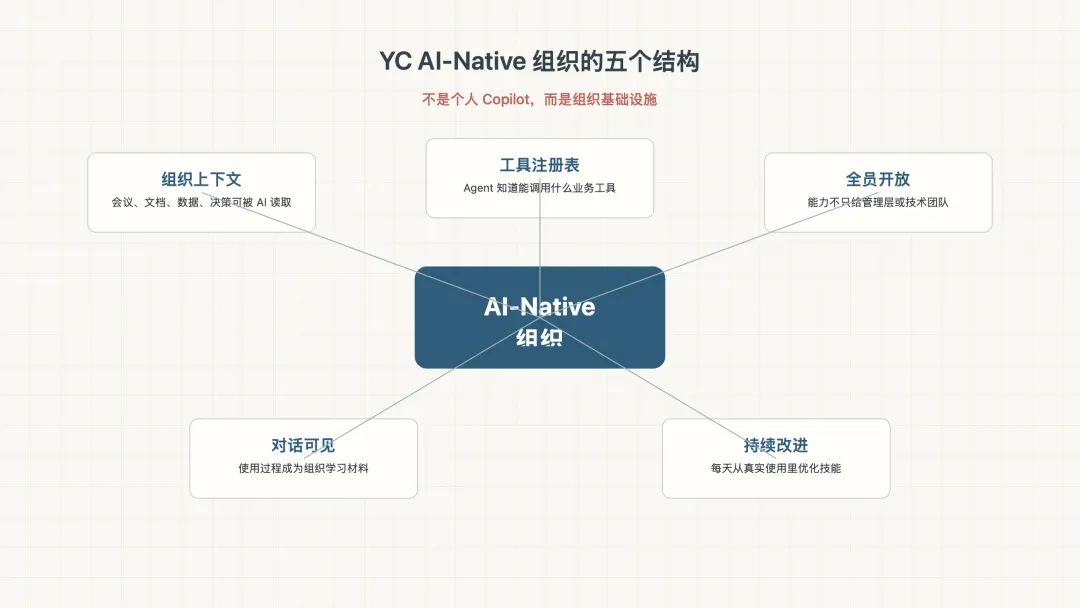
如果用一句话概括,YC 的 AI-Native 组织是:
把 AI 放在组织运行层,而不是只放在个人任务层。
普通 Copilot 式用法,是一个人拿 AI 写邮件、写代码、总结资料、生成文案。它当然有价值,但流程、判断、知识和经验,大部分仍然留在人的脑子里。
YC 的做法更进一步。
它把组织里的会议记录、Agent 对话、决策文档、业务数据、工作过程,都当成 Agent 可以学习和调用的原材料。它不是只让 AI 帮某个人完成一个任务,而是让 AI 逐步理解这个组织如何运转。
这背后有几个组成部分。
第一,组织上下文被系统性记录。
包括会议、对话、文档、数据库、CRM 记录、内部流程和工作产物。没有这些上下文,Agent 只能回答通用问题;有了这些上下文,Agent 才可能回答“我们公司这件事应该怎么做”。
第二,Agent 可以调用真实业务工具。
YC 建了工具注册表,也就是 tool registry,把各团队构建的业务工具集中管理。Agent 不只是聊天,而是可以管理 office hours、处理财务动作、查询内部数据、支持活动管理。
第三,AI 能力向组织成员开放。
YC 强调 Egalitarian,也就是平等主义。AI 能力不是只给领导层,也不是只给工程师,而是尽量让每个人都能使用。
第四,Agent 使用过程默认可见。
原文提到,YC 的 Agent 对话会广播到内部 Slack 频道,全职员工可以看到。这带来两个结果:大家能从彼此的使用方式里学习;同时,可见性本身也形成一种社会性约束。
第五,组织能力可以持续自我改进。
YC 的 Dream Cycle 会在晚上读取当天员工的 Agent 对话,寻找哪些地方可以做得更好,再改进相关技能。一个典型例子是“两句话描述”这个技能,它从合伙人真实辅导创始人的会议转录里学习,最后效果超过任何一个人单独完成的水平。
所以,YC 的 AI-Native 组织不是一个工具清单。
它是一套循环:
员工使用 Agent,产生工作过程;工作过程被记录;记录变成组织上下文;上下文被用来改进技能;技能再反过来提高下一轮工作质量。
这个循环一旦跑起来,AI 就不再只是个人助手,而开始变成组织学习系统。
把这套做法拆开看,YC 至少做了五件事。
第一,把重要上下文放到一个地方。
原文里有个很重要的背景:YC 很多自研软件都跑在同一个 Postgres 数据库上。公司、创始人、财务交易、内部 CRM 笔记,都在一个地方。
这给 Agent 带来了很强的上下文优势。
当员工问“过去几个 batch 里投了哪些太空相关公司”这类问题时,Agent 不是凭空猜,而是可以在统一数据和业务语义上工作。
对大多数企业来说,这一点很难照搬。因为企业数据往往散在 CRM、ERP、飞书、企微、表格、邮件、客服系统和各种 SaaS 里。
但方向是一样的:
如果组织上下文长期分散,Agent 就只能停留在外围;如果企业能逐步把关键上下文整理成 AI 可访问、可检索、可理解的结构,Agent 才有机会进入业务。
第二,建立工具注册表。
工具注册表的价值,不是“工具数量多”,而是给 Agent 一张组织能力地图。
Agent 接到任务后,需要知道自己能调用什么、不能调用什么、哪个工具适合哪个场景、权限边界在哪里。
YC 一开始只有大约 20 个工具,后来每遇到一个可以被 Agent 改善的工作场景,就增加一个工具,最后超过 350 个。
对企业来说,这个启发非常直接:
如果没有工具注册表,Agent 很容易变成一个会聊天的入口;有了工具注册表,它才可能进入真实工作流。
第三,先开放只读能力,再逐步进入流程。
YC 早期一个关键能力,是让 Agent 执行只读 SQL 查询。这个动作看似简单,却让非技术人员可以直接问业务问题。
这说明企业构建 AI-Native 组织,不一定第一步就做高风险自动执行。
更稳的方式,是先开放低风险、可审计、只读型能力,比如知识查询、数据分析、会议总结、流程问答、历史案例检索。
等组织熟悉之后,再逐步开放草稿生成、流程辅助、审批建议、客户跟进建议,最后才考虑带执行权限的 Agent。
第四,让使用过程成为组织学习材料。
YC 把 Agent 对话默认可见,这件事看起来很激进,但它解决了一个很实际的问题:很多人不知道别人怎么用 AI。
如果每个人都在自己的小窗口里用 AI,组织只得到了一堆孤立的个人经验。
如果高价值对话、优秀提示词、典型任务拆解、失败案例和改进方法能被沉淀下来,组织就能把个人经验变成公共能力。
第五,用 Dream Cycle 做持续改进。
这点是 YC 案例里最有想象力的部分。
很多企业今天做 AI 培训,结束以后就结束了。员工学会多少,用成什么样,很难进入组织系统。
YC 的做法是让 Agent 每天从真实使用里学习:哪些问题反复出现,哪些技能不够好,哪些上下文应该提前准备,哪些提示词可以改进。
这意味着 AI-Native 组织不是一次建设完成,而是每天从工作现场里长出来。
很多企业现在已经开始给员工配 AI 工具。
这当然是好事,但它和 AI-Native 组织之间还有一段距离。
Copilot 式提效,核心对象是个人任务。
比如一个销售用 AI 写跟进邮件,一个市场同事用 AI 改文章,一个研发用 AI 补代码,一个 HR 用 AI 总结简历。
这些动作能提高效率,但问题在于:用得好不好,很大程度取决于个人。组织不一定知道谁用得好,也不一定能把好的用法复制给别人。
AI-Native 组织,核心对象是组织能力。
它关心的是:
•组织的关键上下文是否能被 AI 使用?
•业务工具是否能被 Agent 调用?
•高价值用法是否能沉淀为模板、技能和流程?
•员工的 AI 使用过程是否能反过来改进组织知识?
•权限、审计和责任边界是否跟得上?
所以,Copilot 式提效更像“每个人多了一把工具”。
AI-Native 组织更像“公司多了一套学习和执行系统”。
这两者的差别,不在模型,而在组织设计。
很多企业推进 AI 时,会自然进入工具采购逻辑:
选供应商、看 demo、买账号、做培训、找几个部门试点。
这套流程没有错,但如果只停在这里,AI 很容易被限制在个人效率层。
因为真正影响企业 AI 落地的,不只是工具是否好用,而是组织是否准备好了几个条件。
第一,业务上下文是否可用。
如果知识散在个人电脑、聊天记录和老员工脑子里,Agent 很难真的懂业务。
第二,系统和工具是否可调用。
如果 Agent 只能看文档,不能查业务数据,不能进入 CRM、ERP、工单、合同、项目系统,它就很难进入真实流程。
第三,权限边界是否重新设计。
Agent 需要上下文,但企业不能无边界开放。哪些数据可读,哪些动作可写,哪些结果需要人工确认,哪些行为必须留痕,这些都要提前设计。
第四,组织是否愿意让经验公开沉淀。
很多企业不是没有经验,而是经验太分散。销售高手的客户判断、交付经理的项目推进、财务同事的异常处理、客服主管的升级判断,都可能只存在个人身上。
如果这些经验不能被记录、提炼和复用,AI 很难真正变成组织能力。
所以我的判断是:
企业 AI 落地进入深水区以后,最重要的工作不是继续买更多工具,而是改造组织的上下文、工具、权限和学习机制。
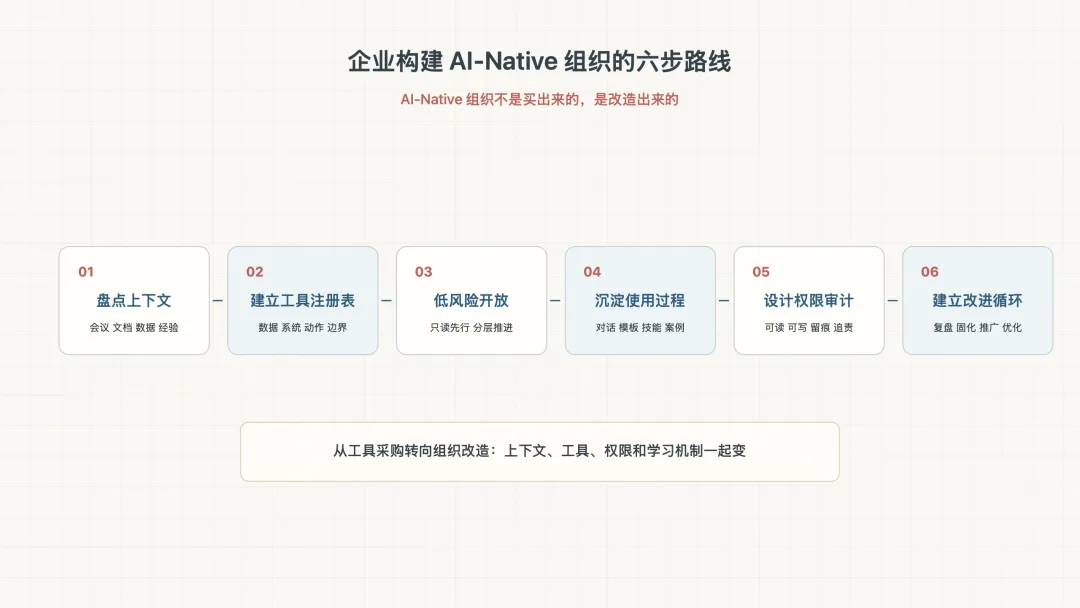
企业当然不能照搬 YC。
YC 是高信任、小团队、目标一致、上下文相对集中的创业组织。大型企业有更多层级、更多监管要求、更多系统边界,也有更多数据安全和责任问题。
但 YC 的原则可以借鉴。
如果一家企业想构建自己的 AI-Native 组织,可以从六步开始。
第一步,盘点组织上下文。
先不要急着买平台,而是先问:
•哪些会议值得记录?
•哪些业务文档值得结构化?
•哪些流程经验只存在老员工脑子里?
•哪些数据分散在 CRM、ERP、客服系统、项目系统和表格里?
•哪些决策过程今天没有被沉淀?
AI-Native 的第一步,是让组织经验可以被 AI 读取。
第二步,建立内部工具注册表。
企业要逐步梳理:
•Agent 能查哪些数据?
•能调用哪些系统?
•能执行哪些动作?
•哪些动作只读?
•哪些动作需要审批?
•哪些动作禁止自动执行?
这就是企业自己的 tool registry。没有它,Agent 只是一个通用助手;有了它,Agent 才开始拥有企业能力。
第三步,从低风险场景分层开放。
不要一上来就让 Agent 自动改客户资料、自动发合同、自动操作财务系统。
更稳的路径是:
先做知识查询、会议总结、制度问答、历史案例检索。
再做只读数据分析、客户画像辅助、销售机会梳理、工单原因归类。
然后做草稿生成、方案建议、流程提醒、审批材料准备。
最后才做带执行权限的 Agent,并且必须配套审批、留痕、回滚和责任边界。
第四步,把员工使用 AI 的过程沉淀下来。
企业不能只统计员工用了多少次 AI。
更应该看:
•好的提示词有没有沉淀?
•好的流程有没有变成模板?
•好的 Agent 对话有没有复用?
•典型失败有没有被复盘?
•一线经验有没有进入知识库?
AI-Native 组织的关键,不是某个人很会用 AI,而是他的用法能不能变成组织能力。
第五步,重新设计权限、审计和责任边界。
AI-Native 不等于无边界开放。
企业必须明确:
•谁可以访问什么上下文?
•Agent 可以执行到哪一步?
•哪些动作必须人来确认?
•出错后责任怎么追溯?
•哪些数据永远不能进入外部模型或第三方工具?
成熟的 AI-Native 组织,不是没有控制,而是把控制机制设计进 Agent 工作流。
第六步,建立组织级 AI 改进循环。
这一步对应 YC 的 Dream Cycle。
企业不一定要一开始就做自动化夜间学习,但至少要建立一个简单循环:
员工使用 AI,产生对话和结果。
团队复盘高价值用法和常见失败。
把好用法固化成模板、工具或技能。
把新技能推广给更多人。
再从下一轮使用中继续优化。
这个循环跑起来以后,AI 才不是一次性项目,而是组织能力的持续建设。
YC 案例很有启发,但也要看清边界。
可以学的,是它的组织设计原则。
比如:让上下文可用,让工具可调用,让能力向更多人开放,让使用过程可沉淀,让组织能力持续改进。
不能照搬的,是它的开放强度。
YC 可以让所有 Agent 对话默认对全职员工可见,是因为它的组织规模、信任结构和业务边界适合这样做。
大型企业不一定能这样做,也不应该直接这样做。
更现实的方式,是分层开放:
公开低敏知识和通用流程。
部门内开放业务场景和项目经验。
跨部门开放经过脱敏和授权的案例。
高敏数据保留严格权限和审计。
这样既能学习 YC 的组织思路,又不会把风险控制丢掉。
还有一点也要提醒。
YC 的优势来自它相对集中的数据和自研系统。很多企业的数据基础没有这么好,系统也更分散。所以企业第一阶段不必追求“全组织 AI-Native”,而应该先选一个业务域做小闭环。
比如销售、客服、研发、交付、财务、人力,都可以选一个高频、低风险、可复盘的流程开始。
先把一个流程里的上下文、工具、权限和复盘机制跑通,再扩展到更多场景。
这比一上来喊“全员 AI-Native”要可靠得多。
如果把今天这篇文章沉淀成一个长期可用的判断表,我建议企业先问 6 个问题。
第一,组织上下文在哪里?
哪些会议、文档、数据、案例、流程、决策和经验,已经可以被 AI 读取?哪些还散在个人手里?
第二,Agent 能调用哪些真实工具?
它只能聊天,还是能查数据、读系统、生成材料、触发流程、提交审批、回写结果?
第三,AI 能力开放给谁?
是少数管理者、技术团队、试点小组,还是按风险分层逐步开放给更多业务人员?
第四,员工使用 AI 的经验如何沉淀?
好的对话、提示词、流程模板、失败案例和业务判断,能不能变成组织资产?
第五,权限、审计和责任边界是否清楚?
哪些数据可读,哪些动作可写,哪些必须人工确认,哪些需要留痕,出错后谁负责?
第六,组织有没有持续改进循环?
AI 使用之后,企业有没有复盘、提炼、固化、推广和再优化的机制?
这 6 个问题,比“买哪个 Agent 平台”更靠近企业 AI 落地的本质。
因为 AI-Native 组织不是买出来的,是改造出来的。
YC 这个案例给企业最大的提醒,不是“赶紧做 350 个工具”,也不是“所有对话都应该公开”。
它真正说明的是:
当 Agent 真正进入组织,企业要改造的不只是工具层,而是组织的上下文层、工具层、权限层和学习层。
企业 AI 落地真正进入深水区以后,重点会从工具采购转向组织改造。
这件事听起来没有模型发布那么热闹,但它更接近企业负责人接下来要面对的真实问题:
你的组织经验能不能被 AI 读取?
你的业务工具能不能被 Agent 调用?
你的员工用 AI 产生的好方法,能不能变成组织能力?
如果这三个问题没有答案,再多工具也只是分散的个人提效。
如果这三个问题开始有答案,AI 才可能从一个个助手,变成企业真正的生产力系统。
