 夜雨聆风
夜雨聆风对于科研人员来说,阅读英文论文早已成为日常工作的一部分。
然而很多人都有类似经历:
好不容易找到一篇有价值的论文,上传到翻译工具后,却发现:
数学公式变成乱码 表格排版完全错乱 图片和正文对应不上 双栏论文变成一大段文字 原文和译文无法对照阅读
结果虽然完成了翻译,但阅读体验甚至比直接看英文还痛苦。
为什么会这样?有没有办法在翻译论文的同时保留原始格式?
本文结合实际案例,分析论文翻译中最常见的问题以及解决方案。
为什么论文翻译比普通文档更难?
很多翻译工具最初都是为普通文档设计的。
而学术论文往往包含:
双栏排版 数学公式 图表 表格 参考文献 图片说明
这些内容并不仅仅是文字。例如下面这类机器学习论文页面:
左右双栏布局 多个公式编号 实验结果表格 图像示意图
如果翻译工具只关注文字内容,就很容易破坏原有结构。因此很多用户会发现:翻译准确度可能还不错,但版面已经无法阅读。
问题一:公式乱码
这是论文翻译中最常见的问题之一。
例如原文中的数学公式或复杂的 LaTeX 表达式。
部分翻译工具会:
删除公式 错误识别符号 将公式当成普通文本翻译
最终导致公式无法正常显示。
对于机器学习、数学、物理等领域的论文来说,这种问题几乎会直接影响阅读。
解决方法
选择能够识别数学公式结构的专业论文翻译工具。
理想情况下:
公式保持原样 编号保持一致 正文引用关系不变
这样读者才能准确理解论文内容。
问题二:图表位置错乱
很多论文的关键信息都藏在图表里。
例如:
Ablation Study Benchmark结果 模型结构图
然而部分翻译工具在处理PDF时会出现:
图片漂移 图表丢失 图文顺序混乱
导致读者需要不断切换原文和译文。
这会大幅增加阅读成本。
问题三:双栏排版被破坏
绝大多数顶会论文采用双栏布局。
例如:
NeurIPS ICML CVPR ACL
如果翻译后直接转换成长文本:原本连续的阅读逻辑就会被打断。尤其是跨栏图表附近,问题更明显。
因此对于学术场景来说:保持论文原始阅读结构往往比单纯翻译更重要。
问题四:原文与译文无法对应
很多翻译工具生成的是纯文本结果。当你阅读到某一段内容时:
无法快速定位对应原文。于是不得不来回切换窗口。对于长论文来说非常低效。
如何选择适合科研场景的论文翻译工具?
对于科研人员来说,一个优秀的论文翻译工具至少应该满足:
✓ 翻译准确
✓ 保留公式
✓ 保留图表
✓ 保留排版
✓ 支持中英对照
✓ 支持长论文阅读
其中最容易被忽略的一点其实是:
排版还原能力。
因为阅读论文不仅是在看文字。更是在理解:
图表 公式 数据 方法结构
这些信息之间的关系。
EasyReader如何解决这些问题?
EasyReader 专门针对学术论文场景进行了优化。
在翻译过程中:
保留论文原始版面结构 支持双栏排版还原 保持公式和编号对应关系 支持图表位置还原 提供中英对照阅读模式
对于包含大量公式、图表和实验结果的论文,阅读体验更接近原始PDF。
除了翻译之外,还支持:
AI论文导读 思维导图生成 表格提取 公式转换LaTeX 多平台学术检索
帮助研究人员更高效地完成文献阅读。
Easyreader的一些实际截图
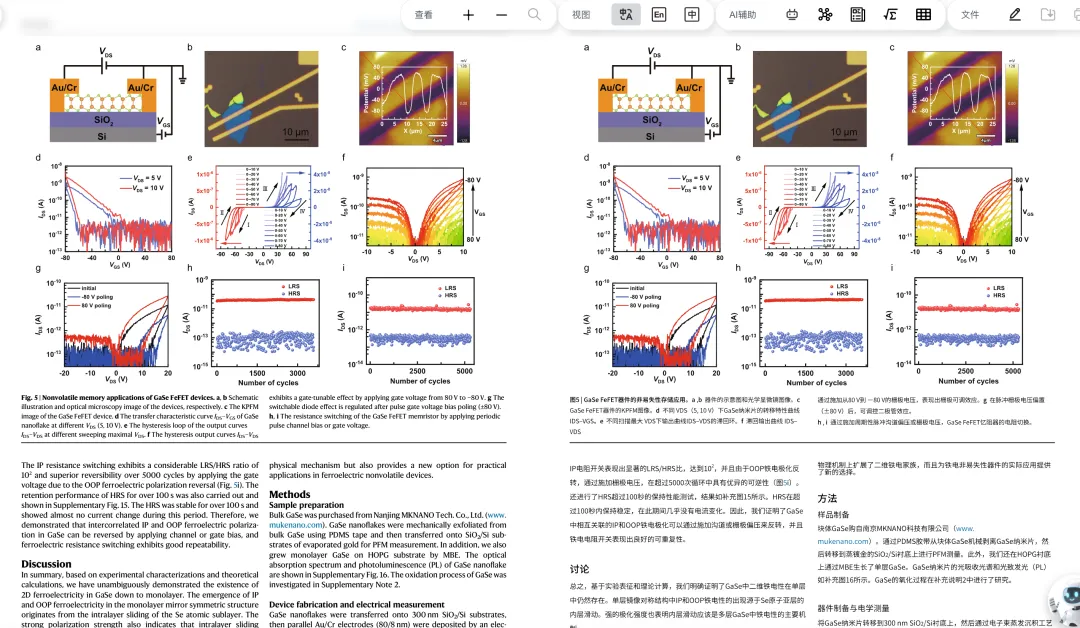
图1 图表与双栏

图2 复杂公式
总结
很多人以为论文翻译最大的挑战是语言。
实际上在科研场景下:
排版、公式、图表和结构往往同样重要。
如果翻译后的论文失去了原有结构,
即使语言准确,阅读效率也会大打折扣。
因此在选择论文翻译工具时,除了关注翻译质量之外,也应该重点关注:
是否保留排版 是否支持公式 是否支持图表 是否支持对照阅读
只有这样,翻译才能真正帮助理解论文,而不是增加新的阅读负担。
