 夜雨聆风
夜雨聆风PART 01
✅ 多文档理解:一次上传50份PDF,AI能跨文档关联信息
✅ 自然语言提问:不用记关键词,直接问"去年的市场规模是多少"
✅ 引用溯源:每个回答都标注来源页码,不用担心AI瞎编
| NotebookLM | 跨文档AI问答+引用溯源 | 海量PDF资料管理 |

PART 02
《高质量数据集建设规划》
《数据要素市场化配置改革方案》
《专精特新企业认定标准》
一次性上传多份PDF到NotebookLM(30秒) 直接问:"这几份文件对'数据集建设'的要求有什么不同?" AI给出对比表格,并标注每个要点来自哪份文件的第几页
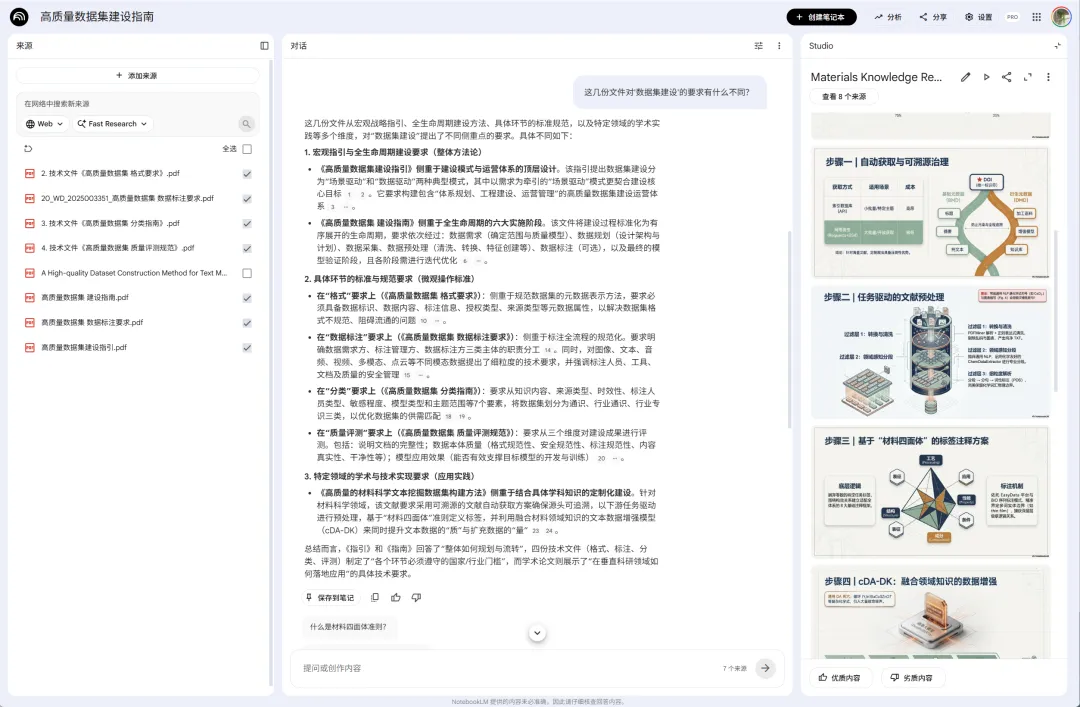
上传所有报告(支持最多50个文档/笔记本) 问:"这些报告里提到的2025年市场规模分别是多少?请列表对比。" AI自动提取所有数据,生成对比表,并标注数据来源
✓ 不用自己翻页找数据
✓ 不用担心遗漏某份报告
✓ 所有数据都有出处,可追溯
PART 03
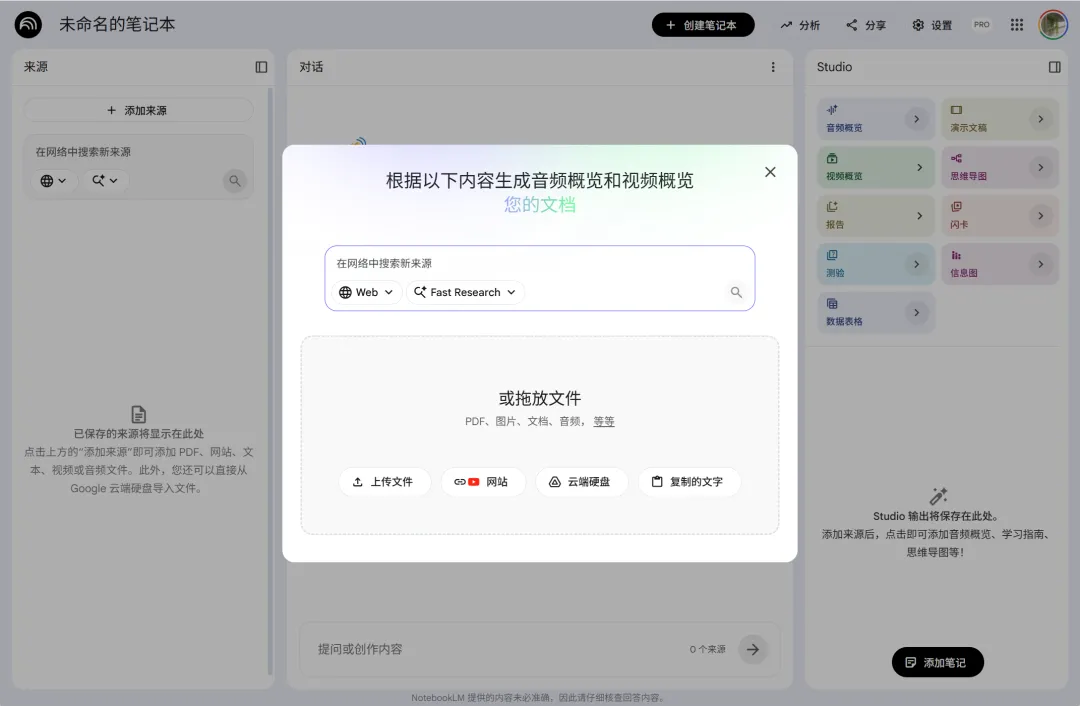
打开 notebooklm.google.com 点击"Create new notebook" 给笔记本命名(建议按项目/主题命名)
✅ 推荐:按项目/主题分类("政策申报资料""竞品分析报告""项目会议纪要")
❌ 避免:泛化命名("工作文档""学习资料")
PDF文档(最常用)
Google Docs / Google Slides
网页链接(自动抓取内容)
纯文本 / Markdown
单个笔记本最多50个文档
单个文档最大500,000字(约300页PDF)
一个项目建一个笔记本(不要把所有资料塞进一个笔记本)
文件上传后,给每个文档加个简短说明
"有什么信息?"(太宽泛,AI不知道你要什么)
"市场规模"(只给关键词,AI不知道你想要什么维度)
"这些报告里提到的2024年市场规模分别是多少?请列表对比。"
"关于XX功能的讨论结论是什么?请按时间排序。"
"这3份政策文件对'数据集建设'的要求有什么不同?"
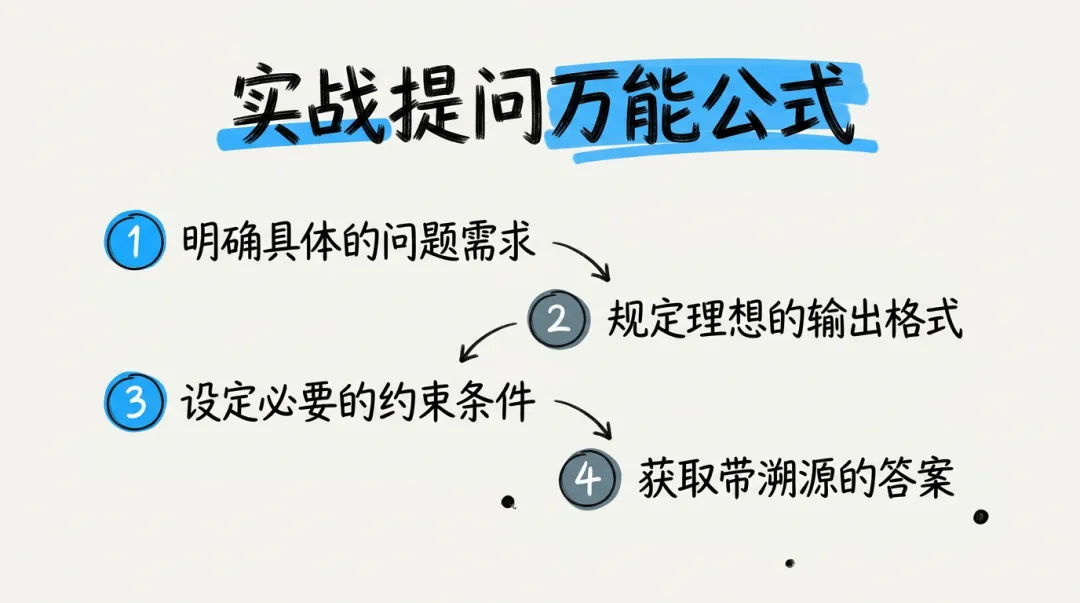
[具体问题] + [输出格式] + [约束条件]示例:问题:"这些报告里的市场规模数据"格式:"请列表对比"约束:"只要2024年的数据"完整提问:"这些报告里提到的2024年市场规模分别是多少?请列表对比。"跨文档对比:"对比这3份文件对XX的定义,有什么区别?" 时间线梳理:"按时间顺序,列出这个项目的关键决策点。" 主题提炼:"这些会议记录里,反复讨论的核心问题是什么?"
看AI的回答 点击引用编号,跳转到原文 确认AI的理解是否准确
关键数据(市场规模、金额、日期):必须点开原文验证
观点总结类("核心问题是XX"):快速扫一眼引用来源即可
PART 04
优先上传"文字版PDF"(不是扫描件)
如果是扫描PDF,先用OCR工具转成文字版
一个笔记本控制在20-30份文档以内
按项目/主题拆分成多个笔记本
"政策申报"笔记本:只放相关政策文件(10份)
"行业报告"笔记本:只放2024年报告(25份)
"项目会议"笔记本:只放近3个月的会议纪要(15份)
NotebookLM的定位是"研究助手",不是"内容生成器"
AI的回答是用来"快速定位信息"的,不是用来"一键生成报告"的
正确用法:AI帮你找到数据和观点→你自己整理成文档
PART 05
| NotebookLM | ||
| Obsidian | ||
| Claude/Gemini | ||
| Excel |

NotebookLM:上传政策文件,提问"申报要求有哪些?" Claude:基于NotebookLM提取的要点,生成申报材料初稿 Obsidian:把申报材料保存为笔记,建立和其他项目的关联 Excel:整理申报材料需要的数据表格
PART 06
第1周:建立笔记本体系
第2周:固定使用场景
第3-4周:优化工作流
✓ 找资料的时间从30分钟降到5分钟
✓ 不再因为"记不住在哪份报告里"而焦虑
✓ 信息整理效率提升3倍以上
PART 07
✓ 把你从"找资料"这个低价值工作中解放出来
✓ 让你把时间花在"思考"和"创造"上
✓ 让你的知识库真正"活"起来,而不是堆在文件夹里吃灰
每周要看10份以上报告的知识工作者
被100份PDF淹没的产品经理/研究员
想搭建个人知识管理系统的效率探索者
PART 08
ChatGPT:单次对话最多上传几个文件,换个对话就要重新上传
NotebookLM:建立持久的笔记本,文档一直保存,随时可以回来继续提问
