 夜雨聆风
夜雨聆风一、开篇:绝大多数人在用 AI 抽奖
不少人使用 AI 的固有模式,就是抛出问题坐等回复,结果达不到预期就反复重发提问。看似在高效借力人工智能,本质却是漫无目的地碰运气。
跳过需求拆解、输出规范、成品验收三大关键环节,只剩等待 AI 生成内容这一步,算不上合理使用工具,纯属被动碰结果。

我的实操思路截然相反:AI 不能简单视作随手调用的工具,更无法全权顶替员工,它只是整套自研协作体系里的组成模块。
系统架构不完善,反复打磨提示词也很难拿到优质成果;协作逻辑搭建到位后,内容优劣不再由大模型单方面决定,核心取决于使用者拆分问题的精细度、落地标准的完善度、关键节点的人工把控。
本文聚焦落地方法论:理清人与 AI 的协作逻辑,抛开低效的 Prompt 堆砌、纯托管 AI 干活的浅层用法,从需求拆分、方案规划、落地执行到成果验收,明确人和 AI 各自的分工边界。
依照任务难易划分三类协作模式,从脑力思辨、定向落地再到完整项目操盘,不同阶段人的分工随之变化,但全程不可或缺。
核心计算公式:最终价值=人的统筹能力 ×(大模型能力+算力消耗)
人机协作不是分段交接任务,全流程同步配合:拆分需求由人主控,搭建框架由人定调,落地中人工实时反馈纠错,收尾验收由人最终敲定。
二、通用逻辑:全阶段适用的多模型交叉校验
在三类协作场景里共用一套方法论:多模型交叉验证。并非挑选单一顶尖模型包揽全部工作,而是同一需求分发多款不同特性的 AI,依托各自优势产出差异化思路,再由使用者汇总甄别。
DeepSeek 擅长梳理逻辑架构,Claude 擅长挖掘隐藏漏洞,豆包优化文案表达与落地体验,智谱侧重推敲底层初衷。四款产品从不同维度查漏补缺,打破个人思维盲区。
常规用法是选定一款 AI 索取标准答案,高效用法是多模型多角度剖析问题,倒逼使用者完善思考。
该逻辑贯穿下面三层协作,仅落地形式随场景变化;层级越复杂,前期需要投入的人工规划越多:L1 仅需精准提问,L3 要提前拆解全链路、敲定整体框架。
三、第一层:思辨探索,AI 充当多角度智囊

本阶段侧重深度思考,没有实物产出。我常会在空闲时间抛出开放性议题,不带预设答案,借助多模型碰撞完善认知。
举例:曾经探究大模型依托统计学原理,为何能带来 “具备自主理解能力” 的观感。
不提前敲定内心答案,才是深度思考的起点。多数人提问 AI 时早已怀揣既定结论,咨询只是寻求观点附和,很难拓展认知。
把问题同步分发四款模型:
DeepSeek 从数理逻辑解释感知来源,
Claude 反向质疑提问的真实诉求,
豆包捕捉潜藏的内心焦虑,
智谱挖掘提问背后认知方向的偏移。
整合多方观点后,逐步梳理完整逻辑链:大模型依托统计运算→AI 核心作用是节约人力脑力→富余精力如何分配→人类注意力资源稀缺,分配失误就会产生损耗。
顺势提炼落地逻辑:成事=资源精准分配 ×AI 降本增效 × 价值精准匹配。
单一 AI 给出的标准答案容易固化思维,多视角碰撞才能持续深挖。
整层逻辑里,人全程掌握主动权:自主拟定问题、整合多方观点、汇总落地结论,AI 只负责补充自身视角,填补个人想不到的思路。
不同模型观点或是互补融合,或是相悖佐证,即便部分观点不合理,也能反向夯实自身原有认知。
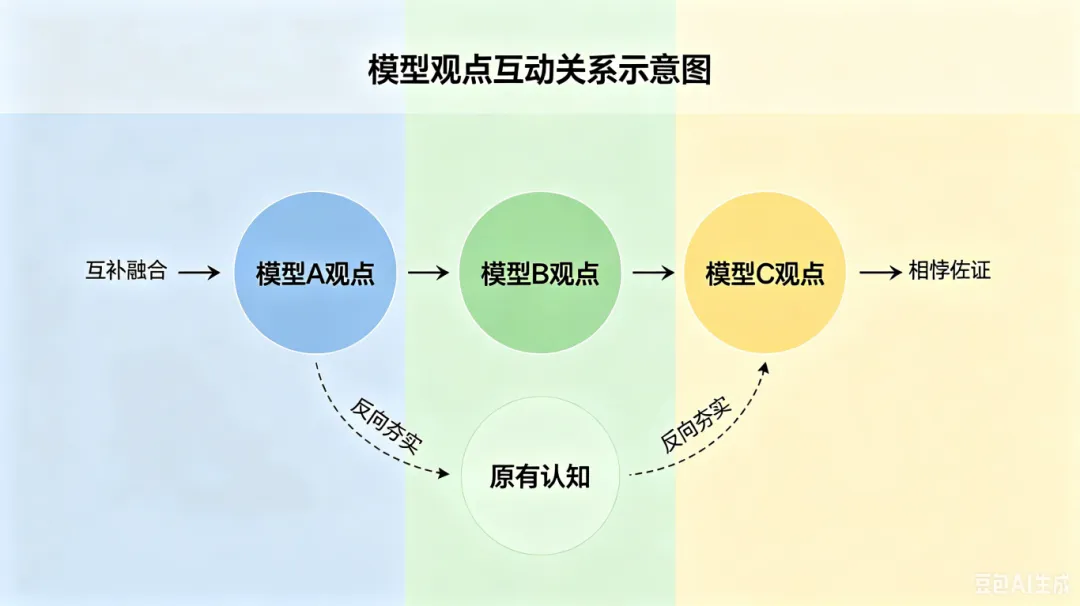
本层关键:杜绝 AI 代脑思考,借助多元视角完善自身思维。
四、第二层:定向落地,AI 变身专职协作者
低效做法:单次提问 “帮忙撰写一篇全屋定制小红书文案”,AI 随机出稿,每次风格、选题飘忽不定,内容不成体系,零散产出毫无沉淀。
标准化落地思路是搭建内容生产流水线:
第一步:确立标准,搭建专属参考库
优先划定合格内容细则:文案文风、选题方向、爆款结构、配图规范全部由人落地定稿,依托行业经验制定规则,再汇总存入知识库。
这套规范用来约束 AI 输出范围,避免内容天马行空,划定边界之后,生成内容自然贴合需求。
第二步:串联全链路生产工序
选题:AI 罗列备选方向→人工筛选定稿;
文案:豆包初稿撰写→智谱排查内容瑕疵→人工给出修改意见;
配图:AI 提供构图思路→人工敲定最终方案;
定稿:对照既定标准逐项核查→人工终审放行。
全流程人工把控关键决策,AI 负责落地执行,相当于加速生产的配件,内容方向盘始终在使用者手中。
第三步:双重交叉校验
内容生成阶段:一款 AI 撰稿、另一款 AI 审校,撰写和审核分离,规避自查盲区;
流程搭建阶段:把整套流水线方案交由多模型复盘DeepSeek 排查流程断层,Claude 挖掘隐藏隐患,持续优化工序。
对比第一层:L1 无标准答案、发散拓维;L2 锁定落地目标、收敛内容,依托多模型提升成品精准度。
简言之,第一层换取多元思路,第二层换取落地精度。
五、第三层:全案操盘,系统化落地复杂项目
第三层不再是单一选题或零散任务,而是由多个关联子项组成的整套项目,需要拆分优先级、梳理依存关系、分步落地执行。
踩坑误区:把整套项目打包成一句话丢给 AI,等待一份万能执行方案。AI 给出的通用方案看似完整,却脱离自身资源、行业现状,落地可行性极低。
本层谨记:不要被排版工整的通用方案误导。
整套协作分成五大环节:
5.1 拆解项目,拆分细分任务
将大型项目拆解成边界清晰的小任务,AI 辅助梳理逻辑、查漏缺项,但拆分细度、任务边界由人决定,只有操盘者清楚自身资源与业务痛点。
比如搭建小红书获客体系,拆分为选题规划、文案量产、封面规范、发布排期、数据复盘五大模块,每个模块目标清晰、验收有据,落地自然有据可循;笼统提问很难落地实操。
5.2 搭建整体落地框架
拆解和框架规划同步推进,拆分逻辑决定落地顺序。敲定各子项先后顺序、资源配比,标注哪些环节需要多模型校验、哪些可简化处理,同步设置各节点验收门槛。
框架无法交由 AI 定制,需要结合业务风险、核心需求人工敲定,AI 仅负责校验框架逻辑漏洞。
5.3 分模块落地执行
进入实操阶段,人的身份从架构师转为项目把控者:单个子项 AI 出初稿→跨模型交叉核验→人工判定效果、下发修改指令→AI 迭代优化→终审通过。
全程人工把控方向,AI 负责落地执行,避免脱离实际盲目生产。
5.4 逐项验收成果
依照前期定制的验收标准核查成品,AI 辅助排查显性问题,最终合格与否由人裁决,验收标准依托行业经验定制,无法由人工智能替代。
5.5 沉淀知识库与项目档案
知识库沉淀各类规范、模板、验收标准,一次搭建反复复用;项目档案留存各版本稿件、修改记录、校验结果,方便后续复盘优化。
5.6 多层交叉校验落地
拆解环节:多模型从逻辑、漏洞、诉求多角度辅助拆分,人工汇总决策;
执行环节:生成、审核由不同模型分开负责,规避自审缺陷,所有修改指令由人下达。
三层整体递进总结
L1 发散思考、拓展认知;
L2 定向收敛、量产内容;
L3 系统布局、规模化落地。前期投入的规划越多,后续落地越省心。
六、结语
最终价值=人的统筹能力 ×(大模型能力+算力消耗)
全文核心落脚在放大 “人” 的乘数价值:需求拆分、框架搭建、过程管控、收尾验收均以人为主导,多模型全流程辅助校验。
合理的人机协作不是抢夺 AI 的决策权,而是依靠多元参考完善自身决策。你定义问题的深度,直接决定 AI 产出内容的上限。
人工智能不会淘汰人类,但只会无脑丢问题、坐等现成答案的人,终将被高效用好 AI 的同行替代。


