 夜雨聆风
夜雨聆风nano-vllm 用千行代码拆解 vLLM 核心,是读懂大模型推理最快的捷径。
1. 介绍
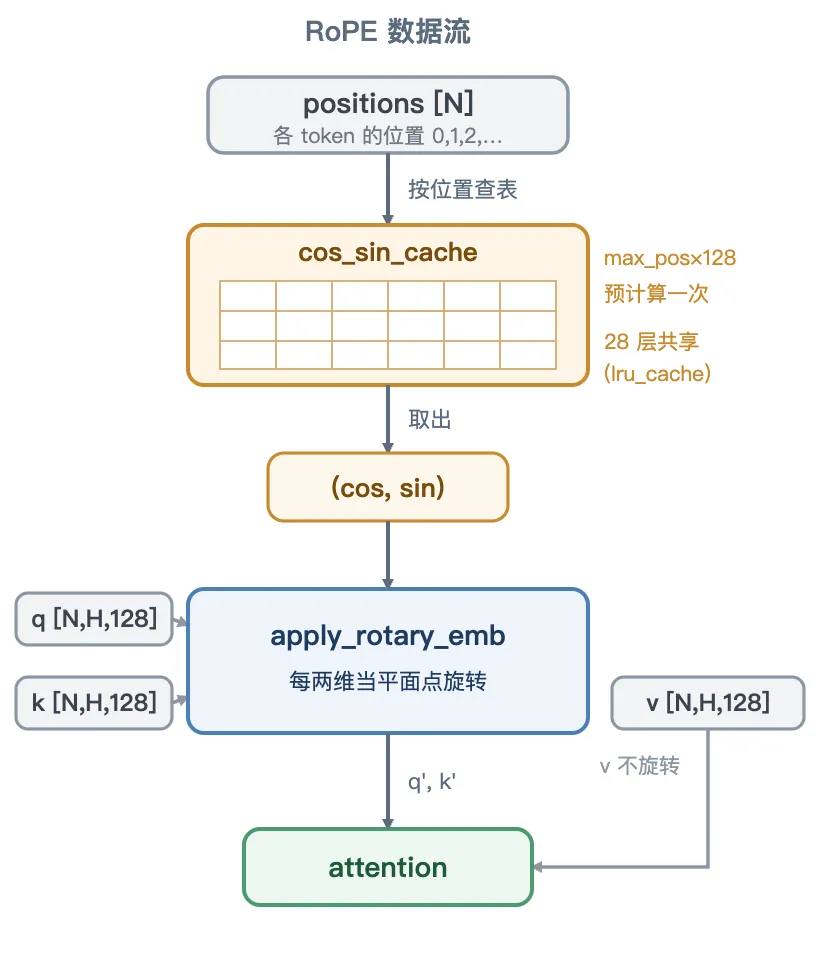
在注意力子层 self_attn 里,算出 q、k 之后、做注意力之前,有一步 self.rotary_emb(positions, q, k)——按每个 token 所在的位置,把它的 q、k 向量旋转一下。这就是 RoPE(旋转位置编码)。
本篇讲清 RoPE 如何用旋转把位置编进 q、k,并实现。
2. 总览
RoPE 在 nano-vllm 里就一个文件 rotary_embedding.py:一个 RotaryEmbedding 类 + 一个 get_rope 工厂。数据流很短——拿 positions(每个 token 在第几位)去查一张预先算好的 cos/sin 表,用查到的 cos/sin 把 q、k 旋转,然后计算注意力。
Qwen3-0.6B 里 RoPE 的关键配置:
head_dim | ||
rotary_dim | ||
rope_theta | ||
max_position_embeddings | ||
num_hidden_layers |
本篇介绍:
• 原理(第 3 章):按位置把 q、k 两两配对旋转,旋转后内积只依赖相对距离;转速 inv_freq从快到慢排一串,避免位置混淆。• 预计算(第 4 章):cos/sin 只由「位置 × 频率」决定,与 q/k 无关,一次算好存表。 • 旋转(第 5 章):查表取 cos/sin,把 q、k 前后两半配对、当平面点旋转。 • 跨层复用(第 6 章): get_rope+lru_cache让 28 层拿到同一个实例、共享同一张表。
3. 原理
一句话:RoPE 用「按位置旋转 Q/K 向量」来编码位置——两个向量做点积时旋转角度相减,注意力分数天然只依赖相对距离。优雅、零参数、自带远程衰减,是 LLaMA / Qwen / GLM / PaLM 等主流大模型的标配。
它要解决什么问题
Transformer 的 self-attention 本质上在算「每个 token 该关注谁」,但它有个天生的毛病:看不见顺序。把句子里的词打乱、token 集合不变,结果一样。「我爱你」和「你爱我」在纯 attention 眼里没区别。所以必须额外把位置信息喂进去。
早期做法是绝对位置编码:给位置 0、1、2… 各准备一个向量,加到 token embedding 上。它有两处弊端:
• 编码的是「你在第几个」这种绝对信息,而 attention 真正在乎的其实是相对距离——形容词在名词前一个位置,这种关系跟它俩在句首还是句尾基本无关; • 「加法」注入比较生硬,换一个没训练过的长度容易乱套。
RoPE(Rotary Position Embedding)换了个思路:不「加」位置,而是「转」位置。
给向量「拧表盘」
把每个 token 的 query / key 向量想象成一根钟表指针,指针方向编码了这个词的语义内容。RoPE 做的事极其简单——根据这个词在句子里的位置,把指针顺时针拧一个角度:位置 0 不拧,位置 1 拧 θ,位置 2 拧 2θ……位置 就拧 。位置越靠后,转得越多。
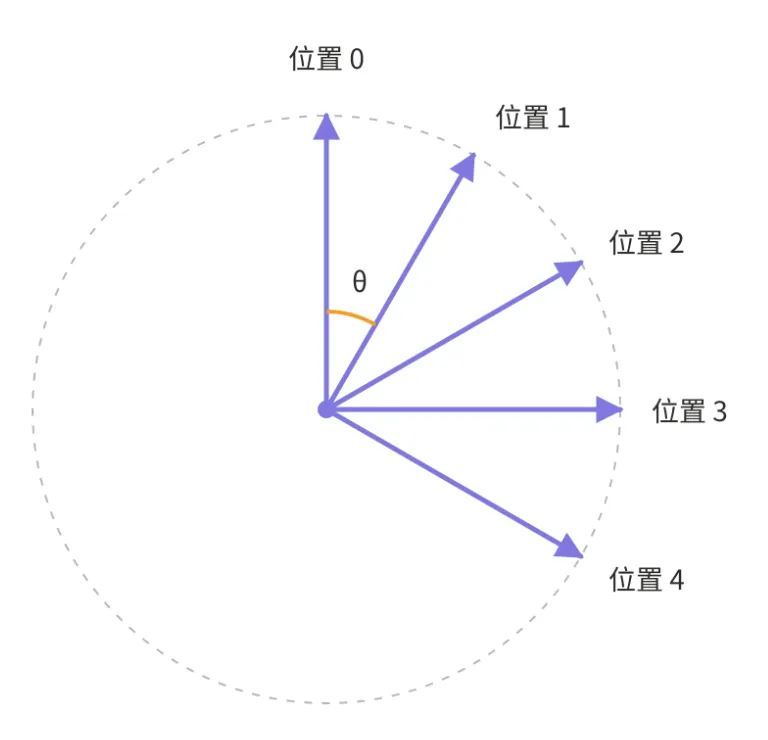
图 1:位置变成旋转角度——同一向量在位置 0,1,2,… 被分别旋转 0, θ, 2θ…,所有箭头落在同一个圆上。
关键点:旋转只改方向、不改长度(图 1 所有箭头都落在同一个圆上)。纯转动、不缩放,所以词本身的内容信息一点没丢,只是被摆到了一个新的朝向上。
相对位置如何自动出现
这是 RoPE 最妙的地方。attention 算分数,本质是算 query 和 key 的点积——可以理解成在量两根指针「合不合拍」:夹角越小越合拍,分数越高。
现在,query 在位置 被拧了 ,key 在位置 被拧了 。当我们量这两根指针的夹角时,两边都转过了,于是夹角只取决于转动量之差:。绝对的转动量被抵消,只剩两个位置的差。
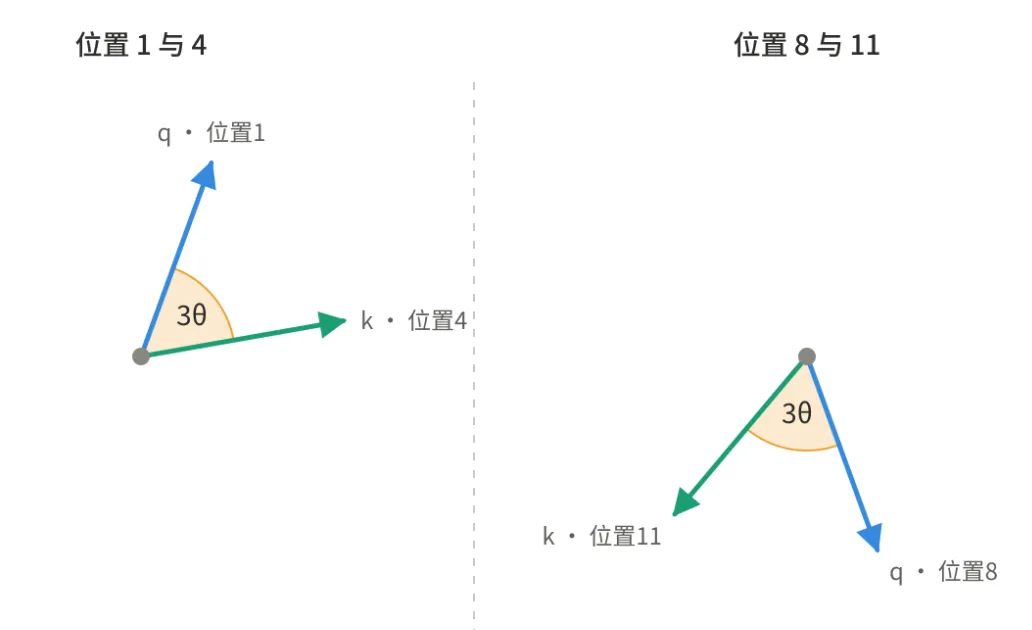
图 2:左边一对词在位置 1 和 4,右边在位置 8 和 11——绝对位置和箭头朝向都不同,但只要间距都是 3,夹角就都等于 3θ,注意力分数也一样。
也就是说:注意力天生就该只关心「隔多远」,而不是「在第几个」。RoPE 不是「教」模型理解相对位置,而是把相对位置直接和注意力融为一体。
多频率:一组转速不同的指针
前面为了讲清楚只用了一根指针。实际上向量是 维的,RoPE 把它两两分成 组,每组是一个 2D 平面、各自独立旋转,而且每组转速(频率)不一样:
第一组转得最快(高频),最后一组转得最慢(低频)。这就像一只钟有秒针、分针、时针。
图 3:三个表盘编码同一个位置 m——高频表盘已转大半圈,低频表盘几乎没动。高频分辨近处,低频覆盖远处。
为什么要多个频率?因为单一转速会「绕圈重复」——转着转着角度回到原点,远处的位置就分不清了。多个不同转速的指针组合起来,就像秒针+分针+时针能唯一确定一个时刻,RoPE 用一整组频率唯一编码每个位置,既能分辨近处的毫厘之差,又能覆盖很长的序列。
另外,如果统一用一个频率,频率大,局部分辨率高但很快绕圈、扛不住长序列;频率小,能管长程但分不清相邻 token。用一整段频率就得到多分辨率编码:高频负责精细局部偏移,低频负责粗粒度长程位置。
数学原理
约定:query、key 记作 ,token 位置记作 ,RoPE 把「位置 处的向量 」映射为 。
二维旋转的定义。 位置 处的 query 定义为把 旋转 :
旋转矩阵有两条性质是后面的支点:
• 正交性:,所以 。 • 可加性:。
核心推导:绝对位置如何消失。 attention 的(softmax 前)打分就是 query 与 key 的内积:
用正交性把转置换成反向旋转,再用可加性合并:
各自的绝对值彻底消失,只剩相对偏移 。这就是图 2「夹角只取决于转动量之差」背后的代数。
一句话:位置编码 = 乘一个单位模长的相位 ,内积时相位相减,自动得到相对位置。
如何分频率
是 head_dim。RoPE 里的 是单个注意力头的维度(head_dim),不是模型隐藏层维度。例如 hidden size 4096、32 个头,则 head_dim = 4096/32 = 128。RoPE 对每个头的 Q、K 各自的这条 128 维向量做旋转,所有头共用同一套 cos/sin 表。
切成 64 个频率。 128 维两两分组 ⇒ 64 个 pair ⇒ 64 个频率:
RoPE 好在哪
• 相对位置:分数天然只依赖 ,符合语言直觉,模型不用费劲去学。 • 零参数:旋转是确定的数学操作,不用训练、不占参数、不需要位置 embedding 表。 • 远程衰减:间距越大注意力倾向越弱,符合语言直觉。 • 易于外推:编码的是相对关系,处理超长序列比绝对编码稳健,便于长上下文扩展(YaRN)。
这也是为什么主流大模型几乎都用 RoPE。
4. cos_sin_cache 预计算
旋转要用的角度,只由「位置 × 频率」决定,跟具体的 q、k 数值无关。所以 RotaryEmbedding.__init__ 在建模型时就把所有位置的 cos、sin 一次算好,拼成一张表存进 buffer;运行时只按位置查表,不再现算。
import torch
from torch import nn
classRotaryEmbedding(nn.Module):
def__init__(self, head_size, rotary_dim, max_position_embeddings, base):
super().__init__()
self.head_size = head_size
assert rotary_dim == head_size # Qwen3:128 维全参与旋转
# ① inv_freq:64 根指针各自的转速(频率)
# 第 i 个 = 1 / base^(2i/d);i 越大转得越慢
inv_freq = 1.0 / (base ** (
torch.arange(0, rotary_dim, 2, dtype=torch.float) / rotary_dim))
# ② 列出所有位置:0, 1, 2, …, max-1
t = torch.arange(max_position_embeddings, dtype=torch.float)
# ③ 外积 = 一张「位置 × 频率」乘法表:
# freqs[位置, 频率] = 位置 × 该频率
# = 这个位置这根指针转过的角度
freqs = torch.einsum("i,j -> ij", t, inv_freq) # [max_pos, 64]
# ④ 旋转要用 cosθ、sinθ(第 5 章会用),先都算好
cos = freqs.cos()
sin = freqs.sin()
# ⑤ 每行拼成 [64 个 cos | 64 个 sin] = 128 个数
# unsqueeze_(1) 插一个长度 1 的维度,
# forward 时会广播(自动复制)到每个 head
cache = torch.cat((cos, sin), dim=-1).unsqueeze_(1) # [max_pos, 1, 128]
# register_buffer:把 cache 挂在模型上、跟随模型加载到 GPU,
# 但它不需要训练的权重,只是一块「只读数据」
# persistent=False:不写进权重文件,用配置随时能重算
self.register_buffer("cos_sin_cache", cache, persistent=False)import math
d = 128# head_dim:一个头有 128 个数
base = 1000000.0# rope_theta:频率总开关
# 同第 3 章公式 1/base^(2i/d):i 越大,频率越小
# (第 3 章讲原理用通用 base=10000;这里是 Qwen3 真实的 100 万)
inv_freq = 1.0 / (base ** (torch.arange(0, d, 2).float() / d))
print("一共几个频率 :", inv_freq.numel()) # 64:128 个数配成 64 对
print("最快(第 0 个):", inv_freq[0].item()) # 1.0
print("最慢(末 1 个):", inv_freq[-1].item()) # ≈ 1.24e-6
# 频率换成「转一圈(2π)要走多少个位置」,看清快慢差多远
# 最快频率=1,所以位置数 = 2π/1 ≈ 6.28
# (与一圈弧度数相等,只因频率=1)
turn_fast = 2 * math.pi / inv_freq[0].item() # 最快那根
turn_slow = 2 * math.pi / inv_freq[-1].item() # 最慢那根
print("最快那根转一圈 :", round(turn_fast, 1), "个位置") # ≈ 6.3
print("最慢那根转一圈 :", f"{turn_slow:,.0f}", "个位置") # ≈ 5,063,256
# 最慢那根走完整个 40960 长度,总共才转这么点
# (连一圈 6.28 弧度都不到)
print("最慢那根走完 40960 :",
round(40960 * inv_freq[-1].item(), 3), "弧度") # ≈ 0.051
rope = RotaryEmbedding(d, d, 40960, base)
print("cos_sin_cache 形状 :", tuple(rope.cos_sin_cache.shape)) # (40960,1,128)一共几个频率 : 64
最快(第 0 个): 1.0
最慢(末 1 个): 1.2409377632138785e-06
最快那根转一圈 : 6.3 个位置
最慢那根转一圈 : 5,063,256 个位置
最慢那根走完 40960 : 0.051 弧度
cos_sin_cache 形状 : (40960, 1, 128)5. apply_rotary_emb 旋转
forward 拿 positions 去表里查出对应的 cos、sin,再用它们把 q、k 旋转。旋转由 apply_rotary_emb 完成:把向量切成前后两半 x1、x2(前一半的第 i 维配后一半的第 i 维,即 GPT-NeoX 式,而非相邻两维),每一对 (x1[i], x2[i]) 当平面上一个点,转过该位置该组的角度。
defapply_rotary_emb(x, cos, sin):
# 把 x 切成前后两半:x1 配 x2(GPT-NeoX 式配对)
x1, x2 = torch.chunk(x.float(), 2, dim=-1) # 升 fp32 再转,保精度
# 2D 旋转矩阵:每一对 (x1, x2) 转过角 θ(cos/sin 即 cosθ/sinθ)
y1 = x1 * cos - x2 * sin
y2 = x2 * cos + x1 * sin
return torch.cat((y1, y2), dim=-1).to(x.dtype) # 拼回,收回原精度
# 接在 RotaryEmbedding 类里(这里单列出来看清)
defforward(self, positions, query, key):
cos_sin = self.cos_sin_cache[positions] # 按位置查表 [N, 1, d]
cos, sin = cos_sin.chunk(2, dim=-1) # 各 [N, 1, d/2]
query = apply_rotary_emb(query, cos, sin) # 旋转 q
key = apply_rotary_emb(key, cos, sin) # 旋转 k(v 不转)
return query, key6. get_rope 跨层复用
是什么:get_rope 是个带 @lru_cache(1) 的工厂函数。28 层的 attention 调用它时,传的参数(head_dim / base / max_position)完全相同,于是都拿到同一个RotaryEmbedding 实例。
打个比方:全楼共用一台饮水机——参数一样就不必每层各装一台。
为什么需要:28 层的 RoPE 配置一模一样。各建一个实例,就各存一张 [40960, 1, 128] 的 cos_sin_cache,纯属重复。
解决了什么:省下 27 张重复的表(显存),也省下 27 遍预计算。
怎么解决:@lru_cache(1) 把唯一一次构造结果缓存住,之后相同入参直接返回缓存的那个实例。集成验证里用 is 确认各层的 rotary_emb 是同一个对象。
from functools import lru_cache
@lru_cache(1) # 只缓存 1 个:相同入参永远返回同一个实例
defget_rope(head_size, rotary_dim, max_position, base):
return RotaryEmbedding(head_size, rotary_dim, max_position, base)
# 印证:两次同参调用拿到同一个对象
r1 = get_rope(128, 128, 40960, 1000000.0)
r2 = get_rope(128, 128, 40960, 1000000.0)
print("同一个实例 :", r1 is r2) # True同一个实例 : True7. positions 从哪来
RoPE 只认一个 positions 张量——每个 token 在序列里的第几位。这个张量在 L11/L12 的 ModelRunner 铺张量时就备好了,prefill 和 decode 两条路各自填:
# 摘自 model_runner.py,两条路怎么填 positions
# —— prefill:一段连续的位置 ——
# for seq in seqs:
# start = ... # 该序列已缓存的长度(prefix cache 时 >0)
# end = start + seq.num_scheduled_tokens
# positions.extend(range(start, end)) # 整段连续位置 [start, end)
# —— decode:只生成下一个 token,单点 ——
# for seq in seqs:
# positions.append(len(seq) - 1) # 当前序列最后一位的位置
# 所以对 RoPE 来说没有 prefill / decode 之分:
# prefill 喂进一串连续位置,decode 喂进一个单点位置,
# 查的是同一张 cos_sin_cache,转的是同一套旋转。8. 小结
RoPE 把位置信息编进 q、k:按 token 所在位置把 q、k 两两配对旋转,旋转后的内积只依赖相对距离 n − m——给注意力注入了它本身缺失的相对位置。
实现上三件事:cos/sin 只由「位置 × 频率」决定,__init__ 里一次算好存成 cos_sin_cache(预计算);apply_rotary_emb 查表取 cos/sin,把前后两半当平面点旋转(旋转);get_rope + lru_cache 让 28 层共享同一个实例、同一张表(跨层复用)。positions 由 prefill 的连续区间和 decode 的单点填入,RoPE 对两者一视同仁。
下一篇讲 Qwen3 的 Linear 层。
