 夜雨聆风
夜雨聆风









蛋白质的真面目,
藏在一层糖里
| HELLO SUMMER |
SUMMER

你是否想过,同样是蛋白质,为什么有的能精准“导航”到炎症部位,有的却“迷路”了?
答案,可能藏在蛋白质表面的糖链上。
糖基化——就是给蛋白质“挂上糖链”的过程——在人体健康与疾病中扮演着关键角色。
而糖蛋白质组学,就是系统研究这些“糖衣”修饰的前沿学科。
最近,国际多位顶尖学者联合发表了一篇重磅综述,系统梳理了糖蛋白质组学的实验方法、数据分析与应用前景。

01
什么是糖基化?为什么要研究它?


糖基化就是蛋白质的“糖衣”修饰


· 糖链通过酶的作用,共价连接到蛋白质上
· 没有核酸模板,全靠酶“手工”合成
· 糖链结构极其多样,调控着蛋白质的功能
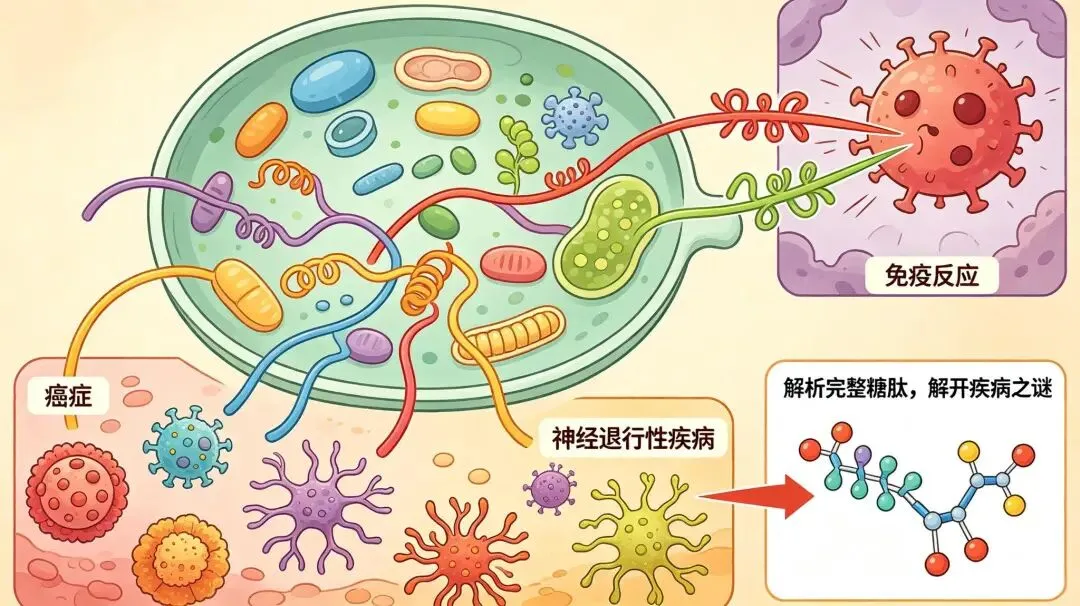
这些“糖衣”有多重要?
它们参与:
· 胚胎发育
· 细胞间通信
· 免疫反应
· 病原体与宿主的相互作用
糖基化出问题,会怎样?
与多种疾病密切相关:
· 癌症
· 炎症
· 精神分裂症
· 先天性糖缺陷病
· 神经退行性疾病
因此,解析糖基化——尤其是完整糖肽(保留天然糖链的肽段)——是理解疾病机制、发现新型标志物的关键。
HELLO SUMMER


02
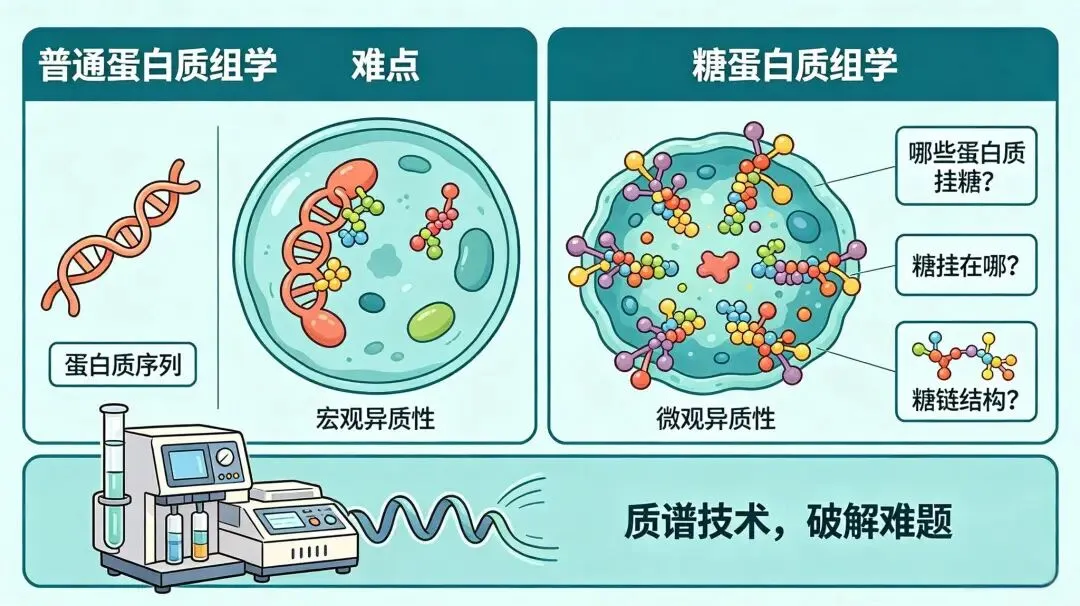
糖蛋白质组学,跟普通蛋白质组学区别

普通蛋白质组学主要回答:蛋白质的序列是什么?
糖蛋白质组学要回答三个问题:
· 哪些蛋白质挂了糖?
· 糖挂在哪个氨基酸位点上?
· 挂的是什么结构的糖链?
这背后有两个难点:
· 宏观异质性:同一个位点,有的蛋白质挂了糖,有的没挂
· 微观异质性:挂了糖的位点,糖链的结构还可能千差万别
过去二十年间,质谱技术尤其是液相色谱-串联质谱(LC-MS/MS),已成为破解这些难题的核心工具。
HELLO SUMMER

03
实验怎么做?五步走

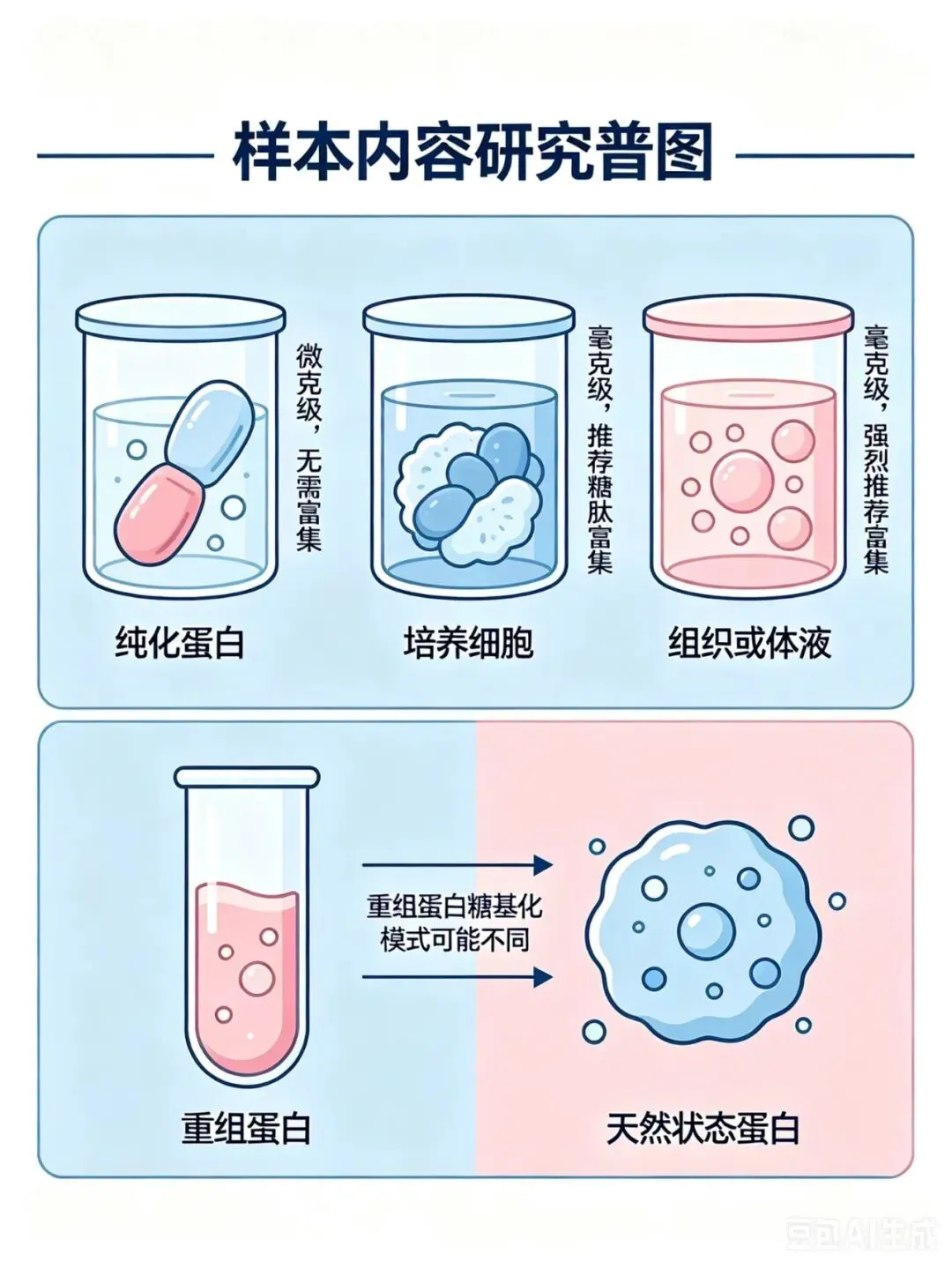
第一步:选择样本
不同样本的难度和需求量差异很大:
· 纯化蛋白:微克级就够了,不需要富集
· 培养细胞:需要毫克级,推荐做糖肽富集
· 组织或体液:也需要毫克级,强烈推荐富集
特别提醒:在试管里表达的重组蛋白,糖基化模式可能和天然状态不一样——选模型要擦亮眼睛。
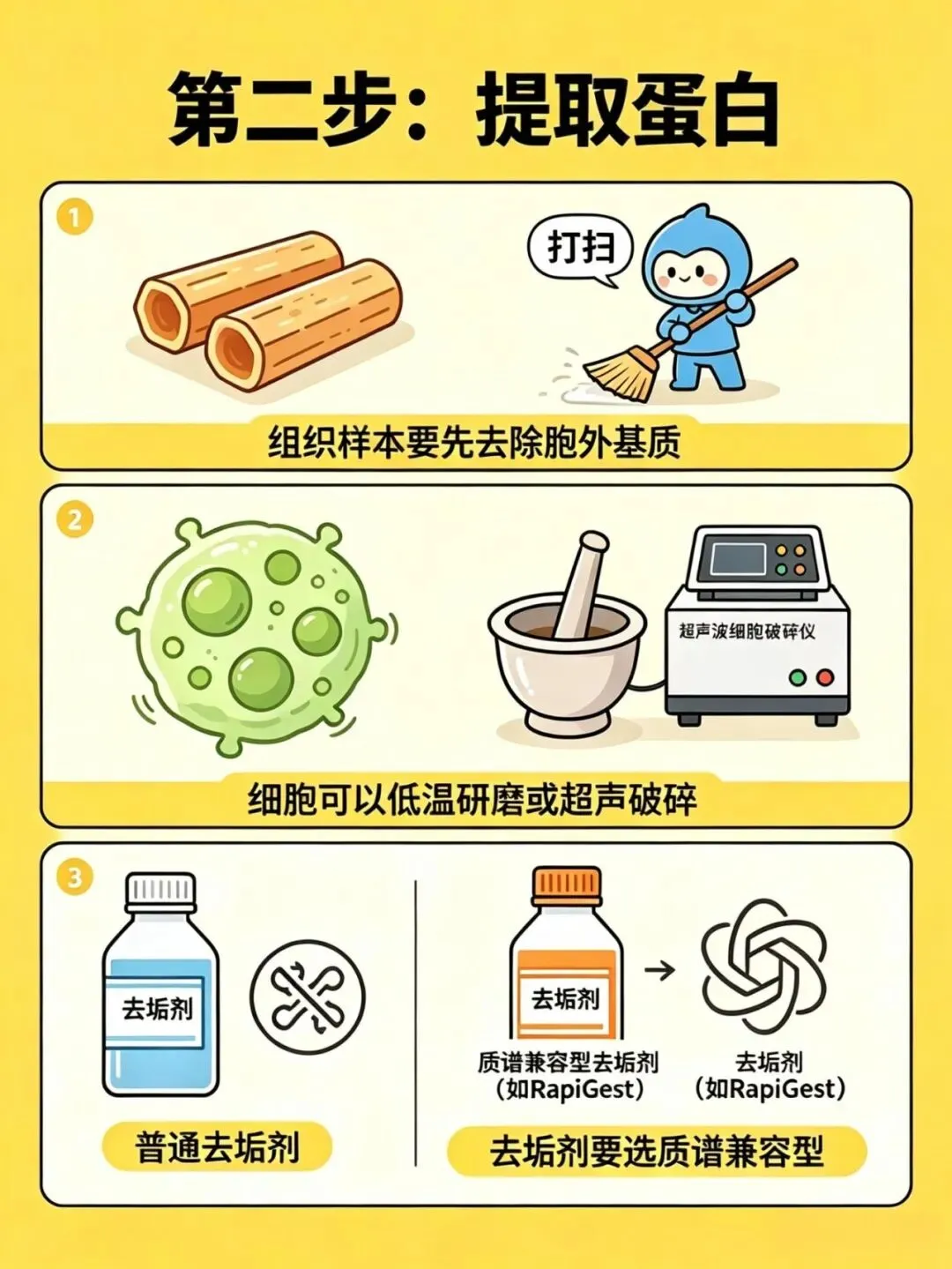
第二步:提取蛋白
· 组织样本要先去除胞外基质
· 细胞可以低温研磨或超声破碎
· 去垢剂要选质谱兼容型(比如RapiGest),普通去垢剂会干扰检测
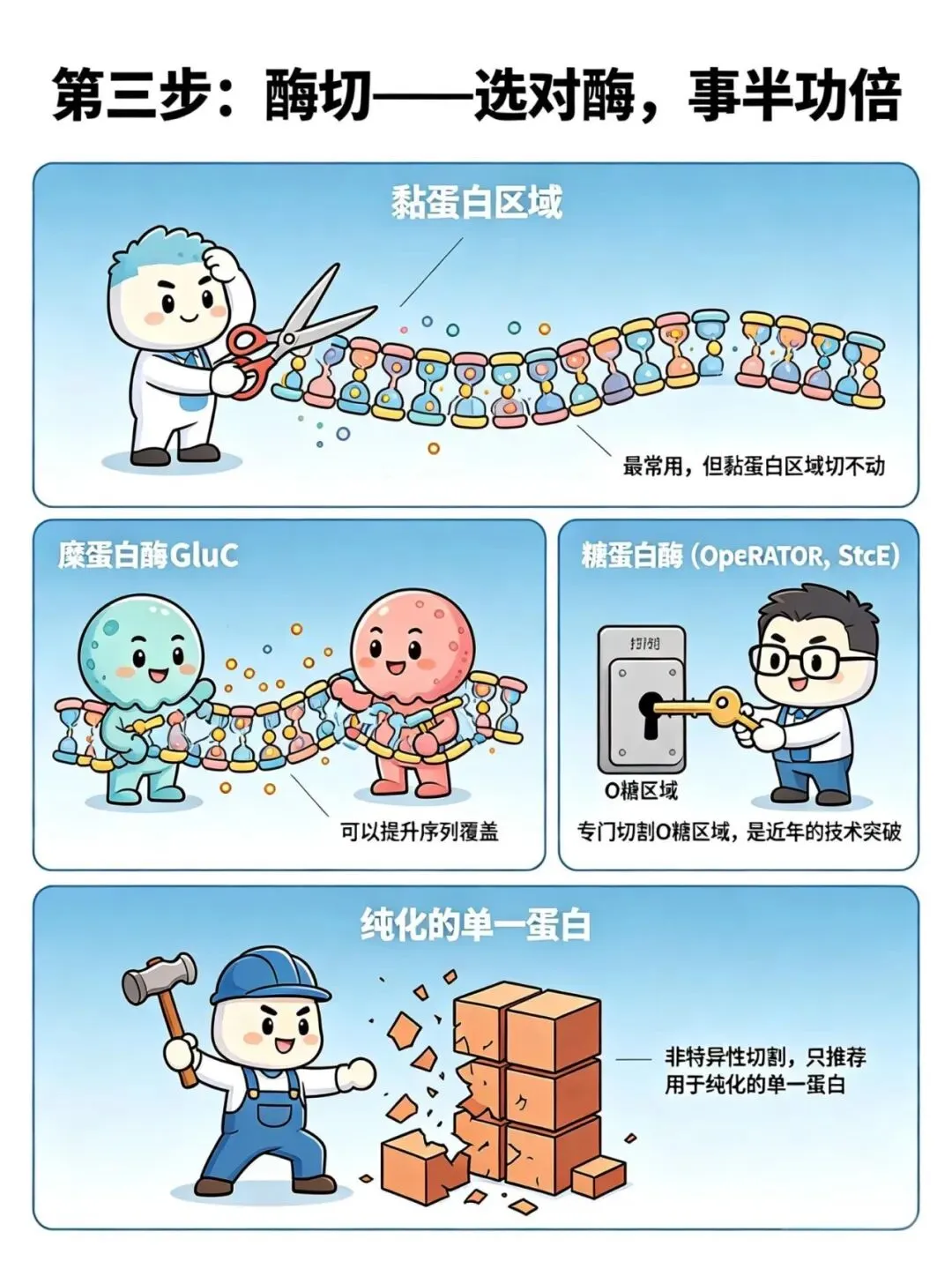
第三步:酶切——选对酶,事半功倍
· 胰蛋白酶:最常用,但黏蛋白区域切不动
· 糜蛋白酶、GluC:可以提升序列覆盖
· 糖蛋白酶(如OpeRATOR、StcE):专门切割O糖区域,是近年的技术突破
· 蛋白酶K:非特异性切割,只推荐用于纯化的单一蛋白
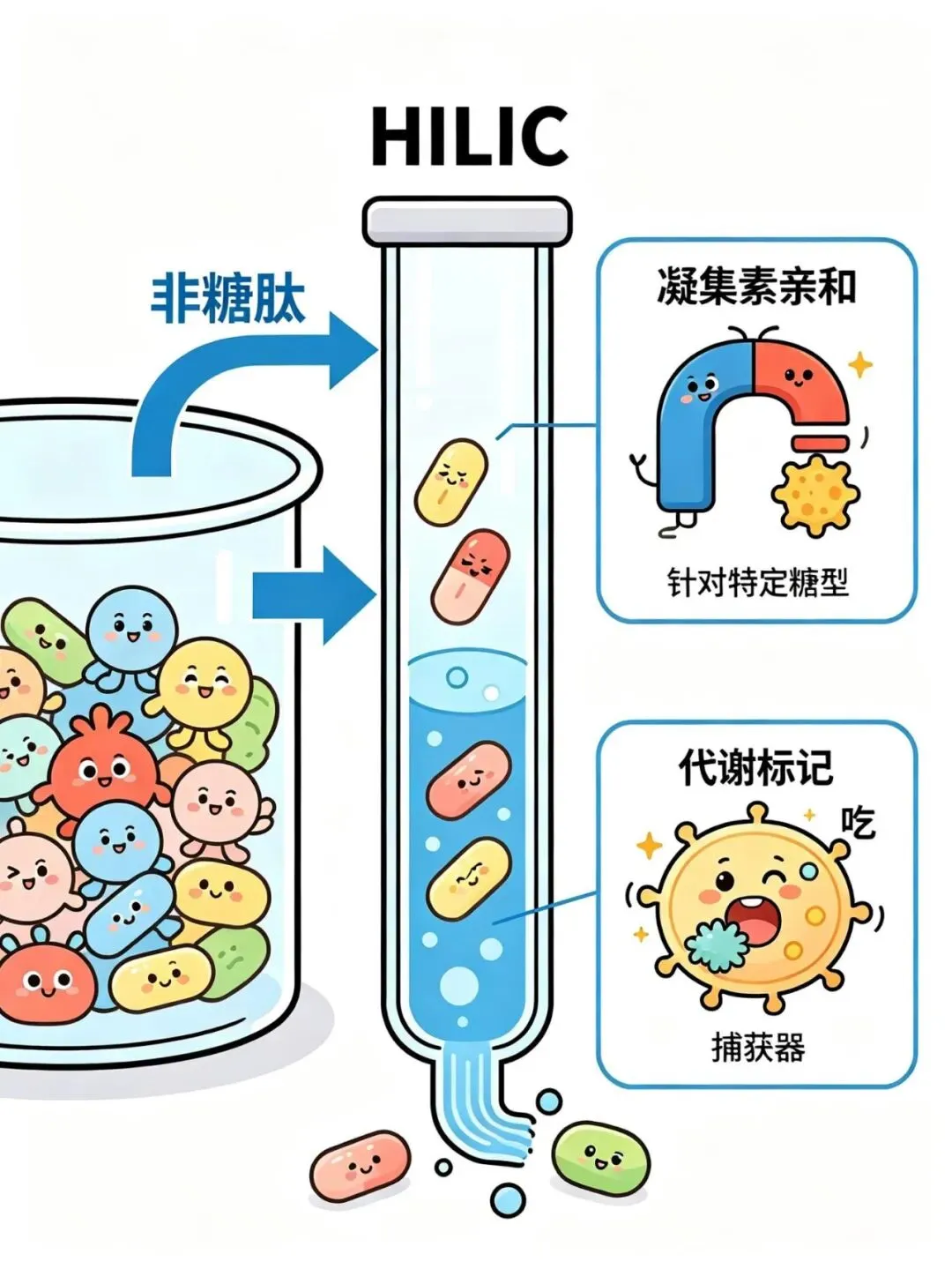
第四步:富集糖肽
因为糖肽在样品中通常含量很低,需要先“捞”出来。
最通用的方法是HILIC(亲水作用色谱)——利用糖链喜欢“吸水”的特性,把糖肽从一大堆非糖肽中分离出来。
其他方法还有:
· 凝集素亲和:针对特定糖型
· 代谢标记:给细胞喂人工糖,再精准捕获
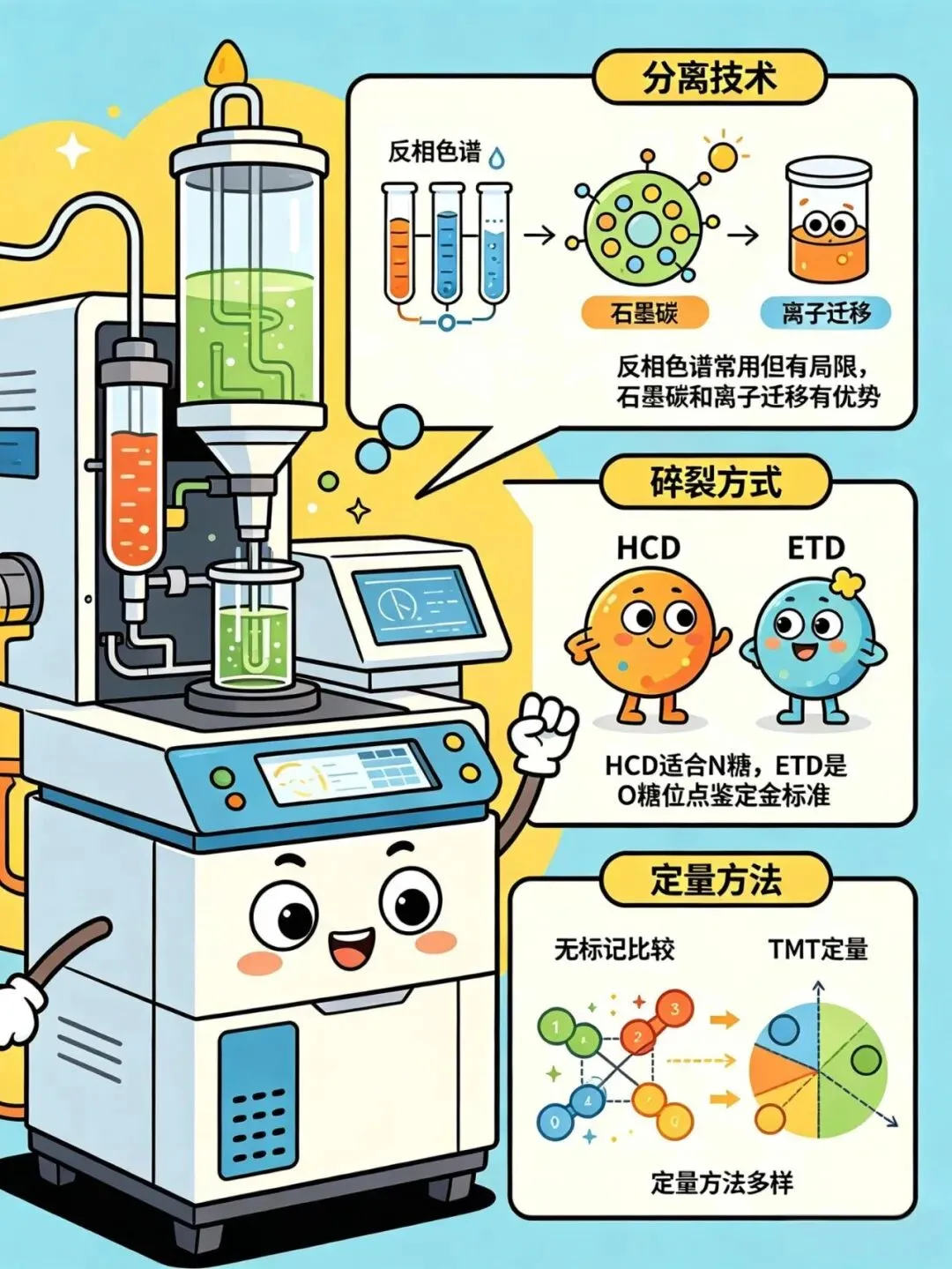
第五步:质谱检测
· 分离技术:反相色谱用得最广,但分不开糖链异构体;石墨碳和离子迁移在这方面更有优势
· 碎裂方式:HCD速度快,适合N糖;ETD是O糖位点鉴定的“金标准”
· 定量方法:从无标记的简单比较,到TMT的18重平行定量,丰俭由人
HELLO SUMMER


04
数据分析:三大检索策略

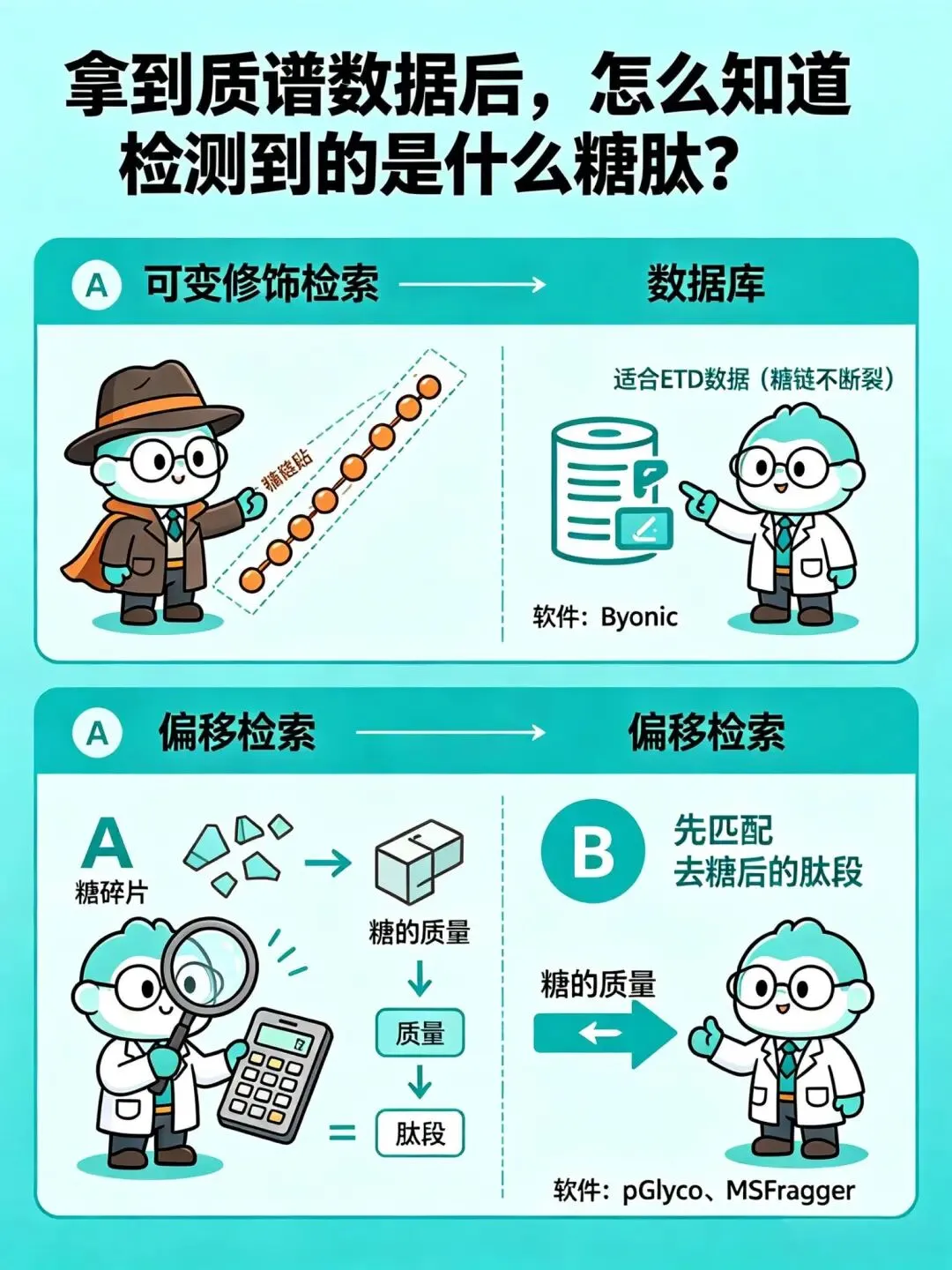
拿到质谱数据后,怎么知道检测到的是什么糖肽?
策略一:可变修饰检索
把糖链当作氨基酸的一种修饰来搜库。
适合ETD数据(糖链不断裂),代表软件有Byonic。
策略二:偏移检索
又分两种路子:
· 先识别糖碎片,算出糖的质量,剩下的质量去匹配肽段
· 先匹配去糖后的肽段,反推糖的质量
代表软件有pGlyco、
MSFragger。
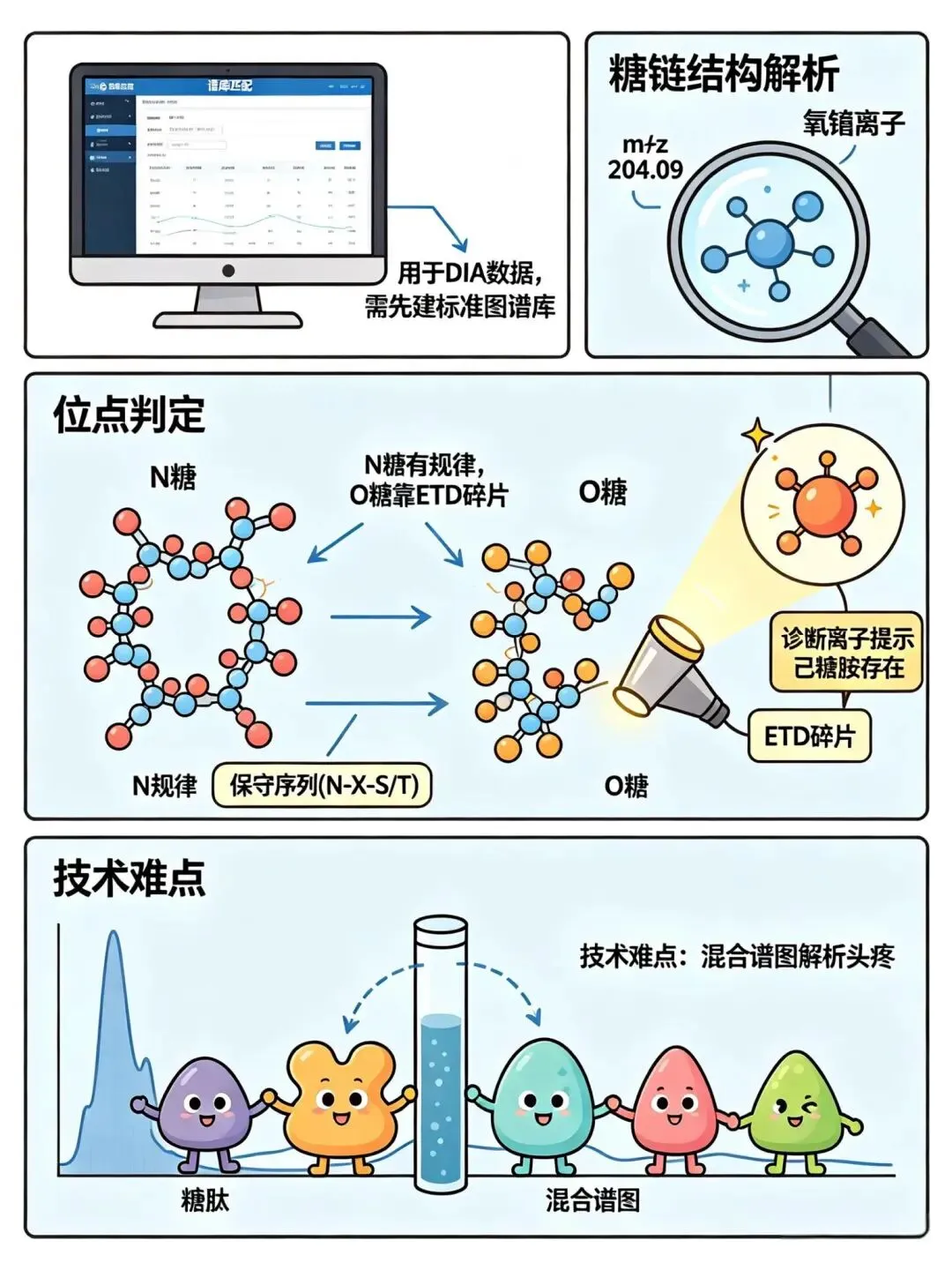
策略三:谱库匹配
主要用于DIA数据,需要先建一个标准图谱库。
位点怎么判定?
· N糖:有规律可循(保守序列N-X-S/T),相对容易
· O糖:没有保守序列,必须靠ETD类碎片才能精确定位
糖链结构怎么解析?
靠“诊断离子”——比如氧鎓离子(m/z 204.09)提示己糖胺的存在。
可以区分不同连接方式的唾液酸(α2,3 vs α2,6)、是否岩藻糖化等。
最大的技术难点:多个结构不同但分子量相同的糖肽,在色谱上同时流出来,会产生“混合谱图”,解析起来非常头疼。
HELLO SUMMER

05
能用来做什么?四大方向

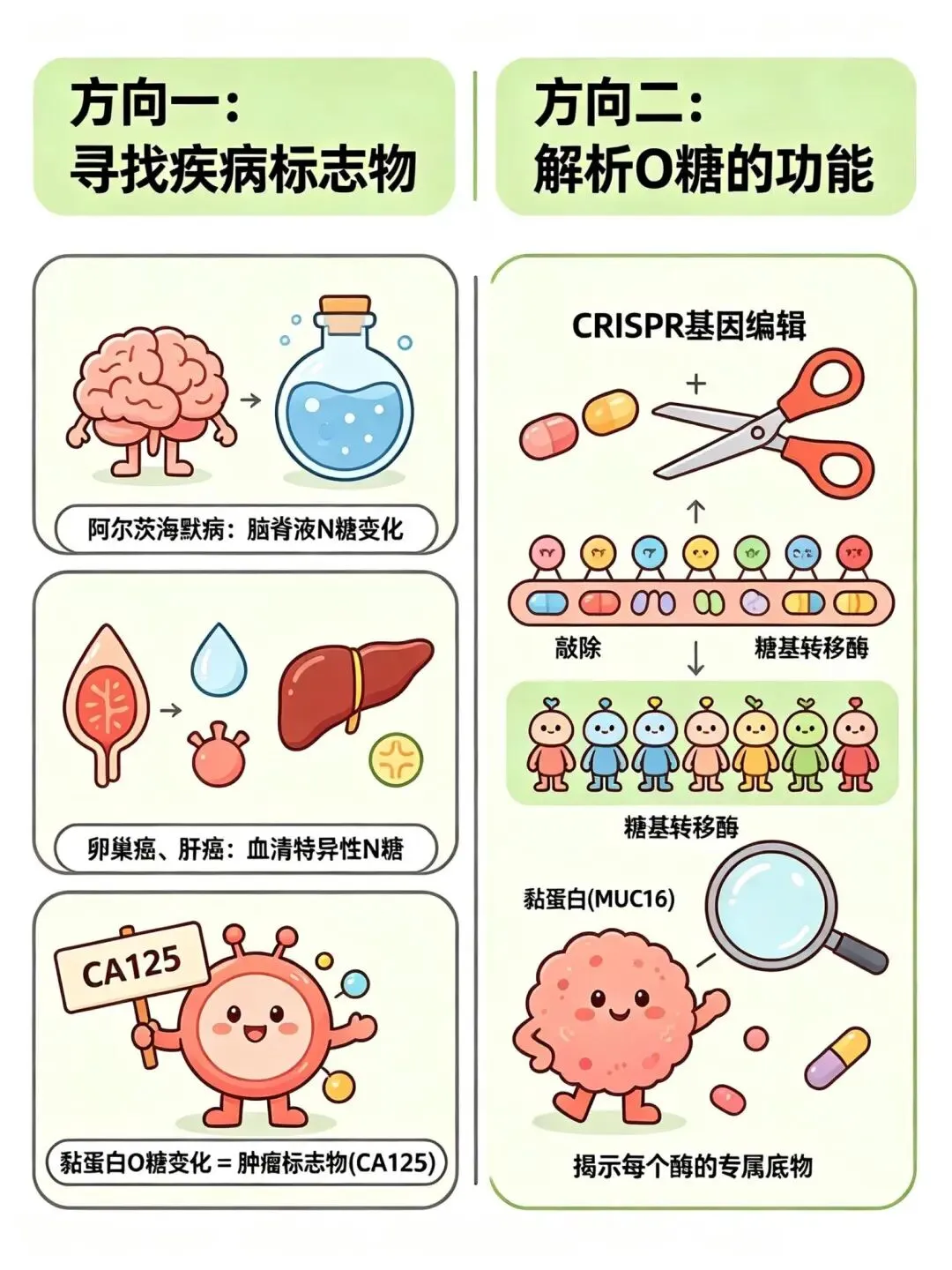
方向一:寻找疾病标志物
· 阿尔茨海默病:脑脊液中的N糖修饰发生变化
· 卵巢癌、肝癌:血清中出现特异性N糖特征
· 黏蛋白(如MUC16)的O糖变化,本身就是肿瘤标志物(就是大家熟知的CA125)
方向二:解析O糖的功能
利用CRISPR基因编辑,逐个敲除不同的糖基转移酶,看哪些蛋白质的糖基化消失了——从而揭示每个酶的“专属底物”。
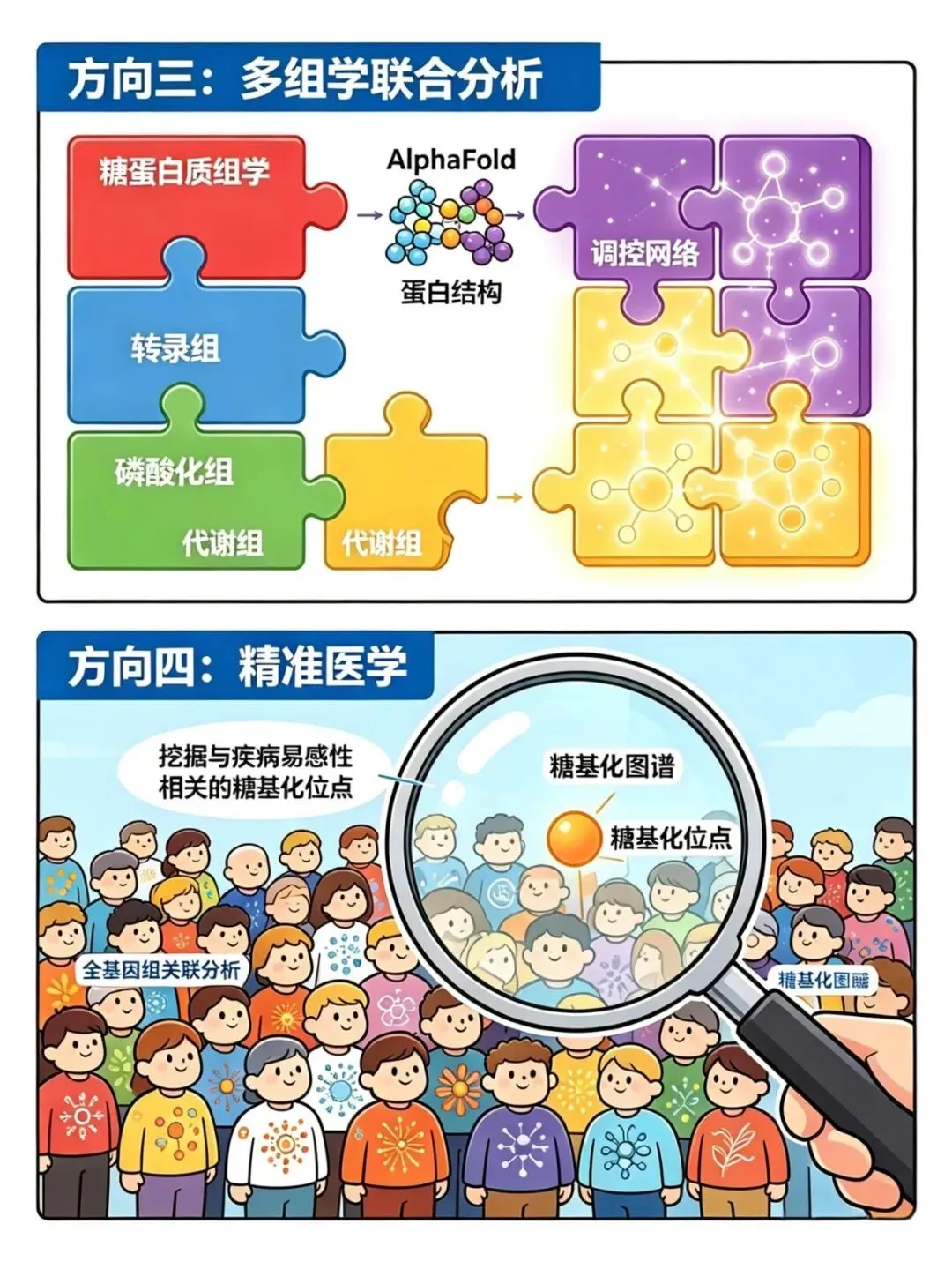
方向三:多组学联合分析
把糖蛋白质组学和转录组、磷酸化组、代谢组数据放一起看,再加上AlphaFold预测的蛋白结构,构建出更完整的调控网络。
方向四:精准医学
大规模人群的糖基化图谱,结合全基因组关联分析(GWAS),挖掘与疾病易感性相关的糖基化位点。
HELLO SUMMER

06
目前还有哪些短板?

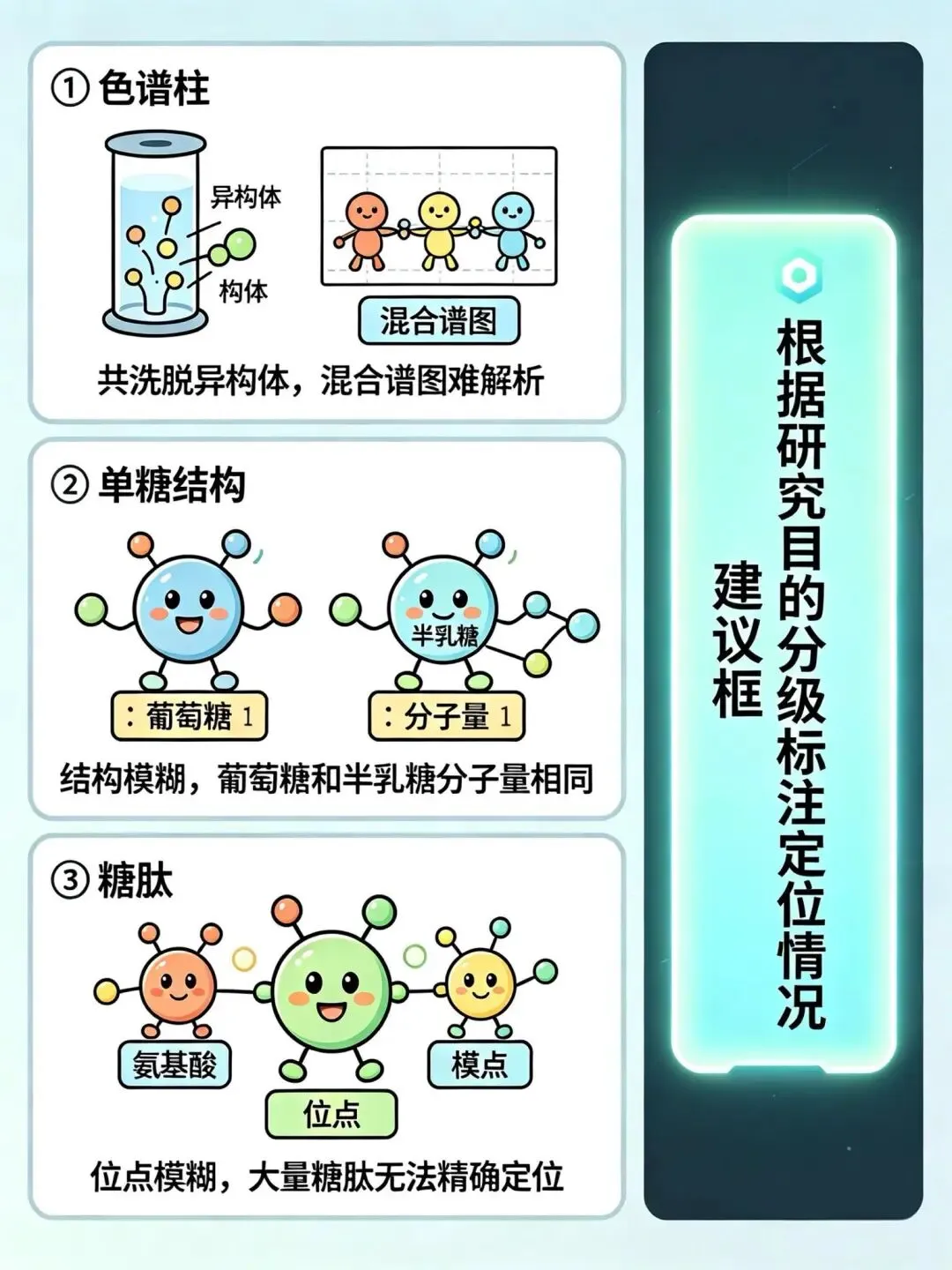
问题一:共洗脱异构体
不同的糖链结构可能在同一时间流出色谱柱,产生混合谱图,难以解析。
问题二:结构模糊
仅靠分子量无法区分同分异构的单糖(比如葡萄糖和半乳糖,分子量一模一样)。需要外切酶分步消化或合成标准品来确认。
问题三:位点模糊
大量糖肽无法精确定位糖到底挂在哪个氨基酸上。
建议根据研究目的,分级标注:直接定位、间接定位、部分定位、无定位。
HELLO SUMMER

07
未来往哪里走?

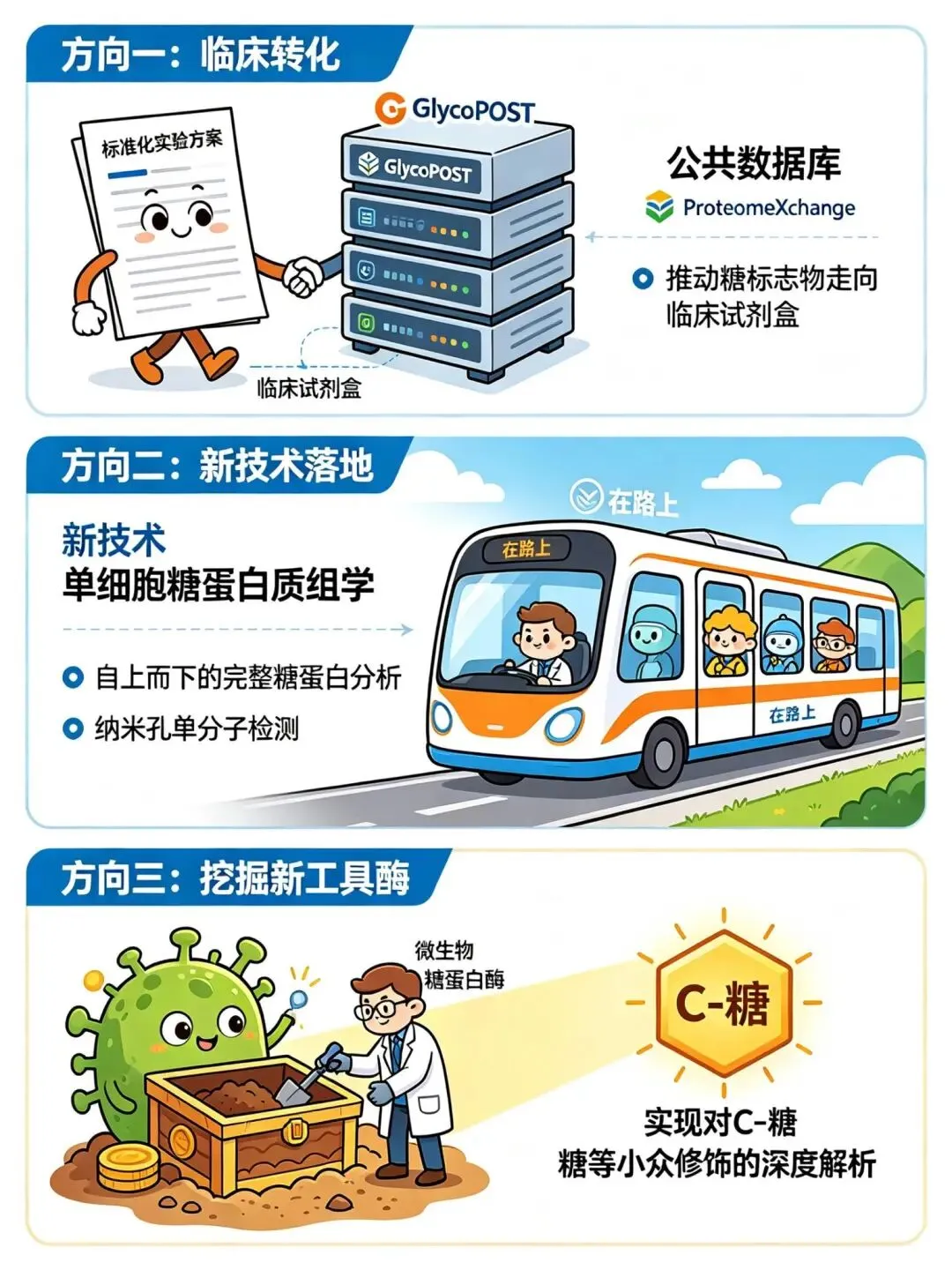
方向一:临床转化
建立标准化实验方案和公共数据库(如GlycoPOST、ProteomeXchange),推动糖标志物走向临床试剂盒。
方向二:新技术落地
单细胞糖蛋白质组学、自上而下的完整糖蛋白分析、纳米孔单分子检测——都在路上。
方向三:挖掘新工具酶
寻找更多微生物来源的糖蛋白酶,实现对C-糖等小众修饰的深度解析。
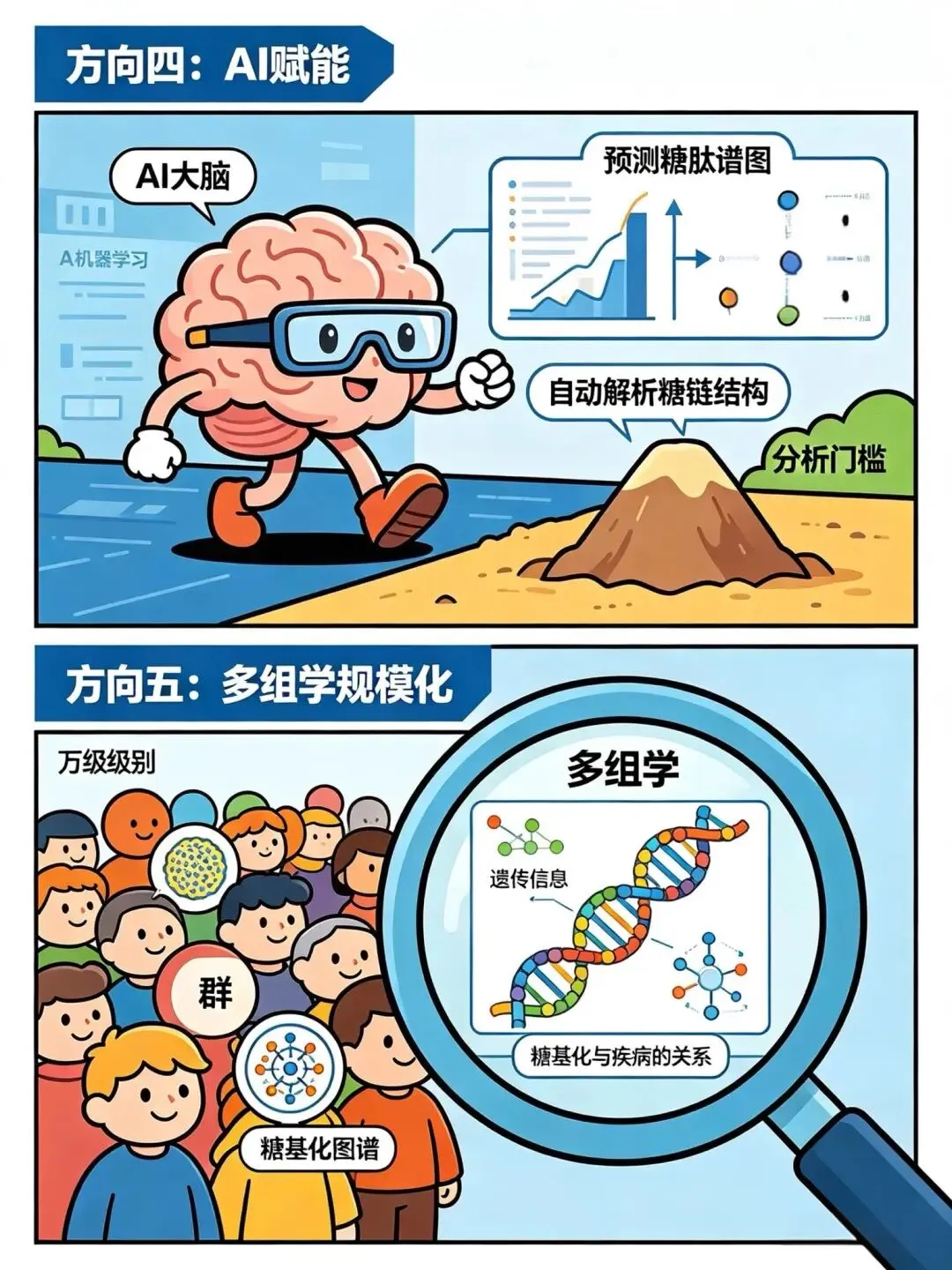
方向四:AI赋能
机器学习预测糖肽谱图、自动解析糖链结构,大幅降低分析门槛。
方向五:多组学规模化
万级别人群的糖基化图谱,结合遗传信息,系统揭示糖基化与疾病的关系。
HELLO SUMMER

糖蛋白质组学,正处于从“技术驱动”迈向“生物学驱动”的关键转折期。
它不仅能帮我们理解蛋白质的“糖衣密码”,
更有望在癌症早筛、神经退行性疾病诊断、新型药物靶点发现中,发挥不可替代的作用。
下一次,当你听到“糖蛋白”三个字,请记住——
它们不是甜的点缀,而是生命调控的“隐形指挥官”。
参考文献:NATURE REVIEWS | METHODS PRIMERS | Article citation ID: (2022) 2:48

