 夜雨聆风
夜雨聆风概述
本周深入分析 RAGFlow 的多模态能力实现,涵盖 OCR 识别、计算机视觉(CV)模型、语音转文字(ASR)三大核心模块。这些模块扩展了 RAGFlow 的文档理解能力,支持图像、视频、音频等多种数据格式的处理。
核心文件
rag/llm/ocr_model.py- OCR 模型集成(MinerU、PaddleOCR) rag/llm/cv_model.py- 计算机视觉模型(25+ 视觉大模型) rag/llm/sequence2txt_model.py- 语音转文字模型(12+ ASR 服务)
一、OCR 模型架构
1.1 OCR 模型层次结构
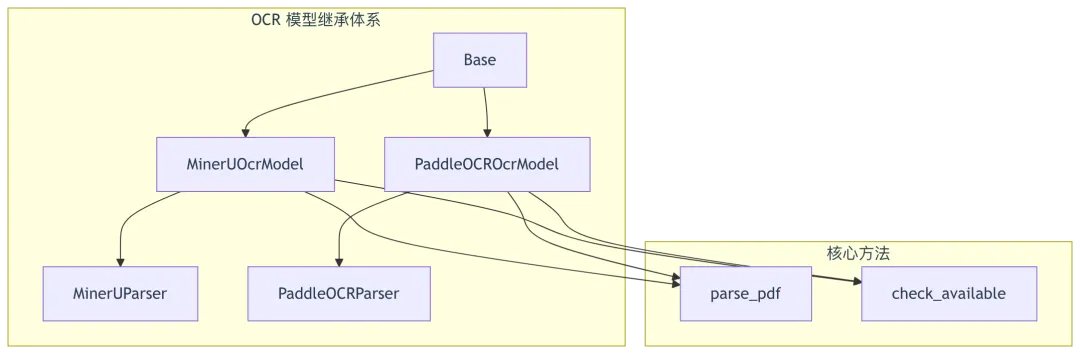
1.2 Base 基类设计
源码位置: rag/llm/ocr_model.py:25-30
class Base:def __init__(self, key: str | dict, model_name: str, **kwargs):self.model_name = model_namedef parse_pdf(self, filepath: str, binary=None, **kwargs) -> tuple[Any, Any]:raise NotImplementedError("Please implement parse_pdf!")
设计模式: 模板方法模式,定义 OCR 模型的标准接口。
1.3 MinerU OCR 实现
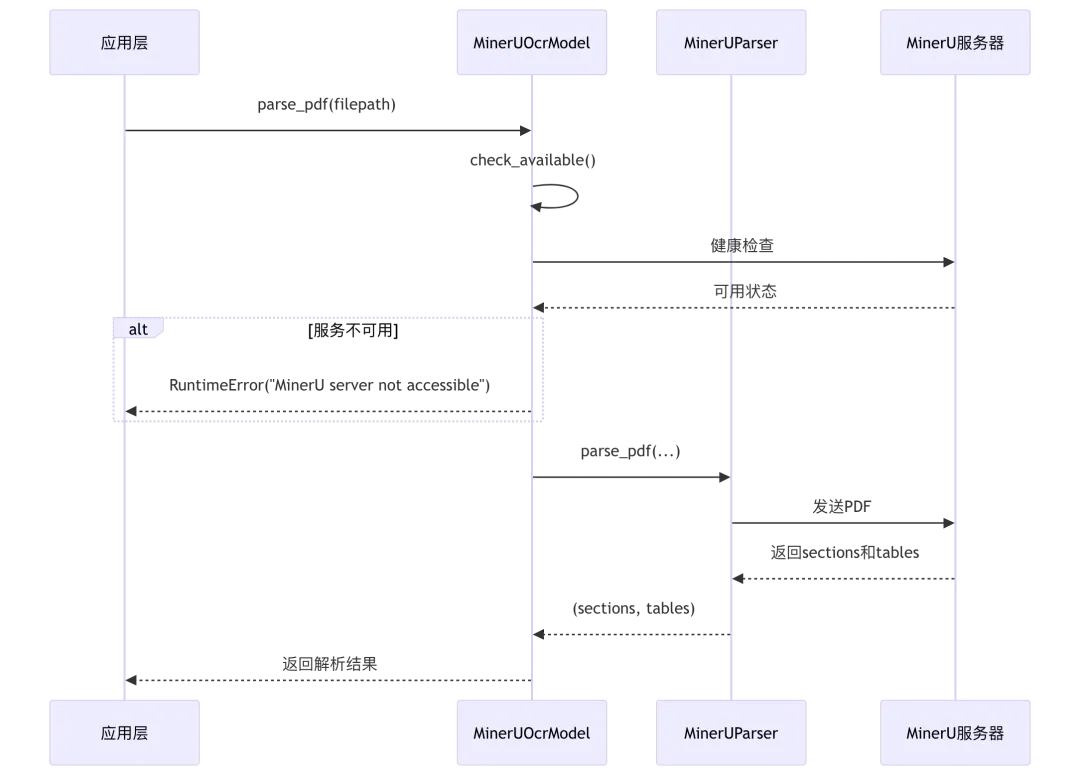
源码位置: rag/llm/ocr_model.py:33-94
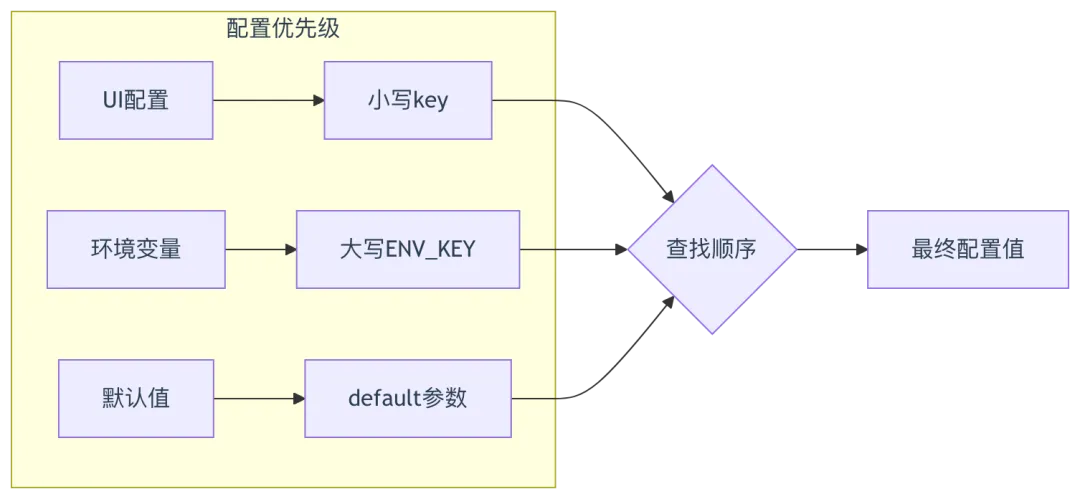
class MinerUOcrModel(Base, MinerUParser):_FACTORY_NAME = "MinerU"def __init__(self, key: str | dict, model_name: str, **kwargs):Base.__init__(self, key, model_name, **kwargs)raw_config = {}if key:try:raw_config = json.loads(key)except Exception:raw_config = {}# 嵌套配置结构处理config = raw_config.get("api_key", raw_config)if not isinstance(config, dict):config = {}def _resolve_config(key: str, env_key: str, default=""):# 优先级: UI配置 > 环境变量 > 默认值return config.get(key, config.get(env_key, os.environ.get(env_key, default)))# 核心配置参数self.mineru_api = _resolve_config("mineru_apiserver", "MINERU_APISERVER", "")self.mineru_output_dir = _resolve_config("mineru_output_dir", "MINERU_OUTPUT_DIR", "")self.mineru_backend = _resolve_config("mineru_backend", "MINERU_BACKEND", "pipeline")self.mineru_server_url = _resolve_config("mineru_server_url", "MINERU_SERVER_URL", "")self.mineru_delete_output = bool(int(_resolve_config("mineru_delete_output", "MINERU_DELETE_OUTPUT", 1)))# 敏感信息脱敏日志redacted_config = {}for k, v in config.items():if any(sensitive_word in k.lower() for sensitive_word in ("key", "password", "token", "secret")):redacted_config[k] = "[REDACTED]"else:redacted_config[k] = vlogging.info(f"Parsed MinerU config (sensitive fields redacted): {redacted_config}")MinerUParser.__init__(self, mineru_api=self.mineru_api, mineru_server_url=self.mineru_server_url)def check_available(self, backend: Optional[str] = None, server_url: Optional[str] = None) -> tuple[bool, str]:backend = backend or self.mineru_backendserver_url = server_url or self.mineru_server_urlreturn self.check_installation(backend=backend, server_url=server_url)def parse_pdf(self, filepath: str, binary=None, callback=None, parse_method: str = "raw", **kwargs):ok, reason = self.check_available()if not ok:raise RuntimeError(f"MinerU server not accessible: {reason}")sections, tables = MinerUParser.parse_pdf(self,filepath=filepath,binary=binary,callback=callback,output_dir=self.mineru_output_dir,backend=self.mineru_backend,server_url=self.mineru_server_url,delete_output=self.mineru_delete_output,parse_method=parse_method,**kwargs,)return sections, tables
配置解析策略:
1.4 PaddleOCR 实现
源码位置: rag/llm/ocr_model.py:97-148
class PaddleOCROcrModel(Base, PaddleOCRParser):_FACTORY_NAME = "PaddleOCR"def __init__(self, key: str | dict, model_name: str, **kwargs):Base.__init__(self, key, model_name, **kwargs)raw_config = {}if key:try:raw_config = json.loads(key)except Exception:raw_config = {}config = raw_config.get("api_key", raw_config)if not isinstance(config, dict):config = {}def _resolve_config(key: str, env_key: str, default=""):return config.get(key, config.get(env_key, os.environ.get(env_key, default)))self.paddleocr_api_url = _resolve_config("paddleocr_api_url", "PADDLEOCR_API_URL", "")self.paddleocr_algorithm = _resolve_config("paddleocr_algorithm", "PADDLEOCR_ALGORITHM", "PaddleOCR-VL")self.paddleocr_access_token = _resolve_config("paddleocr_access_token", "PADDLEOCR_ACCESS_TOKEN", None)# 敏感信息脱敏redacted_config = {}for k, v in config.items():if any(sensitive_word in k.lower() for sensitive_word in ("key", "password", "token", "secret")):redacted_config[k] = "[REDACTED]"else:redacted_config[k] = vlogging.info(f"Parsed PaddleOCR config (sensitive fields redacted): {redacted_config}")PaddleOCRParser.__init__(self,api_url=self.paddleocr_api_url,access_token=self.paddleocr_access_token,algorithm=self.paddleocr_algorithm,)def check_available(self) -> tuple[bool, str]:return self.check_installation()def parse_pdf(self, filepath: str, binary=None, callback=None, parse_method: str = "raw", **kwargs):ok, reason = self.check_available()if not ok:raise RuntimeError(f"PaddleOCR server not accessible: {reason}")sections, tables = PaddleOCRParser.parse_pdf(self, filepath=filepath, binary=binary, callback=callback, parse_method=parse_method, **kwargs)return sections, tables
OCR 模型对比:
二、计算机视觉(CV)模型架构
2.1 CV 模型继承体系
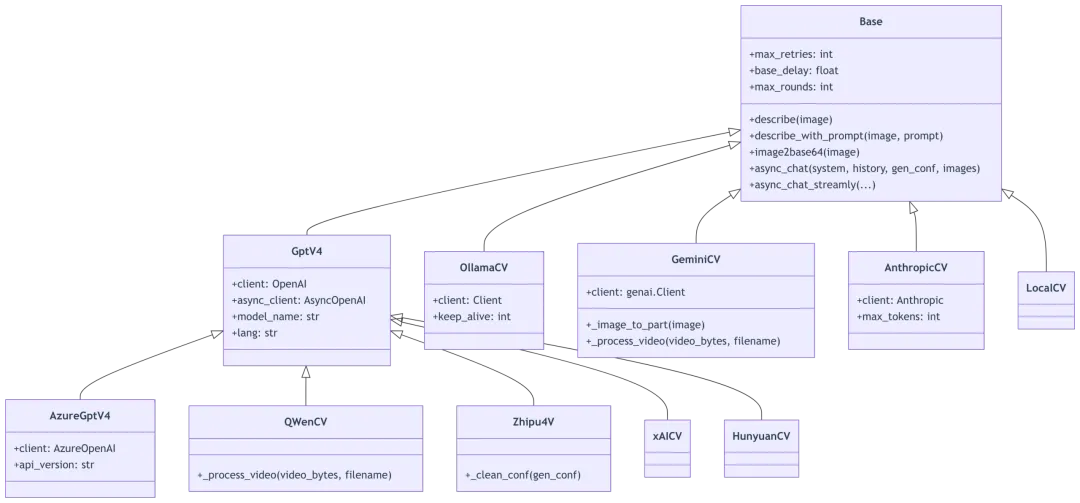
2.2 Base 基类核心实现
源码位置: rag/llm/cv_model.py:42-187
图像编码方法
@staticmethoddef image2base64(image):"""将图像转换为 data URL 格式的 base64 字符串"""if isinstance(image, bytes):# 根据魔数判断 MIME 类型mime = "image/png"if len(image) >= 2 and image[0] == 0xFF and image[1] == 0xD8:mime = "image/jpeg"b64 = base64.b64encode(image).decode("utf-8")return f"data:{mime};base64,{b64}"if isinstance(image, BytesIO):data = image.getvalue()mime = "image/png"if len(data) >= 2 and data[0] == 0xFF and data[1] == 0xD8:mime = "image/jpeg"b64 = base64.b64encode(data).decode("utf-8")return f"data:{mime};base64,{b64}"# PIL Image 对象with BytesIO() as buffered:fmt = "jpeg"try:image.save(buffered, format="JPEG")except Exception:buffered.seek(0)buffered.truncate()image.save(buffered, format="PNG")fmt = "png"data = buffered.getvalue()b64 = base64.b64encode(data).decode("utf-8")mime = f"image/{fmt}"return f"data:{mime};base64,{b64}"
魔数识别:
0xFF 0xD8 | |
0x89 0x50 | |
0x47 0x49 |
图像提示词构建
def _image_prompt(self, text, images):"""构建多模态消息内容"""if not images:return textif isinstance(images, str) or "bytes" in type(images).__name__:images = [images]pmpt = [{"type": "text", "text": text}]for img in images:pmpt.append({"type": "image_url","image_url": {"url": img if isinstance(img, str) and img.startswith("data:")else f"data:image/png;base64,{img}"}})return pmpt
2.3 GptV4 实现详解
源码位置: rag/llm/cv_model.py:189-218
class GptV4(Base):_FACTORY_NAME = "OpenAI"def __init__(self, key, model_name="gpt-4-vision-preview", lang="Chinese", base_url="https://api.openai.com/v1", **kwargs):if not base_url:base_url = "https://api.openai.com/v1"self.api_key = keyself.client = OpenAI(api_key=key, base_url=base_url)self.async_client = AsyncOpenAI(api_key=key, base_url=base_url)self.model_name = model_nameself.lang = langsuper().__init__(**kwargs)def describe(self, image):"""自动生成图像描述"""b64 = self.image2base64(image)res = self.client.chat.completions.create(model=self.model_name,messages=self.prompt(b64),extra_body=self.extra_body)return res.choices[0].message.content.strip(), total_token_count_from_response(res)def describe_with_prompt(self, image, prompt=None):"""使用自定义提示词描述图像"""b64 = self.image2base64(image)res = self.client.chat.completions.create(model=self.model_name,messages=self.vision_llm_prompt(b64, prompt),extra_body=self.extra_body,)return res.choices[0].message.content.strip(), total_token_count_from_response(res)
2.4 QWenCV 视频处理
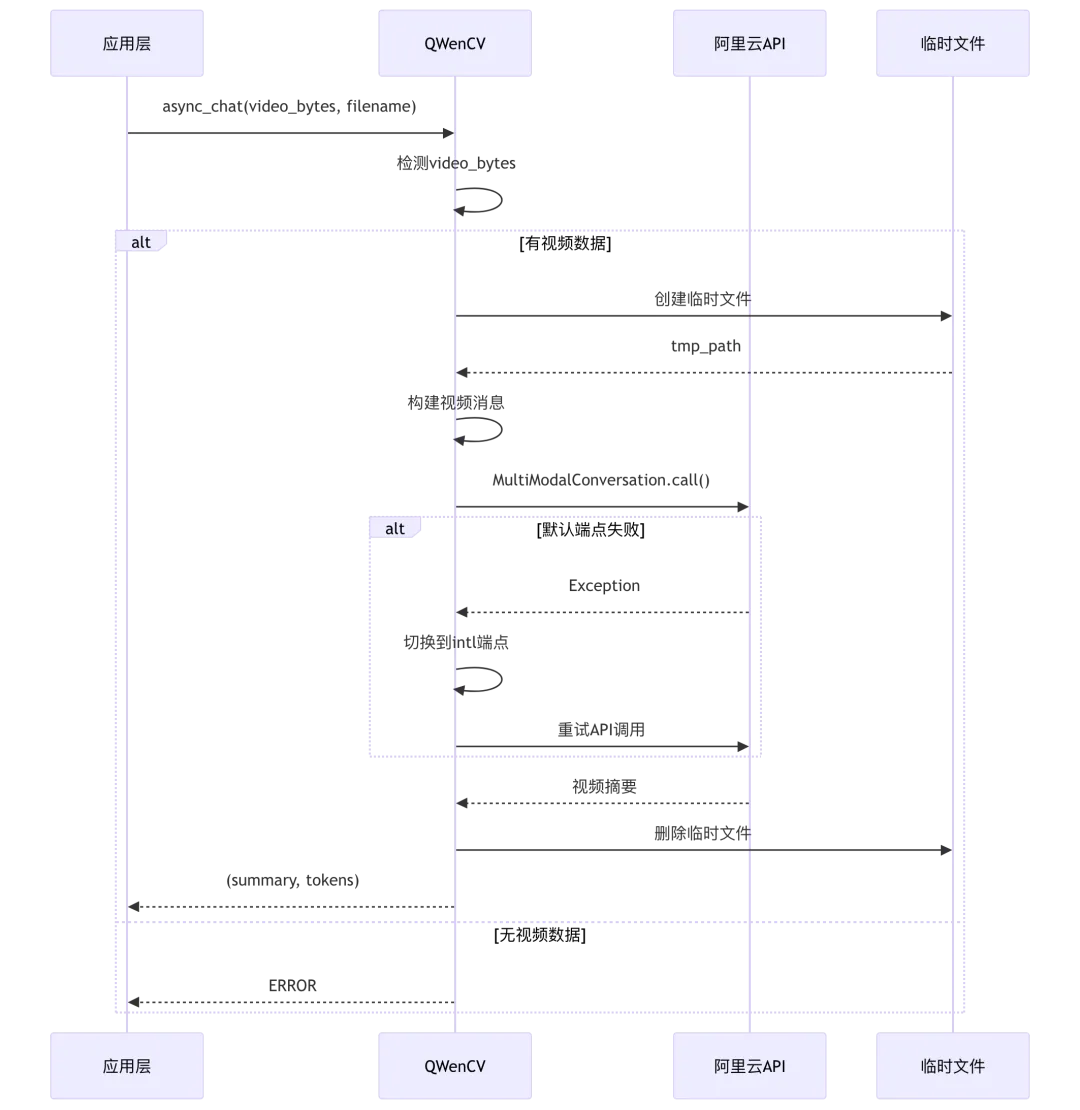
源码位置: rag/llm/cv_model.py:251-305
async def async_chat(self, system, history, gen_conf, images=None, video_bytes=None, filename="", **kwargs):if video_bytes:try:summary, summary_num_tokens = self._process_video(video_bytes, filename)return summary, summary_num_tokensexcept Exception as e:return "**ERROR**: " + str(e), 0return "**ERROR**: Method chat not supported yet.", 0def _process_video(self, video_bytes, filename):from dashscope import MultiModalConversationvideo_suffix = Path(filename).suffix or ".mp4"with tempfile.NamedTemporaryFile(delete=False, suffix=video_suffix) as tmp:tmp.write(video_bytes)tmp_path = tmp.namevideo_path = f"file://{tmp_path}"messages = [{"role": "user","content": [{"video": video_path, "fps": 2},{"text": "Please summarize this video in proper sentences."},],}]def call_api():response = MultiModalConversation.call(api_key=self.api_key,model=self.model_name,messages=messages,)if response.get("message"):raise Exception(response["message"])summary = response["output"]["choices"][0]["message"].content[0]["text"]return summary, num_tokens_from_string(summary)try:return call_api()except Exception as e1:# 切换到国际端点重试import dashscopedashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"try:return call_api()except Exception as e2:raise RuntimeError(f"Both default and intl endpoint failed.\nFirst error: {e1}\nSecond error: {e2}")
2.5 GeminiCV 实现详解
源码位置: rag/llm/cv_model.py:675-896
class GeminiCV(Base):_FACTORY_NAME = "Gemini"def __init__(self, key, model_name="gemini-1.0-pro-vision-latest", lang="Chinese", **kwargs):from google import genaiself.api_key = keyself.model_name = model_nameself.client = genai.Client(api_key=key)self.lang = langBase.__init__(self, **kwargs)logging.info(f"[GeminiCV] Initialized with model={self.model_name} lang={self.lang}")def _image_to_part(self, image):"""将图像转换为 Gemini Part 对象"""from google.genai import typesif isinstance(image, str) and image.startswith("data:") and ";base64," in image:header, b64data = image.split(",", 1)mime = header.split(":", 1)[1].split(";", 1)[0]data = base64.b64decode(b64data)else:data_url = self.image2base64(image)header, b64data = data_url.split(",", 1)mime = header.split(":", 1)[1].split(";", 1)[0]data = base64.b64decode(b64data)return types.Part(inline_data=types.Blob(mime_type=mime,data=data,))def _process_video(self, video_bytes, filename):"""处理视频文件"""from google import genaifrom google.genai import typesvideo_size_mb = len(video_bytes) / (1024 * 1024)client = self.client if hasattr(self, "client") else genai.Client(api_key=self.api_key)logging.info(f"[GeminiCV] _process_video called: filename={filename} size_mb={video_size_mb:.2f}")tmp_path = Nonetry:if video_size_mb <= 20:# 小文件直接内联处理response = client.models.generate_content(model="models/gemini-2.5-flash",contents=types.Content(parts=[types.Part(inline_data=types.Blob(data=video_bytes, mime_type="video/mp4")),types.Part(text="Please summarize the video in proper sentences.")]),)else:# 大文件使用 Files APIlogging.info(f"Video size {video_size_mb:.2f}MB exceeds 20MB. Using Files API...")video_suffix = Path(filename).suffix or ".mp4"with tempfile.NamedTemporaryFile(delete=False, suffix=video_suffix) as tmp:tmp.write(video_bytes)tmp_path = Path(tmp.name)uploaded_file = client.files.upload(file=tmp_path)response = client.models.generate_content(model="gemini-2.5-flash",contents=[uploaded_file, "Please summarize this video in proper sentences."])summary = response.text or ""logging.info(f"[GeminiCV] Video summarized: {summary[:32]}...")return summary, num_tokens_from_string(summary)except Exception as e:logging.warning(f"[GeminiCV] Video processing failed: {e}")raisefinally:if tmp_path and tmp_path.exists():tmp_path.unlink()
视频处理策略:
2.6 AnthropicCV 实现
源码位置: rag/llm/cv_model.py:977-1081
class AnthropicCV(Base):_FACTORY_NAME = "Anthropic"def __init__(self, key, model_name, base_url=None, **kwargs):import anthropicself.client = anthropic.Anthropic(api_key=key)self.async_client = anthropic.AsyncAnthropic(api_key=key)self.model_name = model_nameself.system = ""self.max_tokens = 8192if "haiku" in self.model_name or "opus" in self.model_name:self.max_tokens = 4096Base.__init__(self, **kwargs)def _image_prompt(self, text, images):"""Anthropic 图像格式"""if not images:return textpmpt = [{"type": "text", "text": text}]for img in images:pmpt.append({"type": "image","source": {"type": "base64","media_type": (img.split(":")[1].split(";")[0] if isinstance(img, str) and img[:4] == "data" else "image/png"),"data": (img.split(",")[1] if isinstance(img, str) and img[:4] == "data" else img),},})return pmptasync def async_chat_streamly(self, system, history, gen_conf, images=None, **kwargs):gen_conf = self._clean_conf(gen_conf)total_tokens = 0try:response = self.async_client.messages.create(model=self.model_name,messages=self._form_history(system, history, images),system=system,stream=True,**gen_conf,)think = Falseasync for res in response:if res.type == "content_block_delta":if res.delta.type == "thinking_delta" and res.delta.thinking:if not think:yield "SEMBED"think = Trueyield res.delta.thinkingtotal_tokens += num_tokens_from_string(res.delta.thinking)elif think:yield "DECREF"else:yield res.delta.texttotal_tokens += num_tokens_from_string(res.delta.text)except Exception as e:yield "\n**ERROR**: " + str(e)yield total_tokens
扩展思考支持: AnthropicCV 支持 Claude 的扩展思考(extended thinking)功能,在流式输出中标记思考过程。
2.7 CV 模型提供商汇总
提供商特性对比:
三、语音转文字(ASR)模型架构
3.1 Sequence2txt 模型层次
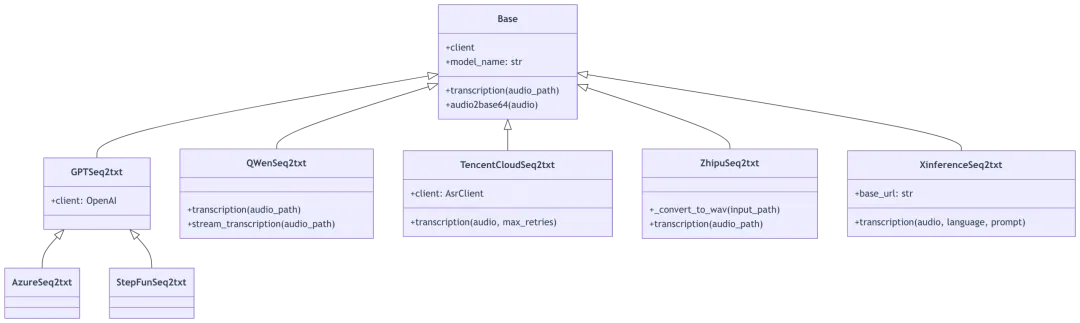
3.2 Base 基类实现
源码位置: rag/llm/sequence2txt_model.py:31-49
class Base(ABC):def __init__(self, key, model_name, **kwargs):"""抽象基类构造器"""passdef transcription(self, audio_path, **kwargs):"""语音转文字核心方法"""audio_file = open(audio_path, "rb")transcription = self.client.audio.transcriptions.create(model=self.model_name,file=audio_file)return transcription.text.strip(), num_tokens_from_string(transcription.text.strip())def audio2base64(self, audio):"""音频转 base64"""if isinstance(audio, bytes):return base64.b64encode(audio).decode("utf-8")if isinstance(audio, io.BytesIO):return base64.b64encode(audio.getvalue()).decode("utf-8")raise TypeError("The input audio file should be in binary format.")
3.3 OpenAI Whisper 实现
源码位置: rag/llm/sequence2txt_model.py:52-60
class GPTSeq2txt(Base):_FACTORY_NAME = "OpenAI"def __init__(self, key, model_name="whisper-1", base_url="https://api.openai.com/v1", **kwargs):if not base_url:base_url = "https://api.openai.com/v1"self.client = OpenAI(api_key=key, base_url=base_url)self.model_name = model_name
3.4 通义千问 ASR 实现
源码位置: rag/llm/sequence2txt_model.py:71-154
class QWenSeq2txt(Base):_FACTORY_NAME = "Tongyi-Qianwen"def __init__(self, key, model_name="qwen-audio-asr", **kwargs):import dashscopedashscope.api_key = keyself.model_name = model_namedef transcription(self, audio_path):import dashscopeif audio_path.startswith("http"):audio_input = audio_pathelse:audio_input = f"file://{audio_path}"messages = [{"role": "system", "content": [{"text": ""}]},{"role": "user", "content": [{"audio": audio_input}]}]resp = dashscope.MultiModalConversation.call(model=self.model_name,messages=messages,result_format="message",asr_options={"enable_lid": True, # 语言识别"enable_itn": False # 逆文本标准化})try:text = resp["output"]["choices"][0]["message"].content[0]["text"]except Exception as e:text = "**ERROR**: " + str(e)return text, num_tokens_from_string(text)def stream_transcription(self, audio_path):"""流式语音识别"""import dashscopeif audio_path.startswith("http"):audio_input = audio_pathelse:audio_input = f"file://{audio_path}"messages = [{"role": "system", "content": [{"text": ""}]},{"role": "user", "content": [{"audio": audio_input}]}]stream = dashscope.MultiModalConversation.call(model=self.model_name,messages=messages,result_format="message",stream=True,asr_options={"enable_lid": True,"enable_itn": False})full = ""for chunk in stream:try:piece = chunk["output"]["choices"][0]["message"].content[0]["text"]full = pieceyield {"event": "delta", "text": piece}except Exception as e:yield {"event": "error", "text": str(e)}yield {"event": "final", "text": full}
ASR 选项说明:
enable_lid | ||
enable_itn |
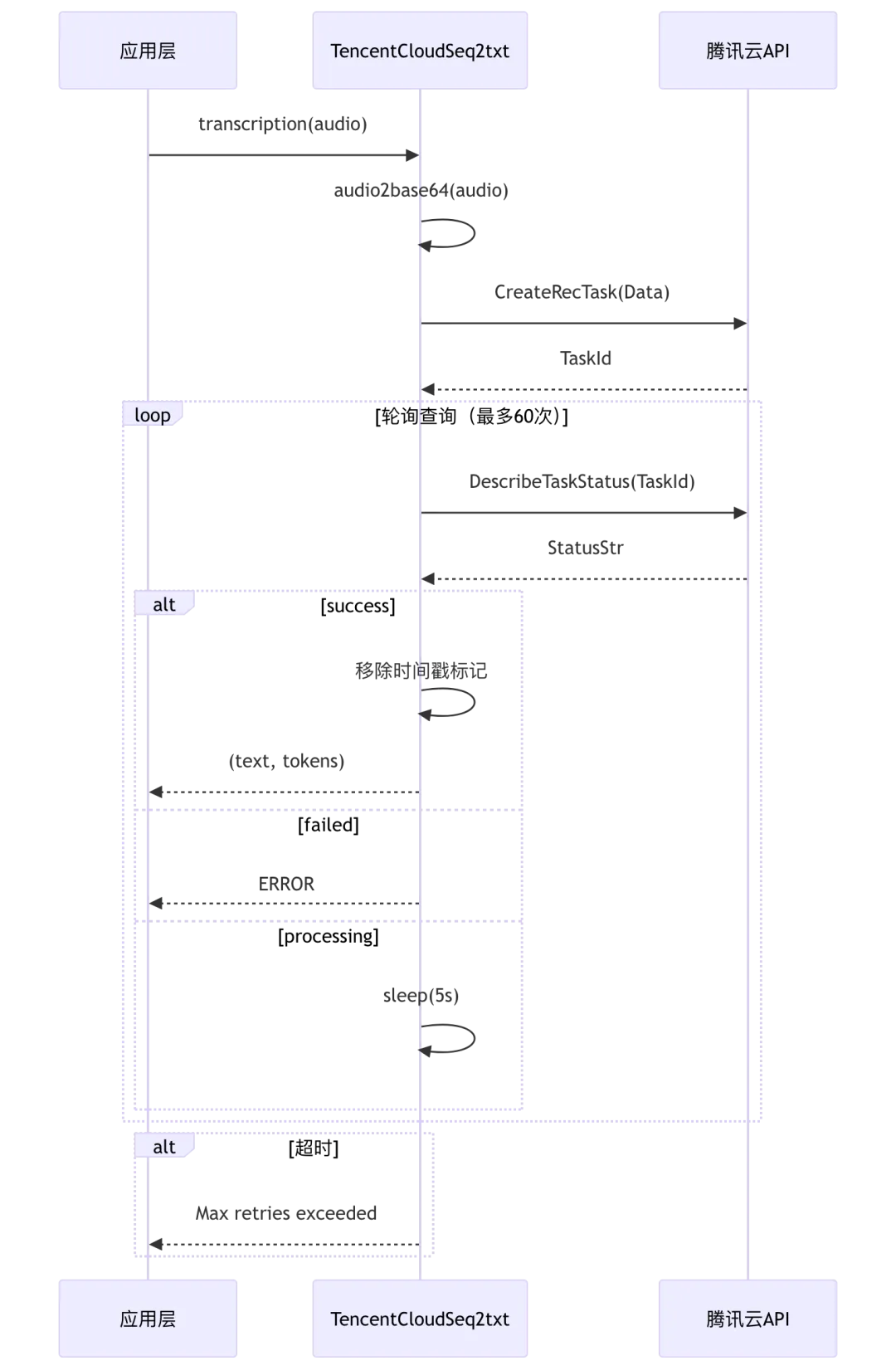
3.5 腾讯云 ASR 实现
源码位置: rag/llm/sequence2txt_model.py:201-260
class TencentCloudSeq2txt(Base):_FACTORY_NAME = "Tencent Cloud"def __init__(self, key, model_name="16k_zh", base_url="https://asr.tencentcloudapi.com"):from tencentcloud.asr.v20190614 import asr_clientfrom tencentcloud.common import credentialkey = json.loads(key)sid = key.get("tencent_cloud_sid", "")sk = key.get("tencent_cloud_sk", "")cred = credential.Credential(sid, sk)self.client = asr_client.AsrClient(cred, "")self.model_name = model_namedef transcription(self, audio, max_retries=60, retry_interval=5):import timefrom tencentcloud.asr.v20190614 import modelsfrom tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKExceptionb64 = self.audio2base64(audio)try:# 1. 提交识别任务req = models.CreateRecTaskRequest()params = {"EngineModelType": self.model_name,"ChannelNum": 1,"ResTextFormat": 0,"SourceType": 1,"Data": b64,}req.from_json_string(json.dumps(params))resp = self.client.CreateRecTask(req)# 2. 轮询查询结果req = models.DescribeTaskStatusRequest()params = {"TaskId": resp.Data.TaskId}req.from_json_string(json.dumps(params))retries = 0while retries < max_retries:resp = self.client.DescribeTaskStatus(req)if resp.Data.StatusStr == "success":# 移除时间戳标记 [00:00.000,00:05.000]text = re.sub(r"\[\d+:\d+\.\d+,\d+:\d+\.\d+\]\s*", "", resp.Data.Result).strip()return text, num_tokens_from_string(text)elif resp.Data.StatusStr == "failed":return "**ERROR**: Failed to retrieve speech recognition results.", 0else:time.sleep(retry_interval)retries += 1return "**ERROR**: Max retries exceeded. Task may still be processing.", 0except TencentCloudSDKException as e:return "**ERROR**: " + str(e), 0
异步识别流程:
3.6 智谱 ASR 实现
源码位置: rag/llm/sequence2txt_model.py:317-378
class ZhipuSeq2txt(Base):_FACTORY_NAME = "ZHIPU-AI"def __init__(self, key, model_name="glm-asr", base_url="https://open.bigmodel.cn/api/paas/v4", **kwargs):if not base_url:base_url = "https://open.bigmodel.cn/api/paas/v4"self.base_url = base_urlself.api_key = keyself.model_name = model_nameself.gen_conf = kwargs.get("gen_conf", {})self.stream = kwargs.get("stream", False)def _convert_to_wav(self, input_path):"""音频格式转换"""ext = os.path.splitext(input_path)[1].lower()if ext in [".wav", ".mp3"]:return input_pathfd, out_path = tempfile.mkstemp(suffix=".wav")os.close(fd)try:import ffmpegimport imageio_ffmpeg as ffmpeg_exeffmpeg_path = ffmpeg_exe.get_ffmpeg_exe()(ffmpeg.input(input_path).output(out_path, ar=16000, ac=1) # 16kHz, 单声道.overwrite_output().run(cmd=ffmpeg_path, quiet=True))return out_pathexcept Exception as e:raise RuntimeError(f"audio convert failed: {e}")def transcription(self, audio_path):payload = {"model": self.model_name,"temperature": str(self.gen_conf.get("temperature", 0.75)) or "0.75","stream": self.stream,}headers = {"Authorization": f"Bearer {self.api_key}"}converted = self._convert_to_wav(audio_path)with open(converted, "rb") as audio_file:files = {"file": audio_file}try:response = requests.post(url=f"{self.base_url}/audio/transcriptions",data=payload,files=files,headers=headers,)body = response.json()if response.status_code == 200:full_content = body["text"]return full_content, num_tokens_from_string(full_content)else:error = body["error"]return f"**ERROR**: code: {error['code']}, message: {error['message']}", 0except Exception as e:return "**ERROR**: " + str(e), 0
音频格式转换:
3.7 ASR 提供商汇总
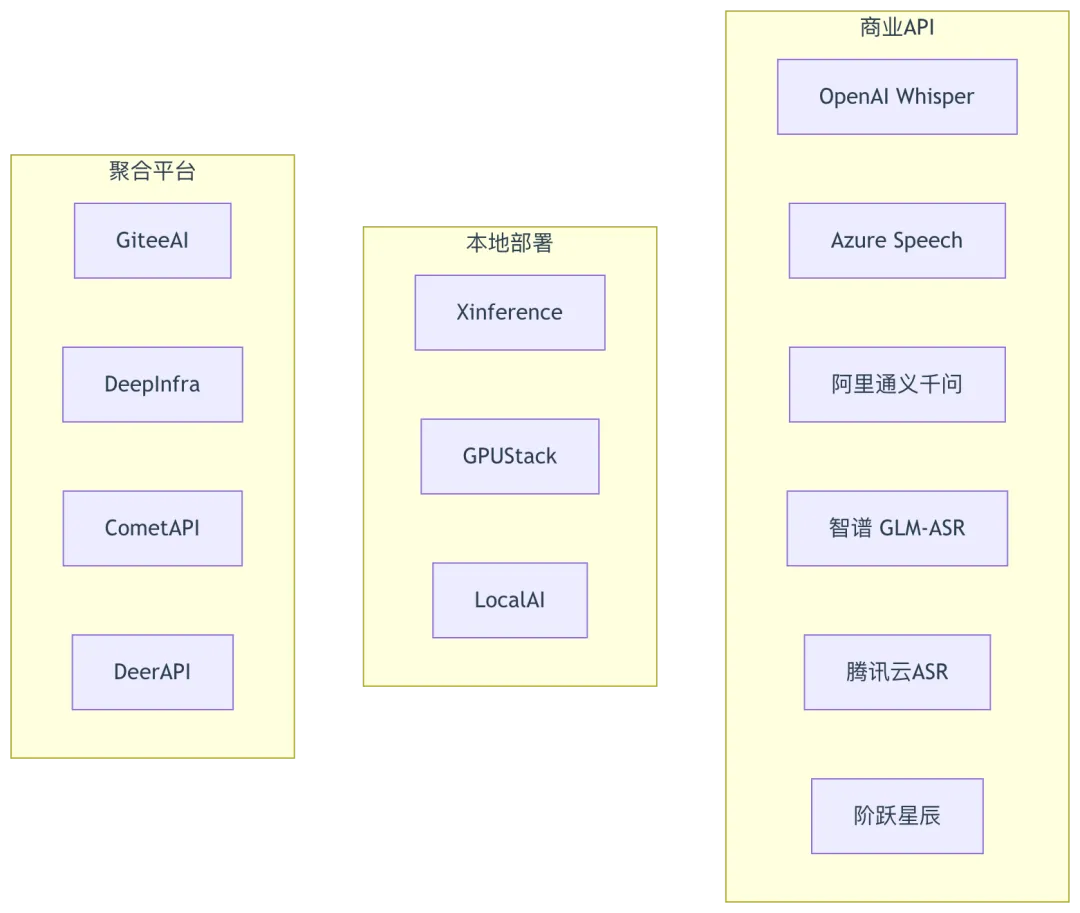
四、设计模式总结
4.1 策略模式
OCR/CV/ASR 模型采用策略模式,通过统一的接口支持多种实现:
# 统一接口class Base:def describe(self, image): ...def transcription(self, audio_path): ...def parse_pdf(self, filepath): ...# 不同策略实现class GptV4(Base): ...class GeminiCV(Base): ...class OllamaCV(Base): ...
4.2 工厂模式
每个模型类通过 _FACTORY_NAME 标识,支持动态实例化:
classGptV4(Base):_FACTORY_NAME = "OpenAI"classGeminiCV(Base):_FACTORY_NAME = "Gemini"# 根据工厂名称创建实例MODEL_MAP = {"OpenAI": GptV4,"Gemini": GeminiCV,...}model = MODEL_MAP[factory_name](key, model_name, **kwargs)
4.3 适配器模式
不同 API 提供商的响应格式通过适配器统一:
# OpenAI 格式return res.choices[0].message.content.strip(), total_token_count_from_response(res)# Anthropic 格式return response["content"][0]["text"].strip(), response["usage"]["input_tokens"] + response["usage"]["output_tokens"]# Gemini 格式return res.text, total_token_count_from_response(res)
五、错误处理与重试机制
5.1 配置化重试参数
class Base(ABC):def __init__(self, **kwargs):# 配置重试参数self.max_retries = kwargs.get("max_retries", int(os.environ.get("LLM_MAX_RETRIES", 5)))self.base_delay = kwargs.get("retry_interval", float(os.environ.get("LLM_BASE_DELAY", 2.0)))self.max_rounds = kwargs.get("max_rounds", 5)
5.2 多端点故障转移
def _process_video(self, video_bytes, filename):try:return call_api() # 默认端点except Exception as e1:# 切换到备用端点dashscope.base_http_api_url = "https://dashscope-intl.aliyuncs.com/api/v1"try:return call_api()except Exception as e2:raise RuntimeError(f"Both default and intl endpoint failed.\nFirst error: {e1}\nSecond error: {e2}")
5.3 敏感信息脱敏
# 日志输出前脱敏redacted_config = {}for k, v in config.items():if any(sensitive_word in k.lower() for sensitive_word in ("key", "password", "token", "secret")):redacted_config[k] = "[REDACTED]"else:redacted_config[k] = vlogging.info(f"Parsed config (sensitive fields redacted): {redacted_config}")
六、性能优化策略
6.1 视频处理优化
6.2 异步处理
# 同步客户端self.client = OpenAI(api_key=key, base_url=base_url)# 异步客户端self.async_client = AsyncOpenAI(api_key=key, base_url=base_url)# 异步方法async def async_chat(self, system, history, gen_conf, images=None, **kwargs):response = await self.async_client.chat.completions.create(...)return response.choices[0].message.content.strip(), total_token_count_from_response(response)
6.3 流式输出
async def async_chat_streamly(self, system, history, gen_conf, images=None, **kwargs):response = await self.async_client.chat.completions.create(model=self.model_name,messages=self._form_history(system, history, images),stream=True,extra_body=self.extra_body,)async for resp in response:if not resp.choices[0].delta.content:continuedelta = resp.choices[0].delta.contentans = deltayield ans
七、总结
RAGFlow 的多模态模型架构体现了以下核心设计原则:
- 可扩展性
: 支持 25+ CV 模型、12+ ASR 服务、2+ OCR 引擎 - 统一接口
: Base 基类定义标准 API,子类实现特定逻辑 - 配置灵活
: 支持环境变量、JSON配置、参数传递多种方式 - 错误容错
: 多端点故障转移、敏感信息脱敏、详细日志记录 - 性能优化
: 异步处理、流式输出、大文件特殊处理
这种架构设计使 RAGFlow 能够灵活应对各种多模态数据处理需求,为 RAG 应用提供了强大的文档理解能力。
