 夜雨聆风
夜雨聆风中国AI每天吃掉140万亿个词元Token!高速增长下有哪些财富机会?
140万亿词元Token。
这个数字我盯着看了十秒,是的,我没看错,你也不要怀疑!
国家数据发展研究院副院长袁军昨天接受采访时说的:中国AI模型日均词元Token调用量突破140万亿。
什么概念?
如果把这些词元Token全部生成4K高清电影,相当于每天拍出1.7万部《流浪地球2》。
每天。不是每年。
这意味着中国的人工智能,已经从"实验室里的技术概念",变成了一台每天消耗巨量算力的永动机。
词元Token是什么?为什么突然这么重要?
你可能觉得"词元Token"是个技术术语,离你很远。
但其实词元Token已经变成了AI时代的"水电煤"——你看不见它,但每分每秒都在用。
你在手机上跟AI对话一次,消耗几百词元Token。
你让AI帮你做一份PPT大纲,消耗几千词元Token。
你公司接入大模型API做客服,一天烧掉几十万词元Token。
以前企业采购软件,是买断制或者年费制。现在变成了——按词元Token付费。用多少,交多少,就跟交电费一样。
袁军说得特别到位:以前衡量一个产品牛不牛,大家看的是日活、月活。但在AI时代,厂商不只要拼用户量,更要拼谁用更少的词元Token办更多的事。
你用1000词元Token能解决的问题,别人用500词元Token就搞定了——那你就贵了一倍。
词元Token使用效率,正在成为AI公司的核心竞争力。
我为什么觉得这条新闻很重要
不是因为它数字大。而是因为这组数据的背景——它来自国家数据发展研究院。
这个机构是什么角色?它是国家数据局下属的正局级事业单位,负责制定国家数据标准和基础设施规划。他们出来讲词元Token,不是在炫技,是在画路线图。
同一篇采访里,袁军透露了几件大事:
第一, 国家数据集管理服务平台已经上线试运行。以后AI训练用的高质量数据,不再是谁家自己闷头搞,而是国家层面统一调度。解决"有数据但看不懂、有场景但喂不饱"的问题。
第二, "算电协同"创新联合体刚刚成立。西部绿电便宜但没人用,东部算力紧张但等电。联合体要打通这个堵点——说白了,就是让AI算力跑得更便宜、更绿色、更可持续。
第三, 袁军评价词元Token时用了三个字:"水电煤。"
这三个字是我今天最想聊的。
从"技术符号"到"基础设施"
词元Token变成水电煤,意味着什么?
你去超市买一瓶水,不会问这个牌子的水跟那个牌子的水"毫升数是不是一样"。因为计量标准是统一的。你用一度电,不会担心这个电网的一度电比那个电网少。
但词元Token到现在为止,还不是。
我前面那篇文章写了——各家厂商对词元Token的定义不一样,计价规则不一样,连损坏赔偿条款都各玩各的。这对大厂来说麻烦,对中小企业来说更是噩梦。

你花一万块钱买了A厂商的词元Token套餐,发现效率比B厂商低了30%。你想换,但词元Token不能退。你想维权,条款写的是"最终解释权归本公司所有"。
这就是基础设施没建好之前的样子。
而袁军透露的信息里,隐含了一条清晰的主线——国家正在把词元Token从"各家自定义的商品",变成全国统一标准的"基础设施要素"。
一旦标准化落地,词元Token就能像水电一样,统一计量、统一计价、跨厂商流通。
到时候,企业选AI服务商,就像选手机套餐一样简单:看性价比、看服务、看口碑。不用再担心被"词元Token刺客"宰一刀。
说说我这个老客户的后续
前阵子来的那个高德地图标注客户,四十号人满城跑地推,月营收200万,想通过数据资产贷500万。
我前两天又跟他聊了一次。
他说他想通了——贷款先放一放,先把业务数字化做起来。问我要不要试试AI。
我说你终于开窍了。
140万亿个词元Token每天在中国大地上被消耗,这说明什么?说明AI已经便宜到人人都用得起了。你那些地推人员跑一天,一人能跑20家商户。但一个AI电话机器人,一天能打2000个。你那些标注数据,人工处理一单要十分钟。AI跑一遍,三秒。
不是要你裁人。是要你把人的精力,从重复劳动中解放出来,去做AI做不了的事——谈客户、做关系、想策略。
他沉默了一会儿,说回去试试。
这大概就是我今天最想表达的吧——
140万亿这个数字,离你很近。
近到它正在改变你明天的工作方式。
而你要做的,就是别再假装它跟你无关了,你要的是立刻行动起来!

DeepSeek继续霸榜!中国大模型词元Token用周调用量连续五周超越美国:DeepSeek大模型位居全球调用榜榜首!数据背后隐藏了哪些造富机会?
根据OpenRouter最新数据测算,上周(5月25日至5月31日)全球AI大模型总调用量为31.8万亿词元Token,较此前一周增长10%,词元Token调用量已连续六周上涨,大模型词元Token调用需求仍在持续释放,中国大模型的词元Token调用量还在持续高速增长。
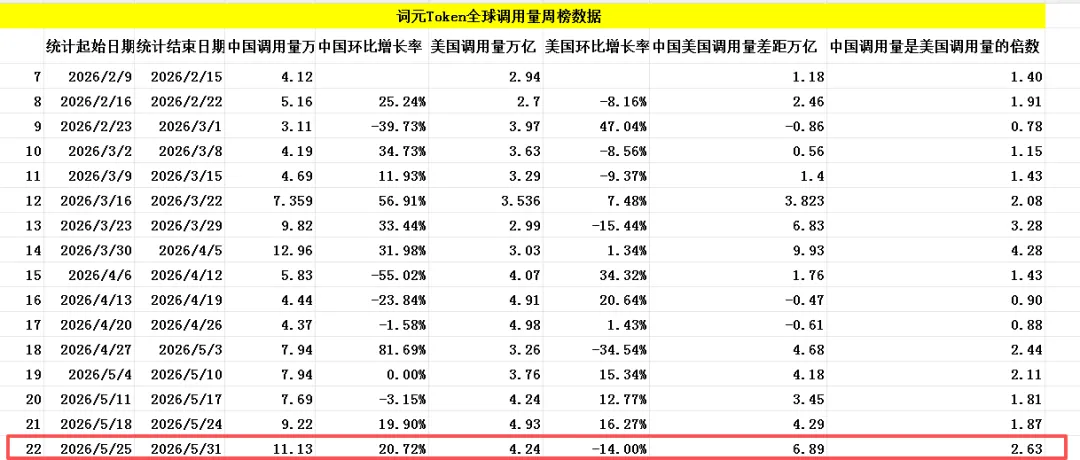
根据粤桂大数据提供的词元Token全球调用量周榜数据汇总,上榜的AI大模型中,中国AI大模型周调用量达11.13万亿词元Token,环比增长高达20.72%,同期美国AI大模型周调用量为4.24万亿词元Token,环比下跌了14%。从数据对比来看,中国大模型周调用量还是远超美国,再次以2.63倍遥遥领先,这已经是连续五周实现反超并稳居全球首位。
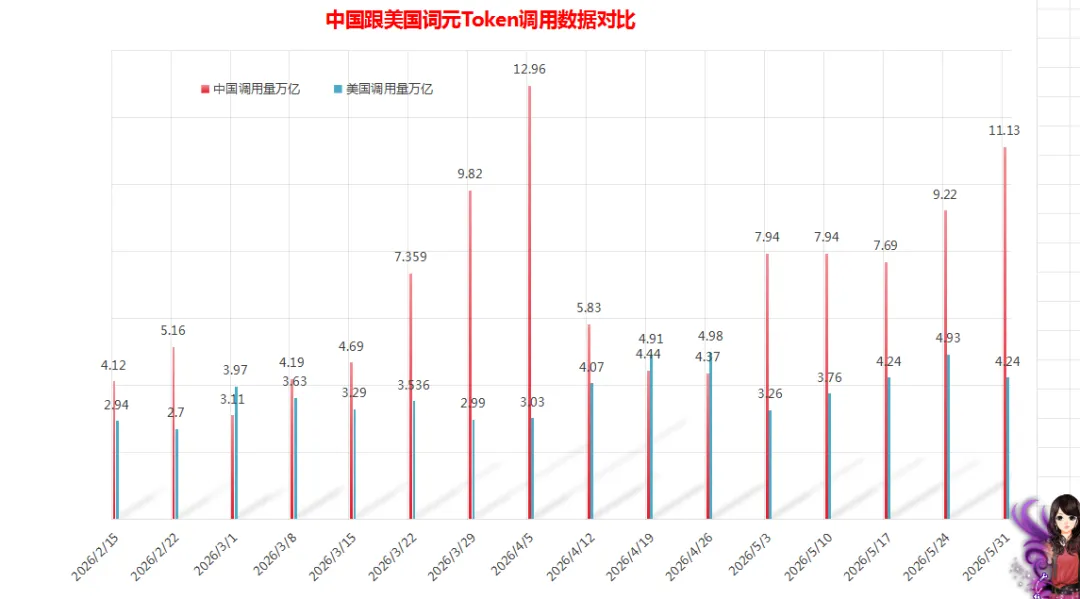
粤桂大数据记录的中国跟美国词元Token调用数据对比
那现在进入人工智能时代,未来会以什么来表征人工智能的财富呢?
在人工智能时代,这一关键指标正变为词元Token——用户输入的每一个字,模型生成的每一段话、识别的每一幅图像,都在消耗词元Token。
怎么理解词元Token?简单来说,词元是人工智能大模型为了高效处理数据,把数据进行拆分后的“最小信息载体”,可以理解为“字/词片段/符号”等。比如“我爱中国!”,可拆分成“我”“爱”“中国”“!”4个词元,大家注意到没有,中国两个字居然是一个词元Token。

总之一句:中国人工智能发展迅速,以大模型调用量的大爆发来说,这里面隐藏了未来更多的投资机会,在人工智能特别是算力领域我们的机会才刚刚开始。

热门话题人工智能领域算力之词元Token:
DeepSeek继续霸榜!中国大模型词元Token用周调用量连续五周超越美国:DeepSeek大模型位居全球调用榜榜首!数据背后隐藏了哪些造富机会?
稳居全球首位!中国大模型词元Token用周调用量连续四周超越美国:DeepSeek大模型问鼎全球调用榜!数据背后隐藏了哪些造富机会?
利好来了!全线大涨!美伊,突传大消息!科创板盛宴你参与了吗?华为 “韬(τ)定律”影响深远!
稳居全球首位!中国大模型词元Token用周调用量连续三周超越美国:腾讯Hy3 preview大涨210%登顶!数据背后隐藏了哪些造富机会?
时隔两周,词元Token调用中国再超美国!腾讯混元Hy3 Preview大模型霸榜!数据背后隐藏了哪些造富机会?
国家数据局:指数级增长 2025年我国词元调用量约21100万亿
全球上周(4月20日至26日)词元TokenAI大模型调用量回升,美国模型调用量继续领先中国,DeepSeek这周能否力挽狂澜?
DeepSeek-V4问世,中美AI的天要变了!黄仁勋预言的灾难仅9天梁文锋就帮他成真了!
厉害了!指数级增长 2025年我国词元Token调用量约21100万亿!数据背后隐藏了哪些造富机会?
全球上周(4月20日至26日)词元TokenAI大模型调用量回升,美国模型调用量继续领先中国,DeepSeek这周能否力挽狂澜?
DeepSeek-V4问世,中美AI的天要变了!黄仁勋预言的灾难仅9天梁文锋就帮他成真了!
国家数据局:拟探索词元交易等新型交易模式,词元Token未来到底有哪些机会?
1.信息处理量
词元(token)是大语言模型处理信息的基本单位,用于衡量输入文本(如用户提问)和输出文本(如模型生成的回答)的规模。例如,一段文字被拆分为多个词元(Token),词元(token)数量越多,表示处理的信息量越大。词元(token)正成为衡量AI工作量的核心单位,其经济价值推动算力产业链变革,上游芯片与服务器厂商受益,下游企业则面临成本压力,倒逼技术优化与国产算力替代进程加速。
2.算力消耗
模型每处理一个词元(token),都需要消耗一定的计算资源(如GPU算力、内存等)。因此,词元(token)数量直接反映了模型运行时的算力消耗程度,是衡量计算成本的重要指标。
3.服务计费依据
在AI服务商业化场景中,词元(token)通常作为计费单位。服务提供商根据用户消耗的词元(token)数量收取费用,用户使用越复杂、越长的任务,消耗的词元(token)越多,费用也越高。简而言之,词元(token)既是技术层面衡量信息处理和算力使用的单位,也是商业层面衡量AI服务价值和成本的核心指标。
你对人工智能的未来发展有什么看法?
欢迎评论区留言交流
以上所有内容仅供投资者学习交流用,不作为投资建议。股市有风险投资需谨慎!
