夜雨聆风
夜雨聆风
6月1日,GTC 台北。
黄仁勋站在台上,用 90 分钟描绘了一幅宏大的 AI 工厂蓝图:Vera Rubin 全面量产、Token 就是资产、1GW 算力集群值 1000 亿美元。

台下掌声雷动,英伟达股价应声上涨2.7%。
但有一个问题,他整场演讲只字未提——
那些 7×24 小时烧到 80℃ 的 GPU ,坏了怎么办?
在国外,大客户走官方 RMA,坏了换新,售后体系完善。
但在国内,大量企业手里的卡来自并行渠道、分区域版本——官方保修不覆盖,返厂无门。
Vera Rubin 再强,Blackwell 再快,它们本质都是物理器件。会老化、会虚焊、会掉核心、会在你最需要算力的时候突然"躺平"。
AI 工厂的本质不是算力,是算力的可用率。
而国内算力运营者面临的现实是:
一块企业级 GPU 躺平,训练延迟数天,几十万算力成本蒸发——然后发现,没人给你保修。
而可用率的命门,恰恰藏在黄仁勋演讲里唯一没放的那页 PPT 上——GPU 维修。

1
存量GPU不会消失,只会越积越多
黄仁勋明确表示,Vera Rubin 已经全面量产,OpenAI、Anthropic、SpaceX 成为首批客户。
这当然是大新闻。但更值得注意的,是演讲中没有明说的一句话:
Blackwell不会退役,它只会被更大规模的集群继续使用。
AI 算力的军备竞赛,不是"换掉旧卡",而是"不断叠加新卡"。
全球数据中心里,H100、H200、B200 等上一代 GPU仍在 7×24 小时满负荷运转。
它们的故障率不会因为新架构发布而降低,反而会在持续高压下逐渐升高。
这,正是 GPU 维修需求持续走强的底层逻辑。
大量通过非官方渠道流入的 GPU ——没有发票、没有区域保修、序列号不在本地售后数据库——坏了就是一块“电子砖头”。
据行业观察,国内专注 GPU 芯片级维修的服务商如维云信息科技,其业务逻辑正是基于这一趋势——修的从来不是“过时卡”,而是仍在生产第一线创造价值、但官方售后覆盖不到的算力资产。

2
AI工厂时代,算力是资产,资产就需要维护
黄仁勋用了一整个段落来讲 AI 工厂的经济账:
1GW 等级的 AI 工厂,起步成本 200 亿至 300 亿美元,未来甚至可能达到 800 亿至 1000 亿美元。
他还抛出一个核心观点:Token 就是资产。

按照这个逻辑推导,结论非常直接:
生产Token的设备——GPU——就是AI工厂里最核心的生产资料。
任何一家企业,花几十亿、几百亿美元建成 AI 工厂后,最不愿意看到的,就是某一块 GPU 因为局部故障导致整机下线、算力闲置、训练中断。
而 GPU 的高密度、高功耗、高发热特性,决定了它本身就是系统中故障率最高的组件之一。
国外客户可以依赖官方质保,但国内大量非官方渠道的卡,坏了就是纯损失。
业内已有服务商提出“算力资产维护”概念,将 GPU 维修从“修不修得起”的问题,重新定义为“在国内硬件流通环境下,不修就等于报废”的问题。
3
黄仁勋没明说,但现实存在的
"GPU维修三角"
综合整场演讲,可以提炼出一个非常现实的矛盾三角:
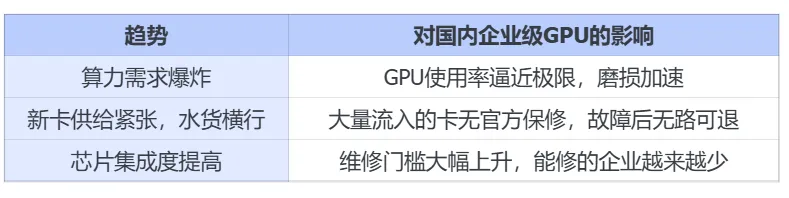
三个趋势叠加的结果:
算力越贵,旧卡越要修;官方保修覆盖不到,专业维修就是刚需;芯片越集成,能接得住的企业越少。
这恰恰是国内专业 GPU 维修服务最真实的存在价值。
写在最后
黄仁勋在这场演讲中,几乎没提"维修"两个字。
但任何有经验的技术人都知道:越是先进的系统,越离不开可靠的后端维护。
如果你也在运营算力集群,心里一定清楚:
哪批卡跑得最烫,哪款型号返修率最高,哪次故障让你最头疼——尤其是那些明明没坏透、但官方售后根本不管的卡。
这些东西黄仁勋不会讲,但我们这帮干维修的天天见。
有类似经历或难题,欢迎来交流。