 夜雨聆风
夜雨聆风本期目录
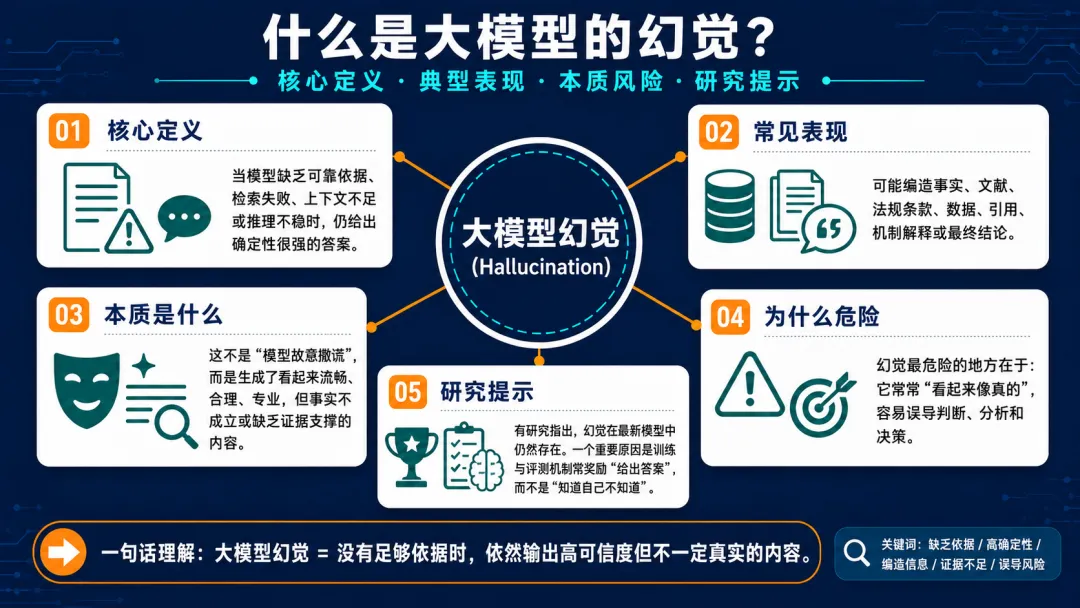
一、什么是大模型幻觉
二、产生幻觉的原因有哪些?
三、科研学术场景AI幻觉的表现形式
四、AI幻觉如何避免或缓解?
五、国内外通用大模型交叉验证缓解AI幻觉的测评
引言
AI 正以前所未有的速度渗透、整合并深度重塑各行各业,技术的持续突破带来革命性变革,从产业结构、工作流程到学习方式、思维模式,都被全面重构与升级。AI 的设计初衷并非替代人类,而是延伸人类能力、增强人类智慧、放大个体价值,协作是人与 AI 关系的基本原则,人机协作共同解决问题。
 (俗称牛马
(俗称牛马 ),面对突飞猛进的AI技术,也在积极的拥抱新技术,赋能到工作与学习,提高效率和个人能力,拓展能力边界,一些感悟和使用体验,分享给大家。
),面对突飞猛进的AI技术,也在积极的拥抱新技术,赋能到工作与学习,提高效率和个人能力,拓展能力边界,一些感悟和使用体验,分享给大家。
 。
。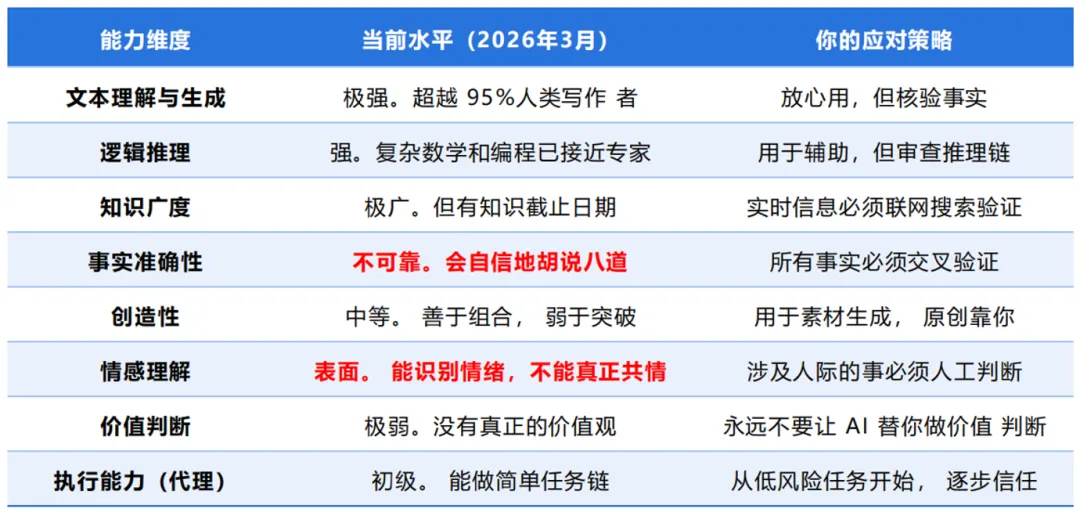
上图引用自厦门大学《智能体OpenClaw(小龙虾)应用实践》
当前大模型强于文本理解与生成、逻辑推理、知识广度等,但在事实准确性、情感理解等还是存在明显的不足。
事实准确性也就是大家常说的幻觉+知识过时问题。知识过时可以通过联网搜索解决,但是AI幻觉会让人难以判别,因为AI可以一本正经的胡说八道,编造根本就不存在的定理、指导原则和参考文献,尤其是在严肃的学术科研及其他专业场景,例如在药物分析、法规、文献解读、申报资料等场景里,它的风险很高,因为错误往往不是低级错误
目前大家对AI使用最普遍还是生活场景,作为日常聊天搭子,帮孩子批改作业,科普概念、搜索信息(代替百度),提供情绪价值等等,在此场景下,幻觉率容忍度大大提升。当然了,也有人完全信任AI,被忽悠,遭受损失,比如最近豆包的“飞机票”和“毒蘑菇”事件。

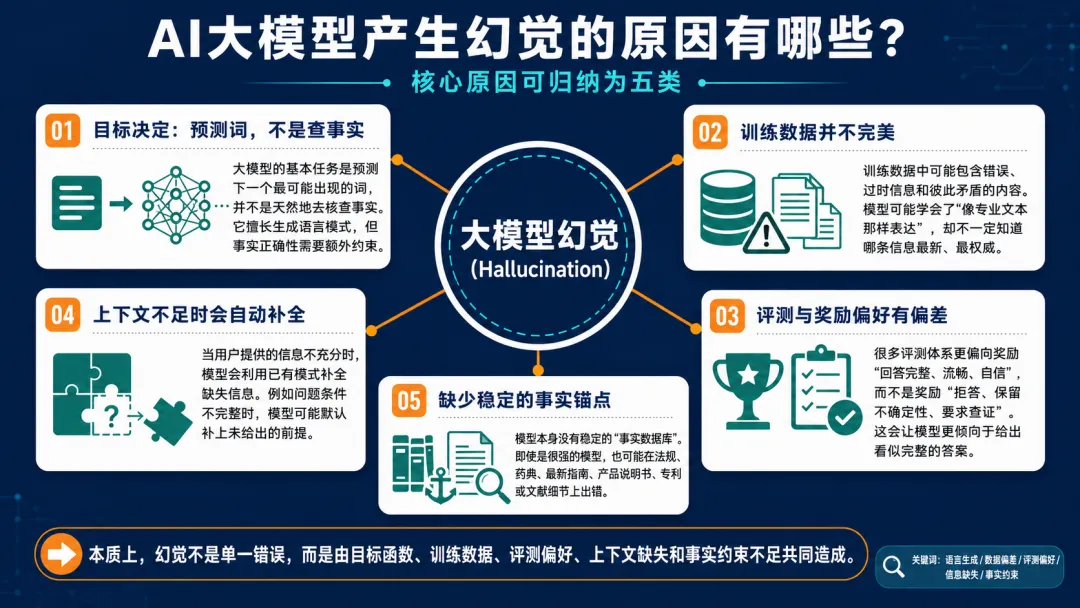
核心原因有5类:
1、大模型的基本任务是预测下一个最可能出现的词,不是天然地“查事实”。它擅长生成语言模式,但事实正确性需要额外约束。
2、训练数据中存在错误、过时信息、互相矛盾的信息。模型可能学到“像专业文本的表达方式”,但不一定知道哪条信息是最新、最权威的。
3、很多评测体系更偏向奖励“回答完整、流畅、自信”,而不是奖励“拒答、保留不确定性、要求查证”。
4、上下文不足时,模型会用已有模式补全缺失信息。比如用户只问“这个限度计算的对吗”,但没有给出其他关键信息,模型就可能自动补全条件。
5、模型本身没有稳定的“事实数据库”。即使是很强的模型,也可能在法规、药典、最新指南、产品说明书、专利、文献细节上出错。
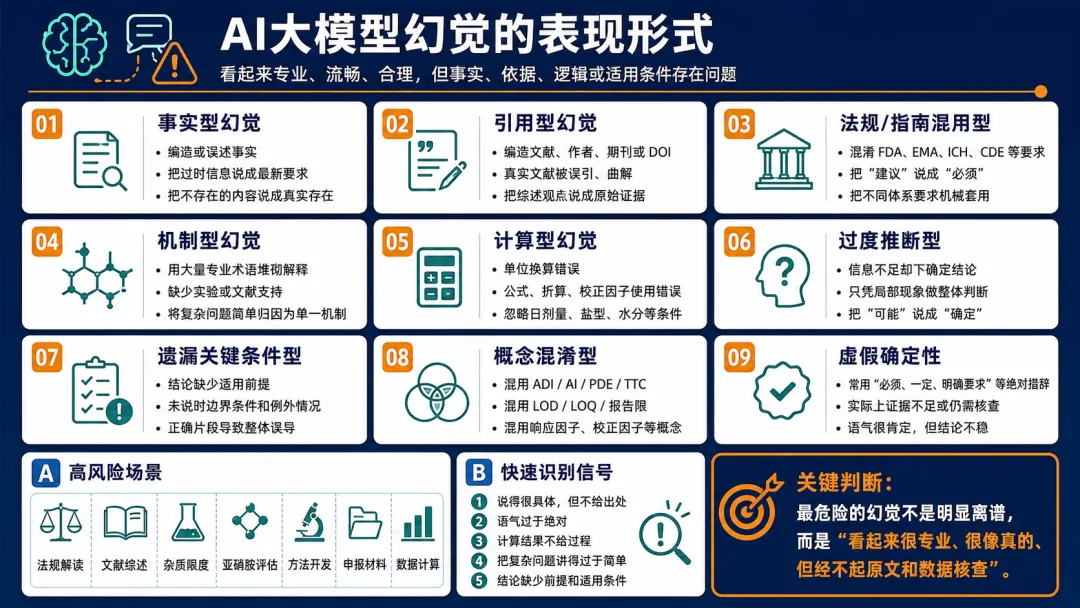
主要表现有 9 类:
模型会把不存在、不准确或过时的信息说成事实。
典型表现
模型会编造文献、法规、指南、DOI、作者、期刊,或者引用真实文献但歪曲原文内容。
典型表现
典型表现
典型表现
典型表现
典型表现
有时模型的结论本身不是完全错,但缺少重要前提,导致实际使用时会误导。
典型表现
模型在不确定时,仍然用非常确定的语气回答。
典型表现-这些词在专业场景里都要警惕
模型在不确定时,仍然用非常确定的语气回答。
典型表现-这些词在专业场景里都要警惕
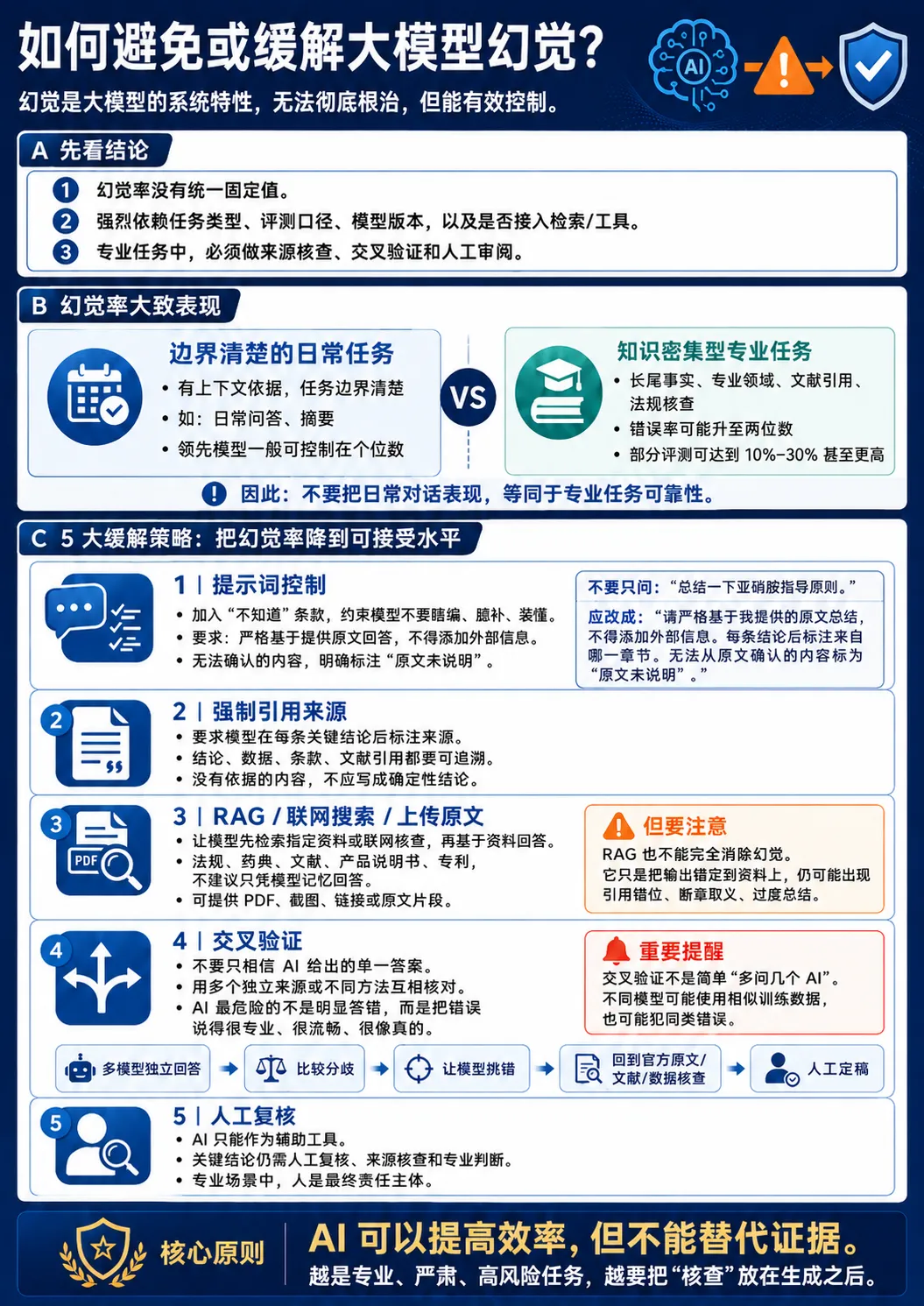
幻觉是大模型的系统特性,无法彻底根治,但能有效控制。
目前主流 AI 模型的幻觉率并没有一个统一固定值,强烈依赖任务类型、评测口径、模型版本和是否接入检索/工具。一般而言,在有上下文依据、任务边界清楚的日常问答或摘要场景中,领先模型的幻觉率可控制在个位数;但在知识密集型、长尾事实、专业领域、文献引用和法规核查等任务中,错误率可能升至两位数,部分评测可达到 10%–30%甚至更高。因此,专业任务中仍需要来源核查、交叉验证和人工审阅。
缓解策略-将幻觉率降到可接受水平(可类比制剂中的NDSRI的控制策略)
1、提示词控制-加入“不知道”条款:管住 AI“爱瞎编、爱脑补、爱装懂,不会说不知道” 的毛病。如:不要只问:“总结一下亚硝胺指导原则。”应改成:“请严格基于我提供的原文总结,不得添加外部信息。每条结论后标注来自哪一章节。无法从原文确认的内容标为‘原文未说明’。”
2、强制引用来源-要求模型每条关键结论后都标注来源
3、使用检索增强生成(RAG)/联网搜索/上传原文-让模型先检索指定资料或联网搜索,再基于资料回答。对于法规、药典、文献、产品说明书、专利,不建议让模型凭记忆回答。应提供原文 PDF、截图、链接,或要求联网核查。
但注意:RAG 也不能完全消除幻觉。它只是把模型输出锚定到资料上,仍然可能出现引用错位、断章取义、过度总结。
4、交叉验证-不要只相信 AI 给出的单一答案,而是用多个独立来源或不同方法互相核对,确认结论是否可靠。因为AI 最危险的不是“明显答错”,而是它可能把错误内容说得非常专业、非常流畅、非常像真的。
交叉验证不是“多问几个 AI”,这不一定可靠,因为不同模型可能来自相似训练数据,也可能犯同类错误。当然了使用多个 AI 模型交叉验证,也是一个很好的防幻觉策略;但只能提高发现错误的概率,不能证明答案一定正确。
最稳妥的做法是:多模型独立回答 → 比较分歧 → 让模型挑错 → 回到官方原文/文献/数据核查 → 人工定稿。
5、人工复核-无论使用哪类模型,AI 都只能作为辅助工具,关键结论仍然需人工复核、来源核查和专业判断。
五、国内外通用大模型交叉验证缓解AI幻觉的测评
5.1、测试方式-对AI回答内容进行不同AI模型的交叉验证
5.2、测评模型-均为网页版,开启思考模式,联网搜索,测评的AI模型为本文发表时间时的最新版本(多版本选择最新,如qwen3.7max)豆包:https://www.doubao.com/chat/ 千问:https://www.qianwen.com/ kimi:https://www.kimi.com/ Deepseek:https://chat.deepseek.com/ MiniMax:https://agent.minimaxi.com/ 文心一言:https://yiyan.baidu.com/ 腾讯元宝:https://yuanbao.tencent.com/chat 阶跃AI(事实核查功能):https://chat.stepfun.com/chats/new 
智谱清言:https://chatglm.cn/ 秘塔:https://metaso.cn/ 秘塔(事实核验功能):https://metaso.cn/fact 扣子:https://www.coze.cn/
Perplexity:https://www.perplexity.ai/
测评各通用AI模型对以上错误是否可以明确指出,对具体错误细节逐条核实,给出明确的结论。
模型名称 | 核查结论 | 是否指出英文为编造 |
豆包 | 核心文件信息错误 | 是 |
千问 | 亚硝胺类杂质控制相关指导文件的发布时间和核心内容存在明显错误 | 是 |
Kimi | 经核查,您提供的文件信息及引文存在多处严重失实 | 是 |
Deepseek | 用户提供的英文内容存在多处事实性错误和不符合中国官方文件原文的情况。总体而言,内容半真半假,存在虚构或严重错误 | 是 |
Minimax | 用户提供的"关键原文"严重失实 | 是 |
文心一言 | 该英文节选基本准确,核心数据与官方文件一致,但有一处表述需注意 | 否 |
腾讯元宝 | 你这段「英文节选」不是NMPA/CDE《化学药物中亚硝胺类杂质研究技术指导原则(试行)》的官方条文,更接近把EMA/FDA框架下的数字(26.5ng/day、1000ng/day量级等)与ICHM7的通用TTC=1.5µg/day混编后,硬套了一个CDE文件名壳的二次加工文本。不能直接当作中国官方法规依据来引用。 | 是 |
阶跃AI(事实核查功能) | 本次核查共涉及16项关键陈述,其中8项判定为不可靠,4项判定为可靠,4项因证据不足或属于特定语境下的合理引申判定为基本可靠/无法判断 | 是 |
智谱清言 | 你给的这段英文节选,不是《化学药物中亚硝胺类杂质研究技术指导原则(试行)》的官方英文版,也不是该指导原则的准确翻译;其中关于“默认1.5μg/day、非挥发性26.5ng/day、挥发性1000ng/day”等关键数值与现行中国、FDA和ICH的官方要求不一致,属于明显错误或混用了其他指南。2.1节“风险评估基本原则”的表述,与中文原文的精神大体相符,但属于概括性改写,而不是逐字翻译。 | 是 |
秘塔 | 用户提供的"官方英文版节选"不是中国NMPA《化学药物中亚硝胺类杂质研究技术指导原则(试行)》的内容,而是来源于美国FDA及EMA等国外监管机构的指南 | 是 |
秘塔(事实核验功能) | 共查验9项,6项已证实、2项查无实据、1项不属实 | 否 |
扣子 | 核查完了,结果挺让人无语的-这份"关键原文"基本上对不上CDE官方文件,里头掺杂了大量与真实文件相反或无关的内容 | 是 |
Gork | 信息部分真实,但存在关键不准确之处 | 否 |
Chatgpt | 你给出的这段“核心文件+官方英文版节选”真实性很低,不能作为官方原文引用。它混合了部分真实监管概念,但文件年份、文件名称、章节结构、限度表述和“官方英文版”均存在明显问题。 | 是 |
Gemini | 该信息严重失实,存在明显的虚构与常识性错误(极大概率为AI幻觉生成的伪造文本) | 是 |
perplexity | 你给出的这段“官方英文版节选”与现有公开原文不完全一致,且有几处明显混写或转述偏差 | 是 |
核心三原则:
1、多模型一致 ≠ 事实正确。 2、多模型不一致 = 必须核查。 3、专业结论最终必须回到原始证据。

