 夜雨聆风
夜雨聆风AI DAILY / 2026.06.06
AI 不是自来水
当巨头也在临时补算力,小团队更不该把每个按钮都设计成“随便问大模型”。
今天的几条 AI 新闻,表面上都很大:Google 要向 SpaceX 购买一大笔算力,Anthropic 在 IPO 前继续回应外界对 AI 回报的怀疑,另一边,一些创业公司反而在做“让人少看手机”的产品。
如果只看热闹,很容易得出一句空话:AI 竞争越来越烧钱。但这句话对普通团队没什么帮助。
我更想把它翻译成一个产品问题:你的 AI 功能,是不是默认了两样东西无限供应?一个是算力,一个是用户注意力。
今天的判断:下一阶段好用的 AI 产品,不是把大模型塞进每个入口,而是知道哪里该调用、哪里该缓存、哪里该降级、哪里干脆别打扰用户。

先承认:AI 调用不是免费水龙头
TechCrunch 报道,Google 将从 2026 年 10 月到 2029 年 6 月向 SpaceX 支付每月 9.2 亿美元,换取约 11 万块 NVIDIA GPU 以及相关算力组件的访问权。Google 的说法是,它最近推出的 AI 产品需求超出预期,需要一段“桥接容量”。
这个细节很有意思。Google 本来就是最有算力家底的公司之一,仍然需要临时补容量。它提醒我们:AI 产品的约束,不只在模型能力,也在推理容量、排队延迟、峰值请求和预算纪律。
小团队当然不需要讨论几十亿美元的合同。但你需要讨论同一类问题:用户一打开页面,哪些地方一定要实时调用大模型?哪些地方可以提前生成?哪些地方命中缓存就够了?哪些地方失败时可以给一个普通搜索、规则模板或人工入口?
必须实时:用户刚输入的个性化问题、需要当前上下文的复杂判断。
可以缓存:固定知识解释、常见操作建议、重复报表总结。
应该降级:低价值闲聊、批量峰值任务、非关键页面装饰型 AI 文案。
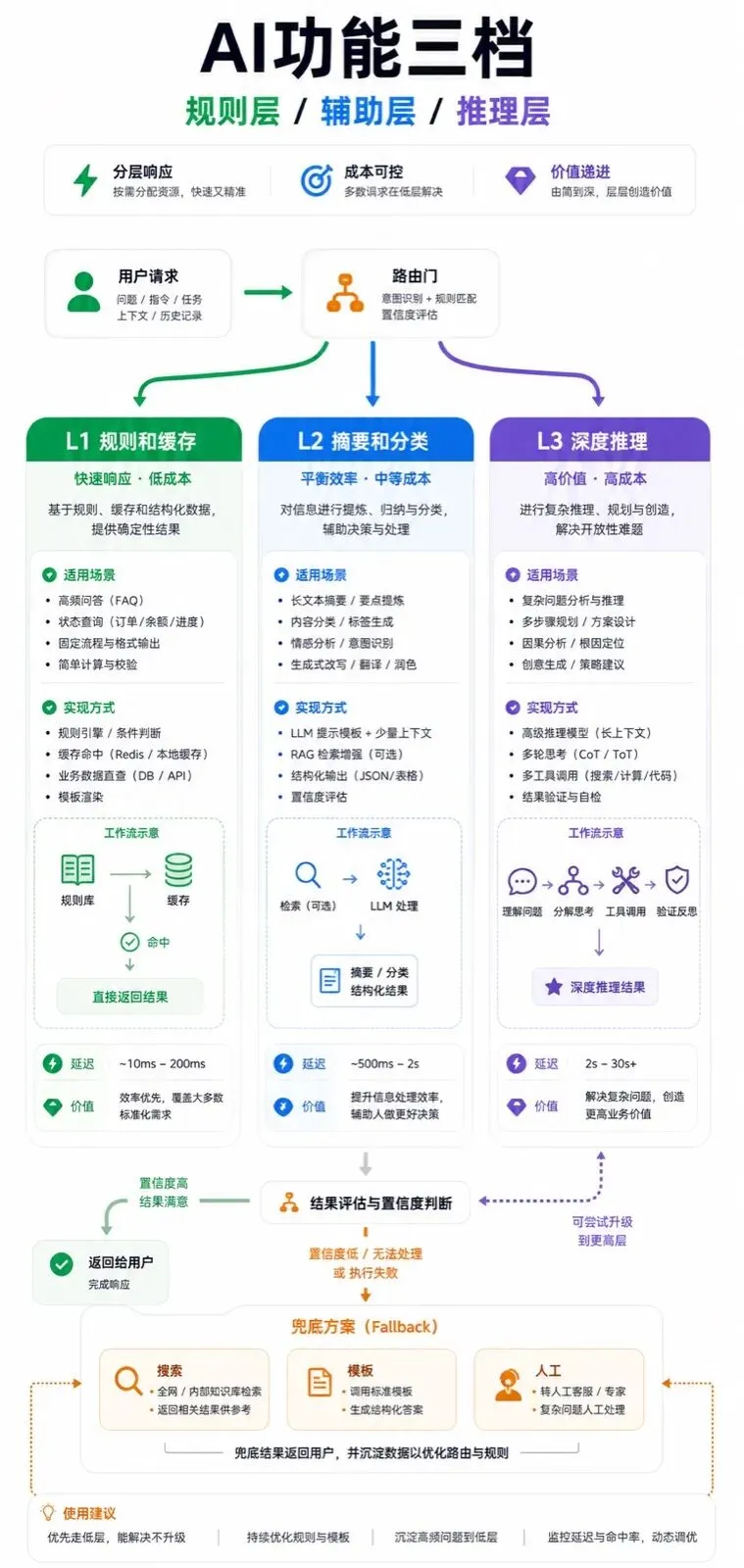
把 AI 功能分成三档,而不是一个开关
很多产品接 AI 的方式太粗:要么没有,要么到处都有。这个设计在演示时很爽,上线后就容易变成一堆隐形压力:慢、贵、不稳定、难解释。
更好的做法,是把 AI 能力做成三档。第一档是规则和缓存,稳定、便宜、可预测;第二档是小模型或轻量调用,处理结构化提炼和草稿;第三档才是大模型深度推理,给真正高价值的问题用。
这不是把体验做差,而是把好钢用在刀刃上。用户并不关心你每次都用了最强模型,用户关心的是该快的时候快,该准的时候准,出问题时不要卡死。
一个简单分层
L1 基础层:规则、模板、搜索、缓存回答。
L2 辅助层:摘要、改写、分类、表格提取。
L3 推理层:复杂决策、多轮规划、高价值专家任务。
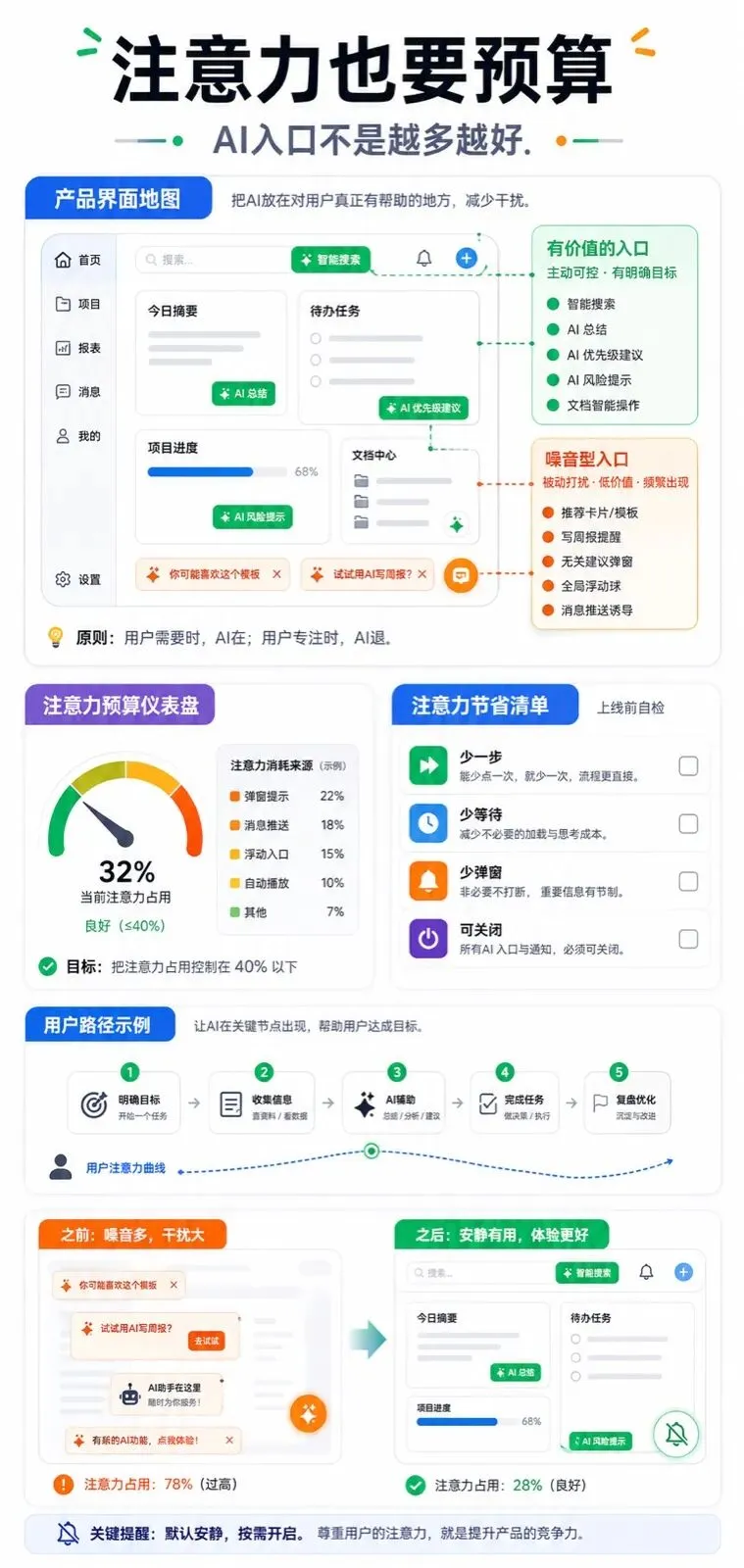
别把用户注意力也当免费资源
另一条 TechCrunch 视频提到,一些创业项目正在往“让人离开手机”的方向做:线下游戏、实体互动、DIY 电脑。这不一定是反 AI,更像是大家开始厌烦一种东西:每个产品都要抢你更多屏幕时间。
这对 AI 产品同样成立。AI 很容易制造更多消息、更多建议、更多弹窗、更多“你要不要试试”。如果它没有减少用户负担,只是把操作变成一堆会说话的入口,那它很快会从惊喜变成噪音。
所以设计 AI 功能时,可以多问一句:这次调用是在帮用户少做一步,还是在骗用户多停留一分钟?前者值得做,后者迟早会被用户关掉。
今天可以先做一件事:打开你正在做的 AI 功能清单,给每个入口标三列:价值、调用成本、失败降级。标不出来的入口,先别上线。
Anthropic 的 Daniela Amodei 在采访里说,前沿模型公司需要大量资本,因为训练和推理都有巨大的前置成本。这个判断放在巨头身上是融资故事,放在普通产品里,就是工程常识。
不要等账单、延迟和投诉一起出现,才想起 AI 功能也需要预算、缓存、排队、降级和边界。
AI 不是自来水。更像一间很贵的实验室:该用的时候别省,不该用的时候别开灯。
