 夜雨聆风
夜雨聆风用AI写代码这件事,说起来挺美好的。你描述一下想要什么,AI刷刷刷写出来,跑一下没问题就用了。快的时候几分钟搞定一个功能,比自己从零写快了不知道多少倍。
但你肯定也碰到过另一种情况。同样是描述需求,同样是AI来写,这次写出来的东西到处是问题。你让它改,改了一处又冒出两处新的。来回折腾几轮,你都忘了自己当初要什么了。
大多数人遇到这种情况,第一反应是模型今天状态不好,或者提示词没写对。
最近有一组数据,指向了一个不太一样的答案。
有个叫rsync的老项目,跑了二十多年,版本记录非常完整。有人把它36个版本的缺陷全拉出来,给每个Bug按严重程度打分,算出一个指标,每10次代码提交对应多少严重缺陷。
其中两个版本用了Claude辅助编程,正好可以跟前面三十多个纯人类版本做对比。
统计结论是,随机挑两个历史版本出来,有46%的概率比Claude版本更差。历史平均缺陷率2.95,Claude版本的平均只有1.65,还不到历史均值的六成。
听起来AI写代码还不错?
但你再看那两个Claude版本各自的数据。一个缺陷率是0.00,零。另一个是3.29,高于历史平均。
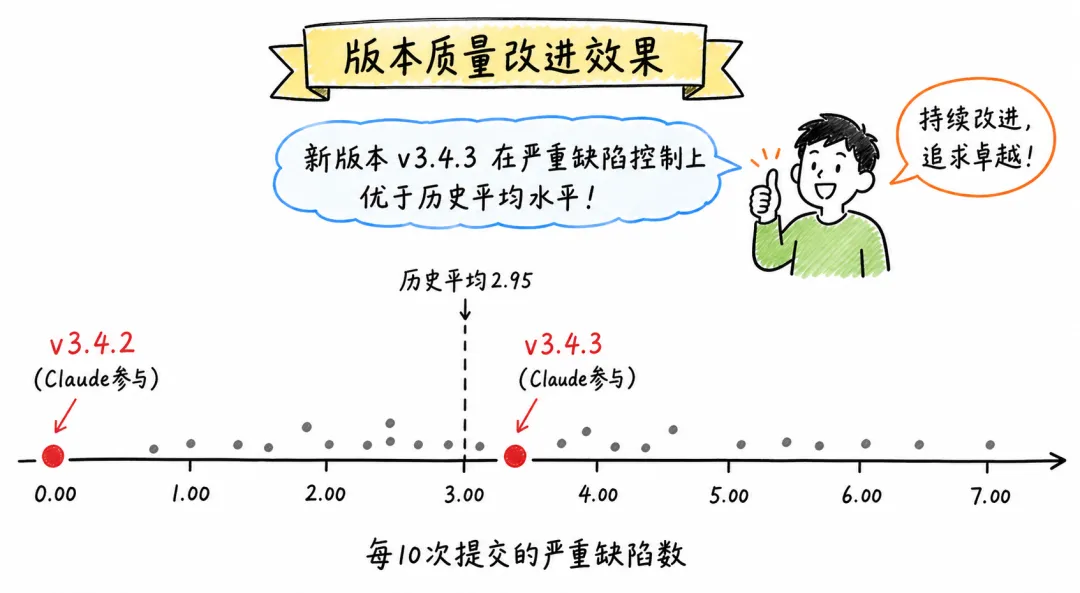 ▲ rsync历史版本缺陷分布:Claude参与的两个版本,一个零缺陷,一个高于平均
▲ rsync历史版本缺陷分布:Claude参与的两个版本,一个零缺陷,一个高于平均
这组数据最有意思的地方不是AI好不好,而是它不稳定。
同一个工具,出来的东西可以从完美变成翻车。
你回忆一下自己的经历,是不是也是这样。有时候AI写得特别顺,有时候一团糟,但你用的是同一个AI。你以为问题在模型身上,但模型根本没换过。
换的是什么?是你当时怎么跟它协作的。
最近有人做了一个小工具,试图解决这个问题。思路很有意思。
你让AI写代码之前,先让它交一份计划。这份计划会在浏览器里打开,你看到哪里不对,直接在上面画批注,然后一键发回给AI。AI看了你的意见,调整计划再交一次。你觉得行了,它才动手写。
Plannotator做的就是这件事。
听起来多了一步,好像更慢了。但你想一下,如果你给一个刚来的新同事派活,你会直接说“把这个功能做了”然后就不管了吗?你肯定会先问一句,你打算怎么做。等他说完你觉得方向没问题,才让他开始。
对AI,大部分人连这一步都省了。
说一句需求,AI直接上手。写完你看一眼结果,不对让它改。来回几轮越改越偏,最后你也说不清到底是AI理解错了还是你自己没想清楚。
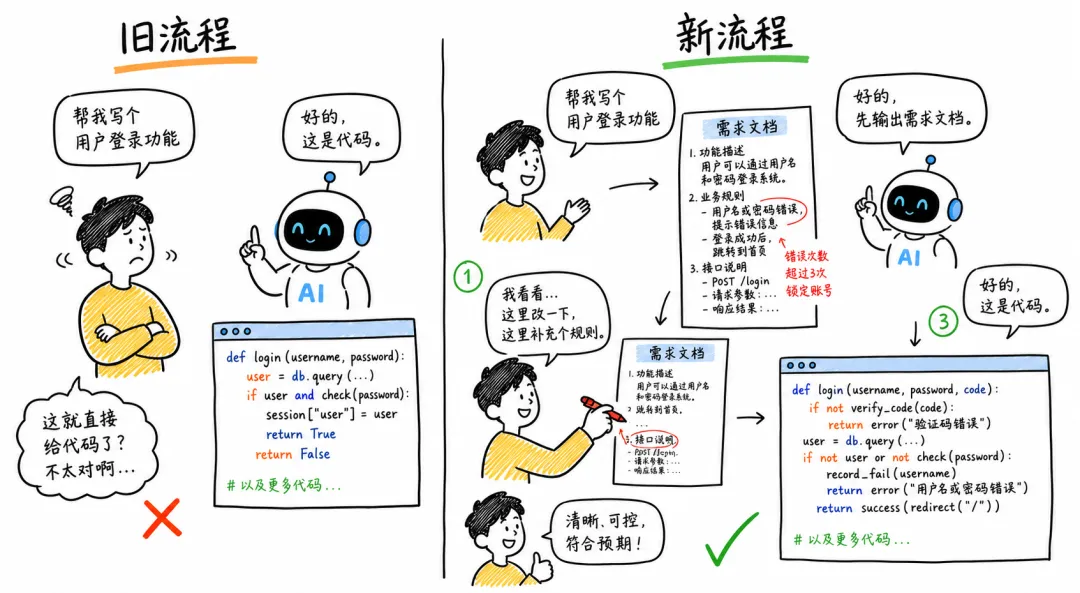 ▲ 先审计划再写代码,把“返工”前移成“纠偏”
▲ 先审计划再写代码,把“返工”前移成“纠偏”
好的计划真的很重要,我们得知道AI要往哪走,以及怎么引导它走对。
这话不花哨,但它戳中了一个盲区。用AI写代码最常见的翻车,不是AI能力不够,是它理解错了你的意图。你以为说清楚了,它以为听明白了,两边都挺自信,然后方向就偏了。让AI先把计划亮出来,你看一眼再让它动手,这一步不复杂,但大部分人没做过。
另一个人的做法完全不同。他不管AI的计划,而是管AI写代码的每一步。
他把一种叫测试驱动开发的老方法做成了Claude Code的一个Skill。这方法在软件行业有几十年了,核心思路三个字就能说清楚,先考试再答题。
先写一个你知道AI一定会“挂科”的测试。然后让AI只写刚好能让这个测试通过的代码,不多写一行。通过了,提交。再来下一个测试。
为什么要这样?因为这个人发现了一件反直觉的事。AI特别擅长写代码,但特别不擅长检查自己写的对不对。你让它写完直接跑,它会告诉你“搞定了”。但“它说搞定了”和“测试证明它搞定了”是完全不同的两件事。
就像一个人做完数学题说“我做对了”,跟你拿答案去对了一遍确认是对的,这两件事的可信度差很多。AI现在就处在“自己说自己对”的阶段,你不给它一个外部的检验标准,它就没办法证明自己。
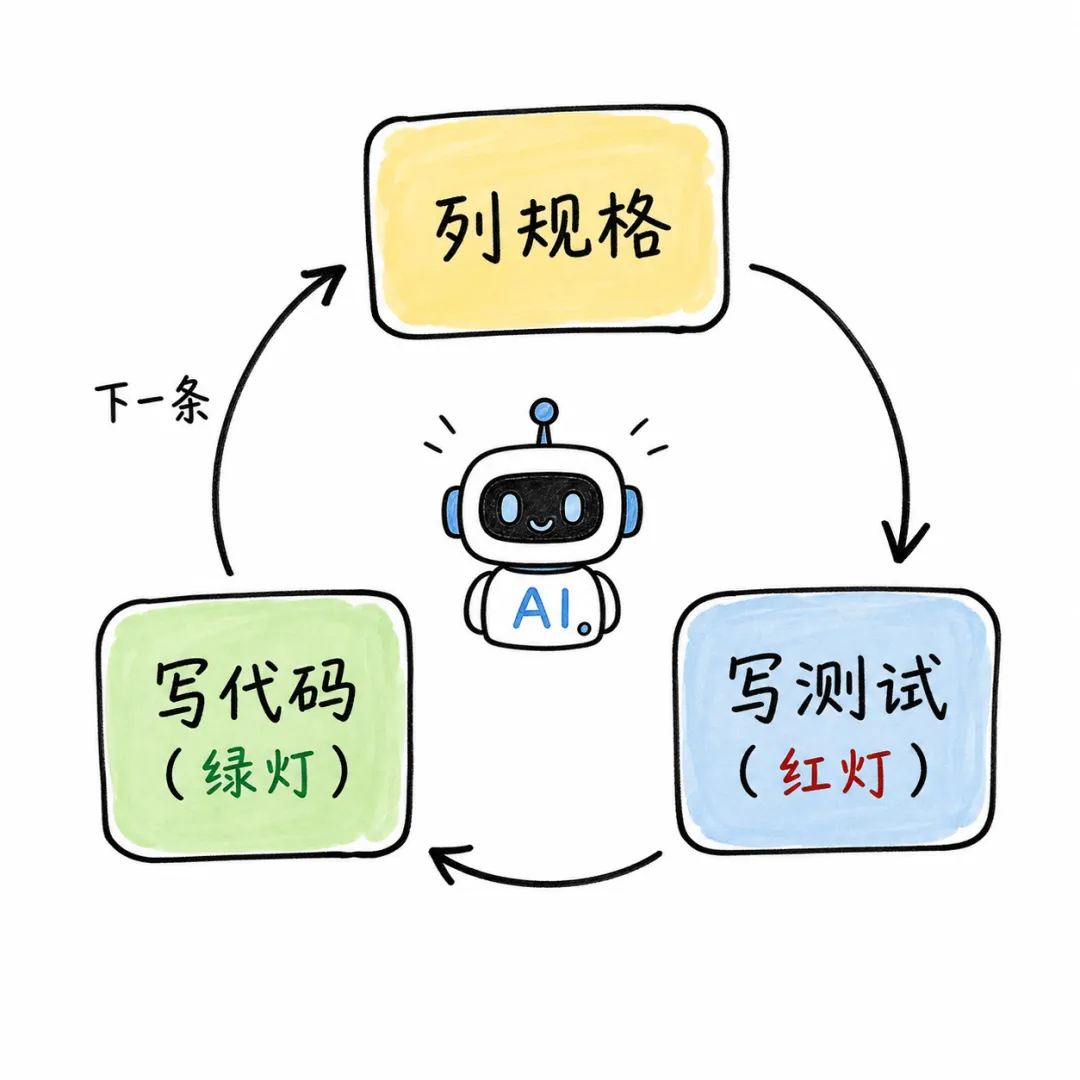
▲ 测试驱动的AI协作:先规格,再红灯测试,再写到绿灯
AI编程最大的生产力提升,不是来自更聪明的模型,是来自AI跟几十年前发现的那些不变的工程原则的结合。
大部分人在Vibe Coding的时候追的是更好的模型、更长的上下文、更精准的提示词。但这个人说,最有用的东西其实几十年前就有了,你只是没拿来用。
回到rsync那组数据。v3.4.2零缺陷,v3.4.3高于平均。谁也不知道这两次具体做了什么不同的事。但有一件事越来越清楚了。
现在很多人喜欢“凭感觉让AI写代码”:说一句话,AI就开始干活。这看起来很轻松。但“轻松”跟“有效”是两件事。
那些被省掉的步骤,让AI先说说打算怎么做、让AI每写一段就证明一下自己写的是对的、在AI动手之前先确认方向没跑偏,这些恰恰是决定结果好坏的东西。你没省掉的时候,AI表现得像一个靠谱的同事。你省掉了,它就变成一个有时灵有时不灵的黑盒。
区别不在AI,在你。
这其实跟很多行业里的老经验是一个道理。同一台设备,同一批原材料,出品质量也有波动。设备精度当然重要,但老师傅都知道,更重要的是工艺有没有执行到位,检验节点有没有真的卡住。AI写代码这件事正在走同一条路。模型是设备,你的描述是原材料,而你跟AI之间的协作流程才是工艺。光换更好的设备不管工艺,产品质量永远不会稳定。
rsync那个分析里还有一个小细节。给每个Bug打严重程度分的时候,作者没有自己打分,是让另一个AI扮演“高级可靠性工程师”来逐条评估的。
我们已经在用AI来评判AI了。仔细想想,这不就是Vibe Coding的日常吗?你让AI写代码,然后让AI告诉你代码对不对。
那到底谁在负责?
觉得有用?点个「在看」让更多人看到
想第一时间收到新文章?关注「普通人的AI进化论」
每天一篇,拆解普通人用得上的AI方法
— 长按识别下方名片,关注我 —
