 夜雨聆风
夜雨聆风
最近,科研圈里关于 AI Agent 的讨论越来越多。
Claude Code、Codex、Gemini CLI、GitHub Copilot、Cursor、各种 GitHub Skill、各种本地文献问答工具……看起来每一个都很强,每一个都像是“科研效率神器”。
但我想先泼一盆冷水:
如果没有清晰的科研流程,工具越多,反而越容易乱。
很多人以为自己是在提效,其实只是把原本混乱的文献、笔记、代码、数据和资料,搬进了一个更复杂的 AI 系统里。
表面上看,输出变多了。
但真正能复用的知识,可能并没有增加。
这就是我想说的“科研效率陷阱”。
一、为什么你用了 AI,反而更累了?

很多科研人刚开始接触 AI Agent 时,都会经历一个阶段:
看到一个工具,收藏。
看到一个教程,转发。
看到一个插件,安装。
看到一个 Skill,马上想试。
结果一段时间之后,电脑里多了很多文件夹,浏览器里多了很多收藏,GitHub 里 star 了很多项目,但自己的科研流程并没有真正变顺。
文献还是看不完。
资料还是找不到。
方向还是越看越乱。
笔记还是无法复用。
引用来源还是要重新核对。
这不是因为 AI 没用,而是因为你把顺序搞反了。
科研提效的第一步,不是先找工具,而是先建立流程。
没有流程,AI 只能帮你制造更多零散信息。
有了流程,AI 才能真正帮你节省时间。
真正的效率,不是更快地产生内容,而是更稳定地沉淀知识。
二、科研人最该配置的,不是更多工具,而是 4 类 Skill
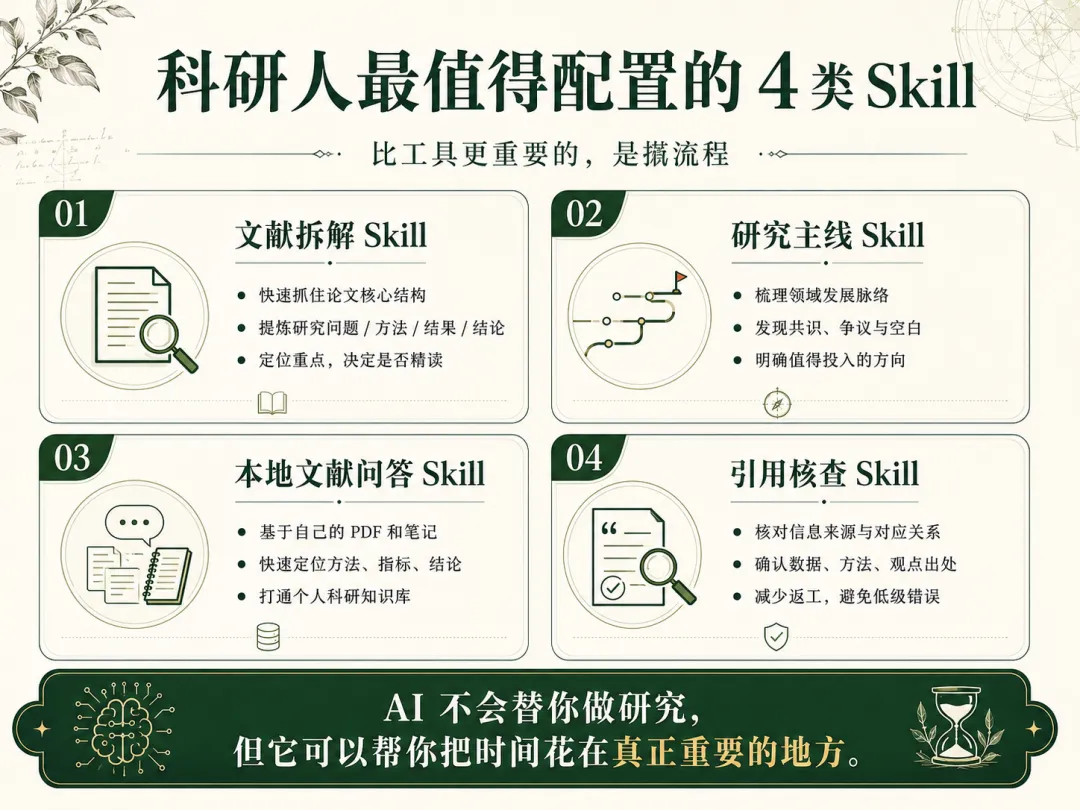
如果只推荐科研人最值得长期配置的能力,我会优先推荐这 4 类 Skill。
第一类:文献拆解 Skill。
它适合解决“论文太多、看不完、抓不住重点”的问题。
一篇文献最重要的,不是每个字都读完,而是先判断它到底解决了什么问题,用了什么方法,得到了什么关键结果,结论边界在哪里。
文献拆解 Skill 的作用,不是替你读论文,而是帮你更快定位重点。
它更像一个阅读导航器,让你知道哪些部分值得精读,哪些部分可以快速略过,哪些结论必须回到原文确认。
第二类:研究主线 Skill。
很多人读了很多文献,但还是没有方向感。
因为单篇文献总结得再清楚,也不等于你看清了整个领域。
研究主线 Skill 的价值,是帮你把一批文献放在一起,梳理出领域现状、共识、争议、空白和可能的切入点。
科研真正困难的地方,不只是读懂一篇文章,而是看清一批文章之间的关系。
哪些是基础研究?
哪些是方法改进?
哪些是应用验证?
哪些只是重复已有思路?
哪些真正提出了新的问题?
这一步,决定了你后面能不能形成自己的判断。
第三类:本地文献问答 Skill。
当你的 PDF、笔记、表格、图片和代码越来越多时,最大的痛点不是“没有资料”,而是“资料找不到”。
本地文献问答 Skill 的价值,就是把你的资料库变成一个可以被检索、被提问、被反复调用的知识系统。
比如你可以围绕自己的资料问:
某个实验方法在哪几篇文献里出现过?
某个指标的检测条件在哪里?
某个概念在不同文献中如何定义?
某个结论有没有对应来源?
它不是替你做判断,而是帮你快速定位信息。
第四类:引用核查 Skill。
这一类 Skill 很多人会忽视,但它非常重要。
科研信息最怕的不是少,而是乱。
某个结论到底来自哪篇文献?
某个数据是不是原文中的结果?
某个方法有没有被误读?
某个观点是作者结论,还是二次解读?
引用核查 Skill 的价值,就是帮助你检查信息和来源是否对应,降低后期返工和错误积累的风险。
这一步不是为了“显得严谨”,而是为了保护你的科研判断。
三、不同 AI Agent,适合不同科研场景

现在很多人容易把 AI Agent 混在一起讨论。
但实际上,不同工具的侧重点并不一样。
Claude Code 更适合本地项目、终端任务、代码库理解、数据分析脚本检查和多文件修改。
Codex 更适合软件工程任务、代码修改、测试、差异查看和任务委托。
Gemini CLI 更适合命令行环境、工具调用、自动化流程和本地工作流联动。
GitHub Copilot 更适合 IDE 内辅助、代码补全、仓库协作和日常开发配合。
Cursor 更适合在编辑器中进行多文件阅读、修改、调试和交互式开发。
所以,不存在“最好的 AI Agent”。
只有“当前阶段最适合你的工具组合”。
如果你只是整理文献,不一定需要复杂的代码 Agent。
如果你正在处理数据分析脚本,终端型 Agent 可能更合适。
如果你主要在写代码和调试,IDE 型工具更顺手。
如果你想管理自己的文献和笔记,本地知识库工具更重要。
科研人最容易踩的坑,就是把所有工具都装上,却没有想清楚自己到底要解决什么问题。
先定义问题,再选择工具。
这个顺序不能反。
四、AI 读文献的正确姿势:让它帮你定位,而不是替你判断
用 AI 读文献时,最重要的是边界感。
AI 可以帮你快速定位重点,但不能替你完成理解。
更稳妥的方式是:
先看研究问题。
这篇文章到底想解决什么?它的研究对象、研究背景和核心问题是什么?
再看方法设计。
样本、变量、流程、检测方法和统计方式是否合理?有没有明显的局限?
然后抓核心结果。
哪些数据最关键?哪些图表真正支撑结论?哪些结果只是补充?
接着回到原文核对。
AI 可以提示你重点在哪里,但证据、细节和判断必须回到原文。
最后形成结构化笔记。
把研究问题、方法、结果、结论边界和可追踪文献整理下来,让这篇文献真正沉淀进你的知识系统。
一句话:
让 AI 帮你定位与提炼,但证据、细节和判断必须回到原文。
这才是安全、稳妥、适合长期使用的方式。
五、一套可落地的 Agent + Skill 科研工作流
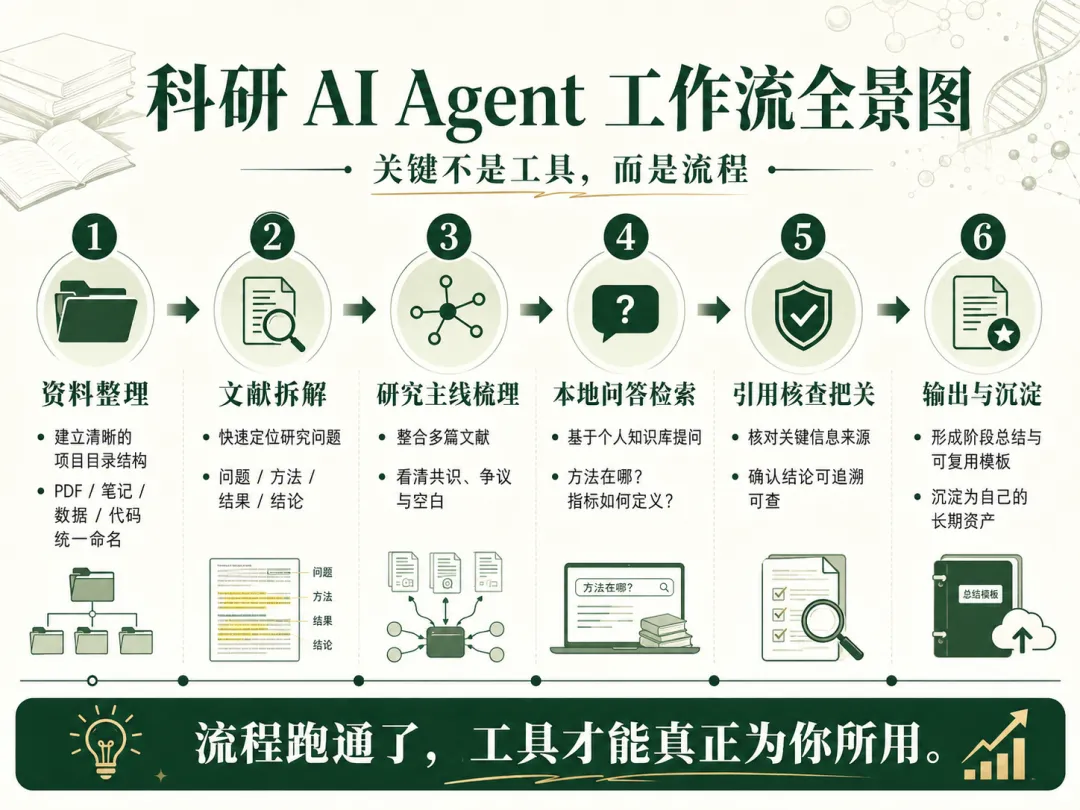
如果你现在想真正开始搭建自己的科研 AI 工作流,可以按照这个顺序来。
第一步,资料整理。
先把 PDF、笔记、表格、图片、代码和实验记录统一放进清楚的项目目录里。
不要把资料随手丢在桌面、微信、浏览器下载文件夹和各种临时文件夹里。
资料管理混乱,后面所有工具都会变得低效。
第二步,文献拆解。
每读一篇文献,都先抓研究问题、方法、结果和结论边界。
这一步的目标不是替代阅读,而是提高判断效率。
第三步,研究主线梳理。
当你积累了一批文献之后,就要定期整理领域共识、争议点、技术瓶颈和未来方向。
不要只停留在“我看过很多文章”,而要进一步形成“我知道这个领域卡在哪里”。
第四步,本地问答检索。
把常用文献、笔记和资料沉淀到自己的知识库里。
以后再查方法、查指标、查结论,就不用每次重新翻文件夹。
第五步,引用核查把关。
只要涉及关键结论、数据来源、方法出处和重要观点,都要回到原文或原始资料核对。
这一步越早形成习惯,后期返工越少。
第六步,输出与沉淀。
把阶段性的阅读、思考、流程和模板整理成可复用资产。
真正有价值的不是一次性输出,而是下一次还能继续用。
流程跑通了,工具才会真正为你服务。
否则,工具只是在制造更多噪音。
六、目前已经可以关注的几个 GitHub 科研 Skill

结尾:
科研提效,不是更快地生成更多内容。
而是更清楚地管理信息,更稳定地沉淀知识,更准确地做出判断。
工具会不断更新,平台会不断变化。
但真正能留下来的,是你的流程、判断和知识资产。
所以,别再乱装 AI 工具了。
先搭流程,再加工具。
这才是科研人真正值得长期投入的 Agent + Skill 工作流。
