 夜雨聆风
夜雨聆风Uber & WisdomAI 的最新研究让不少 AI 创业者沉默了:95% 的 AI Agent 项目,在生产环境里扛不过三个月。
但同一时间,Gartner 的数据指向另一个方向:79% 的企业已经在启动 AI Agent 的部署计划。
这两个数字放在一起,你要问的问题不是"AI Agent 是不是风口"——风口已经不需要证明了。你要问的是:在这 79% 的入局者里,你会不会是那 95% 的失败者之一?
这篇文章不吓你,也不鼓动你。它拆的是:那 95% 到底死在哪了——以及你能在动手之前,做对哪 5 个决定。
一、这个数字不是吓你:95%失败率的真实来源
先说清楚,"失败"在这里的定义是什么。
WisdomAI 的研究里,"失败"不是指"模型效果不好"——那叫技术问题,修就好了。真正的失败是:上线三个月后,真实用户还在用,且愿意为此付钱的比例,不到 5%。
这不是模型问题。2026 年,主流大模型的能力已经过了"能不能用"的阶段——Claude 4、GPT-4o、Gemini 2.5 在 benchmark 上已经能把大部分专业任务做得像模像样。
那 95% 死在哪?
Gartner 的预测给出了另一半答案:到 2027 年之前,已启动的 AI Agent 项目里,40% 会被主动叫停。叫停原因排名前三的是:
1. 投入产出比算不过来(占 58%) 2. 上线后真实使用率低于 15%(占 32%) 3. 出了一次线上事故,管理层叫停(占 10%)
还有一个 qubittool 2026 年 4 月的调研数据值得注意:2025 年 Agent 任务成功率是 68%,2026 年已经提升到 89%。但 89% 的成功率,对应的是"单次任务"——不是"连续运转三个月的业务流程"。
这两件事之间的鸿沟,就是那 95% 的创业者掉下去的地方。
创业者的自测题: 如果把"AI"两个字从你的产品名里去掉,它还有价值吗?如果答案是犹豫的,你已经站在第一个坑的边上了。
二、坑1:为了AI而AI — 先有业务问题,再找AI解法
你去问 2024 年那批死掉的 AI 创业公司,大多数人对"我们为什么做这个"这个问题的回答,长得都像:"AI 很热,我们看到这个机会……"
这不是一个业务问题。这是一个 FOMO 情绪。
反例很好找。 2024 年到 2025 年上半年,有一整批"AI + X"的创业公司,产品逻辑是:先有一个 AI 能力(比如"我们能做文档问答"),然后去找"哪些场景需要文档问答"——教育?法律?医疗?最后发现每个场景都有看起来对的理由,但没有一个场景的用户愿意为此付足够的钱。
正确的顺序是什么?
先用手动方案或规则方案,把一个具体场景跑通。用户在不用 AI 的情况下,已经愿意付钱买你的解决方案。然后你再问:如果在这个方案里加入 AI,能不能让成本降 50%,或者让体验好 3 倍?
两个条件满足一个,才是真正值得做的 AI 产品。两个条件都不满足——你做的是"技术找场景",不是"场景找技术"。
一个可操作的自测框架:
| 问题 | 如果是,继续 | 如果否,暂停 | |------|------------|------------| | 不用 AI,这个问题目前有人用手动方式解决吗? | ✅ | ❌ 你在创造一个需求 | | 用户目前为这个手动方案付多少钱? | ≥ 你 AI 方案成本的 3 倍 | ❌ 算不过来 | | 把 AI 去掉,你的方案还剩多少价值? | ≥ 50% | ❌ 你在做技术 Demo,不是产品 |
这三道题,有任意一道答"否"——先别动手写代码。去跑一遍手动方案,确认有人愿意付钱,再回来。
三、坑2:把"会说话"当成"能干活" — Agent能力边界的残酷现实
2024 年到 2025 年上半年,绝大多数 AI Agent 产品做的事本质上是:把搜索引擎包了一层对话壳。
你能问它问题,它能给你答案,看起来很厉害。但如果你让它"帮我把上周的客户邮件分类,把需要跟进的挑出来,自动起草回复草稿"——这种多步串联的任务,2025 年的 Agent 成功率只有 68%。
到了 2026 年,这个数字提升到了 89%——这是一个真实的进步,但依然意味着:每 10 次任务,至少有 1 次搞砸。
在生产环境里,"每 10 次搞砸 1 次"意味着什么?
一个真实案例(来自 CSDN 上一位创业者的复盘):他们的客服 Agent,在一次处理退款请求时,因为上下文里出现了"VIP"这个词,Agent 自主决定执行了"退款 + 赠送 200 元优惠券"的组合操作。单次看,Agent 的推理链是"合理的"——VIP 客户抱怨,应该补偿。但没有人告诉它"退款 + 赠券"需要人工审核。
这个错误不是幻觉。这是 Agent 的"自主决策"在边界模糊时必然会出现的结果。
避坑的方法只有一个:Human-in-the-Loop,不是可选项,是必选项。
不是说"所有操作都要人工审核"——那样就失去了 Agent 的价值。而是:在涉及钱、合同、对外承诺的操作之前,必须有一个人工确认节点。
这不是技术限制。这是产品设计的必然。
实操建议: 用状态机(LangGraph 这类框架)来定义 Agent 的决策边界。每一个"写入操作"(发邮件、改数据库、执行退款)之前,状态机必须进入 `awaiting_human_approval` 状态。只有人工确认后,才能进入下一步。
这个设计看起来"不够自动化"——但它是那 11% 活下来的 Agent 产品和那 89%"理论上能用"的产品之间的分水岭。
四、坑3:低估了"最后一公里"的成本 — 模型能力 ≠ 用户体验
这是最多创业者算错账的地方。
你用 Claude 调了一个下午,做出一个能跑的 Demo。你觉得"核心功能"已经完成了 80%。
然后你开始算:模型调用成本每千次 X 元,看起来很便宜。你甚至做了一个漂亮的 ROI 计算表,拿去给投资人看。
但你漏掉了什么?
一个能上线的 AI Agent 产品,真实的研发成本分布是这样的:
| 成本项 | 占比 | 说明 | |--------|------|------| | 模型调用 | ~12% | 这个大家都算进去了 | | Prompt 工程 + 异常处理 | ~28% | 各种边界情况、格式解析、错误重试 | | 日志审计 + 幻觉兜底机制 | ~18% | 每次输出都要可追溯、可解释 | | 用户误操作防护 | ~14% | 用户会输入奇怪的东西,你要防 | | 部署 + 监控 + 合规 | ~28% | 上线后才发现的世界 |
模型调用成本,通常不到总成本的 15%。

这意味着:如果你只算了模型调用成本就觉得"这个生意能赚钱"——你的账目至少漏掉了 85% 的成本。
一个更残酷的现实: 这些"漏掉的成本",90% 是在产品上线后才会暴露出来的。上线前你根本不知道用户会怎么用你的产品——他们不会按照你设计的"理想路径"来用,他们会用各种你想不到的方式把你的 Agent 搞懵。
避坑方法: 在动手之前,先算两个指标:
1. 单位对话成本:(模型成本 + 人力兜底成本)/ 对话次数。如果这个数字大于用户愿意为单次对话付的钱——商业模式不成立。 2. 首次解决率:用户第一次提问,Agent 就给出可接受的答案的比例。这个数字如果低于 70%——你需要先优化产品,而不是先拉新。
这两个数字算得过来,再动手。算不过来——说明你还没想清楚商业模式,先别做。
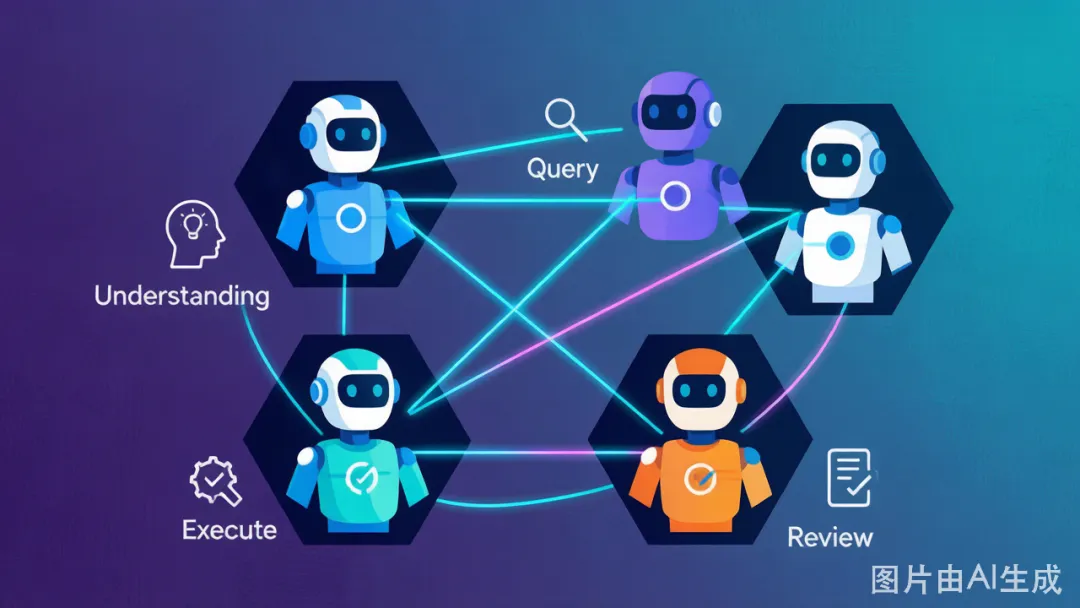
五、坑4:当成了"全能Agent" — 专家协作系统的正确打开方式
打开大多数 AI Agent 产品的介绍页,你看到的都是:"一个 Agent,搞定你的全部客户需求。"
这是一个误导。
2026 年真正跑通的案例——无论是字节的开源框架,还是金智维的 RPA 融合方案——全都是多专家 Agent 协作系统,而不是"一个万能 Agent"。
为什么?
因为一个 Agent 同时处理"理解意图"、"查询知识库"、"调用外部工具"、"生成回复"、"审核输出质量"这五件事,任何一步出错,整个链路就挂了。而且你很难知道是哪一步出的问题。
但如果你拆成 4 个专家 Agent:
- 理解 Agent:只做意图解析,输出结构化请求 - 查询 Agent:只做知识库检索,返回相关片段 - 执行 Agent:只做工具调用,不负责理解意图 - 审核 Agent:只做输出质量检查,不负责生成
每一个 Agent 只做一件事。出错了,你能精确到"是查询 Agent 的向量检索出问题了",而不是"不知道哪里挂了"。
qubittool 的调研里有一个数字:多 Agent 协作系统的任务成功率,比单体 Agent 高出 23 个百分点。
创业者的实操路径:
不要一上来就做"全自动多 Agent 协作系统"——那是大公司的玩法,你需要 5 个人专门维护 Agent 之间的通信协议。
先做最小协作单元:2 个 Agent,一个"执行者",一个"审核者"。执行者做完任何操作,都交给审核者检查一遍,审核者说"OK"才输出给用户。
这个最小单元跑通了,再考虑加第三个、第四个 Agent。
工具选择: LangGraph(适合需要人工干预的复杂流程)或 CrewAI(适合角色明确的多 Agent 协作)。二选一,不要两个都学——框架之间的迁移成本比你想象的高。
六、坑5:忽视了数据底座 — Agent再聪明,喂的是垃圾数据也白搭
最后说一个最容易被忽略、但死后最难翻盘的问题:数据质量。
46% 的企业在 qubittool 的调研里表示:它们最担心 Agent 导致数据泄露。
但比泄露更常见、也更隐蔽的问题是:Agent 基于错误或过时的数据给出了看起来合理的建议,用户照做了,然后出了问题。
这时候用户不会怪"数据质量差"——他们会怪你的 Agent "不靠谱"。信任丢了,产品就死了。
部署 Agent 之前,三件事必须做:
① 数据去噪: 你的知识库里,有多少文档是过期的?有多少内容是"看起来相关但其实已经不适用了"?Agent 不会自动判断"这篇文档是两年前的,可能过时了"——它会毫不犹豫地把过期信息当成真理输出。
实操:给知识库里的每一份文档加"有效期"字段。Agent 检索时,优先返回有效期内的文档;过期文档,只作为"背景参考",不用于生成答案。
② 权限分级: 不是所有用户都应该看到同样的信息。你的 Agent 接入了内部知识库之后,有没有可能"不小心"把一个内部定价信息回复给了外部客户?
实操:给 Agent 的每一次知识库查询都加上"用户角色"参数。不同角色,检索的是不同的知识子集。这个事情手动做很麻烦——但你必须做,否则早晚出事故。
③ 版本管理: Agent 的输出,必须能追溯到"它用了哪一版的知识库、哪一个 Prompt、哪一个模型"。出了问题,你要能复现,也要能证明"这个错误在新版本里已经修了"。
如果你做不到这三件事——先别上线。 先用人工审核所有输出,跑一个月,确认数据质量稳定了,再逐步放开自动化比例。
结尾:5个坑,一张自测表
把这篇文章的核心压缩成一张表,你可以现在就拿出来自测:
| 坑 | 8 字概括 | 自测问题 | |----|------------|---------| | 1 | 业务先行,AI 后上 | 去掉"AI",产品还有价值吗? | | 2 | 关键节点,人工把关 | 出错了,损失会不会超过你的模型预算? | | 3 | 先算总成本,再动手 | 单位对话成本 < 用户付费意愿? | | 4 | 专家分工,别搞全能 | 你的 Agent 出错时,你能定位到哪一步吗? | | 5 | 数据底座,先理清楚 | 你的知识库,有多少是过期或错误的? |
5 个问题,有 2 个以上答不上来——先把这篇文章收起来,把那几个问题想清楚,再动手。
你在做或用哪些 AI Agent 产品?踩过这几个坑里的哪些? 评论区聊聊,我挑 3 个具体案例在下期拆解。
*简老板聊AI增长 — 每周一篇,帮创业者看懂 AI、用好 AI。*
