夜雨聆风
夜雨聆风
目录
软件正在经历第三次变革 软件 1.0、2.0 与 3.0:三种编程范式 LLM 是新型操作系统 LLM 的心理:超人般的缺陷 部分自主应用:钢铁侠战衣,而非机器人 生成-验证循环:人类与 AI 协作的核心 氛围编码(Vibe Coding):每个人都是程序员 为代理构建:新的数字消费者 总结
"软件又在发生变化。"
安德烈·卡帕西(Andrej Karpathy)走上 Y Combinator 的讲台,第一句话就定下了整场演讲的基调。这不是他第一次做这个演讲——他自己也承认了——但他说情况正在发生根本性的变化。
这位特斯拉人工智能前总监、OpenAI 创始成员,如今用一种极其冷静的语气告诉我们:软件行业正在经历一场地震,而大多数人还没意识到震中在哪里。

软件正在经历第三次变革
卡帕西开篇抛出的核心判断是:软件在 70 年里几乎没有发生根本性变化,但过去几年里,它连续发生了两次剧烈变化。
"粗略地说,软件在如此根本的层面上,70年来并没有发生太大的变化。然后,我认为在过去的几年里,它发生了两次相当迅速的变化。因此,需要编写和重写大量的软件,工作量非常大。"
他展示了一张名为"GitHub 地图"的可视化工具,上面是所有已编写代码的分布图。这张图看起来像星空——每颗星星就是一个代码仓库。但卡帕西说,这张图正在被一种全新的代码形态所覆盖。
软件 1.0、2.0 与 3.0:三种编程范式
卡帕西提出了一个经典的三段式框架,这是他几年前就在思考的问题。
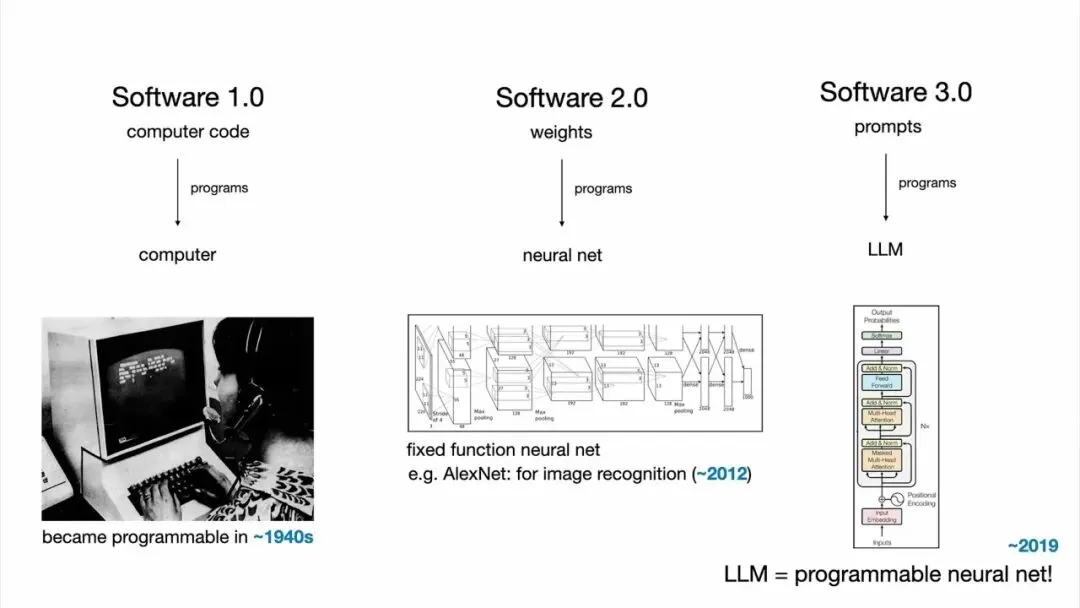
软件 1.0:你为计算机编写代码。这是传统的编程方式——Python、C++、Java,你写什么,计算机就执行什么。
软件 2.0:神经网络。但这不是你直接写的代码,而是权重。你调整数据集,运行优化器,让机器自己"学"出参数。卡帕西指出,HuggingFace 现在就是"软件 2.0 领域的 GitHub"——上面全是神经网络的权重。
"软件 2.0 本质上就是神经网络,特别是神经网络的权重。你不会直接编写这些代码,你更多的是在调整数据集,然后运行优化器来创建神经网络的参数。"
但真正让他兴奋的是软件 3.0。
"你的提示现在就是对 LLM 进行编程的程序。令人惊讶的是,这些提示都是用英文写的。"
卡帕西特意强调了这个转变的荒谬之处:我们居然在用自然语言写程序。几年前他发了一条推文,至今仍被置顶——"我们现在竟然用英语编写计算机程序,这真是太不可思议了。"
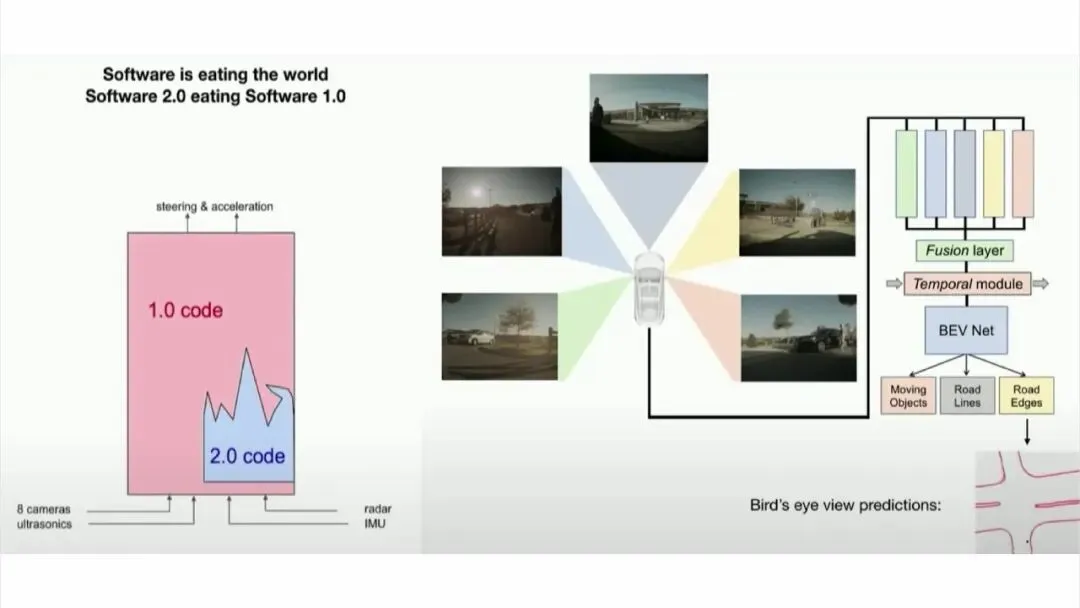
他回忆在特斯拉的经历。当时他们正在研发自动驾驶系统,系统底层有大量 C++ 代码(软件 1.0),上面跑着神经网络用于图像识别(软件 2.0)。随着系统不断改进,一个有趣的现象发生了:
"所有的 C++ 代码都被删除了……最初在 1.0 版本中编写的功能都被迁移到了 2.0 版本。来自不同摄像头和不同时间点的图像信息拼接工作大多由神经网络完成,我们得以删除大量代码。"
这就是卡帕西看到的模式:每一种新软件范式都在"蚕食"前一种范式的领地。现在,软件 3.0 正在做同样的事。
LLM 是新型操作系统
卡帕西用一个类比来理解 LLM 在整个技术栈中的位置——操作系统。
他首先承认,许多人把 LLM 比作"新电力"——这个类比来自安德鲁·吴(Andrew Ng)。这个类比确实抓住了某些特征:LLM 实验室投入巨资建设"电网"(训练模型),然后通过 API 像供电一样提供智能服务,按 token 计费。
但卡帕西认为这个类比不够准确。
"最合理的类比或许是,LLM 与操作系统有着非常强烈的相似之处。"
为什么?因为 LLM 不是单纯的商品。它不仅仅是电力或水——它有一个生态系统。

他画了一张图来解释自己的思考:
- LLM 本身,就像 CPU
- 上下文窗口,就像内存
- 工具调用、函数调用,就像系统调用
- 提示工程,就像编写程序
"LLM 是一种新型计算机。它就像 CPU 的替代品一样,静静地待在那里。上下文窗口有点像内存,而 LLM 则协调内存和计算。"
卡帕西进一步指出,我们现在所处的阶段,就像20 世纪 60 年代的计算机时代。LLM 计算仍然非常昂贵,所以它们集中在云端,我们通过分时共享的方式使用它们——就像当年的大型机。
"个人计算革命尚未发生,因为它在经济上是不可行的。"
但他看到了一些早期迹象。比如 Mac mini 在某些推理任务上表现不错,因为推理主要受内存限制。不过,他承认:"目前还不清楚这看起来是什么样子。也许你们中的一些人可以发明这是什么。"

LLM 的心理:超人般的缺陷
卡帕西花了相当篇幅来讨论一个被他称为"LLM 心理"的话题。他认为,要想用好 LLM,必须先理解它们的"性格"。
"我喜欢把 LLM 看作是人的灵魂。它们是对人的冷静模拟。"
LLM 是训练在人类文本上的 transformer 神经网络。因为训练数据来自人类,所以它们展现出类似人类的涌现心理。但这带来了一系列独特的特征:
超能力: - 百科全书般的知识和记忆力——能记住比任何普通人都多的信息 - 卡帕西用电影《雨人》(Rain Man)来类比:达斯汀·霍夫曼饰演的自闭症天才拥有近乎完美的记忆力
认知缺陷: - 幻觉:它们会胡编乱造 - 缺乏自我认知:没有完善的内部模型来评估自己知道什么、不知道什么 - "草莓里有几个 R"问题:会犯人类基本不会犯的愚蠢错误 - 顺行性遗忘症:不会随着时间推移积累知识

"LLM 本身并不具备这种功能……上下文窗口实际上有点像工作记忆,你必须直接对工作记忆进行编程,因为它们不会默认变得更智能。"
卡帕西用两部电影来类比这种状态:《记忆碎片》(Memento)和《第 51 次约会》(50 First Dates)。两部电影的主角都有固定体重(固定参数),但情境窗口每天早上都被清除——每次对话都是全新的开始。
他还指出了安全方面的缺陷:LLM 容易上当受骗,容易受到提示注入攻击,可能泄露数据。
"你必须在同时思考这个拥有大量认知缺陷和问题的超人般的存在。我们如何才能既利用它们又利用它们的巨大潜力?"

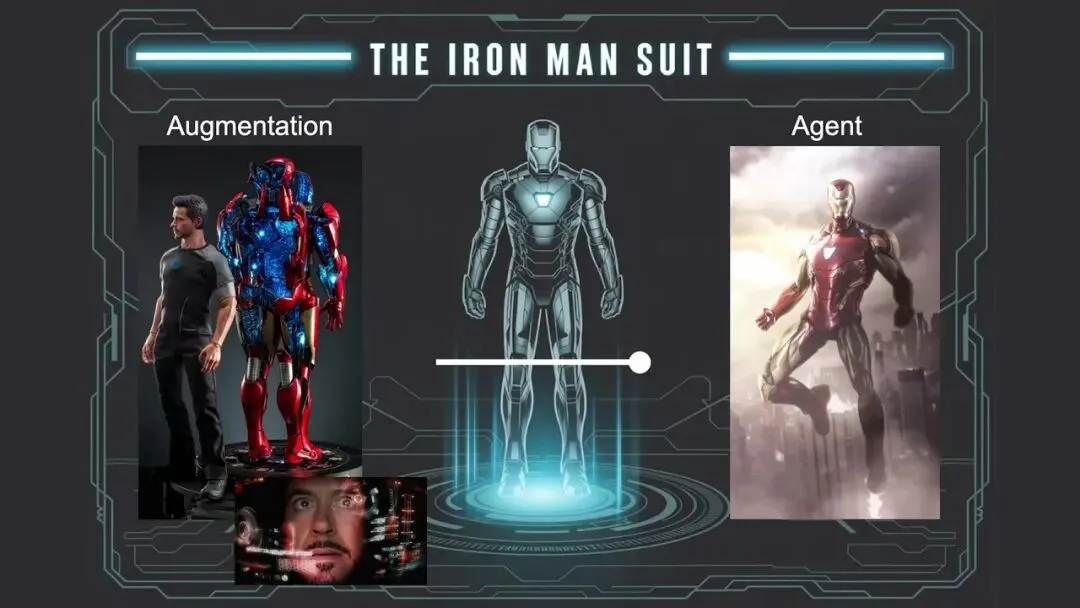
部分自主应用:钢铁侠战衣,而非机器人
这是卡帕西整场演讲中最核心的实操建议。
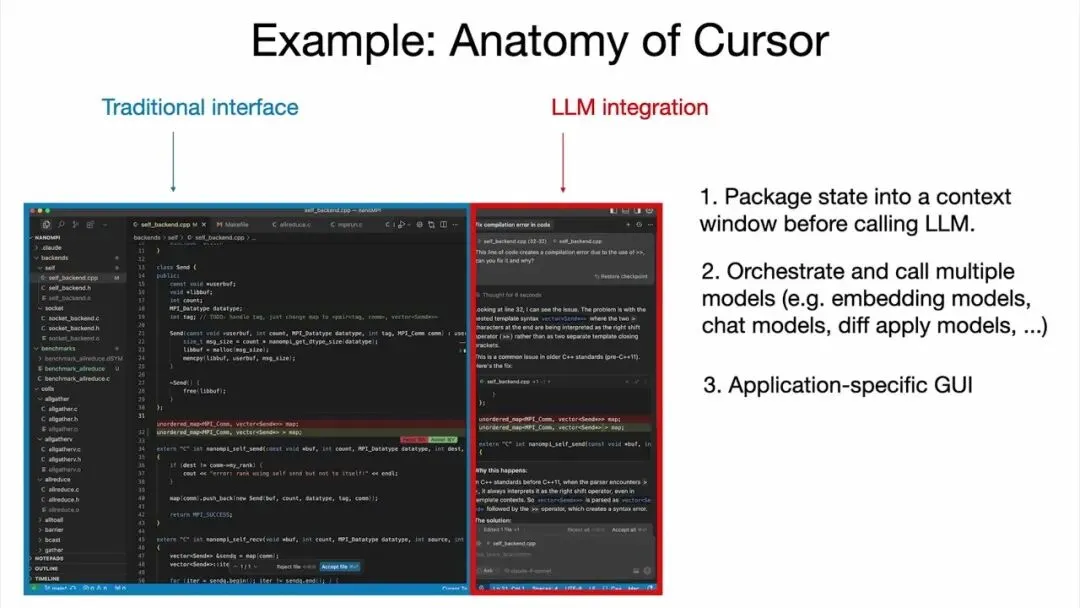
他以编程工具 Cursor 为例。Cursor 是一个集成了 LLM 的代码编辑器,但它的设计方式体现了卡帕西认为所有 LLM 应用都应该具备的特征:
1. 保留传统界面:用户可以像以前一样手动完成所有工作
2. LLM 承担上下文管理:自动处理文件嵌入、聊天模型、差异应用等
3. 多个 LLM 调用:底层协调多个模型
4. 应用特定的 GUI:这是卡帕西特别强调的一点
"你不想直接用文本与操作系统对话。文本很难阅读、解读和理解……最好直接看到差异,比如红色和绿色的变化。"
5. 自主性滑块——这是卡帕西的核心概念
"你可以控制自主度滑块,并根据手头任务的复杂性来调整你愿意为该任务放弃的自主度。"
在 Cursor 中,你可以: - 直接点击补全(你完全控制) - 选中一段代码按 K 键修改(部分自主) - 用命令 L 修改整个文件(更多自主) - 用命令 I 让它在整个仓库中执行任何操作(完全自主)
另一个例子是 Perplexity,它也有类似的设计:快速搜索、深入研究、10 分钟后回来——不同程度的自主权。

"很多软件都会变得部分自动化。我正在努力思考,那会是什么样子?对于你们这些维护产品和服务的人来说,你们将如何使你们的产品和服务实现部分自主化?"
卡帕西提出了几个关键问题: - LLM 能看到人类所能看到的一切吗? - LLM 能否像人类一样行事? - 人类能否监督并了解这项活动的全部情况?
生成-验证循环:人类与 AI 协作的核心
卡帕西认为,LLM 应用的核心模式是:AI 生成,人类验证。
"我们现在有点像是在与 AIS 合作,通常情况下,他们负责生成数据,而我们人类负责验证。让这个循环尽可能快地进行符合我们的利益。"
他提出了两种加速验证的方法:
1. 图形用户界面(GUI):利用人类大脑中的"计算机视觉 GPU"
"阅读文字很费力,也不好玩,但看东西很有趣,就像是通往大脑的一条高速公路。"
2. 控制 AI:不要让它过度反应
"我认为很多人工智能代理过于兴奋了……对我来说,将 10,000 行代码的差异添加到我的代码库中并没有用处。我必须这么做,因为我仍然是瓶颈。"
卡帕西分享了自己的工作方式:他总是分小步进行,害怕出现太大的差异。他想确认一切是否妥当,让循环快速旋转,然后慢慢处理具体的小块内容。
"如果我只是随便写写代码,那一切都很好,但如果我真的想完成工作,有个反应过度的代理做所有这些事情就不太好。"
他还提到了一些最佳实践:如果提示模糊,AI 可能不会完全按照你想要的方式操作,验证就会失败。因此,花更多时间让你的提示更具体,提高验证成功的概率。

氛围编码(Vibe Coding):每个人都是程序员
卡帕西引入了一个他最近"不小心"创造的热门概念——氛围编码(Vibe Coding)。
"这条推文算是把这件事引入了这个梗……它完全变成了一个梗,我真的搞不清楚了。但我想,它触动了人们的内心,并为每个人都有的感受——但无法用语言表达——赋予了一个名称。"

氛围编码的核心是:自然语言成为编程语言。英语突然之间成了编程语言,这意味着每个人都是程序员——因为每个人都说自然语言。
"以前,你需要花五到十年时间学习软件开发方面的知识才能胜任相关工作。情况已经不同了。"
他展示了一个视频——HuggingFace 的 Tom Wolf 分享的儿童风格编程视频。卡帕西说:"你怎么能看了这个视频还对未来感到悲观呢?未来一片光明。"
他自己也尝试了氛围编码。他开发了一个叫 Menu Genen 的 iOS 应用——拍一张菜单照片,AI 生成每道菜的图片。他坦白说:"我实际上不会用 Swift 编程,但我竟然能开发出一个如此基础的应用。"

但这里有一个关键教训:写代码是最简单的部分。
"我只用了几个小时就在我的笔记本电脑上做出了菜单生成器的演示版本,然后却花了一周时间才把它变成现实……所有那些运维方面的东西都让我需要在浏览器中点击各种东西,这非常慢。"
他举了一个具体的例子:在网页上添加 Google 登录。
"这个 Clerk 库里有大量的说明告诉我如何集成它。它就像在告诉我,去这个网址,点击这个下拉菜单,选择这个,去这里,然后点击那个。这就像是在告诉我该怎么做……我为什么要这样做?"

为代理构建:新的数字消费者
卡帕西指出,现在出现了一个全新的数字信息消费者和操控者类别:代理(Agent)。
过去只有人类通过 GUI 与软件交互,或者计算机通过 API 交互。现在有了第三种:代理——它们是计算机,但"有点像人类"。
"它们是人灵,互联网上有人类灵,它们需要与我们的软件基础设施进行交互。"
这意味着我们需要为代理重新设计软件基础设施:
1. llm.txt 文件:就像 robots.txt 告诉网络爬虫如何爬取网站,llm.txt 告诉 LLM 这个域名是关于什么的。
2. 面向 LLM 的文档:Vercel 和 Stripe 已经开始将文档转换为纯 Markdown 格式,因为 LLM 更容易理解。
3. 替代"点击这里":Vercel 将每次点击替换为等效的 curl 命令,这样 LLM 代理可以直接执行。
4. 模型上下文协议(MCP):Anthropic 推出的协议,让代理可以直接与系统对话。

"目前已经为人们编写了大量的文档。所以你会有列表、粗体字和图片之类的东西,而这些内容是 LLM 无法直接访问的。"
卡帕西还分享了一个有趣的例子:他想用 Manim(3Blue1Brown 使用的动画库)制作动画,但不想读文档。于是他把整个动画的代码复制粘贴到 LLM 中,描述了想要的效果,LLM 直接生成了他想要的动画。
"如果我们能让 LLM 看懂文档,就能释放大量的用途。"
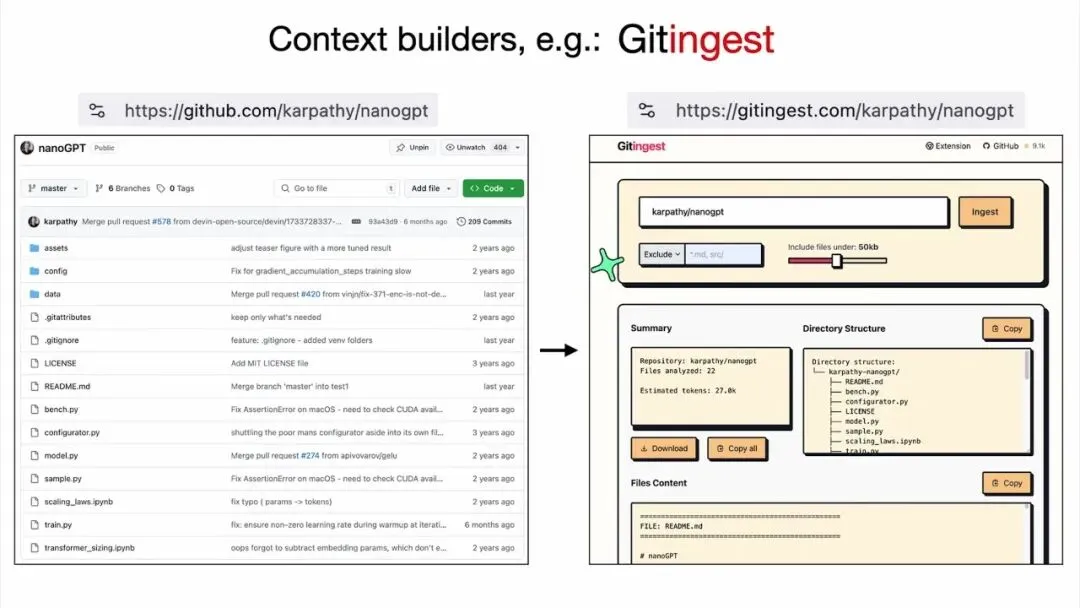
他还推荐了一些小工具,比如 github.dev——把 GitHub 仓库的 URL 改成 github.dev,就能把所有文件连接成一个巨大的文本文件,方便复制粘贴到 LLM 中。
总结
卡帕西的演讲核心信息可以浓缩为以下几点:
1. 软件正在经历第三次范式转移:从手写代码(1.0)到神经网络权重(2.0),再到自然语言提示(3.0)。每一次转移都在"蚕食"前一种范式的领地。
2. LLM 是新型操作系统:不是简单的"新电力",而是拥有完整生态系统的计算平台。我们目前处于 20 世纪 60 年代的大型机时代——个人计算革命尚未到来。
3. LLM 有独特的心理特征:它们拥有超人般的知识储备,但也有严重的认知缺陷(幻觉、遗忘、缺乏自我认知)。与它们协作需要理解这些特征。
4. 构建"部分自主应用":卡帕西最核心的实操建议是——不要追求完全自主的代理,而是构建带有"自主性滑块"的应用,让用户控制 AI 的参与程度。
"与其说是构建炫酷的自主代理演示,不如说是构建部分自主产品。这些产品都拥有定制化的用户界面和用户体验设计。"
5. 生成-验证循环是核心:AI 生成,人类验证。加速这个循环的关键是好的 GUI 设计和对 AI 的控制。
6. 氛围编码(Vibe Coding)改变了一切:自然语言成为编程语言,每个人都是程序员。但写代码只是最简单的部分——运维、部署、身份验证等"非代码"工作才是真正的瓶颈。
7. 为代理重新设计基础设施:文档需要面向 LLM 优化,交互需要从"点击"转向 API 调用。这是一个全新的设计领域。
"在接下来的十年里,我们大致会看到的情况是,我们将把滑块从左向右移动。看看最终效果会是什么样子,应该会很有意思。我迫不及待地想和大家一起把它建成。"