 夜雨聆风
夜雨聆风这里是「算力网络架构手记」北京
专注 AI 集群网络架构与性能优化
深入 GPU×RoCE×NCCL×K8s 跨层瓶颈
只拆真实问题,不写概念科普
00
DPU
有人把它当成“更高级的网卡”。有人把它当成“网卡上的一台小服务器”。也有人直接把它看成:
AI 集群网络的新变量。
这不是空穴来风。
NVIDIA 把 BlueField 描述成把高性能网络、Arm 计算与面向网络/存储/安全的加速能力结合在一起的平台;
Intel 把 IPU 定义为用于加速、隔离和连接基础设施任务的平台;
AMD Pensando 也把 DPU 明确定位在网络、存储和安全的数据面加速上。
也就是说,DPU 从一开始就不是“单纯跑包的 NIC”,而是冲着“把基础设施职能从主机 CPU 挪出去”来的。
所以真正值得问的问题,不是:
DPU 是不是很强?
而是:
DPU 到底会不会改变 AI 集群网络架构?
会。但不是你以为的那种“把交换机替掉”。
更准确地说:
DPU 改变的,不是“有没有网络”。而是“网络职能放在哪一层做、由谁来做、离 GPU 有多近”。
01
DPU 改变的,到底是什么?
一听“改变网络架构”,脑子里想的是:
拓扑会不会变 交换机会不会减少 叶脊会不会被替代 带宽是不是更大
这些当然可能发生变化。但如果你只盯这些,容易看偏。
因为 DPU 最先改变的,通常不是“拓扑形状”。
而是:
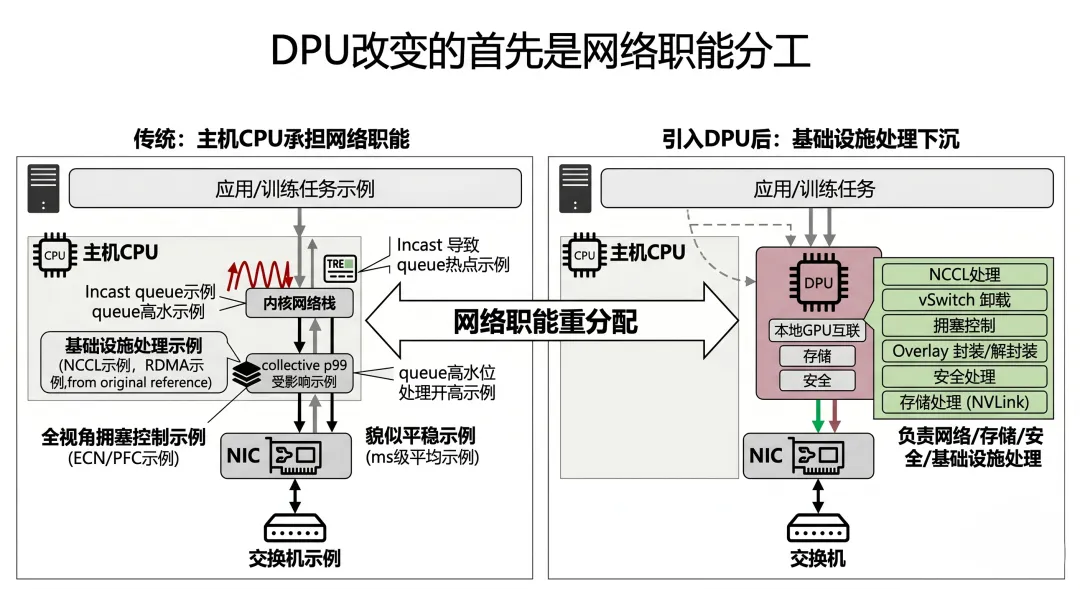
网络里的很多“中间工作”,不再默认由主机 CPU + 内核 + 通用软件路径来承担。
这件事非常关键。
NVIDIA、Intel、AMD 对 DPU/IPU 的官方表述其实都指向同一个方向:把网络虚拟化、存储、隔离、安全、基础设施服务等能力,从主机 CPU 侧挪到一个更靠近网络接口、且更可编程的处理单元上去。
一旦这件事成立,AI 集群的很多老问题,就会开始松动:
谁来处理 vSwitch / overlay / 策略 谁来承担多租户隔离 谁来处理基础设施侧的包处理逻辑 谁来保证训练流量少被“软件路径”干扰 谁来把“通用网络控制逻辑”和“AI 通信路径”隔开
所以 DPU 改变网络架构的第一层,不是“网络长什么样”。
而是:
网络里的职能分工,开始重新洗牌。
02
为什么 AI 集群特别容易成为 DPU 的“试验田”?
因为 AI 集群天生就不喜欢“中间层太重”。
想一想 AI 训练最怕什么:
AllReduce 被拖慢 Incast 放大 queue 抬头 tail latency 上升 GPU 在等通信 多租户或容器栈把路径搞复杂
这些问题看起来都发生在“网络里”。但很多时候,它们不是单纯的“交换机问题”。
而是:
路径太长。职能太混。控制环太多。
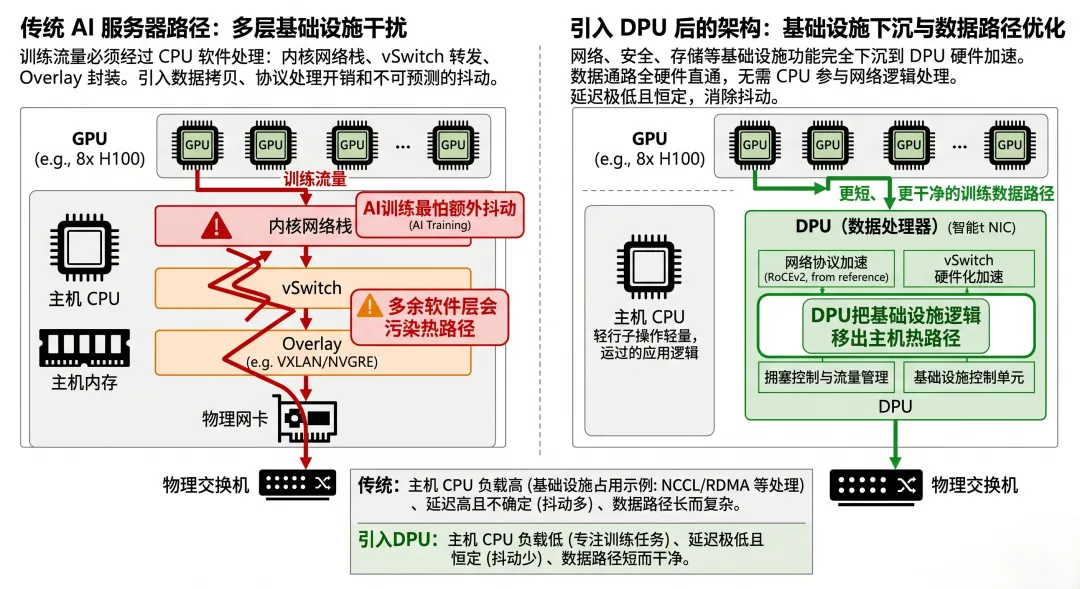
比如在传统主机架构里,一些基础设施处理可能会落在:
主机 CPU Linux 网络栈 vSwitch overlay 封装 容器网络层 安全 / 策略处理链路
这些东西对普通云业务当然有价值。
但对 AI 训练来说,问题在于:
它们不一定在关键时刻足够轻。
而 AI 训练偏偏是一个最怕“少量额外抖动”的系统。因为只要少数流更慢一点,到了 collective 这层,整个 step 都可能被拖住。
所以 DPU 为什么在 AI 集群里看起来特别有吸引力?
因为它提供了一种可能性:
把那些原本会污染训练数据路径的基础设施逻辑,尽量移出主机热路径。
这就是 DPU 和 AI 集群天然契合的地方。不是因为它听起来新。
而是因为 AI 集群特别讨厌“多余的软件干预”。
而 DPU 的官方定位,恰恰就是把网络、存储、安全等基础设施处理从主机 CPU 中 offload 出去。
03
DPU 最先改变的,不是“交换机”,而是“主机边界”
很多人讨论 DPU,会直接跳到网络骨干层:
leaf / spine 会不会变 交换机是不是会减少 Fabric 会不会重构
这些问题都可以讨论。但真正先发生变化的,往往是服务器边界。
为什么?
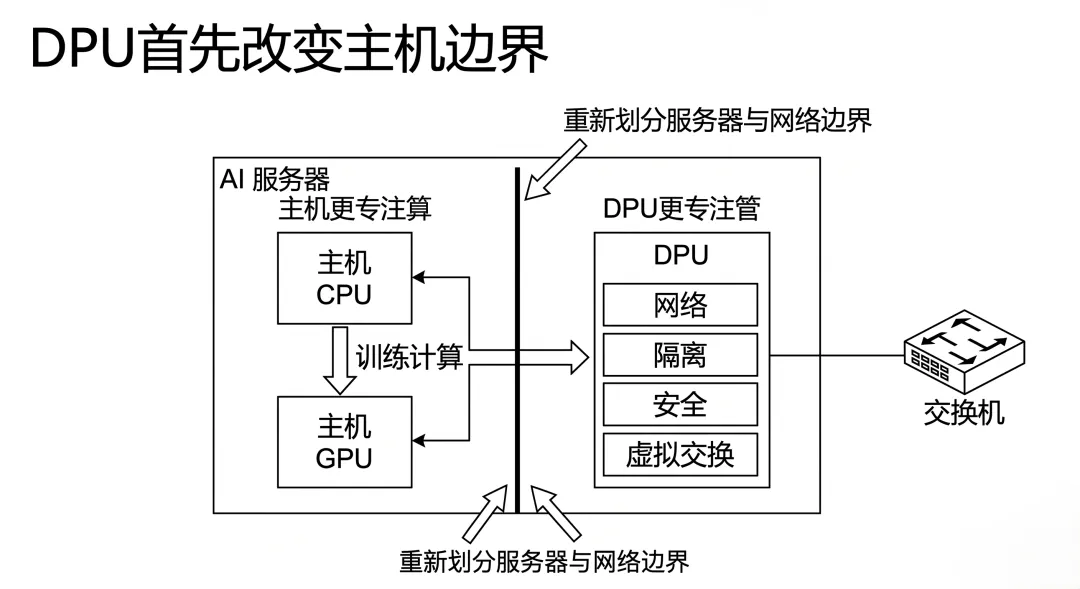
因为 DPU 首先站的位置,不是在机房中间。而是在服务器边缘。
这意味着它天然最容易改变的是:
服务器和网络的分界线 主机 CPU 和网络职能的边界 租户任务和基础设施任务的边界 训练流量和“杂质流量”的边界
这件事有多重要?
在 AI 集群里,它几乎直接决定了两类能力:
第一类:路径干净不干净
如果训练流量必须和很多基础设施逻辑共用一条重路径,那你就会更容易遇到:
抖动 额外上下文切换 软件路径不一致 额外慢尾
第二类:隔离做得好不好
AI 集群越来越不是单一训练任务独占整机房。你会遇到:
多租户 推理与训练并存 容器网络 安全与隔离需求
如果这些事都继续往主机里堆,最后很容易把训练路径“搞脏”。
而 DPU 恰恰提供了一种边界重画方式:
主机更专注于算,基础设施更专注于管。
这就是为什么说,DPU 首先改变的是“主机边界”,而不是“交换机形状”。
04
它会不会直接改善 NCCL / AllReduce 表现?
这个问题必须谨慎回答。
答案不是简单的“会”或者“不会”。
更准确的说法是:
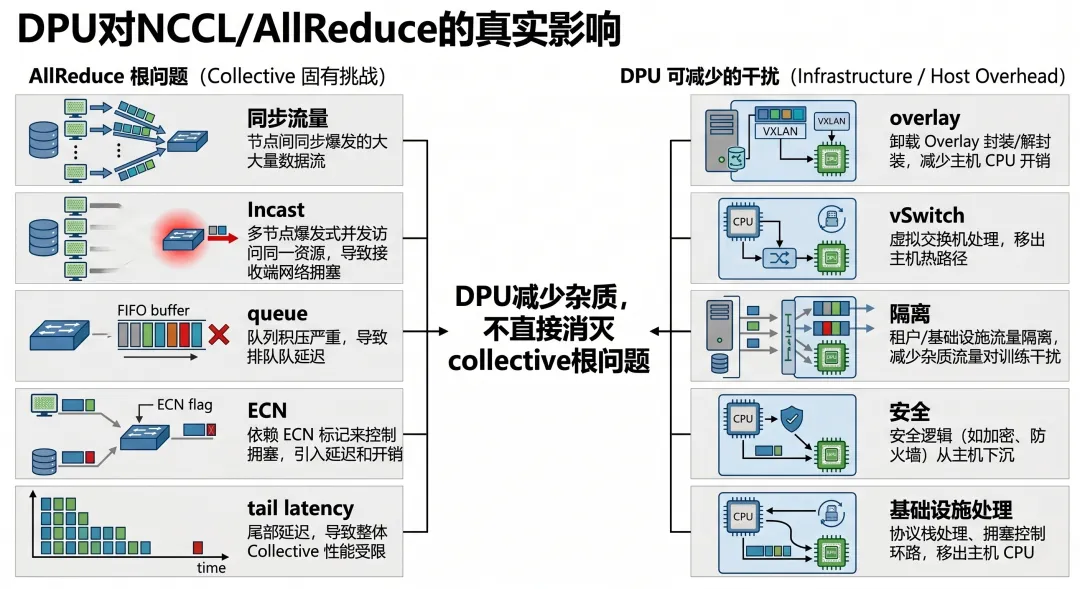
DPU 不会神奇地替你解决 collective 的根问题。但它有可能减少那些本来不该落在训练热路径里的干扰。
这两句话要同时成立。
为什么说它不会神奇地解决根问题?
因为 AllReduce 慢的核心原因,通常仍然是这些:
同步流量 Incast queue 高水位 ECN / PFC 行为 路径不对称 rank / channel 映射不合理 tail latency 放大
这些问题大部分仍然发生在:
NIC fabric switch egress 上层通信组织方式
DPU 不能凭空消灭 Incast。也不能让一个糟糕的拓扑自动变好。
但为什么又说它可能有帮助?
因为它可能把一部分不该干扰训练路径的东西拿走。
比如:
基础设施包处理 部分虚拟化 / overlay 逻辑 部分隔离与策略路径 一些本来落在 host CPU 的网络处理工作
这样做的直接好处不是“collective 自动更快”。
而是:
训练路径更少被杂事打扰。
这是一种“减噪”能力。不是“魔法提速”。
所以如果你问:
“DPU 会不会让 NCCL / AllReduce 更快?”
更负责任的回答是:
它更可能让路径更干净,而不是让 collective 机制本身变简单。
05
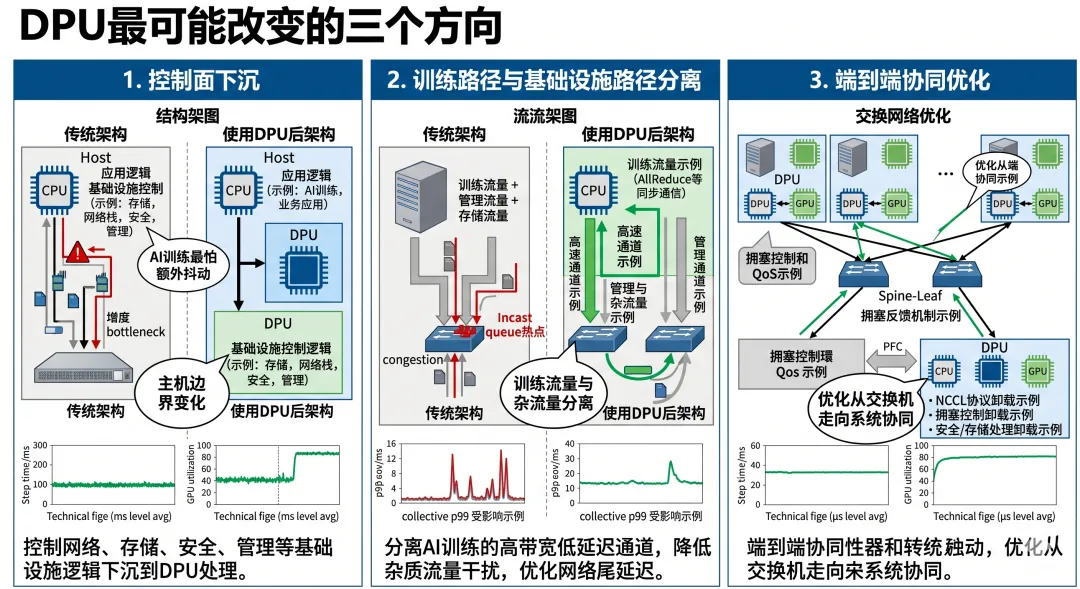
DPU 最可能改变的三个方向
如果要更落地一点,我认为 DPU 对 AI 集群网络架构最可能带来三类变化。
第一类:网络与基础设施控制面更下沉
过去很多基础设施逻辑都在主机里做。
未来更可能出现的情况是:
控制更靠近网口 网络策略更靠近 DPU 主机 OS 与训练任务少承担不必要的基础设施逻辑
这意味着:
AI 服务器会越来越像“算力节点 + 基础设施节点”的组合体。
这对架构的影响非常大。因为它直接改写了“主机到底负责什么”。
第二类:训练路径与基础设施路径更分离
这不是说你一定会有两张物理网。
而是说:
训练数据面 基础设施控制面 隔离 / 安全 / 虚拟化路径
会更容易被切开。
这件事一旦做好,AI 集群最怕的“热路径混脏路径”的问题会缓解很多。
你可以把它理解成:
让训练流量少跟“杂流量”抢同一条软件路径。
第三类:网络优化的重心从“纯交换机调优”变成“端到端协同”
过去大家谈网络优化,很容易只盯:
交换机 buffer ECN 阈值 PFC 行为 spine / leaf 拓扑
这些当然还是要看。
但 DPU 一旦进入架构,优化重心会开始变化:
主机边界怎么划 DPU 承担什么 GPU / NIC / DPU / Switch 如何协同 哪些逻辑在边缘做更合适 哪些通信该在本地消化,哪些必须上网
也就是说,网络优化会越来越像一个“系统协同问题”。
而不是纯交换机问题。
06
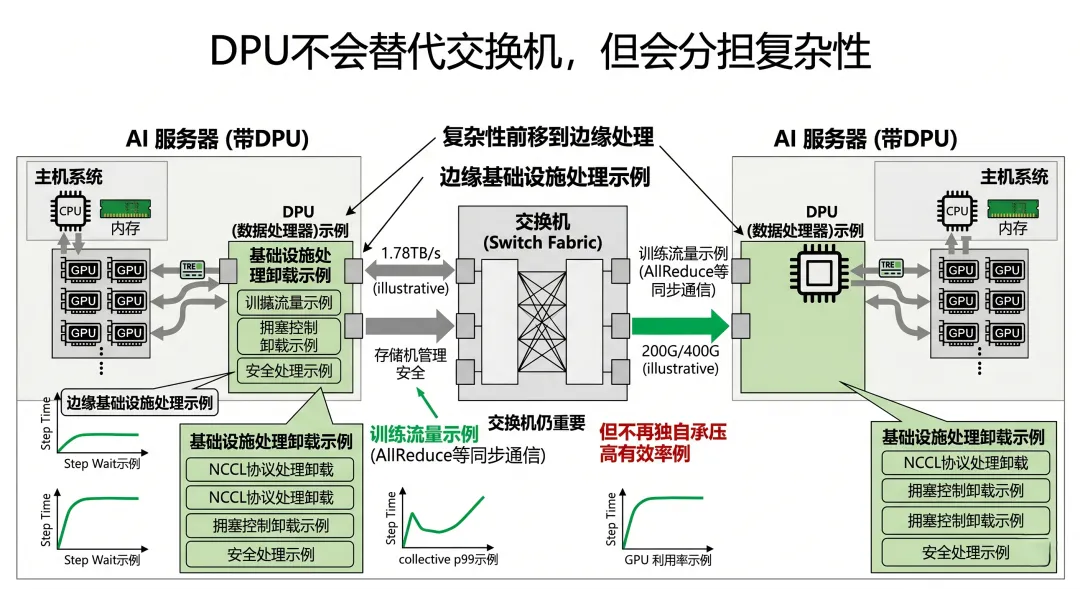
那它会不会让交换机变得“不那么重要”?
会。
但不是你想象中的那种“替代”。
更准确的说法是:
DPU 会让交换机不再独自承担全部复杂性。
这句话很关键。
今天很多 AI 网络问题,最后都压在交换机上:
Incast queue ECN PFC hotspot egress tail latency
于是交换机像一个“总背锅侠”。
但现实是,很多问题本来就不该只靠交换机兜底。
比如:
为什么所有基础设施逻辑都要压在主机再穿过网络? 为什么训练热路径要和那么多控制路径混在一起? 为什么通信组织不更早地在端点附近做约束? 为什么所有压力都要到交换机 egress 才暴露?
DPU 的引入,会让一部分复杂性在更前面被处理掉。
这不是说交换机不重要了。
而是:
交换机不用再独自承担所有中间成本。
所以未来你会感觉:
交换机还是核心 但它不再是唯一核心 AI 网络更像一个“边缘到中间协同”的系统
这就是 DPU 真正有可能带来的架构变化。
07
DPU 真正改变的,是 AI 网络的“重心”
DPU 不一定会让 AI 集群“换掉交换机”,但一定会让 AI 网络的重心发生变化。
这个重心变化是什么?
从:
交换机为中心 主机承担大量基础设施逻辑 训练路径和杂路径混在一起
逐渐走向:
主机更专注算 DPU 更专注基础设施 交换机更专注真正需要跨 fabric 的部分 网络优化从“调交换机”变成“端到端协同”
所以:
DPU 会不会改变 AI 集群网络架构?
答案是:
会。而且它改变的,不只是性能。更是“网络职责分布”的方式。
这才是它最值得关注的地方。
关于这类问题,其实需要一整套系统性的理解和排查方法。
如果你有兴趣,可以在后台私信:答疑
如果你也在做 AI 集群架构
欢迎关注「算力网络架构手记」
长期拆解真实算力网络问题
