 夜雨聆风
夜雨聆风前三篇搭好了基础设施的两根支柱:知识库解决“读了就忘”,Skill 解决“每次重新想结构”。今天聊最后一根。
你手里有了素材、有了框架,怎么用最短的时间把它们变成一篇能交的论文?
一、“用 ChatGPT 写论文”的人,后来都怎样了
泛泛而谈,不符合规范,查重爆红。
我见过不少人兴冲冲地把研究问题丢给 ChatGPT,让它“帮我写一篇 Introduction”。拿到的东西乍一看还行,仔细一读全是问题:引用是编的,逻辑是套话,学术判断为零。更要命的是,这种“什么都能写一点”的输出给你一种虚假的完成感——你以为初稿有了,其实你拿到的是一堆需要从头改写的废料。
万能 AI 的幻觉:什么都能做 = 什么都做不好。
一个 AI 工具不可能同时擅长文献精读、初稿生成、语言润色和学术审校。就像你不会让一个人同时当厨师、服务员和收银员——理论上都能干,实际上每样都打折扣。
工具焦虑:每天出新 AI,到底该用哪个?
GPT-4、Claude、Gemini、Kimi、通义、文心……每周都有新工具发布,每个都说自己最强。你花大量时间试用、对比、纠结,最后一个都没用熟。
选择困难的本质不是工具太多,是你缺乏一个“分工逻辑”。一旦你想清楚每个环节需要什么能力,工具选择就变成了简单的匹配题。
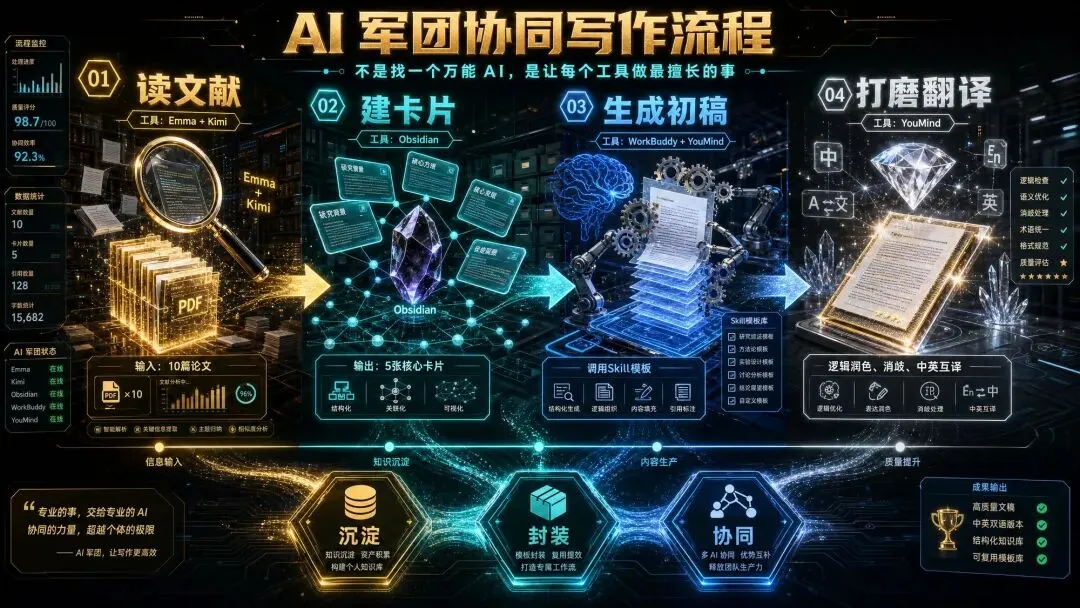
二、All for One,而非 All in One
每个 AI 做它最擅长的一件事,串成一条链。
不要指望一个工具包揽一切。让专业的做专业的事,你设计好接力顺序就行。
我的 AI 智能体矩阵
经过两年多试错,我目前稳定在用的工具链:
注意,这不是唯一正确的组合。这是我根据自己的习惯、预算和研究领域跑通的一条链路。你的链路可能完全不同,但分工逻辑一样:每个节点只负责一件事,做完交给下一个。
三档预算方案
不是每个人都愿意或能够为 AI 工具付费。三种路径都能跑通:
免费方案唯一的代价是每个环节多花一点时间做人工衔接,但核心流程完全一样。
协同写作四步流程
从文献到成稿,完整链路这样跑:
第一步:文献提取(Emma / Kimi)
把 PDF 扔进去,用提示词引导它提取你需要的信息:
请阅读这篇论文,帮我提取以下信息:
1. 核心研究发现(1-2句话概括)
2. 研究方法(方法类型+样本+数据来源)
3. 最值得直接引用的1句原文(标注页码)
4. 这篇论文与"[你的研究主题]"的关联点
AI 提取完,花1分钟检查、修正,然后存入 Obsidian 的文献卡片。
第二步:建卡归库(Obsidian)
把第一步的输出整理成标准格式卡片,存入对应文件夹。纯手工,但因为格式固定,每张卡片不超过2分钟。
第三步:初稿生成(WorkBuddy)
准备好输入素材(相关卡片 + Skill),喂给 WorkBuddy:
请按照以下写作框架,使用下面的文献素材,为我生成一篇 Introduction 初稿:
【写作框架】
(粘贴你的 Introduction 五段式 Skill)
【文献素材】
(粘贴3-5张相关的核心观点卡)
【研究问题】
(一句话)
【方法选择】
(一句话)
要求:严格按照框架的段落结构和字数要求,每个论点必须有明确的文献支撑。
它给你的初稿不会完美,但结构对、素材对、方向对。你拿到的是一个70分的底稿,不是一张白纸。
第四步:深度打磨(YouMind)
把初稿丢进 YouMind,逐段精修。检查逻辑衔接是否自然,确认学术表述是否准确,润色语言去掉 AI 痕迹,补充你自己的学术判断。
这一步最耗时间,也是你作为研究者真正发挥价值的环节。前三步省掉的是机械劳动,这一步是专业判断。
从阅读到成稿
画成流程:
PDF 原文
↓ Emma/Kimi 提取
文献卡片(核心观点+方法+金句)
↓ 存入 Obsidian
知识库(可检索、可复用)
↓ 筛选相关卡片 + 调用 Skill
WorkBuddy 生成初稿
↓
YouMind 逐段打磨
↓
终稿
每个节点的输入来自上一个节点的输出。没有一步是从零开始的。
三、全流程实录
一篇 Introduction 从文献到定稿
以我最近写的一篇基层治理论文为例(公共管理领域,涉及10篇核心文献),完整记录时间消耗:
| 合计 | 约3.5小时 |
传统写法同样的 Introduction 大概需要三到五天——至少一天半翻 PDF 找素材,一天纠结结构,剩下的时间才是真正在写。
工具链协同省掉的是前面的机械劳动。时间集中花在打磨上,也就是真正需要学术判断力的地方。
翻车实录:我踩过的坑
坑一:初稿太依赖 AI,打磨时发现要大改。
早期给 AI 的输入太粗糙——没有 Skill 约束,卡片也不够具体。AI 自由发挥的结果:结构散、引用虚、逻辑跳。打磨阶段基本等于重写。
教训:输入质量决定输出质量。Skill 越具体、卡片越精准,初稿越接近你要的东西。
坑二:工具之间的格式不兼容。
Kimi 提取的内容格式和 Obsidian 卡片格式不一样,每次都要手动调整。后来我在提取提示词里加了格式要求,让 AI 直接按卡片模板输出,省掉了格式转换。
教训:在链路第一个环节就规定好输出格式,后面每一步都省事。
坑三:过度追求自动化,忽略了人的判断。
有一段时间我试图让整条链路全自动——文献自动提取、自动建卡、自动生成初稿。结果质量断崖式下降。因为“这篇文献跟我的研究有什么关系”这个判断,目前的 AI 做不好。它不知道你的研究问题是什么、论证逻辑是什么、你想强调什么。
教训:人的判断是链路中不可替代的节点。自动化机械劳动,不自动化学术思考。

写在最后
工具会一直更新换代。今天用的 Kimi,明年可能有更好的替代品。但分工逻辑不会变——文献提取、知识管理、初稿生成、深度打磨,这四个环节永远存在,执行者可以换。
你建的不是“一套工具组合”,是一条可迭代的流水线。工具是可替换的零件,流程才是资产。
今天做一件事:选好你的工具链(不用纠结最优解,先选一个能跑通的组合),然后拿一篇论文的 Introduction 跑一次完整流程。从文献提取到初稿生成,走一遍。
第一次跑通一定会卡、会慢、会出错。但跑完你就知道哪里需要优化。先跑起来,再迭代。
这是“学术基础设施”系列的最后一篇。四篇连起来:
认知:你缺的不是工具,是基础设施
沉淀:把文献变成可复用的资产
封装:把经验变成可调用的 Skill
协同:让工具各司其职,串成流水线
读完四篇文章不会让你写论文变快,建完基础设施才会。
从今天开始:一张卡片、一个 Skill、一次完整的流程跑通。

