 夜雨聆风
夜雨聆风本文是《把 AI 关进笼子,让它替我合并一万个文件》系列第 2 篇。
那天我心情还挺好。执行官(我让 AI 扮演的"合并工人")花了大半天,告诉我一个复杂模块"合并完成"。我随手点开看了一眼——它把我们自己写的一个配置解析能力,悄悄用 upstream 的版本盖掉了。
没报错。没警告。没有任何一行字告诉我"嘿,我删了点东西"。它就这么没了,然后 AI 一脸坦然地报告:搞定。
如果你做过长期 fork 的维护,你知道这种感觉——不是愤怒,是后背发凉。因为它如果不被我抓到,这个功能就这么从产品里蒸发了,而且没有人会知道。
问题不在 AI 笨,在我让它自己审自己
我第一反应是给它加更严的 prompt:你不许删东西、删之前要警告我、合并完自己检查一遍。
没用。它当然会"检查",而且检查完信誓旦旦告诉我"没问题"。
后来我想明白了一件事,这是我整个七周里最值钱的一个发现:
让写 patch 的那个模型回头审自己的 patch,等于让作者 review 自己的 PR。它会系统性地放过自己。
这不是 AI 蠢,是认知规律。你自己写完一篇文章,回头校对总比别人帮你校对漏得多——因为你脑子里装着"我本来想表达啥",看代码时眼睛会自动脑补"我本来想保留它的"。AI 一模一样,而且更糟:
AI 没有"丢失感"——它不知道自己在丢东西。
它的目标是"让合并后的代码能跑起来",不是"确保什么都没丢"。能跑 ≠ 没丢。一个被删掉的功能,照样能跑得欢。
所以我干了件听起来很轴的事:再请一个 AI,专门当审判官,盯着第一个 AI 别偷工减料。 而且我故意请"别家公司"的——执行官用 GPT,审判官用 Claude。就为了它俩不会互相护短。
这篇就聊这一条主线:对抗式架构。怎么让两个 AI 互相制衡,又不让它们吵起来烧光我的钱。
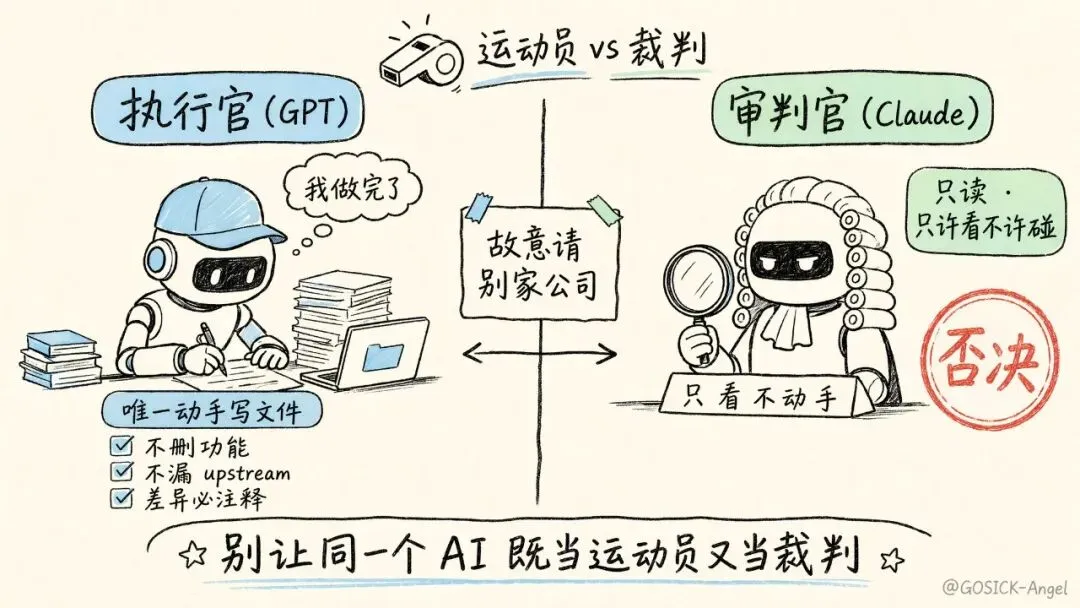
先认识这两位:执行官 vs 审判官
先把"Agent"这个词讲人话。给一个 LLM 套上固定的职责、固定的工具、固定的循环,它就成了一个"打工人"。 多 Agent,就是按职责和权限把活拆给好几个打工人,而不是让一个人全包。
我这套系统里,跟今天主题相关的是两个对立角色。
执行官(Executor):唯一动手写文件的那个
执行官是整个系统里唯一能动手改文件的 agent。性格嘛——闷头干活、效率高、但不爱回头看自己漏了啥的实习生。
我给它定了三条铁律,写死在它的岗位说明里:
1. 不删除当前分支的任何功能代码 2. 不遗漏 upstream 的任何功能、优化或 bugfix 3. 所有行为差异必须用注释明确标注
第三条尤其重要。两边都改过同一处时,最偷懒的做法是闷头选一边。但三个月后你完全不记得这里为什么和 upstream 不一样了。所以每一处"有意为之的差异"都得留注释:
# Current branch enhancement (not in upstream)# Feature: HTTP-only Cookie auth, replaces localStorage tokendef set_auth_cookie(response, token): ...# Merged from upstream 1.11.3# Feature: MCP tool-call supportclass MCPToolNode: ...这些注释不是给 AI 看的,是给未来的我看的。等 upstream 下一个大版本来了,我一眼就知道"这里曾经有过冲突,当初的决定是什么,现在还适不适用"。
审判官(Judge):只许看,不许碰
审判官的定位,我反复强调过一句话:它不是来"帮执行官找通过理由"的,它是来"找漏洞"的。
这个心态差异是致命的。执行官干完活,会下意识觉得"我做完了",带着一种交差的松弛感。审判官在一个完全独立的上下文里冷眼旁观,没有那个"我做完了"的心理包袱。它的任务清单是反着写的——以下任何一条成立,立即否决:
• upstream 里存在的逻辑,在合并结果里消失了 • 当前分支的独有功能被删除或弱化 • 存在没标注的行为差异 • 注释内容和代码行为对不上 • 合并后构建失败
实战第一次就见效:API 的第一个合并阶段,就被审判官当场否决,揪出来一个配置解析能力的回退——就是开头那个让我后背发凉的问题。重做之后才通过,后来验证那个问题千真万确。
审判官靠什么找漏洞?三方对比 + 工具证伪
光让审判官"用心看"还不够,AI 用心看也会漏。审判官的火眼金睛,靠的是两样东西。
第一样:三方对比
大多数人(和大多数 AI)审合并,只看"两边的差异"——upstream 一份、当前分支一份,diff 一下。
这就像法庭上只听原告和被告各说一句,你根本不知道是谁先动的手。
正确的做法是三方对比:把"案发前的现场"也调出来——共同祖先(merge-base)、upstream、当前分支,三份一起看。
MERGE_BASE=$(git merge-base HEAD upstream/main)git show "$MERGE_BASE":path/to/file.py > /tmp/base.pygit show "upstream/main":path/to/file.py > /tmp/upstream.pygit show HEAD:path/to/file.py > /tmp/current.pydiff3 /tmp/current.py /tmp/base.py /tmp/upstream.py只看两边,你只知道"现在不一样"。看三方,你才知道"是谁改的、改了什么、为什么改"。
举个真实例子:某个函数,upstream 重构了,我们也改了(加了企业功能)。只看两边,感觉冲突一团乱麻。三方一摆,发现 upstream 改的部分和我们改的部分根本不沾边,直接合并,压根不冲突。
第二样:工具证伪(这条比加 AI 更管用)
这是整个系统里最反直觉、但收益最大的设计:
LLM 负责理解语义,工具负责证伪。
什么意思?审判官里的 AI 再能说会道,它的判断也得先过一道确定性工具检查。工具说"不行",AI 再怎么解释都没用——这个否决(我们叫 VETO)不可商量。
为什么?因为有些丢失模式,AI 用"读"是读不出来的。比如一个接口改了签名,调用方在另外八个文件里没跟着改——AI 看单个 diff 永远发现不了,但一个反向扫描工具 grep 一下就抓住了。这类"工具能查、AI 会漏"的模式,我整理成了六大丢失模式扫描器,每一条都是确定性的 VETO 关卡。
这六大丢失模式具体长啥样、怎么扫,是下一篇 03 篇[1] 的主菜,这里先埋个钩子。今天你只要记住:审判官不是靠"更聪明的 AI",是靠"AI + 一排不会说谎的工具"。
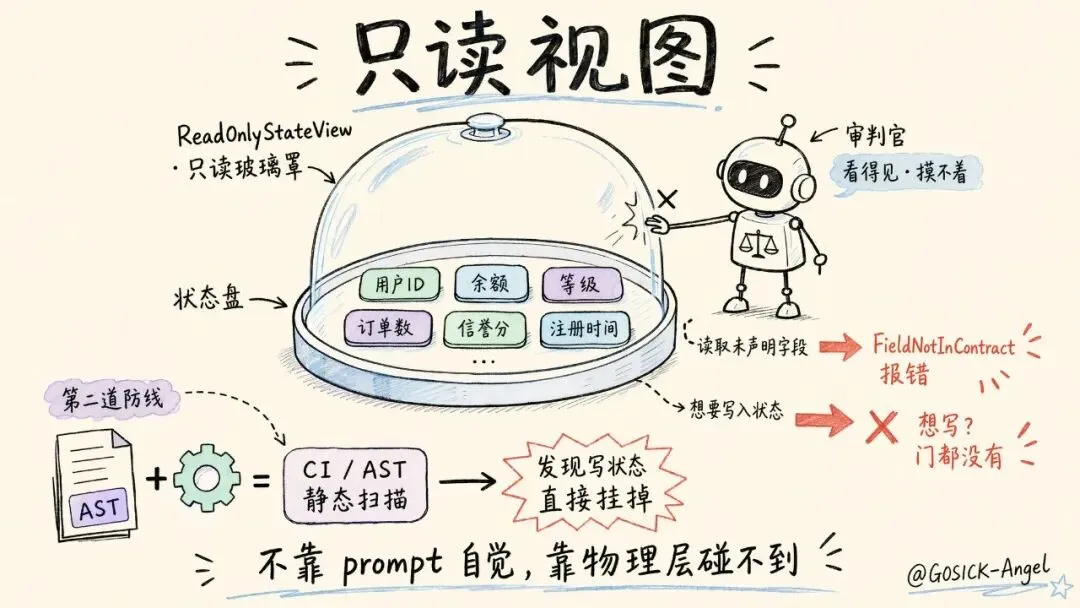
给审判官戴的紧箍咒:只读视图
现在到了最关键的工程细节。
我说审判官"只许看不许碰",这不能靠 prompt 里写一句"请你不要修改状态"——AI 被 prompt 带跑偏太容易了。我得在物理层面让它碰不到。
只读视图(ReadOnlyStateView)是什么
想象整个合并任务的状态(哪些文件、什么风险、谁改了啥)是一大盘数据。我给审判官的,不是这盘数据本身,而是隔着一层只读玻璃罩的它。审判官看得见、摸不着:
• 想读一个没在它合同里声明的字段?当场抛 FieldNotInContract,直接报错。• 想写状态、改任何东西?门都没有——它拿到的就是个只读代理。
更狠的是,这条规矩还有第二道防线:CI 里有个静态扫描,会用 AST 把每个审查 agent 的源码翻一遍,只要出现 state.<字段> = ... 这种写状态的代码,直接挂掉 CI,代码根本合不进来。
# 审判官的岗位说明书(contract),声明它能读什么、绝对禁止什么name: judgeinputs: # 只能读这几个字段,其余一律拒读 - file_decision_records - shadow_conflicts - interface_changesforbidden: - writes_state # never state.x = y - direct_llm_call # never bypass the retry layercollaboration: review_only为什么非要"能写的"和"能审的"物理隔离
因为这样出了事能追责。
如果每个 agent 都能写文件,出 bug 时你根本理不清:是计划错了?是执行官写错了?还是审判官放过了?三方都有嫌疑。
但在我这套里,写权限只攥在执行官一个 agent 手里,而且它写之前必须先"存档"(快照),写砸了立刻"读档"(回滚)。审判官想让执行官改,只能走状态机绕回去,让执行官再写一次。审判官自己永远碰不到文件。
事故归因时,我永远只需要看执行官的日志。这个"先存档再写、唯一写入通道"的快照机制,是第 4 篇 04 篇[2] 的专题,这里你只要知道:审判官只读、执行官唯一写入,是这套制衡的地基。
反共谋:为什么我故意请"另一家公司"
回到开头那个"轴"的决定:执行官用 OpenAI 的 GPT,审判官用 Anthropic 的 Claude。故意不同家。
很多人觉得这是因为"Claude 更会审查"。不是的。
真正的原因是:同一家的两个模型,像一个师傅教出来的两个徒弟,容易犯一模一样的错,还互相点头。 这叫共谋偏差(collusion bias)。如果执行官和审判官是同源模型,执行官漏掉的盲区,审判官大概率也看不见——俩人对着同一个坑齐刷刷地视而不见。
换一家厂的模型,等于换了一双完全不同训练出来的眼睛。它的盲区和执行官的盲区不重叠,这才有制衡的意义。
落到工程上,这件事一点不玄学。系统里每个 agent 都有自己独立的一份 LLM 配置(AgentLLMConfig),各管各的 provider、model、API key 环境变量:
agents: executor: provider: openai # one company model: gpt-5.4 judge: provider: anthropic # the other company — anti-collusion model: claude-opus-4-6想换配比、想加备用 key、想给简单任务降档省钱,改这一块就行,互不干扰。
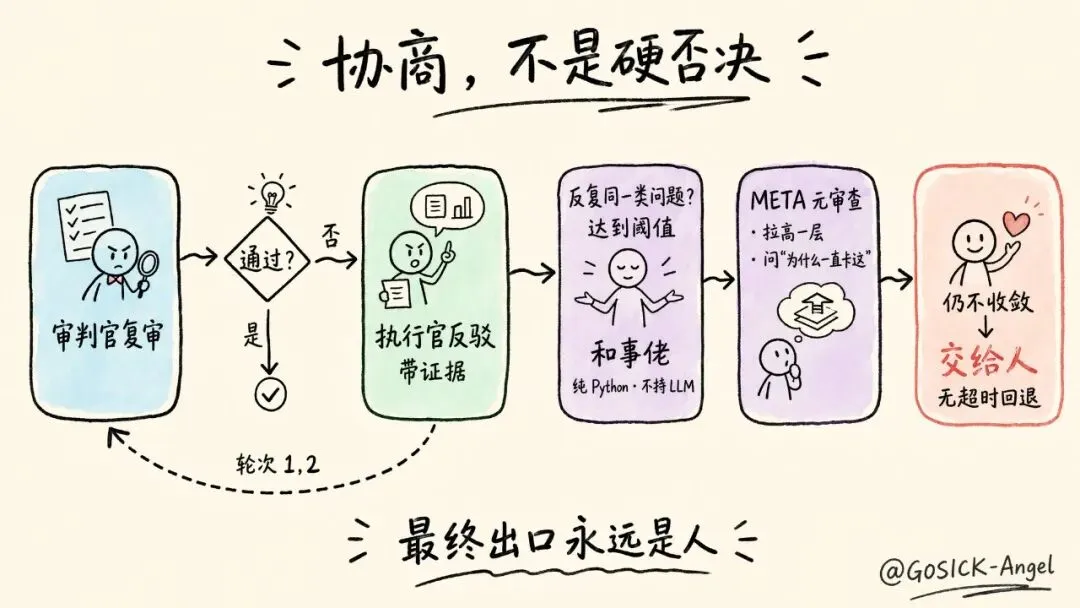
别让审判官当独裁者:协商,而不是硬否决
讲到这你可能觉得:审判官这么强势,执行官岂不是任它拿捏?
早期我确实是这么设计的——审判官说不行就是不行,执行官乖乖重做。结果发现一个问题:审判官有时候误判。它说"你把 upstream 的某个逻辑弄丢了",但其实执行官是有意合并掉的,而且有充分理由。
所以现在审判官的裁决,是协商的起点,不是终点。
执行官可以不服。它能带着合并证据,组织一份"反驳"(build_rebuttal)——我没丢,这里是这么对应的,证据如下。审判官收到反驳,会重新评估:
• 觉得反驳有理 → 收回裁决,达成一致; • 觉得还是不行 → 维持裁决,执行官老实修。
for round in 0..max_dispute_rounds: verdict = judge.review(merge_result) if verdict.approved: break # agreed rebuttal = executor.build_rebuttal(verdict.issues, evidence) verdict = judge.re_evaluate(rebuttal) # judge may be persuaded if verdict.approved: break# still no consensus after max rounds → escalate to human两边每一轮交换的不是"命令",是"证据 + 理由"。这比"审判官一票否决"健康得多——既防住了执行官偷工减料,又不让审判官的误判把对的合并给毙了。
(注意:这是针对语义层面的争议。前面说的工具证伪 VETO 是另一回事——工具说构建失败了,那是客观事实,没得商量。)
死循环怎么解?请个"和事佬"把视角拉高一层
协商听着美好,但你应该已经闻到一股烧钱的味道了。
万一执行官和审判官杠上了呢?执行官反驳、审判官维持、执行官再反驳……或者更糟,参谋改计划、计划审计官又驳回、参谋再改——无限往复,每一轮都是真金白银的 LLM 调用。
幼稚解法是加个硬上限:max_rounds=5,到第五轮强制放行。但你想想,到第五轮还没谈拢的计划,八成是半烂的,强行喂给执行官,事故更大。
我的解法是请第三个角色:调度协调员(Coordinator),一个纯 Python 的和事佬,自己不持有任何 LLM。
它就盯着一件事:同一类问题是不是反复出现? 一旦反复次数达到阈值(默认 2),它不会自己下场判,而是给原来那个 agent 换一套特殊的 prompt(我们叫 META-* 提示),让它把视角拉高一层。
常规审查问的是:"这个计划对不对?"元审查(meta-review)问的是:"我们为什么一直卡在这里?"
这是两个完全不同的问题。前者钻在当前争论里,后者跳出来看全局。换个大脑、换个高度,卡死的局往往就松动了。元审查的结论会写进 coordinator_directives,作为下一轮的战略指引。
轮次 1、2: 执行官和审判官正常你来我往轮次 3(达到阈值): 和事佬发现"同一类 issue 又来了" → 让原 agent 换 META-* prompt 做元审查 → 问"我们为什么卡在这",结论写入 coordinator_directives轮次 4: 带着这个高层指引重新来过仍不收敛 → 交给人这个"和事佬 + 元审查"的模板,任何多 agent 的审查回环都能套。完整工程清单我放在了系列最后的 06 篇[3]。
最后一道出口,永远是人
这是整套制衡里我最坚持的一条原则:最终出口永远是人,而且是显式的人,没有超时回退。
什么叫"没有超时回退"?很多系统会设计成:等人决策,超过 24 小时没回应,就用默认值自动放行。我把这条路堵死了。
具体到代码,记录"这个决策是谁做的"的来源枚举(DecisionSource)里,只有 AUTO_PLANNER/AUTO_EXECUTOR/HUMAN/BATCH_HUMAN 这几种,故意没有TIMEOUT_DEFAULT 这种值——也就是说,系统里压根没有"超时自动放行"这个来源。人机接待员(渲染人工决策模板的那个 agent)的岗位说明里也明确禁止填默认值。结果就是:
一个需要人拍板的条目,只要人没明确决策,它的决定就永远是
ESCALATE_HUMAN(交人处理),绝不会被一个默认值蒙混过去。
为什么这么轴?因为整个系列的核心恐惧,就是"东西在我不知道的情况下悄悄没了"。一个超时默认值,就是这种悄悄丢失的完美温床——你出去喝了杯咖啡,回来发现系统"帮你"做了二十个你根本没看过的决定。不行。需要人看的,就必须等人看。
死循环的终极解法,从来不是"更聪明的 LLM",而是"把问题结构化地、清清楚楚地交到人手上"。
小结:别让 AI 当运动员兼裁判
回头看,这套对抗式架构其实就一句话能概括:
别让同一个 AI 既当运动员又当裁判。
把它拆开,拆成一条制衡链:
执行官写、审判官审、审判官只读、还故意请别家公司的、谈不拢就拉高视角、最后永远交给人。每一环都在防同一件事:
AI 没有"丢失感"——它不知道自己在丢东西。所以我得替它建一套它逃不掉的笼子。
这套东西我已经做成了开源系统。如果你也在维护一个长期分叉的 fork,或者正在搭自己的多 agent 工作流,欢迎试试:
pip install code-merge-systemmerge upstream/main --dry-run # only analyzes, writes nothing--dry-run 只出计划、不动你一个文件,先看看它怎么给你的文件分类、怎么排执行官和审判官的活。首次运行会开个浏览器向导带你配置。觉得哪里设计得蠢,或者哪个制衡没防住你的场景,欢迎来 GitHub 拍砖、提 issue——我这套笼子也是被一个个真实的坑逼出来的,多一双眼睛多一分踏实。
下一篇,我们把镜头怼到审判官的火眼金睛上:那六种 AI 自己绝对发现不了、只能靠工具揪出来的"丢失模式",到底长什么样。
上一篇 七周战争:我是怎么被一次上游合并逼到用 AI 硬刚的[4] · 下一篇 一个都不许少:AI 会悄悄吞掉东西的六种方式[1]
引用链接
[1] 03 篇: 03-never-lose-anything.md[2] 04 篇: 04-step-on-solid-ground.md[3] 06 篇: 06-caging-the-llm.md[4] 我用 AI 合并一万个文件,第一周白干了——然后我把这套血泪方法做成了系统
